AI实训(二):决策树与集成算法、贝叶斯算法
1. 决策树
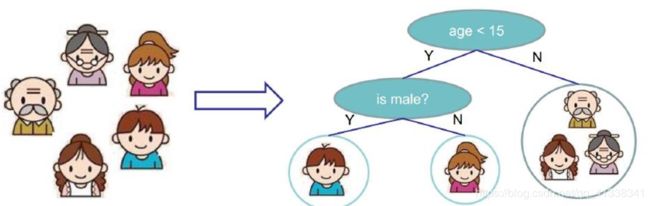
1.1 简单介绍
树模型:
- 决策树:从根节点开始一步步走到叶子节点(决策)
- 所有的数据最终都会落到叶子节点,既可以做分类也可以做回归
- 回归树:就是用树模型做回归问题,每一片叶子都输出一个预测值。预测值一般是该片叶子所含训练集元素输出的均值
树的组成
- 根节点:第一个选择点
- 非叶子节点与分支:中间过程
- 叶子节点:最终的决策结果
决策树的训练与测试
- 训练阶段:从给定的训练集构造出来一棵树
- 测试阶段:根据构造出来的树模型从上到下去走一遍就好了
一旦构造好了决策树,那么分类或者预测任务就很简单了,只需要走一遍就可以了。难点就在于如何构造出来一颗树。这就需要考虑如何从根节点开始选择特征,进行特征切分(选择节点)?
目标:借助一种衡量标准,来计算通过不同特征进行分支选择后的分类情况,找出来最好的那个当成根节点,以此类推。
衡量标准 —— 熵、信息增益
熵:熵是表示随机变量不确定性的度量
解释:说白了就是物体内部的混乱程度,比如杂货市场里面什么都有,那肯定混乱呀,专卖店里面只卖一个牌子的那就稳定多啦
公式: H ( X ) = − ∑ p i ∗ log p i , i = 1 , 2 , . . . , n H(X)=- \sum p_i * \log{p_i}, i=1,2,...,n H(X)=−∑pi∗logpi,i=1,2,...,n
解释: p i p_i pi 代表某一个类别的概率,类别越少,相应每个 p i p_i pi越大, − log p i - \log{p_i} −logpi 越小, − ∑ log p i -\sum \log{p_i} −∑logpi 越小,也就是H(x)越小,乘上 p i p_i pi是起到加权作用。
举个栗子: A集合[1,1,1,1,1,1,1,1,2,2],B集合[1,2,3,4,5,6,7,8,9,10]。显然A集合的熵值要低,因为A里面只有两种类别,相对稳定一些;而B中类别太多了,熵值就会大很多。
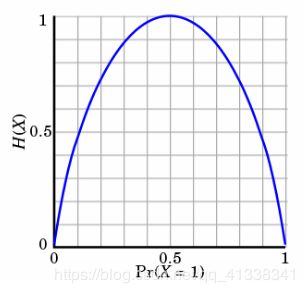
- 熵:不确定性越大,得到的熵值也就越大
- 当p=0或p=1时,H(p)=0,随机变量完全没有不确定性
- 当p=0.5时,H(p)=1,此时随机变量的不确定性最大
在分类任务中我们希望通过节点分支后数据类别的熵值变小,也就是能够越来越稳定,同类可以分在一个节点里。
信息增益:表示特征X使得类Y的不确定性减少的程度。(分类后的专一性,希望分类后的结果是同类在一起)
1.2 决策树构造实例
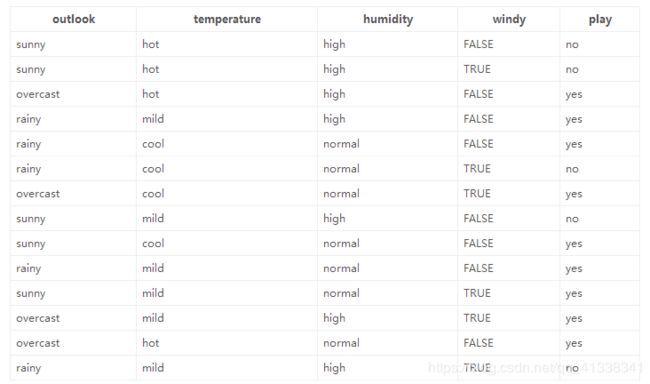
数据:14天打球情况
特征:4种环境变化(outlook、temperature、humidity、windy)
种类:是否打球(yes、no)
目标:构造决策树
划分方式:4种
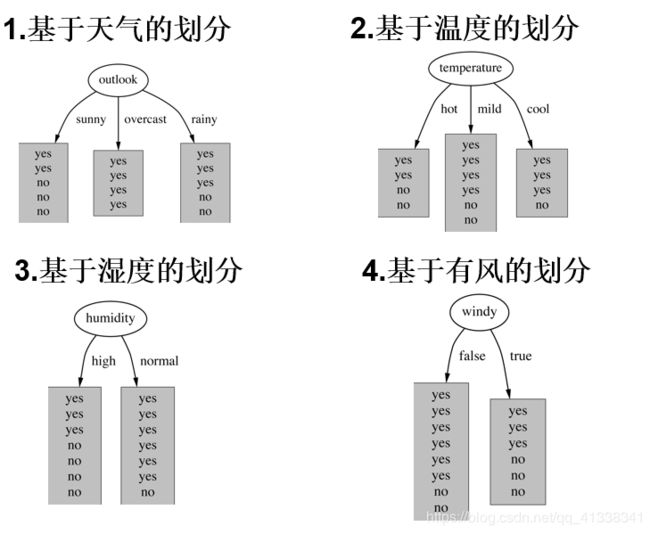
问题:谁当根节点呢?
