FW-GAN: Flow-navigated Warping GAN for Video Virtual Try-on翻译
FW-GAN:用于虚拟视频试穿的流指导变换GAN
摘要:
在目前越来越受关注的基于图像的虚拟试衣系统之外,我们进一步开发了基于视频的虚拟试衣系统,它可以精确地精确地将衣服转移到人身上,并且能以任意姿势生成效果逼真的视频。直接采用现有的基于图像的方法往往无法生成自然逼真的连贯视频。在本工作中,我们提出流指导变换的生成对抗网络(FW-GAN),这是一种新的框架,通过学习来合成虚拟试衣视频,这种学习是基于一张人物图像、一张期望的服装图像,以及一系列的目标姿势。FW-GAN的目标是在处理姿势和服装的同时,合成连贯自然的视频。FW-GAN包括:(i)一个流指导融合模块,可以扭曲过去的帧以帮助合成,这个模块也被用于鉴别器,以帮助增强合成视频的连贯性和质量;(ii)一个warping net,来warp服装图像来改善服装纹理(iii)a parsing constraint loss解析约束损失,用来缓解由于不同姿态、多样的服装导致的/图像分割映射不对齐的问题。在新采集的数据集上进行的实验表明,FW-GAN能够合成高质量的虚拟试衣视频,在定性和定量的角度上都明显优于其他方法。
1 引言:
图像合成技术的出现极大地推动了虚拟试衣系统的发展[15,37],虚拟试衣系统在网上购物、电影制作、视频编辑等诸多应用领域都具有巨大的价值。然而,大多数的虚拟试衣方法都是基于单个图像的,基于视频的试衣方法还没有广泛的探索。本工作中,我们首次尝试解决这个问题。具体来说,给定一张人物图像,想要的衣服,和一系列的目标姿势,我们合成了一个逼真的视频,保留了人和衣服图像的distinct appearance。部分结果如图1所示,可见,此方法可以生成高质量的虚拟试衣视频,带有有说服力的细节。
现有的方法大多采用类似编码解码器的神经网络[15,37]来合成虚拟试穿图像。这些方法主要侧重以固定的姿势,通过替换其他服装合成人物形象,在无拘束的场景中进行虚拟试穿时,由于缺乏处理任意姿势和不同衣服的能力,无法生成逼真的视频。除了二维图像合成外,各种三维建模技术[22,27,30,43]也被开发用于虚拟试衣。但是,这些方法也只针对单个图像,还没有扩展到视频生成。此外,收集三维注释和构建三维模型需要大量的人工成本和大量的计算,这限制了虚拟实验在实际场景中的性能。特别是在视频序列中,人或衣服的图像往往包含各种视觉外观、视点,以及任意人体布局,由于姿势不同而产生。当前基于卷积的生成器在不借助任何外部结构化知识的情况下利用纠缠信息是不切实际的。此外,整个人体的不同姿势可能会导致严重的遮挡或某些身体部位的急剧的外观变化。此外,时空一致性对合成视频的视觉质量至关重要,这是现有的基于图像的合成方法所没有考虑的。

图1.此方法的一些结果。给定一个人的图像,所期望的衣服,和一系列的目标姿势,FW-GAN通过学习来自动把想要的衣服拟合到人身上,重组人的姿势,并输出逼真的视频。第一列是输入图像,第一行是姿势,其他列是每个姿势的虚拟试衣的结果。
为解决上述挑战,我们提出了一种FW-GAN,通过处理不同的姿势和多样的服装,实现虚拟试穿的可控视频合成。FW-GAN主要由三个部分组成:1)流导航模块,该模块使合成视频具有时空一致和高质量的视觉效果;2)一个warping net,用于估计the grid of transformation parameters,来warp所需的衣服,以适应人图像的相应区域;
- a human parsing constraint loss人解析约束损失,这约束了人体布局,加强全局视角的一致。特别地,光流[2]在FW-GAN中起了关键作用,使生成的视频连贯,光流warp扭曲前面帧的像素到新的帧,也用作flow-embedding鉴别器的输入条件,导致更逼真的帧和时空平滑的视频。此外,为了保留所需衣服的细节,使用了一个权重掩码,自适应地从warped desired clothes或合成的服装中选择像素值。
