影评情感分析
实战电影评论情感分析
该任务是对影评的数据做分类,积极还是消极的评论。
通过基于词频统计作为特征的分类模型 和 基于词向量作为特征的分类模型进行对比。
先介绍一个自然语言处理的常用工具NLTK,里面包含了语料库、停用词、搜索文本和计数词汇等等的常用操作。
首先读入数据并查看
df = pd.read_csv('../data/labeledTrainData.tsv', sep='\t', escapechar='\\')
print('Number of reviews: {}'.format(len(df)))
df.head()
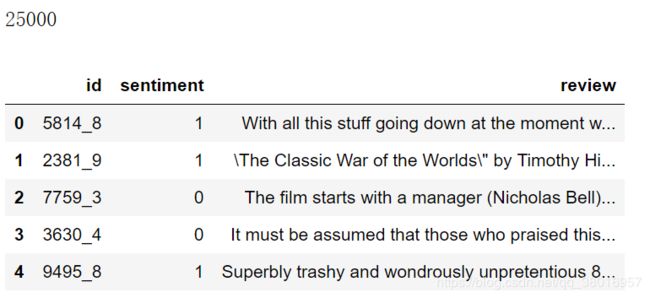
具体查看数据,其实数据从网页爬取,会有很多html的标签,下面对其进行处理
pd.set_option('display.max_colwidth',1000)
df.iloc[6]

建立模型之前是对影评数据做预处理,大概有以下环节:
- 去掉html标签 BeautifulSoup
- 移除标点 re.sub
- 转换大小写 lower().split()
- 切分成词/token
- 去掉停用词
- 重组为新的句子
def clean_text(text):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
words = [w for w in words if w not in eng_stopwords]
return ' '.join(words)
处理好后将数据添加入dataframe,再用sklearn的CountVectorizer对其进行词频统计
CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在第i个文本下的词频。即各个词语出现的次数,通过get_feature_names()可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果
抽取bag of words特征(用sklearn的CountVectorizer),统计词频,取top5000
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(max_features = 5000)
train_data_features = vectorizer.fit_transform(df.clean_review).toarray()
train_data_features.shape
构建好统计的词频特征后,通过交叉验证训练模型
*交叉验证:调参数的时候应设置随机种子为固定的,否则数据参数都在变,不好调参
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data_features,df.sentiment,test_size = 0.2, random_state = 0)
训练分类器
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
y_pred = LR_model.predict(X_test)
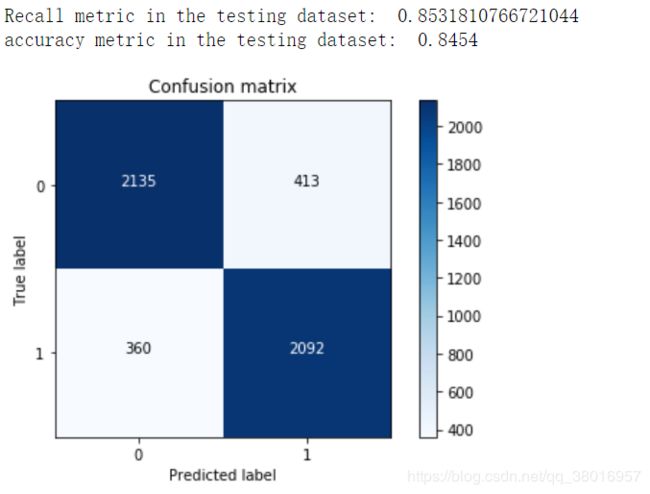
cnf_matrix = confusion_matrix(y_test,y_pred)
# 召回率:在负样本中能够找出多少占比,如负类有10个,模型能够识别这10个负类中8个为负类的,2个为正类,则召回率为8/10
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 精度:正确分类的占比
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
混肴矩阵,得到训练结果
import matplotlib.pyplot as plt
import itertools
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
以上就完成了基于词频统计作为特征的分类模型,下面继续完成基于词向量作为特征的分类模型的训练并进行对比
我们通过word2vec完成构建词向量的操作,因为word2vec模型的输入是一个个单词,所以需要用nltk的punkt分词工具
nltk.download('punkt')
import warnings
warnings.filterwarnings("ignore")
# 英文分词器
tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
# 划分句子、对句子进行清洗
def split_sentences(review):
raw_sentences = tokenizer.tokenize(review.strip())
sentences = [clean_text(s) for s in raw_sentences if s]
return sentences
sentences = sum(review_part.apply(split_sentences), [])
print('{} reviews -> {} sentences'.format(len(review_part), len(sentences)))
关于tokenizer.tokenize,在段落中分句子