依据:信息增益
在历史数据中(14天)有9天打球,5天不打球,所以此时的熵应为: − 9 14 log 2 9 14 − 5 14 log 2 5 14 = 0.0940 -\frac{9}{14} \log_2 {\frac{9}{14}}-\frac{5}{14} \log_2 {\frac{5}{14}}=0.0940 −149log2149−145log2145=0.0940
4个特征逐一分析,先从outlook特征开始:
Outlook = sunny时,熵值为0.971
Outlook = overcast时,熵值为0
Outlook = rainy时,熵值为0.971
根据数据统计,outlook取值分别为sunny、overcast、rainy的概率分别为:5/14, 4/14, 5/14
熵值计算: 5 / 14 ∗ 0.971 + 4 / 14 ∗ 0 + 5 / 14 ∗ 0.971 = 0.693 5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693 5/14∗0.971+4/14∗0+5/14∗0.971=0.693
信息增益:系统的熵值从原始的0.940下降到了0.693,增益为0.247
(gain(temperature)=0.029 gain(humidity)=0.152 gain(windy)=0.048)
同样的方式可以计算出其他特征的信息增益,那么我们选择最大的那个就可以啦,相当于是遍历了一遍特征,找出来了分类效果最好的那个特征。
1.3 决策树算法
ID3:信息增益。
如果在上面的打球数据中新增一个特征ID,该列数据为 [1,2,3,4,5,6,7,8,9,10,11,12,13,14],若基于ID特征进行划分,则划分后的熵为0,信息增益达到最大,但是这样的划分是没有实际意义的。
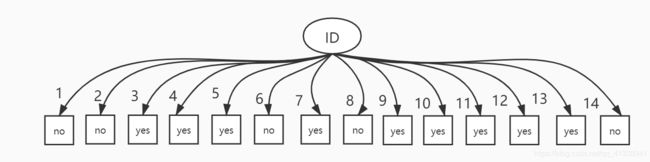
ID3存在的问题:有些特征的值比较离散,类别很多多,每个类别的样本个数又很少,这种特征会影响信息增益的计算。为了解决这种问题,引入了信息增益率。
C4.5:信息增益率。
信息增益率=信息增益/自身熵。
CART:使用GINI系数来当做衡量标准。
GINI系数: G i n i ( p ) = ∑ k = 1 K p k ( 1 − p k ) = 1 − ∑ k = 1 K p k 2 Gini(p)=\sum \limits_{k=1}^K p_k(1-p_k)=1-\sum \limits_{k=1}^Kp_k^2 Gini(p)=k=1∑Kpk(1−pk)=1−k=1∑Kpk2(和熵的衡量标准类似,计算方式不相同)
1.4 连续值处理
在处理数据时,某一列特征数据是连续值怎么办?