我们在新收集的数据集上进行了大量的实验,包括定量比较,消融研究,以及在Amazon Mechanical Turk平台上的人类感知研究。所提出的FW-GAN在合成任意姿态的虚拟实验视频的质量和数量上都大大优于现有的所有方法。我们工作的主要贡献包括:
·为了以一系列的姿态,一张人物图像,和需要的服装,生成高质量的合成虚拟试穿视频,我们提出了一个FW-GAN,将光流与warping net结合,分别warping帧和服装图像,这个方法可以保持全局和局部视角的细节。
·提出了一种融合有效流输入的流嵌入鉴别器,以提高时空连续性。
·使用解析约束损失函数作为结构约束的一种形式,明确地鼓励模型在不同姿态和不同服装下合成结果,与输入图像产生一致的部分配置。
2.相关工作
图像合成。生成对抗网络(GANs)[11]最近在图像合成方面取得了令人印象深刻的成果。为了捕获图像的分布,GANs能够生成与真实图像难以区分的假图像。条件生成对抗网络(cGANs)[26]通过在生成器和鉴别器的输入上附加条件,可以生成具有期望属性的样本,并在图像到图像的转换上显示了良好的结果[19,14,13,8,9,7]。对于人的形象生成,Lassner等人[23]提出了一个全身穿着衣服的人的生成模型。他们首先学习生成人类解析映射,然后学习了一个模型,将得到的片段转换成真实的图像,但是在这个方法中,样式属性是不可控的。Zhao等人[44]提出了一种图像生成模型,输入单一视图,生成多种视图的服装图像。[25, 9, 33, 7]在任意姿势条件下合成的人的图像。
虚拟试穿。以前的虚拟实验大多是基于计算机图形学的。Guan等人[12]设计了一个框架,在不考虑形状和姿势的情况下,在3D身体上合成衣服。Anna等人[18]提出了一种在虚拟镜像环境中进行实时可视化的服装动态跟踪和重放的方法。Sekine等人[30]开发了一种虚拟试衣方法,通过对用户的单一图像进行三维体型建模来调整衣服的图像。Pons-Moll等人的[27]解决了使用多部分的穿衣服的人体三维模型来捕捉全身运动的人身上的多件衣服的问题。[42,35]提出了一种从一张照片计算真实的人体三维模型的方法。也有一些基于图像生成模型的作品,旨在从真实的二维图像中合成感知正确的图像。Jetchev和Bergmann[21]引入了一个conditional analogy GAN来交换服装物品。然而,在推理过程中,他们需要原始物品人物和目标物品的成对图像,这可能不容易获得。VITON[15]使用了一个粗到细的框架,将人身上的原始时尚物品替换为所需的物品,并通过细化网络提高了合成图像的保真度。[37,8]解决了一个类似的问题,但它也旨在通过学习带有几何匹配模块的薄板样条变换来保持服装的特性。
视频合成。人们对视频合成进行了广泛的研究。针对具体问题,提出了视频图像修补[41]、视频matting and blening景物提取和混合[1,6]、视频超分辨率[31,32]。Chan等人提出了一种将舞蹈动作从一个人跳舞的源视频转移到一个目标的方法,前提是获得一个目标对象执行标准动作的持续几分钟的视频。他们的方法基于pix2pixHD[39]和最先进的位姿检测器OpenPose[3,34,40]。vid2vid[38]解决了基于GANs和时空对抗目标的视频-视频合成问题。视频技术具有巨大的应用潜力,但用于视频生成的虚拟试衣较少。
3.FW-GAN
3.1问题公式化。
