OpenTSDB介绍——基于Hbase的分布式的,可伸缩的时间序列数据库,而Hbase本质是列存储
OpenTSDB介绍
1.1、OpenTSDB是什么?主要用途是什么?
官方文档这样描述:OpenTSDB is a distributed, scalable Time Series Database (TSDB) written on top of HBase;
翻译过来就是,基于Hbase的分布式的,可伸缩的时间序列数据库。
主要用途,就是做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
OpenTSDB是基于HBase存储时间序列数据的一个开源数据库,但只是一个HBase的应用而已。也即是在HBase之上加了一层外壳,用于更好的处理时序数据库,真实的数据存储还是在HBase。
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能
1、OpenTSDB介绍
1.1、OpenTSDB是什么?主要用途是什么?
官方文档这样描述:OpenTSDB is a distributed, scalable Time Series Database (TSDB) written on top of HBase;
翻译过来就是,基于Hbase的分布式的,可伸缩的时间序列数据库。
主要用途,就是做监控系统;譬如收集大规模集群(包括网络设备、操作系统、应用程序)的监控数据并进行存储,查询。
1.2、介绍continue
存储到OpenTSDB的数据,是以metric为单位的,metric就是1个监控项,譬如服务器的话,会有CPU使用率、内存使用率这些metric;
OpenTSDB使用HBase作为存储,由于有良好的设计,因此对metric的数据存储支持到秒级别;
OpenTSDB支持数据永久存储,即保存的数据不会主动删除;并且原始数据会一直保存(有些监控系统会将较久之前的数据聚合之后保存)
2、OpenTSDB存储相关的概念
介绍这些概念的时候,我们先看一个实际的场景。
譬如假设我们采集1个服务器(hostname=qatest)的CPU使用率,发现该服务器在21:00的时候,CPU使用率达到99%
下面结合例子看看OpenTSDB存储的一些核心概念
1)Metric:即平时我们所说的监控项。譬如上面的CPU使用率
2)Tags:就是一些标签,在OpenTSDB里面,Tags由tagk和tagv组成,即tagk=takv。标签是用来描述Metric的,譬如上面为了标记是服务器A的CpuUsage,tags可为hostname=qatest
3)Value:一个Value表示一个metric的实际数值,譬如上面的99%
4)Timestamp:即时间戳,用来描述Value是什么时候的;譬如上面的21:00
5)Data Point:即某个Metric在某个时间点的数值。
Data Point包括以下部分:Metric、Tags、Value、Timestamp
上面描述的服务器在21:00时候的cpu使用率,就是1个DataPoint
保存到OpenTSDB的,就是无数个DataPoint。
下面讲一下,OpenTSDB是如何保存DataPoint的。
3、OpenTSDB的设计
还是以例子来说明,譬如保存这样的1个DataPoint:
metric:proc.loadavg.1m
timestamp:1234567890
value:0.42
tags:host=web42,pool=static
3.1、简单的设计
那么,如果是一般的设计,会怎么做呢,可能就是:RowKey=metric|timestamp|value|host=web42|pool=static,Column=v,Value=0.42
这是最简单的设计,那接下来看看,OpenTSDB是怎么做的吧。
3.2、OpenTSDB的方案
OpenTSDB使用HBase存储,核心的存储,是有两张表,tsdb和tsdb-uid
3.2.1、表tsdb
tsdb是保存数据的,看看该表的设计
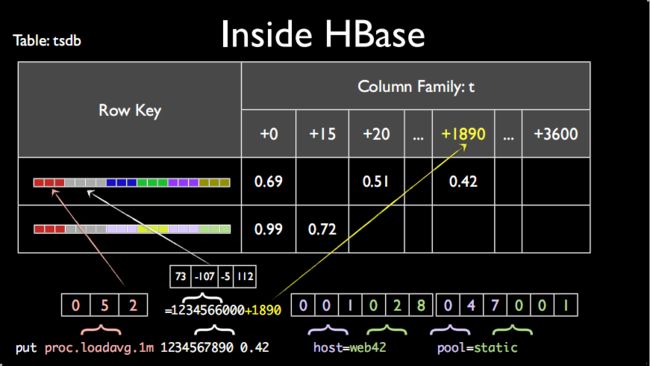
1)RowKey的设计
RowKey其实和上面的metric|timestamp|value|host=web42|pool=static类似;
但是区别是,OpenTSDB为了节省存储空间,将每个部分都做了映射。
在OpenTSDB里面有这样的映射,metric-->3字节整数、tagk-->3字节整数、tagv-->3字节整数
上图的映射关系为,proc.loadavg.1m-->052、host-->001、web42-->028、pool-->047、static-->001
2)column的设计
