Kylin实时OLAP(Real Time OlAP又称RT OLAP)查询模块源码分析
Kylin RT OLAP 查询大致逻辑:Kylin query server 根据当前传入的查询条件,定位到要查询的segment,在根据这些segment定位哪些segment从历史(hbase)查询、哪些segment从实时节点(receiver)查询,需要通过receiver查询的segment,kylin query server通过发送一个http请求给对应的receiver节点进行查询,receiver端的入口为:org.apache.kylin.stream.server.rest.controller.DataController.query 即处理query server 发送的http请求的controller方法。本文主要从这里开始分析receiver查询到返回结果给query server的全过程以及相应源码解读。
一、调用流程简述
receiver 模块查询大致流程为:DataController.query方法先通过调用StreamingCubeDataSearcher.doSearch方法(此方法暂时不会真正触发查询,会进行segment和fragment过滤定位,封装查询器),返回一个StreamAggregateSearchResult实例;然后DataController.query通过调用StreamAggregateSearchResult的iteator方法,此方法会一条一条获得数据并进行聚合;然后DataController.query对每条记录进行序列化和Base64.encodeBase64String,然后返回内容给query server,receiver查询结束。
二、调用核心流程图
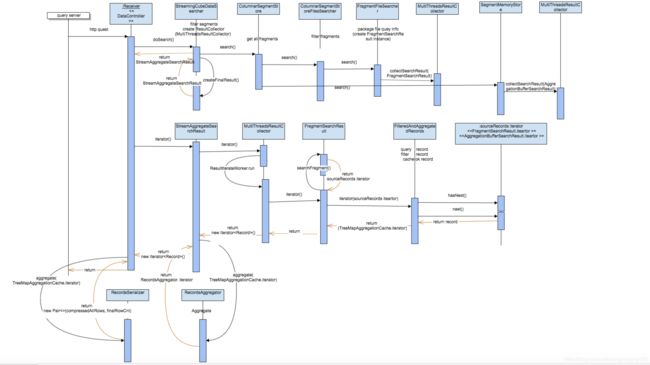
三、核心源码解读
@RequestMapping(value = "/query", method = RequestMethod.POST, produces = { "application/json" })
@ResponseBody
public DataResponse query(@RequestBody DataRequest dataRequest) {
IStreamingSearchResult searchResult = null;
String queryId = dataRequest.getQueryId();
StreamingQueryProfile queryProfile = new StreamingQueryProfile(queryId, dataRequest.getRequestSendTime());
if (dataRequest.isEnableDetailProfile()) {
queryProfile.enableDetailProfile();
}
if (dataRequest.getStorageBehavior() != null) {
queryProfile.setStorageBehavior(StorageSideBehavior.valueOf(dataRequest.getStorageBehavior()));
}
StreamingQueryProfile.set(queryProfile);
logger.info("receive query request queryId:{}", queryId);
try {
final Stopwatch sw = new Stopwatch();
sw.start();
String cubeName = dataRequest.getCubeName();
long minSegmentTime = dataRequest.getMinSegmentTime();
KylinConfig kylinConfig = KylinConfig.getInstanceFromEnv();
CubeDesc cubeDesc = CubeDescManager.getInstance(kylinConfig).getCubeDesc(cubeName);
//开始为执行查询做准备:如获取dim和metrics、封装filter过滤条件、group等
Set<FunctionDesc> metrics = convertMetrics(cubeDesc, dataRequest.getMetrics());
byte[] tupleFilterBytes = Base64.decodeBase64(dataRequest.getTupleFilter());
TupleFilter tupleFilter = TupleFilterSerializer.deserialize(tupleFilterBytes, StringCodeSystem.INSTANCE);
TupleFilter havingFilter = null;
if (dataRequest.getHavingFilter() != null) {
byte[] havingFilterBytes = Base64.decodeBase64(dataRequest.getHavingFilter());
havingFilter = TupleFilterSerializer.deserialize(havingFilterBytes, StringCodeSystem.INSTANCE);
}
Set<TblColRef> dimensions = convertToTblColRef(dataRequest.getDimensions(), cubeDesc);
Set<TblColRef> groups = convertToTblColRef(dataRequest.getGroups(), cubeDesc);
StreamingSegmentManager segmentManager = streamingServer.getStreamingSegmentManager(cubeName);
//得到查询器 StreamingCubeDataSearcher
StreamingCubeDataSearcher dataSearcher = segmentManager.getSearcher();
//构建searchReuest
StreamingSearchContext gtSearchRequest = new StreamingSearchContext(cubeDesc, dimensions, groups,
metrics, tupleFilter, havingFilter);
//通过查询器(StreamingCubeDataSearcher.doSearch)执行查询,此处只是创建了相应的对象,还未真正的触发执行查询,下面会重点分析此方法及其后续执行逻辑
searchResult = dataSearcher.doSearch(gtSearchRequest, minSegmentTime,
dataRequest.isAllowStorageAggregation());
if (StorageSideBehavior.RAW_SCAN == queryProfile.getStorageBehavior()) {