给定一个姿势序列,一个人的图像,和一个衣服的图像,我们的目标是生成一个逼真的视频,其中的人穿着想要的衣服,人的运动是相同的姿势序列。形式上,设Ip、Ic、Pi分别代表人物图像输入、服装图像输入和姿态序列的第i帧。我们用S = {Pi}(i=1~n)表示输入的姿势序列,V = {Ri}(i=1~n)表示视频输出,其中N是帧的总数,Ri为输出视频的第i帧。我们的目标是学习映射(Ip, Ic, S) —>V。我们的训练数据集是![]() ,其中Vti,Ici,Ipi分别是第i个训练视频,服装图像输入,人员图像输入,n是样本的数量。
,其中Vti,Ici,Ipi分别是第i个训练视频,服装图像输入,人员图像输入,n是样本的数量。
3.2.姿势嵌入
在一副图像中一个人的姿态是由具有M个关节的2D骨骼构成的,P = (l1,…,lM)其中,li = (xi, yi)是图像中第i个关节的坐标。如[28]中的解释,坐标li可视为一个随机变量,其概率密度图pi由下式构成:
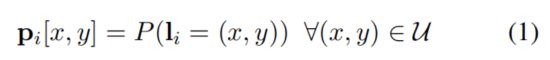
其中u为输入图像的坐标空间。那么姿势P就相当于将所有概率密度图P = (p1,…PM)。
3.3. 网络结构
3.3.1 生成器
提出了一种residual-like生成器,将光流和warping net结合起来,实现对时间信息、个人外貌信息和服装信息的同步采集。在形式上,我们的生成器基于一个条件GAN框架,该框架旨在捕获条件概率分布。我们将生成器表示为G. Ip表示person图像输入的变量。Ic为服装图像输入的变量,S = {Pi}(i=1~n)为位姿序列。然后是位姿序列S的位姿嵌入p,令![]() 表示G的输出,令V表示视频的地面真值。生成器G等于一个条件分布,这样我们就可以用G(V’ |p, Ic, Ip)来计算V’的概率。我们通过求解标准极大极小优化问题来优化G。形式上,目标函数由:
表示G的输出,令V表示视频的地面真值。生成器G等于一个条件分布,这样我们就可以用G(V’ |p, Ic, Ip)来计算V’的概率。我们通过求解标准极大极小优化问题来优化G。形式上,目标函数由:
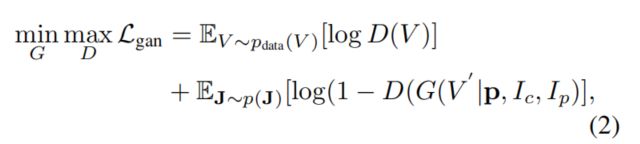
其中J = (p, Ic, Ip), D为鉴别器。
如图2所示,在生成器中,每个输入都有一个相应的编码器来提取特征映射。然后我们将这些特征映射连接并输入到两个独立的网络中,这两个网络都是由几个残差块组成的。残差网络的输出被输入解码器,解码器将产生光流和逼真的图像。

图2:FW-GAN的框架,FW-GAN由四个编码器和两个带残差块的解码器组成。FW-GAN首先预测流,然后warps the last past synthesized frame最后的上一幅合成帧。我们使用权重蒙版和网格蒙版来改进结果。
3.3.2鉴别器
多个文献[39,19,24]表明,在GAN训练中使用多个鉴别器可以减轻模型崩溃问题。同时,我们的任务要求每一帧的视觉质量和时间一致性。基于以上的观察,我们设计了两个鉴别器:帧鉴别器和流嵌入鉴别器。
帧鉴别器负责每一帧的视觉质量。换句话说,它确保每个生成的帧看起来都像真实的视频帧。帧鉴别器取4个输入,姿势序列S = {Pi}(i=1~n),人物外貌图像Ip,服装图像Ic,生成帧v。
元组(S、Ip、Ic)可以看作是帧鉴别器的条件输入。这个鉴别器应该输出1为真对((S, Ip, Ic), v)和0为假对((S, Ip, Ic), ve)。
Flow-embedding鉴别器负责相邻帧之间的时间一致性。我们认为随着相同的光流,连贯的生成帧应该具有连续真实帧的时间动态。就像帧鉴别器,flow-embedding鉴别器也会有条件的输入,光流。我们用O表示K个连续帧的K-1光流。正确的(O,v)对时,鉴别器输出1,假的(O,v)对时,鉴别器输出0。在实验中,我们发现鉴别器在虚拟试穿上工作很好。它使得生成的视频中,任何服装移动的更平滑。
