使用freemarker导出html格式的word(续)
本文接上文(https://blog.csdn.net/u011099093/article/details/81010298)继续探讨导出word中携带图片问题。
在参考了博文http://www.cnblogs.com/liaofeifight/p/5484891.html后,改用.mht格式的模板进行编辑,首先介绍下整体思路:
1.准备好一个word(.doc格式),在里面编辑好自己想要的内容,把需要动态替换的部分 以参数替代,另存为.mht单网页;
2.对.mht单网页内容进行微调(该文件每行应该有长度限制,部分换行时会以=结束),作为第一个模板,程序替换参数后返回body区域的html文本,放入富文本编辑器进行编辑及插入图片;
3.将编辑器内容传至后台解析,分解为指定的几个部分,freemarker替换第二个.mht模板中的参数,导出为word;
一、准备mht模板
这里需要准备两个模板:
第一个模板是替换详细数据用的:根据需要编辑一个word,将需要替换的部分改为指定参数:

然后将word另存为但网页文件(mht),对mht文件进行微调,由于该文件会自动换行,同时在行末添加一个=连接符,所以主要将第一个
标签中不必要的=删掉,以便后面提取到编辑器中时样式不会乱。这里要注意复制模板内容到项目ftl文件中时部分行首会有空格,需要将所有行顶格,这是.ftl文件
部分的代码,中文都被自动转换为ascii十进制编码:
测试报告
一、
概要
对于导出Word
并携带图片的123
种方法探索,查
询到使用itext转换信息${num1!}条,使用openoffice转换信息${num2!}条,pageoffice转换信息${num3!}条,poi转换信息${num4!}条,freemarker转换信息${num5!}条。
(一)
表格展示
itext
openOffice
PageOffice
Poi
Freemarker
统计人
<#if listOfData??>
<#list listOfData as listData>
${listData.sfzh!}
${listData.xm!}
${listData.czje!}
${listData.czcs!}
${listData.rzje!}
${listData.rzcs!}
哈哈哈,成功了!
第二个模板是整体替换编辑器内容用的:
主要在第一个
内,图片base64替换部分,文档末尾图片引用处,三个部分进行替换: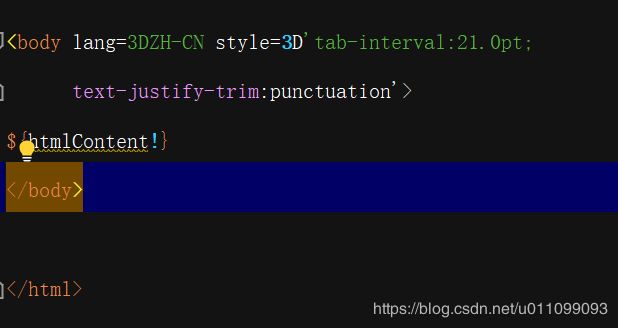
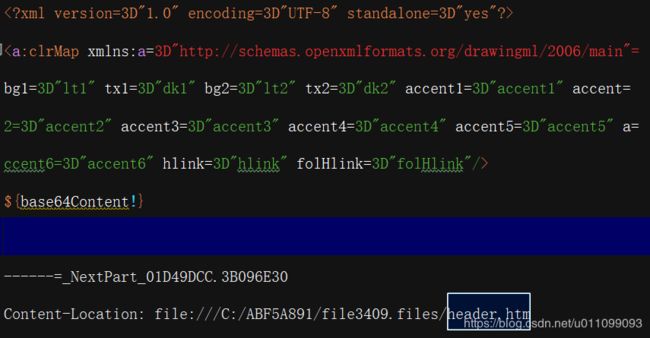
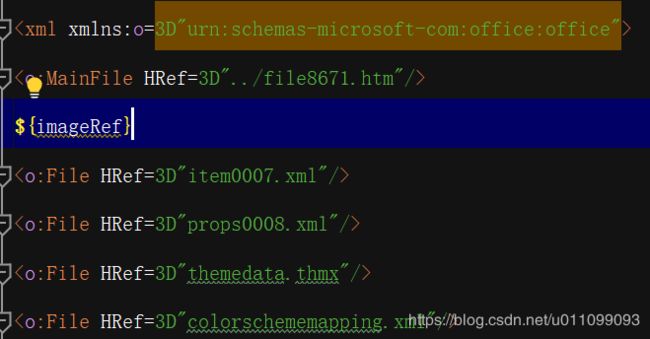
二、程序替换参数,获取替换后内容返回编辑器
/**
* 替换模板参数,提取替换参数的文档内容,返回前台的富文本编辑器中
* @param request
* @return
*/
@ResponseBody
@RequestMapping("getFtlContent")
public Map getFtlContent(HttpServletRequest request) {
HashMap result = new HashMap();
Map data = new HashMap<>();
data.put("num1", "123");
data.put("num2", "9723947");
data.put("num3", "6712");
data.put("num4", "792343200");
data.put("num5", "763");
List listOfData = new ArrayList();
Map data1 = new HashMap<>();
Map data2 = new HashMap<>();
data1.put("sfzh", "340120432232");
data2.put("sfzh", "340120432231");
data1.put("xm", "32423");
data2.put("xm", "234233");
data1.put("czje", "72823627");
data1.put("czje", "728236700");
data1.put("czcs", "873");
data2.put("czcs", "673");
data1.put("rzje", "80238409");
data2.put("rzje", "27934239");
data1.put("rzcs", "张三");
data2.put("rzcs", "李四");
listOfData.add(data1);
listOfData.add(data2);
data.put("listOfData", listOfData);
try {
Map parameters = this.getParameters(request);
ServletContext context = request.getServletContext();
String rootPath = request.getRealPath("/");
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
configuration.setServletContextForTemplateLoading(context, "/freemarkTemplate");
Template template = configuration.getTemplate("mhtTemplate.ftl", "utf-8");
String exportPath = rootPath + "export" + File.separator;
File file = new File(exportPath);
if (!file.exists()) {
file.mkdirs();
}
//这里要注意,如果没有设置输出流编码,则导出的文件可能不是utf-8格式,结果获取的文本会乱码
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(exportPath + "test.doc")),"utf-8"));
WordHtmlGeneratorHelper.handleAllObject(data);
template.process(data, out, ObjectWrapper.BEANS_WRAPPER);
Configuration configuration1 = new Configuration();
configuration1.setDefaultEncoding("utf-8");
configuration1.setServletContextForTemplateLoading(context, "/export");
Template t = configuration1.getTemplate("test.doc", "utf-8");
result.put("value", t.toString());
result.put("state", "success");
} catch (Exception e) {
result.put("state", "error");
e.printStackTrace();
}
return result;
} 这里有个地方需要注意,由于mht中对中文都是用ascii十进制码去替换的,所以在使用process()方法替换参数前需要将数据中的中文处理:
import java.lang.reflect.Field;
import java.util.*;
import com.jessica.word_mht.bean.ProjectPepole;
import org.apache.commons.beanutils.PropertyUtils;
import org.apache.commons.lang3.StringUtils;
import org.springframework.util.ReflectionUtils;
import org.springframework.util.ReflectionUtils.FieldCallback;
/**
* @Description:word 网页导出(单文件网页导出,mht文件格式)
* @author:LiaoFei
* @date :2016-3-28 上午11:17:38
* @version V1.0
*
*/
public class WordHtmlGeneratorHelper {
/**
* @Description: 将字符换成3Dus-asci,十进制Accsii码
* @param @param source
* @param @return
* @return String
* @throws
* @author:LiaoFei
* @date:2016-3-28 上午11:18:39
*/
public static String string2Ascii(String source){
if(source==null || source==""){
return null;
}
StringBuilder sb=new StringBuilder();
char[] c=source.toCharArray();
for(char item : c){
String itemascii="";
// 中文字符:
// 65281 !- 65295 /
// 65296 0 - 65305 9
// 65305 : - 65312 @
// 65313 A - 65338 Z
// 65339 [ - 65344 '
// 65345 a - 65370 z
// 65371 { - 65381 ·
// ‘ 8216 ’ 8217 ‚ 8218 ‛ 8219 “ 8220 ” 8221 „ 8222 ‟ 8223
// † 8224 ‡ 8225 • 8226 ‣ 8227 ․ 8228 ‥ 8229 … 8230 ‧ 8231
// 、 12289 。 12290 〃 12291 〄 12292 々 12293 〆 12294 〇 12295
// 〈 12296 〉 12297 《 12298 》 12299 「 12300 」 12301 『 12302 』 12303
// 【 12304 】 12305 〒 12306 〓 12307 〔 12308 〕 12309 〖 12310 〗 12311
// 〘 12312 〙 12313 〚 12314 〛 12315 〜 12316 〝 12317 〞 12318 〟 12319
// 英文字符:
// 33 ! - 47 /
// 48 0 - 57 9
// ...
// 65569 !- 65583 /
// 65584 0 - 65593 9
// 65594 : - 65600 @
// 65601 A - 65626 Z
// 65627 [ - 65632 `
// 65633 a - 65658 z
// 65659 { - 65662 ~
// “”&¥。‘’《》%
// 8220-8221-38-65509-12290-8216-8217-12298-12299-37
if((item>=19968 && item<40623)||
//部分中文标点
(item>=65281&&item<65382)||
(item>=8216&&item<8222)||
(item>=12289&&item<12317)){
itemascii="&#"+(item & 0xffff)+";";
}else{
itemascii=item+"";
}
sb.append(itemascii);
}
return sb.toString();
}
/**
* @Description: 将object的所有属性值转成成3Dus-asci编码值
* @param @param object
* @param @return
* @return T
* @throws
* @author:LiaoFei
* @date:2016-3-29 下午2:56:24
*/
public static T handleObject2Ascii(final T toHandleObject){
class myFieldsCallBack implements FieldCallback{
@Override
public void doWith(Field f) throws IllegalArgumentException,
IllegalAccessException {
if(f.getType().equals(String.class)){
//如果是字符串类型
f.setAccessible(true);
String oldValue=(String)f.get(toHandleObject);
if(!StringUtils.isEmpty(oldValue)){
f.set(toHandleObject, string2Ascii(oldValue));
}
//f.setAccessible(false);
}
}
}
ReflectionUtils.doWithFields(toHandleObject.getClass(), new myFieldsCallBack());
return toHandleObject;
}
public static List handleObjectList2Ascii(final List toHandleObjects){
for (T t : toHandleObjects) {
handleObject2Ascii(t);
}
return toHandleObjects;
}
public static void handleAllObject(Map dataMap){
//去处理数据
for (Map.Entry entry : dataMap.entrySet()){
Object item=entry.getValue();
//判断object是否是primitive type
if(isPrimitiveType(item.getClass())){
if(item.getClass().equals(String.class)){
item=WordHtmlGeneratorHelper.string2Ascii((String)item);
entry.setValue(item);
}
}else if(isCollection(item.getClass())){
for (Object itemobject : (Collection)item) {
if(isMap(itemobject.getClass())){
WordHtmlGeneratorHelper.handleAllObject((Map)itemobject);
}else{
WordHtmlGeneratorHelper.handleObject2Ascii(itemobject);
}
}
}else{
WordHtmlGeneratorHelper.handleObject2Ascii(item);
}
}
}
public static String joinList(List list,String join ){
StringBuilder sb=new StringBuilder();
for (String t : list) {
sb.append(t);
if(!StringUtils.isEmpty(join)){
sb.append(join);
}
}
return sb.toString();
}
private static boolean isPrimitiveType(Class clazz){
return clazz.isEnum() ||
CharSequence.class.isAssignableFrom(clazz) ||
Number.class.isAssignableFrom(clazz) ||
Date.class.isAssignableFrom(clazz);
}
private static boolean isCollection(Class clazz){
return Collection.class.isAssignableFrom(clazz);
}
private static boolean isMap(Class clazz){
return Map.class.isAssignableFrom(clazz);
}
} 前台获取:
function initReport() {
$('#saveEdit').hide();
$('#insertImg').hide();
$('#exitEdit').hide();
$('#exportWord').show();
$('#editModel').show()
$('#docDiv').show();
UE.getEditor('editor').setHide();
$.ajax({
url:_ctx+'/report/common/getFtlContent',
data:{},
type:'post',
dataType:'json',
success:function (obj) {
var value=obj.value;
//只获取第一个中的内容
var temp=value.split('');
var temp1=temp[1].split('');
// var content=''+temp1[0]+'';
//去除mht模板中的3D字符
var content=temp1[0].replace(/=3D/g,'=');
// console.info(content)
$('#docDiv').empty().append(content)
},error:function () {
alert('error')
}
})
}三、插入图片,处理html内容,导出word
前台获取编辑器内容:
function exportWordFunc(){
var content=UE.getEditor('editor').getContent();
$.ajax({
url:_ctx+'/report/common/exportHtml',
data:{content:content},
type:'post',
dataType:'json',
success:function (obj) {
var filepath=obj.filepath;
console.info(filepath)
if(filepath!=null){
var encode2=encodeURIComponent(filepath);
console.info(encode2)
console.log(_ctx+'/report/common/downloadWord?'+(new Date().getTime())+"&filepath="+encode2)
window.location.href=_ctx+'/report/common/downloadWord?'+(new Date().getTime())+"&filepath="+encode2;
}else{
alert("下载word失败!");
}
}
})
}后台处理:
/**
* 处理前台获取的编辑器内容,导出为word
* @param request
* @param content
* @return
*/
@ResponseBody
@RequestMapping("exportHtml")
public Map exportHtml(HttpServletRequest request, String content) {
Map resultMap = new HashMap<>();
try {
//遍历獲取所有參數
Map parameters = this.getParameters(request);
// ==================================================
// 处理前台获取的富文本html
// content = content.replace("=", "=3D");
RichHtmlHandler handler = new RichHtmlHandler(content);
// handler.setDocSrcLocationPrex("file:///C:/70ED9946");
handler.setDocSrcLocationPrex("file:///C:/ABF5A891");
// handler.setDocSrcParent("file9462.files");
handler.setDocSrcParent("file3409.files");
// handler.setNextPartId("01D189BB.30229F00");
handler.setNextPartId("01D49DCC.3B096E30");
handler.setShapeidPrex("_x56fe__x7247__x0020");
handler.setSpidPrex("_x0000_i");
handler.setTypeid("#_x0000_t75");
handler.handledHtml(true, request);
// 获取处理为mht内容的html
Map data=new HashMap<>();
data.put("htmlContent",handler.getHandledDocBodyBlock());
if (handler.getDocBase64BlockResults() != null
&& handler.getDocBase64BlockResults().size() > 0) {
StringBuffer sb=new StringBuffer();
for (String item : handler.getDocBase64BlockResults()) {
sb.append(item+"\n");
}
data.put("base64Content",sb.toString());
}
if (handler.getXmlImgRefs() != null
&& handler.getXmlImgRefs().size() > 0) {
StringBuffer sb=new StringBuffer();
for (String item : handler.getXmlImgRefs()) {
sb.append(item + "\n");
}
data.put("imageRef",sb.toString());
}
// 模板替换
ServletContext context = request.getServletContext();
String rootPath = request.getRealPath("/");
Configuration configuration = new Configuration();
configuration.setDefaultEncoding("utf-8");
configuration.setServletContextForTemplateLoading(context, "/freemarkTemplate");
Template template = configuration.getTemplate("blankMht.ftl", "utf-8");
String exportPath = rootPath + "export" + File.separator;
File file1 = new File(exportPath);
if (!file1.exists()) {
file1.mkdirs();
}
Writer out = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(new File(exportPath + "test1.doc"))));
// WordHtmlGeneratorHelper.handleAllObject(data);
template.process(data, out, ObjectWrapper.BEANS_WRAPPER);
// ==================================================
String filepath = exportPath + "test1.doc";
resultMap.put("filepath", filepath);
return resultMap;
} catch (Exception e) {
e.printStackTrace();
} finally {
}
return null;
} 这里有一个需要注意的点:就是RichHtmlHandler对象设置的那几个属性值与模板中的对应属性值一定要对应,否则结果不正确!
RichHtmlHandler类是将html内容处理为.mht可以接受的几部分内容的工具类:
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import com.jessica.word_mht.util.JFileUtils;
import com.jessica.word_mht.util.RequestResponseContext;
import com.jessica.word_mht.util.UUIDUtils;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import javax.servlet.http.HttpServletRequest;
//import sun.tools.tree.NewArrayExpression;
/**
* @Description:富文本Html处理器,主要处理图片及编码
* @author:LiaoFei
* @date :2016-3-28 下午4:13:21
* @version V1.0
*
*/
public class RichHtmlHandler {
private Document doc = null;
private String html;
private String docSrcParent = "";
private String docSrcLocationPrex = "";
private String nextPartId;
private String shapeidPrex;
private String spidPrex;
private String typeid;
private String handledDocBodyBlock;
private List docBase64BlockResults = new ArrayList();
private List xmlImgRefs = new ArrayList();
public String getDocSrcLocationPrex() {
return docSrcLocationPrex;
}
public void setDocSrcLocationPrex(String docSrcLocationPrex) {
this.docSrcLocationPrex = docSrcLocationPrex;
}
public String getNextPartId() {
return nextPartId;
}
public void setNextPartId(String nextPartId) {
this.nextPartId = nextPartId;
}
public String getHandledDocBodyBlock() {
String raw= WordHtmlGeneratorHelper.string2Ascii(doc.getElementsByTag("body").html());
return raw.replace("=3D", "=").replace("=", "=3D");
}
public String getRawHandledDocBodyBlock() {
String raw= doc.getElementsByTag("body").html();
return raw.replace("=3D", "=").replace("=", "=3D");
}
public List getDocBase64BlockResults() {
return docBase64BlockResults;
}
public List getXmlImgRefs() {
return xmlImgRefs;
}
public String getShapeidPrex() {
return shapeidPrex;
}
public void setShapeidPrex(String shapeidPrex) {
this.shapeidPrex = shapeidPrex;
}
public String getSpidPrex() {
return spidPrex;
}
public void setSpidPrex(String spidPrex) {
this.spidPrex = spidPrex;
}
public String getTypeid() {
return typeid;
}
public void setTypeid(String typeid) {
this.typeid = typeid;
}
public String getDocSrcParent() {
return docSrcParent;
}
public void setDocSrcParent(String docSrcParent) {
this.docSrcParent = docSrcParent;
}
public String getHtml() {
return html;
}
public void setHtml(String html) {
this.html = html;
}
public RichHtmlHandler(String html) {
doc = Jsoup.parse( wrappHtml(html));
}
public void re_init(String html){
doc=null;
doc = Jsoup.parse(wrappHtml(html));
docBase64BlockResults.clear();
xmlImgRefs.clear();
}
/**
* @Description: 获得已经处理过的HTML文件
* @param @return
* @return String
* @throws IOException
* @throws
* @author:LiaoFei
* @date:2016-3-28 下午4:16:34
*/
public void handledHtml(boolean isWebApplication, HttpServletRequest request)
throws IOException {
Elements imags = doc.getElementsByTag("img");
if (imags == null || imags.size() == 0) {
// 返回编码后字符串
return;
//handledDocBodyBlock = WordHtmlGeneratorHelper.string2Ascii(html);
}
// 转换成word mht 能识别图片标签内容,去替换html中的图片标签
for (Element item : imags) {
// 把文件取出来
String src = item.attr("src").replace("3D\"","").replace("\"","");
String srcRealPath = src;
if (isWebApplication) {
// String contentPath= RequestResponseContext.getRequest().getContextPath();
String contentPath= request.getContextPath();
if(!StringUtils.isEmpty(contentPath)){
if(src.startsWith(contentPath)){
src=src.substring(contentPath.length());
}
}
// srcRealPath = RequestResponseContext.getRequest().getSession()
// .getServletContext().getRealPath(src);
srcRealPath = request.getSession()
.getServletContext().getRealPath(src);
}
File imageFile = new File(srcRealPath);
String imageFielShortName = imageFile.getName();
String fileTypeName = JFileUtils.getFileSuffix(srcRealPath);
String docFileName = "image" + UUIDUtils.get32UUID() + "."
+ fileTypeName;
String srcLocationShortName = docSrcParent + "/" + docFileName;
String styleAttr = item.attr("style"); // 样式
//高度
String imagHeightStr=item.attr("height");;
if(StringUtils.isEmpty(imagHeightStr)){
imagHeightStr = getStyleAttrValue(styleAttr, "height");
}
//宽度
String imagWidthStr=item.attr("width");;
if(StringUtils.isEmpty(imagHeightStr)){
imagHeightStr = getStyleAttrValue(styleAttr, "width");
}
imagHeightStr = imagHeightStr.replace("px", "");
imagWidthStr = imagWidthStr.replace("px", "");
if(StringUtils.isEmpty(imagHeightStr)){
//去得到默认的文件高度
imagHeightStr="0";
}
if(StringUtils.isEmpty(imagWidthStr)){
imagWidthStr="0";
}
int imageHeight = Integer.parseInt(imagHeightStr);
int imageWidth = Integer.parseInt(imagWidthStr);
// 得到文件的word mht的body块
String handledDocBodyBlock = WordImageConvertor.toDocBodyBlock(srcRealPath,
imageFielShortName, imageHeight, imageWidth,styleAttr,
srcLocationShortName, shapeidPrex, spidPrex, typeid);
item.parent().append(handledDocBodyBlock);
item.remove();
// 去替换原生的html中的imag
String base64Content = WordImageConvertor
.imageToBase64(srcRealPath);
String contextLoacation = docSrcLocationPrex + "/" + docSrcParent
+ "/" + docFileName;
String docBase64BlockResult = WordImageConvertor
.generateImageBase64Block(nextPartId, contextLoacation,
fileTypeName, base64Content);
docBase64BlockResults.add(docBase64BlockResult);
String imagXMLHref = " 另外依赖的工具类:
import java.awt.image.BufferedImage;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.math.BigDecimal;
import javax.imageio.ImageIO;
import com.jessica.word_mht.util.UUIDUtils;
import org.apache.commons.codec.binary.Base64;
import sun.misc.BASE64Encoder;
/**
* @Description:WORD 文档图片转换器
* @author:LiaoFei
* @date :2016-3-28 上午11:21:06
* @version V1.0
*
*/
public class WordImageConvertor {
//private static Const WORD_IMAGE_SHAPE_TYPE_ID="";
/**
* @Description: 将图片转换成base64编码的字符串
* @param @param imageSrc 文件路径
* @param @return
* @return String
* @throws IOException
* @throws
* @author:LiaoFei
* @date:2016-3-28 上午11:22:26
*/
public static String imageToBase64(String imageSrc) throws IOException{
//判断文件是否存在
File file=new File(imageSrc);
if(!file.exists()){
throw new FileNotFoundException("文件不存在!");
}
StringBuilder pictureBuffer = new StringBuilder();
FileInputStream input=new FileInputStream(file);
ByteArrayOutputStream out = new ByteArrayOutputStream();
//读取文件
//BufferedInputStream bi=new BufferedInputStream(in);
Base64 base64=new Base64();
BASE64Encoder encoder=new BASE64Encoder();
byte[] temp = new byte[1024];
for(int len = input.read(temp); len != -1;len = input.read(temp)){
out.write(temp, 0, len);
//out(pictureBuffer.toString());
//out.reset();
}
pictureBuffer.append(new String( base64.encodeBase64Chunked(out.toByteArray())));
//pictureBuffer.append(encoder.encodeBuffer(out.toByteArray()));
/*byte[] data=new byte[input.available()];
input.read(data);
pictureBuffer.append(base64.encodeBase64String (data));*/
input.close();
/*BASE64Decoder decoder=new BASE64Decoder();
FileOutputStream write = new FileOutputStream(new File("c:\\test2.jpg"));
//byte[] decoderBytes = decoder.decodeBuffer (pictureBuffer.toString());
byte[] decoderBytes = base64.decodeBase64(pictureBuffer.toString());
write.write(decoderBytes);
write.close();*/
return pictureBuffer.toString();
}
public static String toDocBodyBlock(
String imageFilePath,
String imageFielShortName,
int imageHeight,
int imageWidth,
String imageStyle,
String srcLocationShortName,
String shapeidPrex,String spidPrex,String typeid){
//shapeid
//mht文件中针对shapeid的生成好像规律,其内置的生成函数没法得知,但是只要保证其唯一就行
//这里用前置加32位的uuid来保证其唯一性。
String shapeid=shapeidPrex;
shapeid+= UUIDUtils.get32UUID();
//spid ,同shapeid处理
String spid=spidPrex;
spid+=UUIDUtils.get32UUID();
/*  */
StringBuilder sb1=new StringBuilder();
sb1.append(" ");
//以下是为了兼容游览器显示时的效果,但是如果是纯word阅读的话没必要这么做。
/* StringBuilder sb2=new StringBuilder();
sb2.append(" ");
sb2.append("
*/
StringBuilder sb1=new StringBuilder();
sb1.append(" ");
//以下是为了兼容游览器显示时的效果,但是如果是纯word阅读的话没必要这么做。
/* StringBuilder sb2=new StringBuilder();
sb2.append(" ");
sb2.append(" ");
sb2.append("");*/
//return sb1.toString()+sb2.toString();
return sb1.toString();
}
/**
* @Description: 生成图片的base4块
* @param @param nextPartId
* @param @param contextLoacation
* @param @param ContentType
* @param @param base64Content
* @param @return
* @return String
* @throws
* @author:LiaoFei
* @date:2016-3-28 下午4:02:05
*/
public static String generateImageBase64Block(String nextPartId,String contextLoacation,
String fileTypeName,String base64Content){
/*--=_NextPart_01D188DB.E436D870
Content-Location: file:///C:/70ED9946/file9462.files/image001.jpg
Content-Transfer-Encoding: base64
Content-Type: image/jpeg
base64Content
*/
StringBuilder sb=new StringBuilder();
sb.append("\n");
sb.append("\n");
sb.append("------=_NextPart_"+nextPartId);
sb.append("\n");
sb.append("Content-Location: "+ contextLoacation);
sb.append("\n");
sb.append("Content-Transfer-Encoding: base64");
sb.append("\n");
sb.append("Content-Type: " + getImageContentType(fileTypeName));
sb.append("\n");
sb.append("\n");
sb.append(base64Content);
return sb.toString();
}
private static String generateImageBodyBlockStyleAttr(String imageFilePath, int height,int width){
StringBuilder sb=new StringBuilder();
BufferedImage sourceImg;
try {
sourceImg = ImageIO.read(new FileInputStream(imageFilePath));
if(height==0){
height=sourceImg.getHeight();
}
if(width==0){
width=sourceImg.getWidth();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//将像素转化成pt
BigDecimal heightValue=new BigDecimal(height*12/16);
heightValue= heightValue.setScale(2, BigDecimal.ROUND_HALF_UP);
BigDecimal widthValue=new BigDecimal(width*12/16);
widthValue= widthValue.setScale(2, BigDecimal.ROUND_HALF_UP);
sb.append("height:"+heightValue +"pt;");
sb.append("width:"+widthValue +"pt;");
sb.append("visibility:visible;");
sb.append("mso-wrap-style:square; ");
return sb.toString();
}
private static String getImageContentType(String fileTypeName){
String result="image/jpeg";
//http://tools.jb51.net/table/http_content_type
if(fileTypeName.equals("tif") || fileTypeName.equals("tiff")){
result="image/tiff";
}else if(fileTypeName.equals("fax")){
result="image/fax";
}else if(fileTypeName.equals("gif")){
result="image/gif";
}else if(fileTypeName.equals("ico")){
result="image/x-icon";
}else if(fileTypeName.equals("jfif") || fileTypeName.equals("jpe")
||fileTypeName.equals("jpeg") ||fileTypeName.equals("jpg")){
result="image/jpeg";
}else if(fileTypeName.equals("net")){
result="image/pnetvue";
}else if(fileTypeName.equals("png") || fileTypeName.equals("bmp") ){
result="image/png";
}else if(fileTypeName.equals("rp")){
result="image/vnd.rn-realpix";
}else if(fileTypeName.equals("rp")){
result="image/vnd.rn-realpix";
}
return result;
}
public static void main(String[] args) throws FileNotFoundException, IOException {
/*String picture="F:\\725017921264249223.jpg";
BufferedImage sourceImg =ImageIO.read(new FileInputStream(picture));
int height=sourceImg.getHeight();
int width=sourceImg.getWidth();
System.out.println(height +" And pt=" +height*12/16);
System.out.println(width+" And pt=" +width*12/16);*/
String picture="E:\\huoqubing.jpg";
System.out.println(imageToBase64(picture));
}
}
");
sb2.append("");*/
//return sb1.toString()+sb2.toString();
return sb1.toString();
}
/**
* @Description: 生成图片的base4块
* @param @param nextPartId
* @param @param contextLoacation
* @param @param ContentType
* @param @param base64Content
* @param @return
* @return String
* @throws
* @author:LiaoFei
* @date:2016-3-28 下午4:02:05
*/
public static String generateImageBase64Block(String nextPartId,String contextLoacation,
String fileTypeName,String base64Content){
/*--=_NextPart_01D188DB.E436D870
Content-Location: file:///C:/70ED9946/file9462.files/image001.jpg
Content-Transfer-Encoding: base64
Content-Type: image/jpeg
base64Content
*/
StringBuilder sb=new StringBuilder();
sb.append("\n");
sb.append("\n");
sb.append("------=_NextPart_"+nextPartId);
sb.append("\n");
sb.append("Content-Location: "+ contextLoacation);
sb.append("\n");
sb.append("Content-Transfer-Encoding: base64");
sb.append("\n");
sb.append("Content-Type: " + getImageContentType(fileTypeName));
sb.append("\n");
sb.append("\n");
sb.append(base64Content);
return sb.toString();
}
private static String generateImageBodyBlockStyleAttr(String imageFilePath, int height,int width){
StringBuilder sb=new StringBuilder();
BufferedImage sourceImg;
try {
sourceImg = ImageIO.read(new FileInputStream(imageFilePath));
if(height==0){
height=sourceImg.getHeight();
}
if(width==0){
width=sourceImg.getWidth();
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//将像素转化成pt
BigDecimal heightValue=new BigDecimal(height*12/16);
heightValue= heightValue.setScale(2, BigDecimal.ROUND_HALF_UP);
BigDecimal widthValue=new BigDecimal(width*12/16);
widthValue= widthValue.setScale(2, BigDecimal.ROUND_HALF_UP);
sb.append("height:"+heightValue +"pt;");
sb.append("width:"+widthValue +"pt;");
sb.append("visibility:visible;");
sb.append("mso-wrap-style:square; ");
return sb.toString();
}
private static String getImageContentType(String fileTypeName){
String result="image/jpeg";
//http://tools.jb51.net/table/http_content_type
if(fileTypeName.equals("tif") || fileTypeName.equals("tiff")){
result="image/tiff";
}else if(fileTypeName.equals("fax")){
result="image/fax";
}else if(fileTypeName.equals("gif")){
result="image/gif";
}else if(fileTypeName.equals("ico")){
result="image/x-icon";
}else if(fileTypeName.equals("jfif") || fileTypeName.equals("jpe")
||fileTypeName.equals("jpeg") ||fileTypeName.equals("jpg")){
result="image/jpeg";
}else if(fileTypeName.equals("net")){
result="image/pnetvue";
}else if(fileTypeName.equals("png") || fileTypeName.equals("bmp") ){
result="image/png";
}else if(fileTypeName.equals("rp")){
result="image/vnd.rn-realpix";
}else if(fileTypeName.equals("rp")){
result="image/vnd.rn-realpix";
}
return result;
}
public static void main(String[] args) throws FileNotFoundException, IOException {
/*String picture="F:\\725017921264249223.jpg";
BufferedImage sourceImg =ImageIO.read(new FileInputStream(picture));
int height=sourceImg.getHeight();
int width=sourceImg.getWidth();
System.out.println(height +" And pt=" +height*12/16);
System.out.println(width+" And pt=" +width*12/16);*/
String picture="E:\\huoqubing.jpg";
System.out.println(imageToBase64(picture));
}
}至此,成功导出为word:
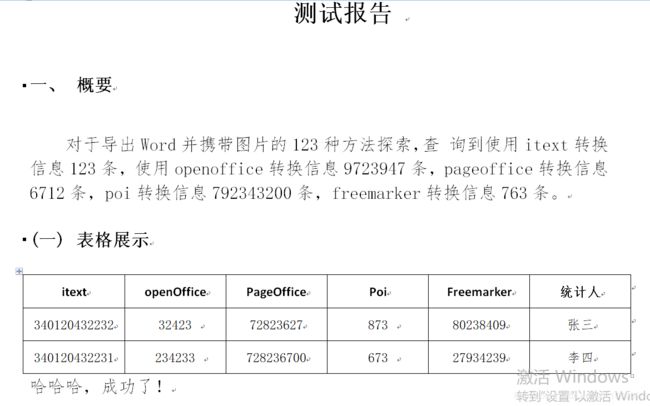
另外,之前只用国外开源的项目docx-html-editor也成功导出了带图片的word,但是源码中没有使用spring框架,不好添加到现有项目中,有兴趣的小伙伴可以移步去尝试下,成功了记得告诉我!
传送门:https://github.com/plutext/docx-html-editor