Window是Flink的核心功能之一,使用好Window对解决一些业务场景是非常有帮助的。
今天分享5个Flink Window的使用小技巧,不过在开始之前,我们先复习几个核心概念。
Window有几个核心组件:
Assigner,负责确定待处理元素所属的Window;
Trigger,负责确定Window何时触发计算;
Evictor,可以用来“清理”Window中的元素;
Function,负责处理窗口中的数据;
Window是有状态的,这个状态和元素的Key以及Window绑定,我们可以抽象的理解为形式为(Key, Window) -> WindowState的Map。
Window分为两类,Keyed和Non-Keyed Window,今天我们只讨论Keyed Window。
OK,接下来进入正题。
技巧一:Mini-Batch输出
看到这个标题大家可能会很疑惑,Flink的一大优势是“纯流式计算”,相比于Mini-Batch方式在实时性上有很大优势,这里的技巧却是和Mini-Batch有关的,这不是“自断手脚”吗?
在解答这个疑问之前,我们先介绍一下问题背景。
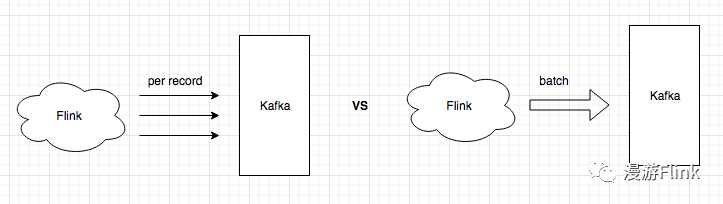
大部分Flink作业在处理完数据后,都要把结果写出到外部系统,比如Kafka。 在写外部系统的时候,我们有如下两种方式:
在实际生产中,除非对延迟要求非常高,否则使用第一种方式会给外部存储系统带来很大的QPS压力,所以一般建议采用第二种方式。
这里多介绍一下,实际上很多存储系统在设计SDK的时候,已经考虑了对Batch发送的支持 ,比如Kafka:
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request.
对于这种SDK,用户在使用的时候会更加省心,只需要对每条消息调用一下send接口即可,消息会缓存在队列里,由异步线程对消息进行Batch发送。
不过需要注意的是,在Flink Checkpoint的时候,一定要通过flush把未发送的数据发送出去。
以FlinkKafkaProducer示意:
class FlinkKafkaProducer extends RichSinkFunction implements CheckpointedFunction {
public void invoke(IN next, Context context) throws Exception {
kafkaProducer.send(record, callback);
}
public void snapshotState(FunctionSnapshotContext ctx) throws Exception {
kafkaProducer.flush();
}
}
如果外部存储系统的SDK没有提供异步Batch发送功能的话,那就需要用户自己实现了:
第一种思路是这样的,在RichSinkFunction中,通过Flink ListState缓存数据,然后根据消息数量和延迟时间来确定发送时机。
这种方式在原理上并没有问题,缺点是需要用户自己对状态进行维护和清理,稍微有点麻烦。
其实我们可以通过Window来实现这一需求,Window自带的State,可以很好地实现缓存数据功能,并且状态的维护清理不需要用户操心。
用户需要关心的主要是两个点:
如何缓存一定数量之后触发发送;
如何延迟一定时间之后触发发送;
第一个点很好实现,通过CountWindow + ProcessWindowFunction即可实现:
DataStream> input = ...;
input
.keyBy(t -> t.f0)
.countWindow(200) // batch大小
.process(new BatchSendFunction());
public class BatchSendFunction extends ProcessWindowFunction {
public void process(Object o, Context context, Iterable elements, Collector out) throws Exception {
List batch = new ArrayList<>();
for(Object e: elements) {
batch.add(e);
}
// batch发送
client.send(batch);
}
}
这种方式简单有效,能应对大部分情况,但是有一个缺陷,就是无法控制延迟。
如果某个Key对应的消息比较少,那可能延迟一段时间才能发到外部系统。 举一个极端的例子,如果某个Key的消息数量“凑不够”设定的Batch大小,那么窗口就永远不会触发计算,这显然是不能接受的。
为了解决这个问题,即满足上面的第二点,我们就需要用到Trigger了。 可以通过自定义Trigger,实现根据消息的数量以及延迟来确定发送时机:
DataStream> input = ...;
input
.keyBy(t -> t.f0)
.window(GlobalWindows.create())
.trigger(new BatchSendTrigger())