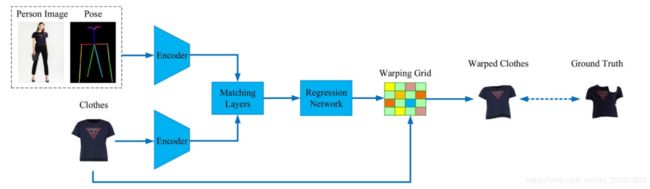
图3.Warping Net的框架。我们首先输入人物图像,目标姿势和需要的服装到编码器中,来分别提取特征映射。然后对Matching layers训练,来计算特征映射之间的关系。在matching layers之后是一个回归网络,输出转换映射的warping 网格。最后,我们使用这个warping网格来warp想要的衣服。
3.3.3 Warping Net
如图3所示,翘曲网络由两个编码器、matching layers和一个回归网络组成。设Ck表示一个卷积层,卷积核大小为4、步长为2,k个滤波器。让Rk 表示一个卷积层,核大小为3,步长为1,k个滤波器,然后是BatchNorm2d规范化和ReLU激活函数。设Lk表示一个线性函数输出k维。对于matching layers,我们直接使用GEOCNN[29]的相关映射计算。因此,编码器包含:C64、C128、C256、C512、R512、R512。回归网络包括:C512、C256、C128、C64、L32。
3.4学习目标函数
在本文中,FW-GAN的目标函数是几种不同损失的加权和。我们将在下面几节中详细介绍它们。
感知损失。为了获得高层和多样的特征,我们从预训练VGG网络和我们的对抗网络的鉴别器中提取了两个不同的特征,如[39,15]。然后,我们把它们结合起来表示这个工作的感知损失。
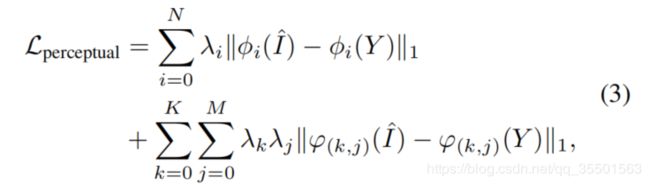
φi(I^)表示VGG网络中合成的图像I^的第i个特征映射,λi控制它们的权重。同样,ϕ(k, j) (I^ )是合成图像I^的第k个鉴别器的第j层特征映射,而λj表示第j层的权重和λk描述第k个鉴别器的权重。N为VGG的层数。K表示鉴别器的数量。M表示鉴别器的层数。
Parsing Consraint Loss解析约束损失。但是,上述目标没有考虑子部件的局部信息。为了进一步提高生成图像的质量,我们提出了一种新的parsing consistent loss解析一致性损失方法,使生成图像的部分结构与地面真值的部分结构相一致。设ψ是人类的解析器。我们要求合成图像和地面真值图像的解析结果相同。本文利用光网络[19]来训练人解析器。特别是,我们表示地面真值图像的解析结果为:F =ψ(Y) Rn*n*c, n是图像的高度/宽度和c是语义标签的数量。合成图像的输出被定义为P =ψ(I^)。对于每一个像素,解析结果应该是一样的,例如,像素参数(h, w)预测出的解析标签F (h, w) ∈Rc等于P (h, w)。由于将softmax损失在deep CNNs中是一个广泛使用的方法,deep CNNs量化两种概率之间的不同。因此,我们将解析一致性损失定义为:
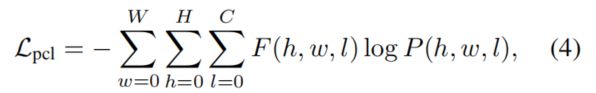
其中,C表示解析标签的数量,H表示图像的宽,W表示图像的宽。
3.4.1总体目标函数
此外,我们直接采用了一个来自FlowNet[10]的流损失作为Lflow。我们从pix2pix[20]的L1损失作为我们的网格损失Lgrid来迫使生成器从warped衣服中学习更多的像素。设Lgan为本文生成器的损失。综上所述,FW-GAN客观的描述了所有损失的加权和,如公式(5)所示。

超参数αi (i = 1、2、3、4、5)控制每个损失的权重。
4. 实验
在本节中,我们首先介绍了所提出的FW-GAN的实现细节。然后描述了评价生成视频质量的评价指标。接下来,我们将介绍baseline方法和收集的数据集。最后,我们与baseline方法和消融研究方法进行了可视化比较,并对定量和定性结果进行了分析。
4.1实现细节