为了方便后期更进一步的节省空间。OpenTSDB将一个小时的数据,保存在一行里面。
所以上面的timestamp1234567890,会先模一下小时,得出1234566000,然后得到的余数为1890,表示的是它是在这个小时里面的第1890秒;
然后将1890作为column name,而0.42即为column value
3.2.2、表tsdb-uid

这里其实保存的就是一些metric,tagk,tagv的一些映射关系。
4、OpenTSDB的总体架构

Servers:就是服务器了,上面的C就是指Collector,可以理解为OpenTSDB的agent,通过Collector收集数据,推送数据;
TSD:TSD是对外通信的无状态的服务器,Collector可以通过TSD简单的RPC协议推送监控数据;另外TSD还提供了一个web UI页面供数据查询;另外也可以通过脚本查询监控数据,对监控数据做报警
HBase:TSD收到监控数据后,是通过AsyncHbase这个库来将数据写入到HBase;AsyncHbase是完全异步、非阻塞、线程安全的Hbase客户端,使用更少的线程、锁以及内存,可以提供更高的吞吐量,特别对于大量的写操作。
Opentsdb使用
1. 关于metric, tag name和tag value
1) opentsdb的每个时间序列必须有一个metric和一个或多个(tag name, tag value)对,每个时间序列每小时的数据保存为一行。
2) Opentsdb的metric, tag name和tag value各自的UID数量上限为2^24个,该值可以通过改变源代码重新编译后进行修改,最多可以扩展到8字节,即2^64个。不建议修改。
3) tag name和tag value的UID分配是完全独立的,例如,如果tag value的取值为整数2,那么这个值完全可以被多个tag name所使用,例如cpu=2, interface=2, hdd=2等。
4) 在设计系统时应该确保metric, tag name和tag value的可能取值在较小的范围内,因为它们的数量影响到查询速度。
5) 注意事项:
a. 减少它们的数量。
b. 为每个metric使用同类的tag name
c. 考虑系统常用的查询方式,选择合适的时间序列metric和tag
d. 每个metric的tag数量维持在5个以内,最多不超过8个。
6) 存储时间序列数据的时候,每个数据点要包含以下内容:metric,至少一对tag,时间戳(自1970年起的秒或毫秒),一个数值(整数或浮点数)。
7) 时间戳:一定是整数,且不超过13位。如果是13位表示毫秒,10位则表示秒。在一个序列中应该采用同样单位的时间戳(都是秒或者都是毫秒),混合不同单位的时间戳会引起查询缓慢,如无必要,应该用秒为单位,降低存储空间的消耗。
8) metric和tag的命名规则:大小写敏感,不允许空格,只允许以下字符:字母,数字,减号,下划线,点号,斜杠(/),长度不限,但是尽量短一些。
2. 数据点:
1) 只能由数字和小数点组成,如果没有小数点,则认为是整数,否则认为是浮点数。整数使用可变长度编码方式,最少1字节,最多8字节。浮点数为4字节单精度浮点数。由于浮点数是单精度类型,因此不支持需要精确值得浮点数,例如15.2会被保存为15.199999809265137
2) 写入数据时不必按照时间顺序写入,时间戳在后的数据可以先写入,再写入时间戳在前的数据。
3) 数据重复写入的问题:
a. 在同一小时内多次写入相同的数据不会有问题。
b. 如果设置和compaction操作,那么如果前后两次写入的数据类型不同,则在查询时一定会抛出异常。如果两次写入的数据类型相同,那么在该行还没有进行compaction操作之前,前面的数据将被覆盖掉。
4) 数据写入方式:
数据有三种写入方式:telnet, http post,用数据文件批量导入。
3. HBase的组建方式:
1) 测试或容量较低时可以采用单机模式,这时HBase使用本地文件系统作为存储。
2) 大数据量的生产环境应该采用正式的多机集群模式:Namenode双机备份,3台Zookeeper,HDFS节点采用JBOD存储,HBase的Region节点和HDFS数据节点共用。
各个节点之间采用千兆或万兆网络连接,集群位于一个数据中心。
4. 性能考虑:
1) 每个TSD进程的处理能力大约为每秒几千次写,可以使用多个TSD进程实现更高写入能力,前端采用DNS轮询或Varnish缓存实现负载均衡。当集群专用于opentsdb时,TSD进程可以和HBase的Region server位于同一台机器。
2) 可以将TSD进程配置为持久连接,这就可以阻止每次写入数据都经历建立和关闭连接的过程。
3) 关闭元数据和实时发布功能,因为它们极大地影响到系统性能。