.process(new BatchSendFunction());
public class BatchSendTrigger extends Trigger {
// 最大缓存消息数量
long maxCount;
// 最大缓存时长
long maxDelay;
// 当前消息数量
int elementCount;
// processing timer的时间
long timerTime;
public BatchSendTrigger(long maxCount, long maxDelay) {
this.maxCount = maxCount;
this.maxDelay = maxDelay;
}
public TriggerResult onElement(T element, long timestamp, GlobalWindow window, TriggerContext ctx) throws Exception {
if (elementCount == 0) {
timerTime = ctx.getCurrentProcessingTime() + maxDelay;
ctx.registerProcessingTimeTimer(timerTime);
}
// maxCount条件满足
if (++elementCount >= maxCount) {
elementCount = 0;
ctx.deleteProcessingTimeTimer(timerTime);
return TriggerResult.FIRE_AND_PURGE;
}
return TriggerResult.CONTINUE;
}
public TriggerResult onProcessingTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception {
// maxDelay条件满足
elementCount = 0;
return TriggerResult.FIRE_AND_PURGE;
}
public TriggerResult onEventTime(long time, GlobalWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
public void clear(GlobalWindow window, TriggerContext ctx) throws Exception {
}
}
技巧二:去重
消息去重是分布式计算中一个很常见的需求,以Kafka为例,如果网络不稳定或者Kafka Producer所在的进程失败重启,都有可能造成Topic中消息的重复。 那么如何在消费Topic数据的时候去重,自然成了业务关心的问题。
消息去重有两个关键点:
数据的唯一ID是用来判断是否重复的标准。 时间跨度决定了ID对应的状态保存的时长,如果无限存储下去,一定会造成内存和效率问题。
如果使用Flink实现去重的话,首先想到的思路可能是这样的: 自定义一个FilterFunction,通过HashMap来保存消息是否出现的状态; 为了避免HashMap持续增长,我们可以使用Guava中支持过期配置的Cache来保存数据。
代码示意如下:
public class DedupeFilterFunction extends RichFilterFunction {
LoadingCache cache;
public void open(Configuration parameters) throws Exception {
cache = CacheBuilder.newBuilder()
// 设置过期时间
.expireAfterWrite(timeout, TimeUnit.MILLISECONDS)
.build(...);
}
public boolean filter(T value) throws Exception {
ID key = value.getID();
boolean seen = cache.get(key);
if (!seen) {
cache.put(key, true);
return true;
} else {
return false;
}
}
}
这段代码看起来已经能够很好地解决我们的需求了,但是有一个问题,如果作业异常重启的话,Cache中的状态就都丢失了。 因此这种方式还需要再加一些逻辑,可以通过实现CheckpointedFunction接口,在snapshotState和initializeState的时候,对Cache中的数据进行保存和恢复。
这里就不展开具体代码了,我们直接看一下如何通过Window实现去重。
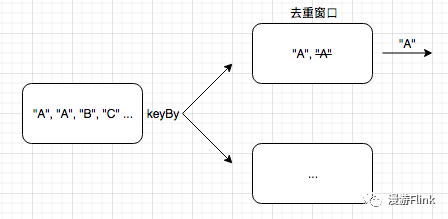
大致思路是这样的,首先通过keyBy操作,把相同ID的数据发往下游同一个节点; 下游窗口保存并处理数据,只发送一条数据到下游。
这里有两个关键点:
窗口的大小与数据重复的时间跨度有关;
窗口的状态不需要也不应该保存所有数据,只需要保存一条即可;
代码示意如下:
DataStream input = ...;
input
.keyBy(...)