在训练中,生成器和鉴别器二选一地更新,使用mini-batch大小4通过随机梯度求解程序,Adm优化器(β1 = 0.5,β2 = 0.999)。我们交替在1个步骤的优化生成器器,下1个步骤的优化鉴别器。初始学习率为0.0002。该实现基于四个Titan XP GPU上的Pytorch平台。经过30个epoch,可以得到高质量的结果。我们将用户研究部署在Amazon Mechanical Turk (AMT)平台上。
4.2数据集
我们构建了一个新的适合视频虚拟试衣的视频数据集VVT。我们首先收集了791个时装模特走秀的视频,这些视频的背景大多是白色的,这确保了我们能够专注于虚拟试穿的任务,并为我们的模特提供有说服力的评价。此外,我们移除了没有姿态结果或解析结果的噪声帧。每个视频的帧数主要在250到300之间。我们将视频分为一个训练集和一个测试集,分别有661个视频和130个视频。训练集和测试集的总帧数分别为159170和30931。我们还抓取了791张人物图片和791张衣服图片,并制作了每一个与人物图片和衣服图片相关的视频。我们还确保了每个人的图像与关联视频中的人不同,每个衣服图像与关联人图像中的衣服不同。因此,数据集中的一个样本由一个视频、一个人的图像和一个衣服的图像组成。

图4。与VVT数据集上的基线方法和消融方法进行可视化比较。从左开始的前三列是任务的输入。它们分别是人的形象、想要的服装和目标姿势。最后三列是由不同的方法生成的框架。最后一列的图像是根据我们提出的算法生成的。它看起来比其他两种算法更好
4.3。评价指标
Frechet Inception Distance(FID)[17]是评价图像合成质量的一个指标。在去除最后几层网络后,使用inception模型[36]作为特征提取器,分别从真实图像和合成图像中提取特征向量。然后计算真实图像中特征向量的均值μ和协方差矩阵的特征向量Σ。它还计算合成图像中特征向量的相同的统计量μ~和Σ~。然后计算支FID:![]() 。由于本论文针对视频合成问题,我们采用一种FID的变体,vid2vid[38],,它比原来的FID更适合于视频合成质量的评估。我们使用I3D[4]和3D-ResNeXt-101[16]作为我们的预训练的视频识别CNNs。我们将10帧作为一个视频剪辑,利用网络中最后一个平均池层的输出作为我们的特征向量。
。由于本论文针对视频合成问题,我们采用一种FID的变体,vid2vid[38],,它比原来的FID更适合于视频合成质量的评估。我们使用I3D[4]和3D-ResNeXt-101[16]作为我们的预训练的视频识别CNNs。我们将10帧作为一个视频剪辑,利用网络中最后一个平均池层的输出作为我们的特征向量。
4.4.Baselines
CP-VTON[37]是Wang等人提出的保留特征的虚拟试上网络。与VITON[15]相比,他们主要处理衣服的关键特征。很明显,CP-VTON[37]确实产生了具有更多关键特性的服装。在我们的实验中,我们在VVT数据集上对CP-VTON和VITON[15]进行了训练。在测试时,我们将它们应用到我们的任务中,这意味着我们将输入每一帧的位姿热图,而不是固定的位姿热图。在实验过程中,我们发现无论输入什么位姿的热图,其生成的图像几乎是相同的。然后,我们查看用于训练CP-VTON和VITON的数据集,发现该数据集的大多数图像几乎处于相同的姿势。
4.5定性结果
图6和图4显示了VVT数据集上的一些定性结果。结果表明,流模块和网格模块在实现真实感视频合成中起着重要的作用。没有网格,模块会导致合成模糊的低分辨率视频,衣服上的图案会丢失。没有流嵌入鉴别器网络(w/o)就无法获得时空平滑。图6展示了给定的人物图像、服装图像和目标姿态图像,FW-GAN能够合成我们期望的人物图像穿着想要的衣服,摆出想要的姿势。图7显示了我们的方法由于服装款式不常见而导致的一些失败结果。一些warping net的结果如图5所示。由此可见,所提出的warping net具有良好的性能。

图五:一些关于warping net的结果如第四栏所示。Warped的网格在第五栏。该Warping Net络预测变换映射参数,来warp衣服,使其具有与地面真值相似的真实感。

图6:FW-GAN在VVT数据集上的一些结果
4.6.定量结果
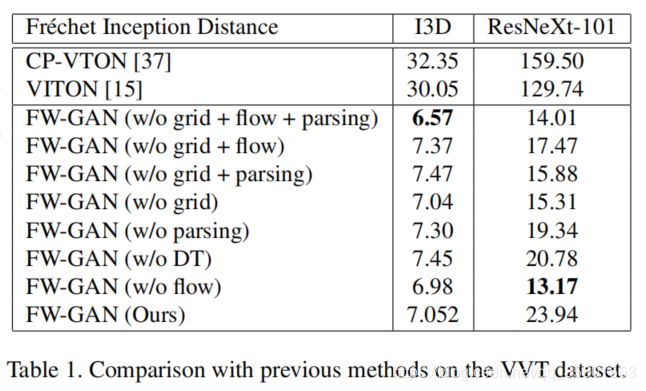
验证集中,我们使用学习得到的模型和baseline合成了3000个视频片段。每个视频片段由10个连续的帧组成。然后我们使用I3D和3D-ResNeXt-101从合成的视频片段和真实的视频片段中提取时空特征向量,并根据这些特征向量计算FID。表1报告了我们的方法的FID和baseline,表明我们的方法明显优于baseline。它也显示了在我们的模型上进行的详细的消融研究。虽然表1中的消融结果并没有显示出明显的提高,但我们认为这是因为FID使用深度卷积层来提取特征映射,会丢失一些对评价视频合成质量很重要的信息。如表1所示,最后一行VITON[15]的FID分数表明,与其他方法相比,提出的FA-GAN可以生成更加时空平滑的视频。数字越小表示性能越好。其中,w/o流表示无光流的FW-GAN。w/o parsing表示没有解析约束损失的FW-GAN。w/o grid表示FW-GAN没有warping网络。w/o DT表示没有流嵌入鉴别器。w/o (grid + flow + parsing) 表示没有这三个部分。。。。。(zjy:后面相同表示没有相应的部分)
5.人类感知研究
为了实现公平的视觉比较,我们将用户研究部署在Amazon Mechanical Turk (AMT)平台上。AMT是一个平台,它运营着一个需要人类智能的工作市场。我们精心设计了一个类似Wang等人[38]的主观A/B测试。与它们不同的是,我们让图像gif表示视频。我们展示了图像、包括人员图像,所需的服装图像和目标姿势的GIF图像,然后是两个打乱顺序的可选GIFs。所有的图片和GIFs都是256 x192的大小。AMT研究中大约有100名工人和1000个任务。作业分为有限时间作业和不限时间作业两种。工作人员被要求选择一个更好选项,姿势序列,所需的衣服,以及人的外观。结果如表2所示,报告了FW-GAN优于其他方法,获得了最高的人类偏好得分。

5.1消融研究
我们通过消融研究来探讨FW-GAN的重要成分的作用。结果见表1。没有网格模块、流模块和解析约束损失的这个模块,在I3D中获得了最好的FID分数,而没有流模块的模型在ResNeXt-101中获得了最好的FID分数。虽然我们的全模型没有得到最好的FID分数,但从图4可以看出,我们的全模型能够合成更逼真的图像,衣服图案也更清晰完整。在另一方面,FID使用最后一个池化层的输出作为特征向量,丢失了一些原始图像输入的信息,我们的消融模型中FID的分数相差不大。

图7:在VVT数据集上一些失败的结果,这是因为服装的款式不常见
6结论
提出了一种基于流导航的可生成对抗网络(FW-GAN)的视频虚拟试衣方案,该方案可生成任意姿态和各种服装的新的人物视频。为了达到良好的虚拟试穿质量,我们的FW-GAN主要包含三个部分:1) FW-GAN融合了光流和几何匹配,来分别对帧和服装图像进行warping,可以保留全局和局部视角的细节;2)提出一个流嵌入鉴别器,将有效流输入加入到鉴别器中,以提高时空平滑度3)解析约束损失函数作为结构约束的一种形式,明确鼓励模型在不同姿态和不同服装下综合结果,生成与输入图像一致的连贯部分。实验结果表明,所提出的FW-GAN方法在通过操控姿态和服装来合成虚拟试穿视频方面明显优于其他先进的方法。