long counter = 0;
for (Record record : searchResult) {
counter ++;
}
logger.info("query-{}: scan {} rows", queryId, counter);
}
//创建序列化对象
RecordsSerializer serializer = new RecordsSerializer(gtSearchRequest.getRespResultSchema());
//调用searchResult.iterator触发真正的从磁盘和内存中读取数据,serialize方法进行一条一条的序列化并记录一共处理了多少条记录,searchResult.iterator()实际执行的为StreamingCubeDataSearcher$StreamAggregateSearchResult.iterator(),后续会重点分析searchResult.iterator()方法
Pair<byte[], Long> serializedRowsInfo = serializer.serialize(searchResult.iterator(),
dataRequest.getStoragePushDownLimit());
DataResponse dataResponse = new DataResponse();
//encode内容
dataResponse.setData(Base64.encodeBase64String(serializedRowsInfo.getFirst()));
sw.stop();
logger.info("query-{}: return response, took {} ms", queryId, sw.elapsedMillis());
//本次满足条件的条数
long finalCnt = serializedRowsInfo.getSecond();
queryProfile.setFinalRows(finalCnt);
String profileInfo = queryProfile.toString();
dataResponse.setProfile(profileInfo);
logger.info("query-{}: profile: {}", queryId, profileInfo);
//返回结果
return dataResponse;
} catch (Exception e) {
throw new StreamingException(e);
} finally {
if (searchResult != null) {
try {
searchResult.close();
} catch (Exception e) {
logger.error("Fail to close result scanner, query id:" + queryId);
}
}
}
}
重点分析StreamingCubeDataSearcher.doSearch 开始
StreamingCubeDataSearcher.doSearch方法
public IStreamingSearchResult doSearch(StreamingSearchContext searchRequest, long minSegmentTime,
boolean allowStorageAggregation) {
StreamingQueryProfile queryProfile = StreamingQueryProfile.get();
try {
logger.info("query-{}: use cuboid {} to serve the query", queryProfile.getQueryId(),
searchRequest.getHitCuboid());
//获取collector类型,根据是否多线程判断,默认为8个线程可配置,所以此处为MultiThreadsResultCollector
ResultCollector resultCollector = getResultCollector();
//获取此receiver上此cube的所有activeSegments和immutableSegments列表
Collection<StreamingCubeSegment> segments = streamingSegmentManager.getAllSegments();
StreamingDataQueryPlanner scanRangePlanner = searchRequest.getQueryPlanner();
//对这些segment进行处理(先看是否需要查询此segment,如果不需要则不会真正查询)
for (StreamingCubeSegment queryableSegment : segments) {
//过滤掉segment的时间范围不满足条件的segment,minSegmentTime传递的一个固定的值-1,isLongLatencySegment的比较也是一个固定的值0,DateRangeStart几乎都会大于0)
if (!queryableSegment.isLongLatencySegment() && queryableSegment.getDateRangeStart() < minSegmentTime) {
String segmentName = queryableSegment.getSegmentName();
queryProfile.skipSegment(segmentName);
logger.info("query-{}: skip segment {}, it is smaller than the min segment time:{}",
queryProfile.getQueryId(), segmentName, minSegmentTime);
continue;
}
//根据查询的时间过滤掉不在这个时间范围内的segment
if (scanRangePlanner.canSkip(queryableSegment.getDateRangeStart(), queryableSegment.getDateRangeEnd())) {
String segmentName = queryableSegment.getSegmentName();
queryProfile.skipSegment(segmentName);
logger.info("query-{}: skip segment {}", queryProfile.getQueryId(),
queryableSegment.getSegmentName());
} else {//满足条件的segment
String segmentName = queryableSegment.getSegmentName();
queryProfile.includeSegment(segmentName);
logger.info("query-{}: include segment {}", queryProfile.getQueryId(), segmentName);
//执行查询,调用此segment的store的实现类的search方法。(目前实现类只有一个即org.apache.kylin.stream.core.storage.columnar.ColumnarSegmentStore.ColumnarSegmentStore,可通过配置kylin.stream.store.class指定其他实现类)
//实际调用org.apache.kylin.stream.core.storage.columnar.ColumnarSegmentStore.ColumnarSegmentStore.search方法,接下来咱们继续追踪此方法
queryableSegment.getSegmentStore().search(searchRequest, resultCollector);
}
}
return createFinalResult(resultCollector, searchRequest, allowStorageAggregation, queryProfile);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
ColumnarSegmentStore.search方法
public void search(final StreamingSearchContext searchContext, ResultCollector collector) throws IOException {
SegmentMemoryStore searchMemoryStore;
List<DataSegmentFragment> searchFragments;
mergeReadLock.lock();
collector.addCloseListener(new CloseListener() {
@Override
public void onClose() {
mergeReadLock.unlock();
}
});
persistReadLock.lock();
try {
//获取此segment的所有fragments(一个segment又分为多个fragments)
searchFragments = getAllFragments();
if (persisting) {
searchMemoryStore = persistingMemoryStore;
} else {
searchMemoryStore = activeMemoryStore;
}
} finally {
persistReadLock.unlock();
}
//调用ColumnarSegmentStoreFilesSearcher的search方法
new ColumnarSegmentStoreFilesSearcher(segmentName, searchFragments).search(searchContext, collector);
searchMemoryStore.search(searchContext, collector);
}
ColumnarSegmentStoreFilesSearcher.search方法
public void search(final StreamingSearchContext searchContext, ResultCollector collector) throws IOException {
logger.info("query-{}: scan segment {}, fragment files num:{}", queryProfile.getQueryId(),
segmentName, fragments.size());
//对每一个fragments进行分析查询(会判断此fragments是否是需要查询的,否则不会真正去查询此fragment)
for (DataSegmentFragment fragment : fragments) {
File metaFile = fragment.getMetaFile();
if (!metaFile.exists()) {
if (queryProfile.isDetailProfileEnable()) {
logger.info("query-{}: for segment {} skip fragment {}, no meta file exists",
queryProfile.getQueryId(), segmentName, fragment.getFragmentId());
}
continue;
}
//获取此fragment的一些元数据信息,不真正获取到数据
FragmentData fragmentData = loadFragmentData(fragment);
FragmentMetaInfo fragmentMetaInfo = fragmentData.getFragmentMetaInfo();
StreamingDataQueryPlanner queryPlanner = searchContext.getQueryPlanner();
//判断此fragment是否是需要查询的fragment
if (fragmentMetaInfo.hasValidEventTimeRange()
&& queryPlanner.canSkip(fragmentMetaInfo.getMinEventTime(), fragmentMetaInfo.getMaxEventTime())) {
continue;
}
queryProfile.incScanFile(fragmentData.getSize());
FragmentFileSearcher fragmentFileSearcher = new FragmentFileSearcher(fragment, fragmentData);
//真正需要查询fragment调用FragmentFileSearcher.search方法
fragmentFileSearcher.search(searchContext, collector);
}
collector.addCloseListener(new CloseListener() {
@Override
public void onClose() {
for (DataSegmentFragment fragment : fragments) {
ColumnarStoreCache.getInstance().finishReadFragmentData(fragment);
}
}
});
}
FragmentFileSearcher.search方法
@Override
public void search(StreamingSearchContext searchContext, ResultCollector collector) throws IOException {
FragmentMetaInfo fragmentMetaInfo = fragmentData.getFragmentMetaInfo();
CuboidMetaInfo cuboidMetaInfo;
if (searchContext.hitBasicCuboid()) {
cuboidMetaInfo = fragmentMetaInfo.getBasicCuboidMetaInfo();
} else {
cuboidMetaInfo = fragmentMetaInfo.getCuboidMetaInfo(searchContext.getHitCuboid());
if (cuboidMetaInfo == null) {
logger.warn("the cuboid:{} is not exist in the fragment:{}, use basic cuboid instead",
searchContext.getHitCuboid(), fragment.getFragmentId());
cuboidMetaInfo = fragmentMetaInfo.getBasicCuboidMetaInfo();
}
}
ResponseResultSchema responseSchema = searchContext.getRespResultSchema();
TblColRef[] dimensions = responseSchema.getDimensions();
FunctionDesc[] metrics = responseSchema.getMetrics();
Map<TblColRef, Dictionary<String>> dictMap = fragmentData.getDimensionDictionaries(dimensions);
CubeDesc cubeDesc = responseSchema.getCubeDesc();
List<MeasureDesc> allMeasures = cubeDesc.getMeasures();
Map<FunctionDesc, MeasureDesc> funcMeasureMap = Maps.newHashMap();
for (MeasureDesc measure : allMeasures) {
funcMeasureMap.put(measure.getFunction(), measure);
}
MeasureDesc[] measures = new MeasureDesc[metrics.length];
for (int i = 0; i < measures.length; i++) {
measures[i] = funcMeasureMap.get(metrics[i]);
}
DimensionEncoding[] dimensionEncodings = ParsedStreamingCubeInfo.getDimensionEncodings(cubeDesc, dimensions,
dictMap);
ColumnarMetricsEncoding[] metricsEncodings = ParsedStreamingCubeInfo.getMetricsEncodings(measures);
ColumnarRecordCodec recordCodec = new ColumnarRecordCodec(dimensionEncodings, metricsEncodings);
// change the unEvaluable dimensions to groupBy
Set<TblColRef> unEvaluateDims = Sets.newHashSet();
TupleFilter fragmentFilter = null;
if (searchContext.getFilter() != null) {
fragmentFilter = convertFilter(fragmentMetaInfo, searchContext.getFilter(), recordCodec,
dimensions, new CubeDimEncMap(cubeDesc, dictMap), unEvaluateDims);
}
if (ConstantTupleFilter.TRUE == fragmentFilter) {
fragmentFilter = null;
} else if (ConstantTupleFilter.FALSE == fragmentFilter) {
collector.collectSearchResult(IStreamingSearchResult.EMPTY_RESULT);
}
Set<TblColRef> groups = searchContext.getGroups();
if (!unEvaluateDims.isEmpty()) {
searchContext.addNewGroups(unEvaluateDims);
groups = Sets.union(groups, unEvaluateDims);
}
//构建FragmentSearchResult并放入collectorResult中,之后会调用collectorResult的iteartor,然后在collectorResult的iteartor方法中调用FragmentSearchResult.iterator()方法真正获取数据
collector.collectSearchResult(new FragmentSearchResult(fragment, fragmentData, cuboidMetaInfo, responseSchema, fragmentFilter, groups, searchContext.getHavingFilter(),
recordCodec));
}
StreamingCubeDataSearcher.createFinalResult
private IStreamingSearchResult createFinalResult(final ResultCollector resultCollector,
final StreamingSearchContext searchRequest, boolean allowStorageAggregation,
StreamingQueryProfile queryProfile) throws IOException {
//resultCollector即为咱们返回的FragmentSearchResult
IStreamingSearchResult finalResult = resultCollector;
if (queryProfile.getStorageBehavior().ordinal() <= StorageSideBehavior.SCAN.ordinal()) {
return finalResult;
}
if (allowStorageAggregation) {
finalResult = new StreamAggregateSearchResult(finalResult, searchRequest);
}
return finalResult;
}
StreamingCubeDataSearcher$StreamAggregateSearchResult.iterator
@Override
public Iterator<Record> iterator() {