nltk.word_tokenize(line)对line进行分词
sentences_list = []
for line in sentences:
# sentences_list为单个单词
sentences_list.append(nltk.word_tokenize(line))
下面用gensim构建word2vec模型:
word2vec模型参数
-
sentences:可以是一个list
-
sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
-
size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
-
window:表示当前词与预测词在一个句子中的最大距离是多少
-
alpha: 是学习速率
-
seed:用于随机数发生器。与初始化词向量有关。
-
min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
-
max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
-
workers参数控制训练的并行数。
-
hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
-
negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
-
iter: 迭代次数,默认为5
# 设定词向量训练的参数
num_features = 300 # Word vector dimensionality
min_word_count = 40 # Minimum word count
num_workers = 4 # Number of threads to run in parallel 并行建模
context = 10 # Context window size
model_name = '{}features_{}minwords_{}context.model'.format(num_features, min_word_count, context)
from gensim.models.word2vec import Word2Vec
model = Word2Vec(sentences_list, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context)
# If you don't plan to train the model any further, calling
# init_sims will make the model much more memory-efficient.
model.init_sims(replace=True)
# It can be helpful to create a meaningful model name and
# save the model for later use. You can load it later using Word2Vec.load()
model.save(os.path.join('..', 'models', model_name))
有了词向量,但现在做的任务是将影评句子分类,需将句子转换为向量,这里是将一句话中每个词的向量相加再取均值
from nltk.corpus import stopwords
eng_stopwords = set(stopwords.words('english'))
def clean_text(text, remove_stopwords=False):
text = BeautifulSoup(text, 'html.parser').get_text()
text = re.sub(r'[^a-zA-Z]', ' ', text)
words = text.lower().split()
if remove_stopwords:
words = [w for w in words if w not in eng_stopwords]
return words
def to_review_vector(review):
global word_vec
review = clean_text(review, remove_stopwords=True)
#print (review)
#words = nltk.word_tokenize(review)
word_vec = np.zeros((1,300))
for word in review:
#word_vec = np.zeros((1,300))
if word in model:
word_vec += np.array([model[word]])
#print (word_vec.mean(axis = 0))
# 这里是将一句话中每个词的向量相加再取均值
return pd.Series(word_vec.mean(axis = 0))
train_data_features = df.review.apply(to_review_vector)
train_data_features.head()

有了每一句话的向量,接下来就可以以每一句话的向量作为特征喂入模型进行分类
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data_features,df.sentiment,test_size = 0.2, random_state = 0)
LR_model = LogisticRegression()
LR_model = LR_model.fit(X_train, y_train)
y_pred = LR_model.predict(X_test)
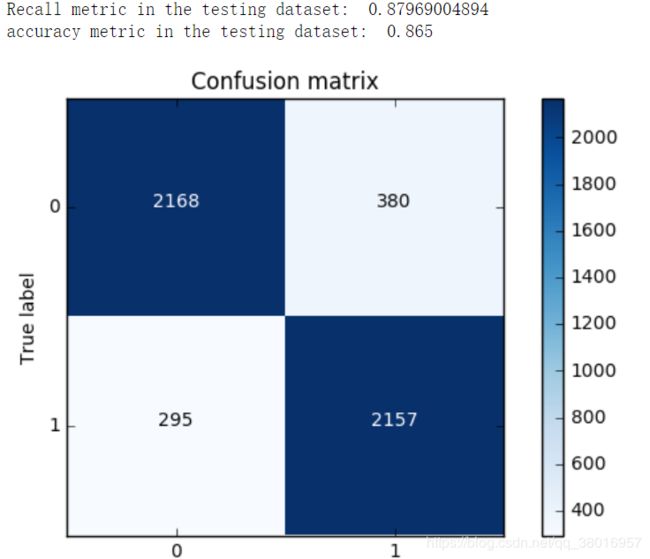
cnf_matrix = confusion_matrix(y_test,y_pred)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
print("accuracy metric in the testing dataset: ", (cnf_matrix[1,1]+cnf_matrix[0,0])/(cnf_matrix[0,0]+cnf_matrix[1,1]+cnf_matrix[1,0]+cnf_matrix[0,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
基于词向量作为特征的分类模型召回率和精度:
基于词频统计作为特征的分类模型 召回率和精度:
