中断-整体流程
文章疏理自
<<深入Linux设备驱动程序内核机制>>
http://blog.csdn.net/droidphone/article/category/1118447
感谢以上两位大侠的创作,读者亦可查阅原文.
读完此文你可以了解到:
1. 中断的处理流程
2. 中断在linux中的实现
3. arm架构对中断做的处理
4. 电平/边沿触发时中断控制器所做的动作
中断控制器PIC,与CPU连接,然后产生中断的外设与PIC连接.
一颗SoC芯片中集成了处理器和各种外设控制器,包括PIC.
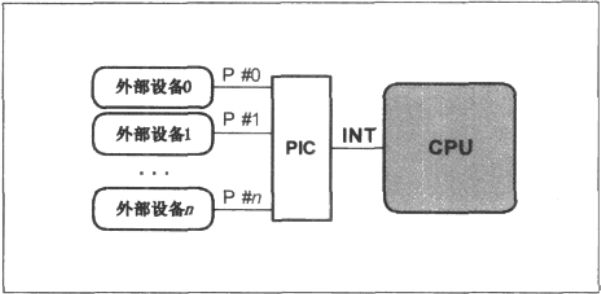
中断控制器的作用:
对各个irq的优先级进行控制;
向CPU发出中断请求后,提供某种机制让CPU获得实际的中断源(irq编号);
控制各个irq的电气触发条件,例如边缘触发或者是电平触发;
使能(enable)或者屏蔽(mask)某一个irq;
提供嵌套中断请求的能力;
提供清除中断请求的机制(ack);
有些控制器还需要CPU在处理完irq后对控制器发出eoi指令(end of interrupt);
在smp系统中,控制各个irq与cpu之间的亲缘关系(affinity);
中断产生时处理器硬件逻辑会:
当前任务的上下文寄存器保存在一个特定的中断栈中
屏蔽处理器响应外部中断的能力(ARM是通过把CPSR中的I位置位,表明禁止新的IRQ请求)
硬件逻辑根据中断向量表调用通用中断处理函数
通用中断处理函数
这部分代码都是用汇编语言实现的,不同架构的平台实现也不尽相同,但相同点是都会从PIC中得到导致此次中断产生的中断号irq,
然后调用一个C函数,即我们熟知的do_IRQ.
我们来简单看下ARM架构是如何处理的.
我们知道,arm的异常和复位向量表有两种选择,一种是低端向量,向量地址位于0x00000000,另一种是高端向量,向量地址位于0xffff0000,
Linux选择使用高端向量模式,也就是说,当异常发生时,CPU会把PC指针自动跳转到始于0xffff0000开始的某一个地址上:
ARM的异常向量表
地址 异常种类
FFFF0000 复位
FFFF0004 未定义指令
FFFF0008 软中断(swi)
FFFF000C Prefetch abort
FFFF0010 Data abort
FFFF0014 保留
FFFF0018 IRQ
FFFF001C FIQ
中断向量表在arch/arm/kernel/entry_armv.S文件的结尾部分,不帖代码了.
不过要注意位于__vectors_start和__vectors_end之间的是真正的向量跳转表,位于__stubs_start和__stubs_end之间的
是处理跳转的部分.
例如:
vector_stub irq, IRQ_MODE, 4
以上这一句把宏展开后实际上就是定义了vector_irq,根据进入中断前的cpu模式,分别跳转到__irq_usr或__irq_svc
系统启动阶段,位于arch/arm/kernel/traps.c中的early_trap_init()被调用:
void __init early_trap_init(void)
{
......
/*
* Copy the vectors, stubs and kuser helpers (in entry-armv.S)
* into the vector page, mapped at 0xffff0000, and ensure these
* are visible to the instruction stream.
*/
memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start);
......
}
以上两个memcpy会把__vectors_start开始的代码拷贝到0xffff0000处,把__stubs_start开始的代码拷贝到0xFFFF0000+0x200处,
这样,异常中断到来时,CPU就可以正确地跳转到相应中断向量入口并执行他们。
对于系统的外部设备来说,通常都是使用IRQ中断,所以我们只关注__irq_usr和__irq_svc,两个函数最终都会进入irq_handler这个宏:
.macro irq_handler
#ifdef CONFIG_MULTI_IRQ_HANDLER
ldr r1, =handle_arch_irq
mov r0, sp
adr lr, BSYM(9997f)
ldr pc, [r1]
#else
arch_irq_handler_default
#endif
9997:
.endm
代码同样位于arch/arm/kernel/entry_armv.S文件中
如果选择了MULTI_IRQ_HANDLER配置项,则意味着允许平台的代码可以动态设置irq处理程序,平台代码可以修改全局变量
handle_arch_irq,从而可以修改irq的处理程序。我目前的代码中,在板级相关的文件中
.handle_irq = gic_handle_irq,
arch/arm/kernel/setup.c
handle_arch_irq = mdesc->handle_irq;
所以最终调用到了gic_handle_irq(arch/arm/common/gic.c)
这个函数主要功能就是从中断控制器中获得irq号,紧接着就调用handle_IRQ,从这个函数开始,中断程序进入C代码中,
传入的参数是IRQ编号和寄存器结构指针.
VIC : Vectored Interrupt Controller
GIC: Generic Interrupt Controller
网上有句是说:
两者区别是,向量中断就是不同的中断有不同的入口地址,非向量中断就只有一个入口地址,
进去了在判断中断标志来识别具体是哪个中断。向量中断实时性好,非向量中断简单.
我感觉GIC主要是在smp系统中提供统一的访问接口.
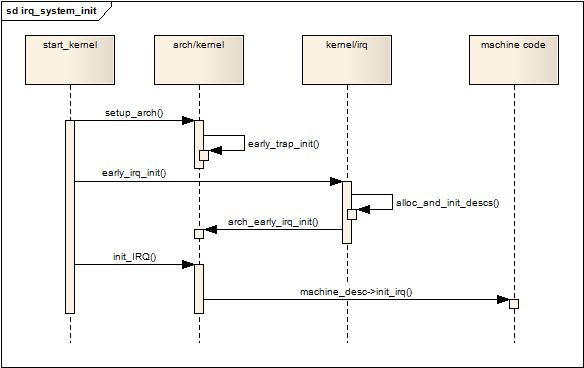
到这里我们做个图(引用自 DroidPhone 的),看下软件上是如何初始化的:
/*
* handle_IRQ handles all hardware IRQ's. Decoded IRQs should
* not come via this function. Instead, they should provide their
* own 'handler'. Used by platform code implementing C-based 1st
* level decoding.
*/
void handle_IRQ(unsigned int irq, struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
perf_mon_interrupt_in();
irq_enter();
/*
* Some hardware gives randomly wrong interrupts. Rather
* than crashing, do something sensible.
*/
if (unlikely(irq >= nr_irqs)) {
if (printk_ratelimit())
printk(KERN_WARNING "Bad IRQ%u\n", irq);
ack_bad_irq(irq);
} else {
generic_handle_irq(irq);
}
/* AT91 specific workaround */
irq_finish(irq);
irq_exit();
set_irq_regs(old_regs);
perf_mon_interrupt_out();
}
首先看两个参数,irq是do_IRQ的调用者通用中断处理函数从PIC中得到的irq,regs是保存下来的
被中断任务的执行上下文.
我们看set_irq_regs函数的实现:
static inline struct pt_regs *set_irq_regs(struct pt_regs *new_regs)
{
struct pt_regs *old_regs;
old_regs = __this_cpu_read(__irq_regs);
__this_cpu_write(__irq_regs, new_regs);
return old_regs;
}
这个函数的意思就是把变量__irq_regs赋于新值regs,把它原来的值保存在old_regs中.这样的目的就是
系统中的每一个CPU都可以通过__irq_regs来访问系统保存的中断上下文.__irq_regs用来在调试时打印
当前栈的信息,也可以通过保存的中断上下文寄存器来判断被中断的进程运行在用户态还是内核态.
irq_enter的作用是禁止抢占.
是通过把preempt_count加上HARDIRQ_OFFSET,HARDIRQ_OFFSET代表中断的上半部,preempt_count
是进程调度时用到的.也就是系统会根据preempt_count的值来判断是否可以调度.只有当preempt_count为0时才可以调度.
当调用preempt_disable或add_preempt_count函数时都不可以进行调度,因为都会改变preempt_count的值为非0.
所以irq_enter就是告诉系统,现在正在处理中断的上半部分工作,不可以进行调度.
你可能会奇怪,既然此时的irq中断都是都是被禁止的,为何还要禁止抢占?这是因为要考虑中断嵌套的问题,
一旦驱动程序主动通过local_irq_enable打开了IRQ,而此时该中断还没处理完成,新的irq请求到达,
这时代码会再次进入irq_enter,在本次嵌套中断返回时,内核不希望进行抢占调度,而是要等到最外层的中断处理完成后才做出调度动作,所以才有了禁止抢占这一处理。
到了最关键的部分generic_handle_irq,
/**
* generic_handle_irq - Invoke the handler for a particular irq
* @irq: The irq number to handle
*
*/
int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(irq, desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
static inline void generic_handle_irq_desc(unsigned int irq, struct irq_desc *desc)
{
desc->handle_irq(irq, desc);
}
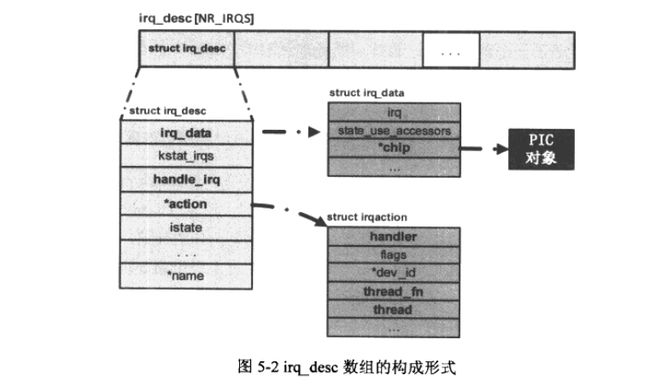
说到这里要介绍几个数据结构,struct irq_desc, struct irq_data, struct irq_chip, struct irqaction. 我们先用图来表示下它们的关系:
这里只贴关键的成员变量:
struct irq_desc {
struct irq_data irq_data; //保存中断请求irq和chip相关的数据
irq_flow_handler_t handle_irq; //指向一个跟当前设备中断触发电信号类型相关的函数,比方说如果是边沿触发,
//那么就指向一个边沿触发类型的函数.在handle_irq指向的函数内部会调用
//设备特定的中断服务例程.特定平台linux系统在初始化阶段会提供handle_irq的具体实现
struct irqaction *action; /* IRQ action list */ irq action链表,是对某一具体设备的中断处理的抽象,设备驱动程序会通过
//request_irq来向这个链表中注册自己的中断处理函数,这个action结构体中有个next成员变量,会把
//注册的ISR串连起来,当然如果此irq line上只有一个设备,那么这个action就对应这个设备的中断处理程序
unsigned int status_use_accessors;//处理中断时的irq状态都保存在这个成员变量中
const char *name; //会显示在/proc/interrupts中
......
};
struct irq_data {
unsigned int irq; //中断请求号
struct irq_chip *chip; //当前中断来自的PIC,chip是对PIC的一个抽象,屏蔽硬件平台上PIC的差异,
//给软件提供统一的对PIC操作的接口.这些函数接口主要用来屏蔽或启用当前
//中断,设定外部设备中断触发电信号的类型,向发出中断请求的设备发送中断响应信号
//平台初始化函数负责实现该平台对应的PIC函数,并安装对irq_desc数组中
......
};
struct irqaction {
irq_handler_t handler; //中断服务例程,即我们熟知的ISR,当我们调用request_irq时会把我们实现的ISR注册到这里
void *dev_id; //调用handler时传递的参数,在多个设备共享一个irq号时特别重要,设备驱动程序就是通过此
//成员变量来标识自己,在free_irq时用到
struct irqaction *next; //串连下一个action
......
};
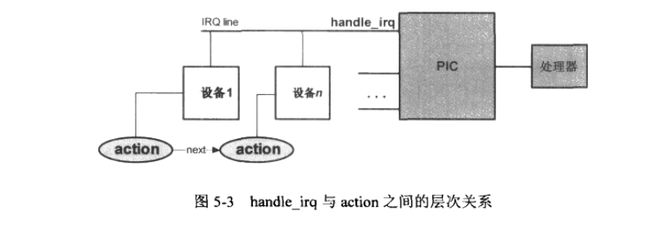
通过以上的介绍,我们可以知道,一个中断对应两个层次,一个是handle_irq,一个是action.前者对应irq line上的处理动作,后者对应设备相关的中断处理.
也就是说,一条irq line对应一个handle_irq,而这条irq line上可以挂载多个设备,即多个设备都可以通过同一个irq line产生中断,action成员变量用来
串连挂载在此irq line上的各个设备驱动的ISR.如果irq line上只有一个设备驱动注册,那么这个action成员变量即是此设备驱动的ISR.用图来表示就是:
接着desc->handle_irq(irq, desc)这个调用走,handle_irq是在irq_set_handler里赋的值.
void __irq_set_handler(unsigned int irq, irq_flow_handler_t handle, int is_chained,
const char *name)
{
......
desc->handle_irq = handle;
desc->name = name;
......
}
接下来就到了具体的handler, 如果是电平触发那么会调用到handle_level_irq,边沿触发的中断会调用到handle_edge_irq,在这两个函数中
做了一些器件相关的工作,可以查看 中断-电平/边沿触发时要做的具体工作 ,(这篇文章很好的说明了中断在什么时候是屏蔽的,什么时候是打开的)
或<<深入Linux设备驱动程序内核机制>>的5.7~5.8节.
一点小提示,mask_ack_irq就是屏蔽中断线
irq_ack用来向设备发送一个中断响应信号,从硬件角度讲就是让发出中断的设备产生一个信号电平的转换,防止该设备不停的发出同一中断信号.
kernel/irq/chip.c的handle_edge_irq函数有段注释,我们从注释中可以了解到:
After the ack another
interrupt can happen on the same source even before the first one
is handled by the associated event handler. If this happens it
might be necessary to disable (mask) the interrupt depending on the
controller hardware.
mask_irq 禁止中断
ack_irq 复位设备的中断请求引脚,ack后中断控制器才会再次向处理器发中断请求
mask_ack_irq 是以上两者的结合
同时引出个问题:在SMP系统中,我们知道在中断上下文会禁止CPU响应中断并禁止抢占,那么当一个CPU处理IRQ时,此中断线若再次来中断会不会在另一个CPU上处理?
答:要分是什么触发,边沿还是电平触发。
电平触发:来中断时会先mask然后ack,mask是禁止产生中断,ack就是复位设备中断脚,在ack发出之后,设备就可以再次来中断,否则会一直保持高电平状态。
虽说在ack后可以再次来中断,但是由于之前执行了mask,禁止中断,所以直到执行unmask另一个CPU才会收到中断。
边沿触发:不像电平触发那样,如果不ack会一直保持高电平,边沿触发只是在电平跳变时才触发IRQ,所以处理不当就容易丢失。也正因为这样,
边沿触发不会mask irq,只是ack,以便复位引脚,在这之后再次产生中断另一个CPU可以做处理,因为之前并没有mask。
无论是边沿触发还是电平触发,最终都会调用到handle_irq_event.它为调用设备驱动程序安装的中断处理程序做最后的准备.
handle_irq_event最终会调用handle_irq_event_percpu,然后通过一个do {} while 循环 action->handler(irq, action->dev_id)
来调用中断处理程序.
有一点要注意,就是在中断共享的情况下,也就是一条中断线上注册了多个中断处理程序,那么在某一个设备触发中断时,这条中断线上的
所有中断处理程序都会被调用到,因此共享中断时ISR要判断是否是自己的设备产生的中断,这主要靠读取自己设备的中断状态寄存器完成.
如果发现不是自己的设备产生的中断,那么返回一个IRQ_NONE就好了.
这里再做个图,以表中断处理的整个大致流程:
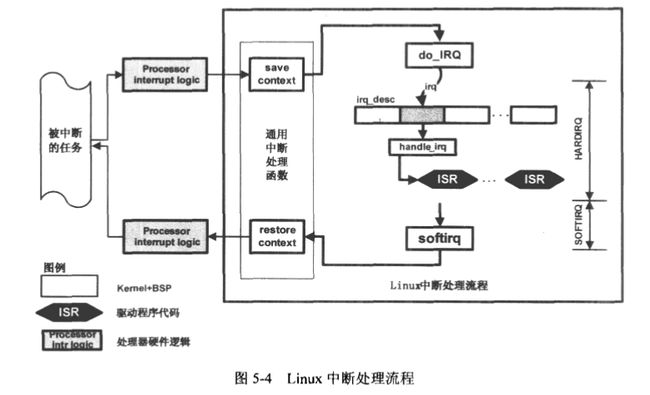
还有些要注意的:
对一些共享资源,如果中断例程有可能用到,那么要加自旋锁.
中断中只能用
spin_lock_irq/spin_unlock_irq
spin_lock_irqsave/spin_unlock_irqrestore
千万不能用
spin_lock/spin_unlock
后者有可能会导致死锁.比方进程A跑在CPU0上,正在使用某个共享资源C,突然来一中断,CPU0去处理中断,正好中断也要用C,如果用spin_lock,那么中断会自旋,等待进程A的释放,而进程A被中断,等待中断执行完,所以就形成了死锁.
用前者的自旋锁接口就不会出现此问题,因为前者是禁止抢占,禁止中断的情况下访问共享资源.
但有一点,就是用自旋锁保护的代码要尽可能的在最短的时间内执行完,因为前者虽然不会出现死锁,但是其他的进程也会为了等待资源的释放而自旋,这样会影响系统的性能,所以要临界区的代码要尽快执行完.能保证这一点有时候并不容易,因为我们必须清楚的知道自己在做什么,就是你调用的函数你要清楚的了解它是否会睡眠,还有在某些情况下进程在临界区中可能被换出处理器.所以我们要劳记一条准则:任何拥有自旋锁的代码必须是原子的,不能睡眠.
中断相关补充关于SOFTIRQ:
中断分为HARDIRQ和SOFTIRQ两部分,耗时的工作将会延迟到SOFTIRQ去做。
对于中断后半部的延迟操作可以说内核提供了三种机制:softirq、tasklet、work queue。
软中断处理程序执行的时候,允许响应中断,但它自己不能休眠。
当一个软中断处理程序执行的时候,当前处理器上的软中断被禁止,但其他处理器仍可以执行软中断。就是说,如果一个软中断处理程序在它执行的同时被再次触发了,那么另外一个处理器可以同时运行其处理程序。所以任何共享数据都需要用锁来保护。但是内核并未对软中断加锁,因为这样会影响性能,这样使用软中断就没有任何意义了(这句话不太理解,为什么就没有意义了呢?难道是因为性能的影响?)。因此,大部分软中断处理程序都采取单处理器数据(即per-CPU数据)或其他一些技巧来避免显式地加锁。
紧接着还有一句话:
引入软中断的主要原因是其可扩展性。就是可以扩展到多个处理器上,即可以并发执行。如果不需要扩展到多处理器,那么就使用tasklet吧。(那应该可以回答上面的疑问,就是性能的影响)
软中断一般在下列地方执行:
A、从一个硬件中断代码处返回时;
B、在ksoftirqd内核线程中;
C、显式检查和执行待处理的软中断代码中,如网络子系统。
一般软中断都用在那些执行频率很高和连续性要求很高的情况下。Linux只有两处用了软中断,网络子系统和SCSI子系统。
为了避免在一个中断的softirq部分耗太多时间而对系统性能造成影响,便引入了ksoftirqd。它的主要任务就是处理softirq,如果没有softirq需要处理,该进程将进入睡眠。关于ksoftirqd在LKD的8.3.2节的第4小部分会有详细的介绍。
------------------------------------
附:
tasklet是用软中断实现的一种下半部机制。
tasklet和软中断执行的时机一般都是在HARDIRQ处理程序返回时。
per-CPU变量即每个CPU维护一个本地变量,我们知道用per-CPU变量就不需要加锁来保护了。因为per-CPU变量是用禁止抢占来实现。
用per-CPU变量的好处就是:
1、减少数据锁定。
2、减少缓存失效。什么是缓存失效?就是如果一个处理器操作一个数据,而这个数据存放在其他处理器缓存中,那么存放这个数据的处理器就要不断的清除或刷新自己的缓存。持续不断的缓存失效称为缓存抖动,这样对系统性能影响很大。而使用per-CPU变量将使缓存影响降至最低,因为理想情况下只会访问自己的数据。
抢占即一个高优先级的抢占低优先级的执行,并不是只针对SMP系统中,别把概念搞错了!!!
<<深入Linux设备驱动程序内核机制>>
http://blog.csdn.net/droidphone/article/category/1118447
感谢以上两位大侠的创作,读者亦可查阅原文.
读完此文你可以了解到:
1. 中断的处理流程
2. 中断在linux中的实现
3. arm架构对中断做的处理
4. 电平/边沿触发时中断控制器所做的动作
中断控制器PIC,与CPU连接,然后产生中断的外设与PIC连接.
一颗SoC芯片中集成了处理器和各种外设控制器,包括PIC.
中断控制器的作用:
对各个irq的优先级进行控制;
向CPU发出中断请求后,提供某种机制让CPU获得实际的中断源(irq编号);
控制各个irq的电气触发条件,例如边缘触发或者是电平触发;
使能(enable)或者屏蔽(mask)某一个irq;
提供嵌套中断请求的能力;
提供清除中断请求的机制(ack);
有些控制器还需要CPU在处理完irq后对控制器发出eoi指令(end of interrupt);
在smp系统中,控制各个irq与cpu之间的亲缘关系(affinity);
中断产生时处理器硬件逻辑会:
当前任务的上下文寄存器保存在一个特定的中断栈中
屏蔽处理器响应外部中断的能力(ARM是通过把CPSR中的I位置位,表明禁止新的IRQ请求)
硬件逻辑根据中断向量表调用通用中断处理函数
通用中断处理函数
这部分代码都是用汇编语言实现的,不同架构的平台实现也不尽相同,但相同点是都会从PIC中得到导致此次中断产生的中断号irq,
然后调用一个C函数,即我们熟知的do_IRQ.
我们来简单看下ARM架构是如何处理的.
我们知道,arm的异常和复位向量表有两种选择,一种是低端向量,向量地址位于0x00000000,另一种是高端向量,向量地址位于0xffff0000,
Linux选择使用高端向量模式,也就是说,当异常发生时,CPU会把PC指针自动跳转到始于0xffff0000开始的某一个地址上:
ARM的异常向量表
地址 异常种类
FFFF0000 复位
FFFF0004 未定义指令
FFFF0008 软中断(swi)
FFFF000C Prefetch abort
FFFF0010 Data abort
FFFF0014 保留
FFFF0018 IRQ
FFFF001C FIQ
中断向量表在arch/arm/kernel/entry_armv.S文件的结尾部分,不帖代码了.
不过要注意位于__vectors_start和__vectors_end之间的是真正的向量跳转表,位于__stubs_start和__stubs_end之间的
是处理跳转的部分.
例如:
vector_stub irq, IRQ_MODE, 4
以上这一句把宏展开后实际上就是定义了vector_irq,根据进入中断前的cpu模式,分别跳转到__irq_usr或__irq_svc
系统启动阶段,位于arch/arm/kernel/traps.c中的early_trap_init()被调用:
void __init early_trap_init(void)
{
......
/*
* Copy the vectors, stubs and kuser helpers (in entry-armv.S)
* into the vector page, mapped at 0xffff0000, and ensure these
* are visible to the instruction stream.
*/
memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start);
......
}
以上两个memcpy会把__vectors_start开始的代码拷贝到0xffff0000处,把__stubs_start开始的代码拷贝到0xFFFF0000+0x200处,
这样,异常中断到来时,CPU就可以正确地跳转到相应中断向量入口并执行他们。
对于系统的外部设备来说,通常都是使用IRQ中断,所以我们只关注__irq_usr和__irq_svc,两个函数最终都会进入irq_handler这个宏:
.macro irq_handler
#ifdef CONFIG_MULTI_IRQ_HANDLER
ldr r1, =handle_arch_irq
mov r0, sp
adr lr, BSYM(9997f)
ldr pc, [r1]
#else
arch_irq_handler_default
#endif
9997:
.endm
代码同样位于arch/arm/kernel/entry_armv.S文件中
如果选择了MULTI_IRQ_HANDLER配置项,则意味着允许平台的代码可以动态设置irq处理程序,平台代码可以修改全局变量
handle_arch_irq,从而可以修改irq的处理程序。我目前的代码中,在板级相关的文件中
.handle_irq = gic_handle_irq,
arch/arm/kernel/setup.c
handle_arch_irq = mdesc->handle_irq;
所以最终调用到了gic_handle_irq(arch/arm/common/gic.c)
这个函数主要功能就是从中断控制器中获得irq号,紧接着就调用handle_IRQ,从这个函数开始,中断程序进入C代码中,
传入的参数是IRQ编号和寄存器结构指针.
VIC : Vectored Interrupt Controller
GIC: Generic Interrupt Controller
网上有句是说:
两者区别是,向量中断就是不同的中断有不同的入口地址,非向量中断就只有一个入口地址,
进去了在判断中断标志来识别具体是哪个中断。向量中断实时性好,非向量中断简单.
我感觉GIC主要是在smp系统中提供统一的访问接口.
到这里我们做个图(引用自 DroidPhone 的),看下软件上是如何初始化的:
/*
* handle_IRQ handles all hardware IRQ's. Decoded IRQs should
* not come via this function. Instead, they should provide their
* own 'handler'. Used by platform code implementing C-based 1st
* level decoding.
*/
void handle_IRQ(unsigned int irq, struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
perf_mon_interrupt_in();
irq_enter();
/*
* Some hardware gives randomly wrong interrupts. Rather
* than crashing, do something sensible.
*/
if (unlikely(irq >= nr_irqs)) {
if (printk_ratelimit())
printk(KERN_WARNING "Bad IRQ%u\n", irq);
ack_bad_irq(irq);
} else {
generic_handle_irq(irq);
}
/* AT91 specific workaround */
irq_finish(irq);
irq_exit();
set_irq_regs(old_regs);
perf_mon_interrupt_out();
}
首先看两个参数,irq是do_IRQ的调用者通用中断处理函数从PIC中得到的irq,regs是保存下来的
被中断任务的执行上下文.
我们看set_irq_regs函数的实现:
static inline struct pt_regs *set_irq_regs(struct pt_regs *new_regs)
{
struct pt_regs *old_regs;
old_regs = __this_cpu_read(__irq_regs);
__this_cpu_write(__irq_regs, new_regs);
return old_regs;
}
这个函数的意思就是把变量__irq_regs赋于新值regs,把它原来的值保存在old_regs中.这样的目的就是
系统中的每一个CPU都可以通过__irq_regs来访问系统保存的中断上下文.__irq_regs用来在调试时打印
当前栈的信息,也可以通过保存的中断上下文寄存器来判断被中断的进程运行在用户态还是内核态.
irq_enter的作用是禁止抢占.
是通过把preempt_count加上HARDIRQ_OFFSET,HARDIRQ_OFFSET代表中断的上半部,preempt_count
是进程调度时用到的.也就是系统会根据preempt_count的值来判断是否可以调度.只有当preempt_count为0时才可以调度.
当调用preempt_disable或add_preempt_count函数时都不可以进行调度,因为都会改变preempt_count的值为非0.
所以irq_enter就是告诉系统,现在正在处理中断的上半部分工作,不可以进行调度.
你可能会奇怪,既然此时的irq中断都是都是被禁止的,为何还要禁止抢占?这是因为要考虑中断嵌套的问题,
一旦驱动程序主动通过local_irq_enable打开了IRQ,而此时该中断还没处理完成,新的irq请求到达,
这时代码会再次进入irq_enter,在本次嵌套中断返回时,内核不希望进行抢占调度,而是要等到最外层的中断处理完成后才做出调度动作,所以才有了禁止抢占这一处理。
到了最关键的部分generic_handle_irq,
/**
* generic_handle_irq - Invoke the handler for a particular irq
* @irq: The irq number to handle
*
*/
int generic_handle_irq(unsigned int irq)
{
struct irq_desc *desc = irq_to_desc(irq);
if (!desc)
return -EINVAL;
generic_handle_irq_desc(irq, desc);
return 0;
}
EXPORT_SYMBOL_GPL(generic_handle_irq);
static inline void generic_handle_irq_desc(unsigned int irq, struct irq_desc *desc)
{
desc->handle_irq(irq, desc);
}
说到这里要介绍几个数据结构,struct irq_desc, struct irq_data, struct irq_chip, struct irqaction. 我们先用图来表示下它们的关系:
这里只贴关键的成员变量:
struct irq_desc {
struct irq_data irq_data; //保存中断请求irq和chip相关的数据
irq_flow_handler_t handle_irq; //指向一个跟当前设备中断触发电信号类型相关的函数,比方说如果是边沿触发,
//那么就指向一个边沿触发类型的函数.在handle_irq指向的函数内部会调用
//设备特定的中断服务例程.特定平台linux系统在初始化阶段会提供handle_irq的具体实现
struct irqaction *action; /* IRQ action list */ irq action链表,是对某一具体设备的中断处理的抽象,设备驱动程序会通过
//request_irq来向这个链表中注册自己的中断处理函数,这个action结构体中有个next成员变量,会把
//注册的ISR串连起来,当然如果此irq line上只有一个设备,那么这个action就对应这个设备的中断处理程序
unsigned int status_use_accessors;//处理中断时的irq状态都保存在这个成员变量中
const char *name; //会显示在/proc/interrupts中
......
};
struct irq_data {
unsigned int irq; //中断请求号
struct irq_chip *chip; //当前中断来自的PIC,chip是对PIC的一个抽象,屏蔽硬件平台上PIC的差异,
//给软件提供统一的对PIC操作的接口.这些函数接口主要用来屏蔽或启用当前
//中断,设定外部设备中断触发电信号的类型,向发出中断请求的设备发送中断响应信号
//平台初始化函数负责实现该平台对应的PIC函数,并安装对irq_desc数组中
......
};
struct irqaction {
irq_handler_t handler; //中断服务例程,即我们熟知的ISR,当我们调用request_irq时会把我们实现的ISR注册到这里
void *dev_id; //调用handler时传递的参数,在多个设备共享一个irq号时特别重要,设备驱动程序就是通过此
//成员变量来标识自己,在free_irq时用到
struct irqaction *next; //串连下一个action
......
};
通过以上的介绍,我们可以知道,一个中断对应两个层次,一个是handle_irq,一个是action.前者对应irq line上的处理动作,后者对应设备相关的中断处理.
也就是说,一条irq line对应一个handle_irq,而这条irq line上可以挂载多个设备,即多个设备都可以通过同一个irq line产生中断,action成员变量用来
串连挂载在此irq line上的各个设备驱动的ISR.如果irq line上只有一个设备驱动注册,那么这个action成员变量即是此设备驱动的ISR.用图来表示就是:
接着desc->handle_irq(irq, desc)这个调用走,handle_irq是在irq_set_handler里赋的值.
void __irq_set_handler(unsigned int irq, irq_flow_handler_t handle, int is_chained,
const char *name)
{
......
desc->handle_irq = handle;
desc->name = name;
......
}
接下来就到了具体的handler, 如果是电平触发那么会调用到handle_level_irq,边沿触发的中断会调用到handle_edge_irq,在这两个函数中
做了一些器件相关的工作,可以查看 中断-电平/边沿触发时要做的具体工作 ,(这篇文章很好的说明了中断在什么时候是屏蔽的,什么时候是打开的)
或<<深入Linux设备驱动程序内核机制>>的5.7~5.8节.
一点小提示,mask_ack_irq就是屏蔽中断线
irq_ack用来向设备发送一个中断响应信号,从硬件角度讲就是让发出中断的设备产生一个信号电平的转换,防止该设备不停的发出同一中断信号.
kernel/irq/chip.c的handle_edge_irq函数有段注释,我们从注释中可以了解到:
After the ack another
interrupt can happen on the same source even before the first one
is handled by the associated event handler. If this happens it
might be necessary to disable (mask) the interrupt depending on the
controller hardware.
mask_irq 禁止中断
ack_irq 复位设备的中断请求引脚,ack后中断控制器才会再次向处理器发中断请求
mask_ack_irq 是以上两者的结合
同时引出个问题:在SMP系统中,我们知道在中断上下文会禁止CPU响应中断并禁止抢占,那么当一个CPU处理IRQ时,此中断线若再次来中断会不会在另一个CPU上处理?
答:要分是什么触发,边沿还是电平触发。
电平触发:来中断时会先mask然后ack,mask是禁止产生中断,ack就是复位设备中断脚,在ack发出之后,设备就可以再次来中断,否则会一直保持高电平状态。
虽说在ack后可以再次来中断,但是由于之前执行了mask,禁止中断,所以直到执行unmask另一个CPU才会收到中断。
边沿触发:不像电平触发那样,如果不ack会一直保持高电平,边沿触发只是在电平跳变时才触发IRQ,所以处理不当就容易丢失。也正因为这样,
边沿触发不会mask irq,只是ack,以便复位引脚,在这之后再次产生中断另一个CPU可以做处理,因为之前并没有mask。
无论是边沿触发还是电平触发,最终都会调用到handle_irq_event.它为调用设备驱动程序安装的中断处理程序做最后的准备.
handle_irq_event最终会调用handle_irq_event_percpu,然后通过一个do {} while 循环 action->handler(irq, action->dev_id)
来调用中断处理程序.
有一点要注意,就是在中断共享的情况下,也就是一条中断线上注册了多个中断处理程序,那么在某一个设备触发中断时,这条中断线上的
所有中断处理程序都会被调用到,因此共享中断时ISR要判断是否是自己的设备产生的中断,这主要靠读取自己设备的中断状态寄存器完成.
如果发现不是自己的设备产生的中断,那么返回一个IRQ_NONE就好了.
这里再做个图,以表中断处理的整个大致流程:
还有些要注意的:
对一些共享资源,如果中断例程有可能用到,那么要加自旋锁.
中断中只能用
spin_lock_irq/spin_unlock_irq
spin_lock_irqsave/spin_unlock_irqrestore
千万不能用
spin_lock/spin_unlock
后者有可能会导致死锁.比方进程A跑在CPU0上,正在使用某个共享资源C,突然来一中断,CPU0去处理中断,正好中断也要用C,如果用spin_lock,那么中断会自旋,等待进程A的释放,而进程A被中断,等待中断执行完,所以就形成了死锁.
用前者的自旋锁接口就不会出现此问题,因为前者是禁止抢占,禁止中断的情况下访问共享资源.
但有一点,就是用自旋锁保护的代码要尽可能的在最短的时间内执行完,因为前者虽然不会出现死锁,但是其他的进程也会为了等待资源的释放而自旋,这样会影响系统的性能,所以要临界区的代码要尽快执行完.能保证这一点有时候并不容易,因为我们必须清楚的知道自己在做什么,就是你调用的函数你要清楚的了解它是否会睡眠,还有在某些情况下进程在临界区中可能被换出处理器.所以我们要劳记一条准则:任何拥有自旋锁的代码必须是原子的,不能睡眠.
中断相关补充关于SOFTIRQ:
中断分为HARDIRQ和SOFTIRQ两部分,耗时的工作将会延迟到SOFTIRQ去做。
对于中断后半部的延迟操作可以说内核提供了三种机制:softirq、tasklet、work queue。
软中断处理程序执行的时候,允许响应中断,但它自己不能休眠。
当一个软中断处理程序执行的时候,当前处理器上的软中断被禁止,但其他处理器仍可以执行软中断。就是说,如果一个软中断处理程序在它执行的同时被再次触发了,那么另外一个处理器可以同时运行其处理程序。所以任何共享数据都需要用锁来保护。但是内核并未对软中断加锁,因为这样会影响性能,这样使用软中断就没有任何意义了(这句话不太理解,为什么就没有意义了呢?难道是因为性能的影响?)。因此,大部分软中断处理程序都采取单处理器数据(即per-CPU数据)或其他一些技巧来避免显式地加锁。
紧接着还有一句话:
引入软中断的主要原因是其可扩展性。就是可以扩展到多个处理器上,即可以并发执行。如果不需要扩展到多处理器,那么就使用tasklet吧。(那应该可以回答上面的疑问,就是性能的影响)
软中断一般在下列地方执行:
A、从一个硬件中断代码处返回时;
B、在ksoftirqd内核线程中;
C、显式检查和执行待处理的软中断代码中,如网络子系统。
一般软中断都用在那些执行频率很高和连续性要求很高的情况下。Linux只有两处用了软中断,网络子系统和SCSI子系统。
为了避免在一个中断的softirq部分耗太多时间而对系统性能造成影响,便引入了ksoftirqd。它的主要任务就是处理softirq,如果没有softirq需要处理,该进程将进入睡眠。关于ksoftirqd在LKD的8.3.2节的第4小部分会有详细的介绍。
------------------------------------
附:
tasklet是用软中断实现的一种下半部机制。
tasklet和软中断执行的时机一般都是在HARDIRQ处理程序返回时。
per-CPU变量即每个CPU维护一个本地变量,我们知道用per-CPU变量就不需要加锁来保护了。因为per-CPU变量是用禁止抢占来实现。
用per-CPU变量的好处就是:
1、减少数据锁定。
2、减少缓存失效。什么是缓存失效?就是如果一个处理器操作一个数据,而这个数据存放在其他处理器缓存中,那么存放这个数据的处理器就要不断的清除或刷新自己的缓存。持续不断的缓存失效称为缓存抖动,这样对系统性能影响很大。而使用per-CPU变量将使缓存影响降至最低,因为理想情况下只会访问自己的数据。
抢占即一个高优先级的抢占低优先级的执行,并不是只针对SMP系统中,别把概念搞错了!!!