//这里的inputSearchResult.iterator实际调用的为MultiThreadsResultCollector.iterator recordsAggregator.aggregate(inputSearchResult.iterator());//--inputSearchResult==MultiThreadsResultCollector
return recordsAggregator.iterator();//recordsAggregator
}
MultiThreadsResultCollector.iterator
@Override
public Iterator<Record> iterator() {
notCompletedWorkers = new AtomicInteger(searchResults.size());
//启动真正读取数据的线程并开始读取,将读取的数据放入queue中
executor.submit(new WorkSubmitter());
final int batchSize = 100;
final long startTime = System.currentTimeMillis();
//返回一个迭代器,读取数据的线程将数据在后台通过线程的放肆读取后放入到queue中,上层调用返回的这个iterator的hasnext和next方法获取到每条记录
return new Iterator<Record>() {
List<Record> recordList = Lists.newArrayListWithExpectedSize(batchSize);
Iterator<Record> internalIT = recordList.iterator();
@Override
public boolean hasNext() {
boolean exits = (internalIT.hasNext() || queue.size() > 0);
if (!exits) {
while (notCompletedWorkers.get() > 0) {
Thread.yield();
long takeTime = System.currentTimeMillis() - startTime;
if (takeTime > timeout) {
throw new RuntimeException("Timeout when iterate search result");
}
if (internalIT.hasNext() || queue.size() > 0) {
return true;
}
}
}
return exits;
}
@Override
public Record next() {
try {
long takeTime = System.currentTimeMillis() - startTime;
if (takeTime > timeout) {
throw new RuntimeException("Timeout when iterate search result");
}
if (!internalIT.hasNext()) {
recordList.clear();
//从queue中消费取出数据
Record one = queue.poll(timeout - takeTime, TimeUnit.MILLISECONDS);
if (one == null) {
throw new RuntimeException("Timeout when iterate search result");
}
recordList.add(one);
queue.drainTo(recordList, batchSize - 1);
internalIT = recordList.iterator();
}
return internalIT.next();
} catch (InterruptedException e) {
throw new RuntimeException("Error when waiting queue", e);
}
}
@Override
public void remove() {
throw new UnsupportedOperationException("not support");
}
};
}
MultiThreadsResultCollector$WorkSubmitter.run启动执行线程
private class WorkSubmitter implements Runnable {
@Override
public void run() {
//为每一个searchResults启动一个
for (final IStreamingSearchResult result : searchResults) {
executor.submit(new ResultIterateWorker(result));
try {
workersSemaphore.acquire();
} catch (InterruptedException e) {
logger.error("interrupted", e);
}
}
}
}
MultiThreadsResultCollector$ResultIterateWorker.run真正启动读取数据的线程
private class ResultIterateWorker implements Runnable {
IStreamingSearchResult result;
public ResultIterateWorker(IStreamingSearchResult result) {
this.result = result;
}
@Override
public void run() {
try {
result.startRead();
//for (Record record : result) {相当于调用result.iterator,result目前有多个实现类,比如:FragmentSearchResult.iterator方法真正读取数据的具体逻辑
for (Record record : result) {
try {
queue.put(record.copy());//将从磁盘或内存中查询到的每条记录放入queue中
} catch (InterruptedException e) {
throw new RuntimeException("Timeout when visiting streaming segmenent", e);
}
}
result.endRead();
} catch (Exception e) {
logger.error("error when iterate search result", e);
} finally {
notCompletedWorkers.decrementAndGet();
workersSemaphore.release();
}
}
}
FragmentSearchResult.iterator()读取数据的具体逻辑
public Iterator<Record> iterator() {
//返回FragmentCuboidReader.iteartor迭代器或者new的一个iteartor(此iterator中的next也调用的为FragmentCuboidReader。read方法),具体返回哪个看是否需要full table scan决定,大致实现类似,只是一个是全部从头读取,一个是从指定的行读取(new iterator)
final Iterator<RawRecord> sourceRecords = searchFragment();
FilteredAndAggregatedRecords filterAggrRecords = new FilteredAndAggregatedRecords(sourceRecords,
responseSchema, recordCodec, filter, groups, havingFilter);
//调用FilteredAndAggregatedRecords.iteartor,此iterator主要是根据sourceRecords这个迭代器进行迭代获取每条记录,然后判断这条记录是否符合查询,如果符合则放入aggrCache查询结果中
return filterAggrRecords.iterator();
}
FragmentSearchResult.searchFragment()返回具体读取内容的reader迭代器,根据是否需要full table scan返回fragmentCuboidReader.iterator()或者new iterator(根据fragmentCuboidReader指定行开始读取数据)
private Iterator<RawRecord> searchFragment() {
IndexSearchResult indexSearchResult = searchFromIndex();
Iterator<RawRecord> result;
// Full table scan
if (indexSearchResult == null || indexSearchResult.needFullScan()) {
result = fragmentCuboidReader.iterator();
queryProfile.addStepInfo(getFragmentDataScanStep(), "use_index", "false");
} else {
queryProfile.addStepInfo(getFragmentDataScanStep(), "use_index", "true");
if (indexSearchResult.rows == null) {
if (queryProfile.isDetailProfileEnable()) {
logger.info("query-{}: no data match the query in the file segment-{}_fragment-{}",
queryProfile.getQueryId(), fragment.getSegmentName(), fragment.getFragmentId());
}
return Iterators.emptyIterator();
}
final Iterator<Integer> rows = indexSearchResult.rows;
result = new Iterator<RawRecord>() {
@Override
public boolean hasNext() {
return rows.hasNext();
}
@Override
public RawRecord next() {
return fragmentCuboidReader.read(rows.next() - 1);
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
return result;
}
FragmentSearchResult$FilteredAndAggregatedRecords.iterator 获取每条记录并判断是否满足查询结果,满足则放入
@Override
public Iterator<Record> iterator() {
if (hasAggregation()) {
while (sourceRecords.hasNext()) {//即为FragmentCuboidReader.hasNext 或者 new的那个iterator的hasNext,源码参见FragmentSearchResult.searchFragment()方法
RawRecord rawRecord = sourceRecords.next();//,FragmentCuboidReader.iterator.next 获取一条记录 或者 new的那个iterator的next,源码参见FragmentSearchResult.searchFragment()方法,后面会详细讲解FragmentCuboidReader.iterator.next方法查看一条记录的获取
if (filter != null && !satisfyFilter(rawRecord)) {//进行过滤
filterRowCnt ++;
} else {//满足条件的记录进行聚合并放入结果中
//AggregationCache.aggregate实际为FragmentSearchResult$TreeMapAggregationCache.aggregate,这个方法比较简单就是讲rawRecord的内容放到aggrCache的一个treeMap中,key为维度列的值,value为度量列的值
aggrCache.aggregate(rawRecord);
}
}
//所有记录全部遍历完成,则返回FragmentSearchResult$TreeMapAggregationCache.iterator,共上层一条一条的处理数据并返回给datacontroller(比如做havingfilter过滤等)
return aggrCache.iterator();
} else {
return transformAndFilterRecords();
}
}
FragmentCuboidReader.iterator方法,full table scan调用的地方
@Override
public Iterator<RawRecord> iterator() {
final RawRecord oneRawRecord = new RawRecord(dimCnt, metricCnt);
final Iterator<byte[]>[] dimValItr = new Iterator[dimensionDataReaders.length];
//得到每个维度列的reader,不同的列有不同的reader,具体根据此segment创建时指定的meta信息决定,常用的为new LZ4CompressedColumnDataItr()和RunLengthCompressedColumnReader。将segment 从内存persist的时候会根据维度列找到对应的压缩实现类参见代码:ColumnarMemoryStorePersister类中调用ColumnarStoreDimDesc.ColumnarStoreDimDesc,可从StreamingSegmentManager.addEvent.createSegment.getSegmentStore定位存储格式
//获取维度列的值