这就需要连续属性离散化,常用的离散化策略是二分法,这个技术也是C4.5中采用的策略。
1.5 剪枝策略
为什么要剪枝:决策树过拟合风险很大,理论上可以完全分得开数据。(想象一下,如果树足够庞大,每个叶子节点不就一个数据了嘛)
剪枝策略:预剪枝,后剪枝
- 预剪枝:边建立决策树边进行剪枝的操作(更实用)
- 限制深度,叶子节点个数,叶子节点样本数,信息增益量等
- 后剪枝:当建立完决策树后来进行剪枝操作(很少用)
- 通过一定的衡量标准: C α ( T ) = C ( T ) + α ∗ ∣ T l e a f ∣ C_α(T)=C(T)+α*|T_{leaf}| Cα(T)=C(T)+α∗∣Tleaf∣ (叶子节点越多,损失越大)
2. 集成算法(Ensemble learning)
目的:让机器学习效果更好,单个不行,群殴走起。
2.1 Bagging模型
- 全称: bootstrap aggregation
- 说白了就是并行训练多个分类器然后取平均: f ( x ) = 1 M ∑ m = 1 M f m ( x ) f(x)=\frac{1}{M} \sum \limits_{m=1}^M f_m(x) f(x)=M1m=1∑Mfm(x)
- 最典型的代表就是随机森林啦
- 随机:数据采样随机,特征选择随机(每棵决策树都是从训练集中随机抽取一部分来训练,同时也是从特征里面随机选择一部分来训练)。之所以要进行随机,是要保证泛化能力,如果树都一样,那就没意义了!
- 森林:很多个决策树并行放在一起
- KNN就不太适合用于Bagging模型,因为很难去随机让泛化能力变强。
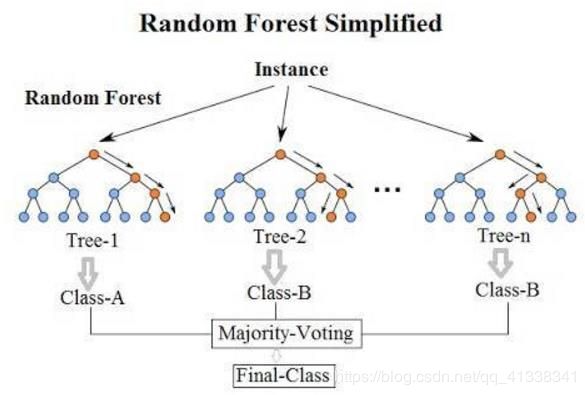
随机森林
由于二重随机性,使得每个树基本上都不会一样,最终的结果也会不一样。
构造树模型:

理论上越多的树效果会越好,但实际上基本超过一定数量就差不多上下浮动了。

随机森林优势:
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
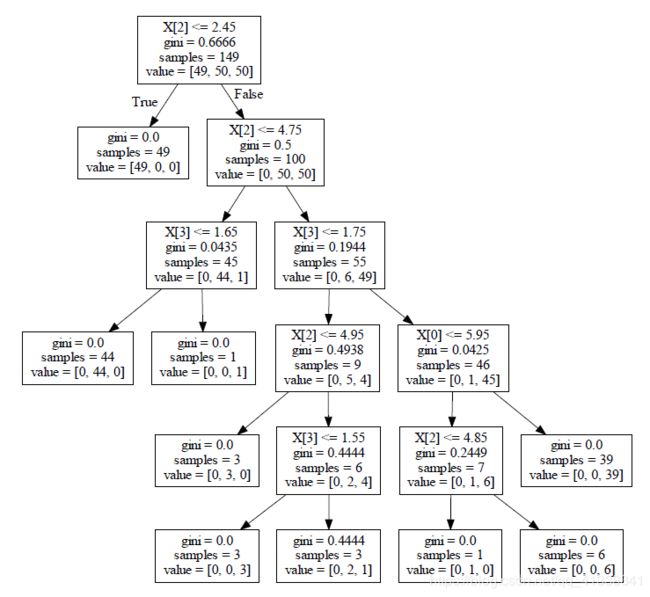
- 可以进行可视化展示,便于分析
- 容易做成并行化方法,速度比较快
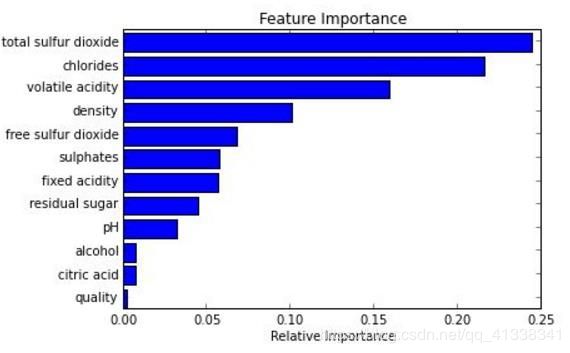
可视化展示,不同于神经网络,决策树可以很清晰地知道每个节点的内部情况。
2.2 Boosting模型
- 从弱学习器开始加强,通过加权来进行训练。
F m ( x ) = F m − 1 ( x ) + a r g m i n h ∑ i = 1 n L ( y i , F m − 1 ( x i ) + h ( x i ) ) F_m(x)=F_{m-1}(x)+argmin_h \sum \limits_{i=1}^n L(y_i,F_{m-1}(x_i)+h(x_i)) Fm(x)=Fm−1(x)+argminhi=1∑nL(yi,Fm−1(xi)+h(xi))(L是loss function。加入一棵树,要比原来强,也就是损失函数要降低) - 典型代表:AdaBoost, Xgboost
- Adaboost会根据前一次的分类效果调整数据权重
- 最终的结果:每个分类器根据自身的准确性来确定各自的权重,再合体
- 解释:如果某一个数据在这次分错了,那么在下一次我就会给它更大的权重
- 串行
Adaboost工作流程
- 每一次切一刀!