.timeWindow(Time.minutes(2))
.reduce(new ReduceFunction() {
public String reduce(String s, String t1) throws Exception {
return s;
}
})
这个实现看起来简单有效,但是有两个问题:
第一个问题,Tumbling Window的窗口划分是和窗口大小对齐的,和我们的预期并不符。
如上2min的窗口划分产生的窗口类似于[00: 00, 00: 02), [00: 02, 00: 04) ...。 如果某条消息在00: 01到达,那么1min之后该窗口就会触发计算。 这样数据重复检测的时间跨度就缩小为了1min,这样会影响去重的效果。
这个问题我们可以通过Session Window来解决,比如ProcessingTimeSessionWindows.withGap(Time.minutes(2))。 不过这里的2min表示的是“如果间隔2min没有重复数据到达的话,则判定为后续没有重复数据”,和上面timeWindow的参数表示的含义是不同的。
第二个问题, 由于需要等窗口结束的时候才触发计算,从而导致了数据发送到下游的延迟较大。
这个可以通过自定义Trigger来解决,当第一条消息到达的时候,就触发计算,且后续不再触发新的计算。
修改后的代码示意如下:
DataStream input = ...;
input
.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.minutes(2)))
.trigger(new DedupTrigger(Time.minutes(2).toMilliseconds()))
.reduce(new ReduceFunction() {
public String reduce(String s, String t1) throws Exception {
return s;
}
})
public class DedupTrigger extends Trigger {
long sessionGap;
public DedupTrigger(long sessionGap) {
this.sessionGap = sessionGap;
}
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
// 如果窗口大小和session gap大小相同,则判断为第一条数据;
if (window.getEnd() - window.getStart() == sessionGap) {
return TriggerResult.FIRE;
}
return TriggerResult.CONTINUE;
}
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
}
public boolean canMerge() {
return true;
}
public void onMerge(TimeWindow window, OnMergeContext ctx) throws Exception {
}
}
说明一下,这里是通过判断窗口大小是否和Session Gap大小相同来判断是否为第一条数据的,这是因为第二条消息到达后,窗口Merge会导致窗口变大。
极端情况是两条消息的处理间隔小于1ms,不过考虑到实际生产中数据重复产生的场景,这种极端情况可以不考虑。 如果不放心,可以考虑通过ValueState来保存并判断是否为第一条数据,这里不展示具体代码了。
技巧三:以“天”划分窗口
具体需求大致是这样的,以自然天划分窗口,每隔5min触发一次计算。 这个需求并不复杂,但是挺常见,我们简单讨论一下。
首先想到的是Tumbling Window,timeWindow(Time.days(1)),但是这样无法实现每隔5min触发一次计算。
然后想到的是通过Sliding Window,timeWindow(Time.days(1), Time.minutes(5)),但是这样的窗口切分并不是自然天,而是大小为一天的滑动窗口。
这里我们可以通过Tumbling Window + 自定义Trigger的方式来实现。 不过需要注意的是,业务需要的自然天一般是指本地时间(东八区)的自然天,但是Flink的窗口切分默认按照UTC进行计算。 好在Flink提供了接口来满足类似需求,TumblingProcessingTimeWindows#of(Time size, Time offset)。
代码示意如下:
DataStream input = ...;
input
.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.days(1), Time.hours(-8)))
.trigger(new Trigger() {
public TriggerResult onElement(String element, long timestamp, TimeWindow window, TriggerContext ctx) throws Exception {
// 触发计算的间隔
long interval = Time.minutes(5).toMilliseconds();
long timer = TimeWindow.getWindowStartWithOffset(ctx.getCurrentProcessingTime(), 0, interval) + interval;
ctx.registerProcessingTimeTimer(timer);
return TriggerResult.CONTINUE;
}
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.FIRE;
}
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
}
})
.reduce(...)
技巧四:慎用ProcessWindowFunction
关于ProcessWindowFunction的缺点,官方文档有说明:
This comes at the cost of performance and resource consumption, because elements cannot be incrementally aggregated but instead need to be buffered internally until the window is considered ready for processing.
相较于ReduceFunction/AggregateFunction/FoldFunction的可以提前对数据进行聚合处理,ProcessWindowFunction是把数据缓存起来,在Trigger触发计算之后再处理,可以把其对应的WindowState简单理解成形式为(Key, Window) -> List的Map。
虽然我们在上面“Mini-Batch输出”章节中用到了ProcessWindowFunction,但是考虑到设定的Window最大数据量比较少,所以问题并不大。 但如果窗口时间跨度比较大,比如几个小时甚至一天,那么缓存大量数据就可能会导致较严重的内存和效率问题了,尤其是以filesystem作为state backend的作业,很容易出现OOM异常。
我们以求窗口中数值的平均值为例,ProcessWindowFunction可能是这样的:
public class AvgProcessWindowFunction extends ProcessWindowFunction {
public void process(Long integer, Context context, Iterable elements, Collector out) throws Exception {
int cnt = 0;
double sum = 0;
// elements 缓存了所有数据
for (long e : elements) {
cnt++;
sum += e;
}
out.collect(sum / cnt);
}
}
AggregateFunction可以对每个窗口只保存Sum和Count值:
public class AvgAggregateFunction implements AggregateFunction, Double> {
public Tuple2 createAccumulator() {
// Accumulator是内容为的Tuple
return new Tuple2<>(0L, 0L);
}
public Tuple2 add(Long in, Tuple2 acc) {
return new Tuple2<>(acc.f0 + in, acc.f1 + 1L);
}
public Double getResult(Tuple2 acc) {
return ((double) acc.f0) / acc.f1;
}
public Tuple2 merge(Tuple2 acc0, Tuple2 acc1) {
return new Tuple2<>(acc0.f0 + acc1.f0, acc0.f1 + acc1.f1);
}
}
可以看出AggregateFunction在节省内存上的优势。
不过需要注意的是,如果同时指定了Evictor的话,那么即使使用 ReduceFunction/AggregateFunction/FoldFunction,Window也会缓存所有数据,以提供给Evictor进行过滤,因此要慎重使用。
这里通过源码简单说明一下:
// WindowedStream
public SingleOutputStreamOperator aggregate(...) {
...