for (int i = 0; i < dimensionDataReaders.length; i++) {
//调用对应压缩类的iteartor方法目前主要两类(LZ4CompressedColumnDataItr、RunLengthCompressedColumnReader)参见ColumnarStoreDimDesc.ColumnarStoreDimDesc代码
dimValItr[i] = dimensionDataReaders[i].iterator();
}
final Iterator<byte[]>[] metricsValItr = new Iterator[metricDataReaders.length];
//获取度量列的值
for (int i = 0; i < metricDataReaders.length; i++) {
metricsValItr[i] = metricDataReaders[i].iterator();
}
return new Iterator<RawRecord>() {
@Override
public boolean hasNext() {
if (readRowCount >= rowCount) {
return false;
}
return true;
}
@Override
public RawRecord next() {
for (int i = 0; i < dimensionDataReaders.length; i++) {
oneRawRecord.setDimension(i, dimValItr[i].next());
}
for (int i = 0; i < metricDataReaders.length; i++) {
oneRawRecord.setMetric(i, metricsValItr[i].next());
}
readRowCount++;
return oneRawRecord;
}
@Override
public void remove() {
throw new UnsupportedOperationException("unSupported");
}
};
}
FragmentSearchResult$TreeMapAggregationCache.aggregate,这个方法比较简单就是将rawRecord的内容放到aggrCache的一个treeMap中,key为维度列的值,value为度量列的值
public boolean aggregate(RawRecord r) {
byte[][] dimVals = r.getDimensions();
byte[][] metricsVals = r.getMetrics();
MeasureAggregator[] aggrs = aggBufMap.get(dimVals);
if (aggrs == null) {
//for storage push down limit
if (aggBufMap.size() >= pushDownLimit) {
return false;
}
byte[][] copyDimVals = new byte[schema.getDimensionCount()][];
for(int i=0;i<dimVals.length;i++){
copyDimVals[i] = new byte[dimVals[i].length];
System.arraycopy(dimVals[i], 0, copyDimVals[i], 0, dimVals[i].length);
}
System.arraycopy(dimVals, 0, copyDimVals, 0, dimVals.length);
aggrs = newAggregators();
aggBufMap.put(copyDimVals, aggrs);
}
for (int i = 0; i < aggrs.length; i++) {
Object metrics = recordDecoder.decodeMetrics(i, metricsVals[i]);
aggrs[i].aggregate(metrics);
}
return true;
}
FragmentSearchResult$TreeMapAggregationCache.iterator
public Iterator<Record> iterator() {
Iterator<Entry<byte[][], MeasureAggregator[]>> it = aggBufMap.entrySet().iterator();
final Iterator<Entry<byte[][], MeasureAggregator[]>> input = it;
return new Iterator<Record>() {
final Record oneRecord = new Record(schema.getDimensionCount(), schema.getMetricsCount());
Entry<byte[][], MeasureAggregator[]> returningEntry = null;
final HavingFilterChecker havingFilterChecker = (havingFilter == null) ? null
: new HavingFilterChecker(havingFilter, schema);
@Override
public boolean hasNext() {
while (returningEntry == null && input.hasNext()) {
returningEntry = input.next();
if (havingFilterChecker != null) {
if (!havingFilterChecker.check(returningEntry.getValue())) {
returningEntry = null;
}
}
}
return returningEntry != null;
}
@Override
public Record next() {
byte[][] rawDimVals = returningEntry.getKey();
for (int i = 0; i < rawDimVals.length; i++) {
oneRecord.setDimension(i, recordDecoder.decodeDimension(i, rawDimVals[i]));
}
MeasureAggregator[] measures = returningEntry.getValue();
for (int i = 0; i < measures.length; i++) {
oneRecord.setMetric(i, measures[i].getState());
}
finalRowCnt ++;
returningEntry = null;
return oneRecord;
}
@Override
public void remove() {
throw new UnsupportedOperationException();
}
};
}
}