- 最终合在一起
- 弱分类器这就升级了!
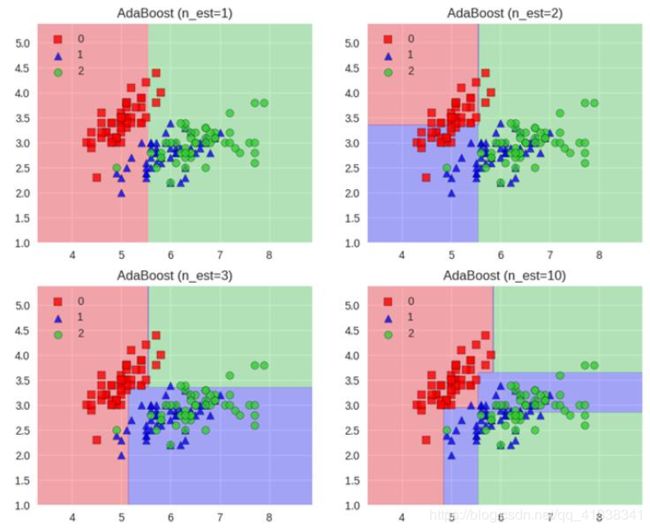
2.3 Stacking模型
- 聚合多个分类或回归模型(可以分阶段来做)
- 分阶段:第一阶段得出各自结果,第二阶段再用前一阶段结果训练
- 堆叠:很暴力,拿来一堆直接上(各种分类器都来了)
- 可以堆叠各种各样的分类器(KNN,SVM,RF等等)
- 堆叠在一起确实能使得准确率提升,但是速度是个问题。
- 竞赛刷分可能会用到,实际任务很少用这种模型。
3. 贝叶斯算法
正向概率:假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大
逆向概率:如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测
贝叶斯公式: P ( A ∣ B ) = P ( B ∣ A ) P ( A ) P ( B ) P(A|B)=\frac{P(B|A)P(A)}{P(B)} P(A∣B)=P(B)P(B∣A)P(A)
朴素贝叶斯假设特征之间是独立,互不影响。
3.1 例子
引例
假设学校里的男女比例是60%:40%,男生总是穿长裤,女生则一半穿长裤一半穿裙子。
正向概率:随机选取一个学生,他(她)穿长裤的概率和穿裙子的概率是多大?
逆向概率:迎面走来一个穿长裤的学生,你只看得见他(她)穿的是否长裤,而无法确定他(她)的性别,你能够推断出他(她)是女生的概率是多大吗?
假设学校里面人的总数是 U 个。
- 穿长裤的(男生): U ∗ P ( B o y ) ∗ P ( P a n t s ∣ B o y ) \color{blue} U * P(Boy) * P(Pants|Boy) U∗P(Boy)∗P(Pants∣Boy)
- P(Boy) 是男生的概率 = 60%
- P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的概率是多大,这里是 100% ,因为所有男生都穿长裤。
- 穿长裤的(女生): U ∗ P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) \color{red} U * P(Girl) * P(Pants|Girl) U∗P(Girl)∗P(Pants∣Girl)
求解:穿长裤的人里面有多少女生?
- 穿长裤总数: U ∗ P ( B o y ) ∗ P ( P a n t s ∣ B o y ) + U ∗ P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) \color{blue}{U * P(Boy) * P(Pants|Boy) }+ \color{red}{U * P(Girl) * P(Pants|Girl)} U∗P(Boy)∗P(Pants∣Boy)+U∗P(Girl)∗P(Pants∣Girl)
- 在穿长裤的前提下是女生:
P ( G i r l ∣ P a n t s ) = U ∗ P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) 穿 长 裤 总 数 = U ∗ P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) U ∗ P ( B o y ) ∗ P ( P a n t s ∣ B o y ) + U ∗ P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) = P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) P ( B o y ) ∗ P ( P a n t s ∣ B o y ) + P ( G i r l ) ∗ P ( P a n t s ∣ G i r l ) \begin{array}{lr} P(Girl|Pants) \\ \\ = \frac{\color{red}{U * P(Girl) * P(Pants|Girl)} }{穿长裤总数} & \\ \\ =\frac{\color{red}{U * P(Girl) * P(Pants|Girl)} }{\color{blue}{U * P(Boy) * P(Pants|Boy) }+ \color{red}{U * P(Girl) * P(Pants|Girl)}} & \\ \\ =\frac{\color{red}{P(Girl) * P(Pants|Girl)} }{\color{blue}{P(Boy) * P(Pants|Boy) }+ \color{red}{ P(Girl) * P(Pants|Girl)}} & \\ \end{array} P(Girl∣Pants)=穿长裤总数U∗P(Girl)∗P(Pants∣Girl)=U∗P(Boy)∗P(Pants∣Boy)+U∗P(Girl)∗P(Pants∣Girl)U∗P(Girl)∗P(Pants∣Girl)=P(Boy)∗P(Pants∣Boy)+P(Girl)∗P(Pants∣Girl)P(Girl)∗P(Pants∣Girl) - 化简:
分母其实就是 P(Pants)
分子其实就是 P(Pants, Girl)
拼写纠正实例
问题:我们看到用户输入了一个不在字典中的单词,我们需要去猜测:“这个家伙到底真正想输入的单词是什么呢?也就是 P(我们猜测他想输入的单词 | 他实际输入的单词)
用户实际输入的单词记为 D ( D 代表 Data ,即观测数据)
猜测1:P(h1 | D),猜测2:P(h2 | D),猜测3:P(h1 | D) …统一为:P(h | D)
可得,P(h | D) = P(h) * P(D | h) / P(D)
对于不同的具体猜测 h1、h2、h3 … ,P(D) 都是一样的,所以在比较P(h1 | D) 和 P(h2 | D) 的时候我们可以忽略这个常数P(D)。也就是 P ( h ∣ D ) ∝ P ( h ) ∗ P ( D ∣ h ) P(h | D) ∝ P(h) * P(D | h) P(h∣D)∝P(h)∗P(D∣h)
对于给定观测数据,一个猜测是好是坏,取决于“这个猜测本身独立的可能性大小(先验概率,Prior )”和“这个猜测生成我们观测到的数据的可能性大小。
贝叶斯方法计算: P(h) * P(D | h),P(h) 是特定猜测的先验概率,P(D|h)可以通过自己设定规则来计算,比如通过键盘上两个键之间的距离、编辑距离之类的。
比如用户输入tlp ,那到底是 top 还是 tip ?这个时候,当最大似然不能作出决定性的判断时,先验概率就可以插手进来给出指示——“既然你无法决定,那么我告诉你,一般来说 top 出现的程度要高许多,所以更可能他想打的是 top ”。
垃圾邮件过滤实例
问题:给定一封邮件,判定它是否属于垃圾邮件。D 来表示这封邮件,注意 D 由 N 个单词组成。我们用 h+ 来表示垃圾邮件,h- 表示正常邮件。
P ( h + ∣ D ) = P ( h + ) ∗ P ( D ∣ h + ) / P ( D ) P(h+|D) = P(h+) * P(D|h+) / P(D) P(h+∣D)=P(h+)∗P(D∣h+)/P(D)
P ( h − ∣ D ) = P ( h − ) ∗ P ( D ∣ h − ) / P ( D ) P(h- |D) = P(h- ) * P(D|h- ) / P(D) P(h−∣D)=P(h−)∗P(D∣h−)/P(D)
先验概率:P(h+) 和 P(h-) 这两个先验概率都是很容易求出来的,只需要计算一个邮件库里面垃圾邮件和正常邮件的比例就行了。
D 里面含有 N 个单词 d1, d2, d3,…,dn,P(D|h+) = P(d1,d2,…,dn|h+),P(d1,d2,…,dn|h+) 就是说在垃圾邮件当中出现跟我们目前这封邮件一模一样的一封邮件的概率是多大!
P(d1,d2,…,dn|h+) 扩展为: P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1,h+) * …
P(d1|h+) * P(d2|d1, h+) * P(d3|d2,d1, h+) * …假设 d i d_i di 与 d i − 1 d_{i-1} di−1 是完全条件无关的(朴素贝叶斯假设特征之间是独立,互不影响),简化为 P(d1|h+) * P(d2|h+) * P(d3|h+) * …
对于P(d1|h+) * P(d2|h+) * P(d3|h+) * …只要统计 di 这个单词在垃圾邮件中出现的频率即可。