if (evictor != null) {
TypeSerializer> streamRecordSerializer =
(TypeSerializer>) new StreamElementSerializer(input.getType().createSerializer(getExecutionEnvironment().getConfig()));
// 如果配置了Evictor,则通过ListState保存原始StreamRecord数据;
ListStateDescriptor> stateDesc =
new ListStateDescriptor<>("window-contents", streamRecordSerializer);
operator = new EvictingWindowOperator<>(...)
} else {
// 如果没有配置Evictor,则通过AggregatingStateDescriptor保存Accumulator状态
AggregatingStateDescriptor stateDesc = new AggregatingStateDescriptor<>("window-contents",
aggregateFunction, accumulatorType.createSerializer(getExecutionEnvironment().getConfig()));
operator = new WindowOperator<>(...);
}
...
}
技巧五:慎用“细粒度”的SlidingWindow
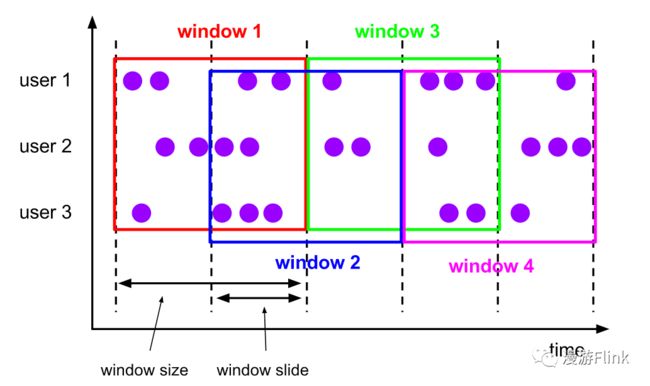
使用SlidingWindow的时候需要指定window_size和window_slide,这里的”细粒度“是指window_size/window_slide特别大的滑动窗口。
以timeWindow(Time.days(1), Time.minutes(5))为例,Flink会为每个Key维护days(1) / minutes(5) = 288个窗口,总的窗口数量是keys * 288。 由于每个窗口会维护单独的状态,并且每个元素会应用到其所属的所有窗口,这样就会给作业的状态保存以及计算效率带来很大影响。
有如下解决思路可以尝试:
第一,通过TumblingWindow + 自定义Trigger来实现,如“技巧三”中所示的方法;
第二,不使用Window,通过ProcessFunction实现。 通过Flink State来保存聚合状态,在processElement中更新状态并设定Timer,在onTimer中把聚合结果发往下游。
代码示意如下:
public class MyProcessFunction extends ProcessFunction {
MapState state;
public void open(Configuration parameters) throws Exception {
super.open(parameters);
state = getRuntimeContext().getMapState(new MapStateDescriptor(...));
}
public void processElement(Object value, Context ctx, Collector out) throws Exception {
// 触发计算的间隔
long interval = Time.minutes(5).toMilliseconds();
long timer = TimeWindow.getWindowStartWithOffset(ctx.timerService().currentProcessingTime(), 0, interval) + interval;
ctx.timerService().registerProcessingTimeTimer(timer);
// 根据消息更新State
state.put(...);
}
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
super.onTimer(timestamp, ctx, out);
// 根据State计算结果
Object result = ...;
out.collect(result);
}
}
小结
通过深入理解和熟练使用Assigner/Trigger/Evictor/Function以及Window State,可以很方便的解决业务中的一些需求问题。 以上是我的个人理解,希望大家多多探索,互相交流 : )
参考资料
Apache Flink Window:
https://ci.apache.org/projects/flink/flink-docs-stable/dev/stream/operators/windows.html
Flink performance issue with sliding time window:
https://stackoverflow.com/questions/51977741/flink-performance-issue-with-sliding-time-window
我就知道你“在看”