5.5 SVM补充-机器学习笔记-斯坦福吴恩达教授
SVM补充
决策边界
Coursera 上 ML 的课程对 SVM 介绍有限,参看了周志华教授的《机器学习》一书后,补充了当中对于 SVM 的介绍。
首先,我们考虑用更传统的权值定义式来描述我们的 SVM 决策边界(划分超平面):
w T x + b = 0 (1) w^Tx+b=0\tag1 wTx+b=0(1)
其中, w w w 表示权值向量,权值向量对应了决策边界的法向量。 b b b 则表示偏置,也称位移项,表示了决策边界距坐标原点的距离。我们可以将决策边界记为 ( w , b ) (w,b) (w,b) ,那么,样本 x x x 到决策边界的距离为:
r = ∣ w T + b ∣ ∣ ∣ w ∣ ∣ (2) r=\frac{|w^T+b|}{||w||}\tag2 r=∣∣w∣∣∣wT+b∣(2)
我们将正样本标识为 1,负样本标识为 -1, 则 SVM 的期望预测可以重新描述为:
{ w T x ( i ) + b ≥ + 1 , i f y ( i ) = + 1 w T x ( i ) + b ≤ − 1 , i f y ( i ) = − 1 (3) \begin{cases}w^Tx^{(i)}+b≥+1,\quad if\ y^{(i)}=+1\\w^Tx^{(i)}+b≤-1,\quad if\ y^{(i)}=-1\end{cases}\tag3 {wTx(i)+b≥+1,if y(i)=+1wTx(i)+b≤−1,if y(i)=−1(3)
亦即:
y ( i ) ( w T x ( i ) + b ) ≥ 1 (4) y^{(i)}(w^Tx^{(i)}+b)≥1\tag4 y(i)(wTx(i)+b)≥1(4)
使等号成立的样本称之为“支持向量(Support Vectors)”,两个异类的支持向量到决策边界的距离之和为:
γ = 2 ∣ ∣ w ∣ ∣ (5) γ=\frac2{||w||}\tag5 γ=∣∣w∣∣2(5)
γ 被称之为间隔。
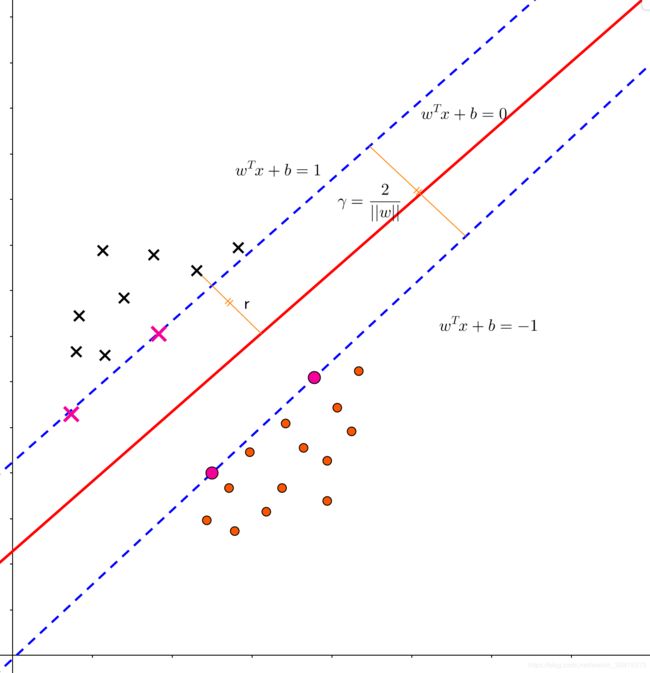
在之前的篇章中我们知道,SVM 就是力图是 γ γ γ 足够大,从而获得更好的泛化能力:
max w , b 2 ∣ ∣ w ∣ ∣ s . t . y ( i ) ( w T x ( i ) + b ) ≥ 1 , i = 1 , 2 , . . . , m (6) \max_{w,b}\frac2{||w||}\\ s.t.\quad y^{(i)}(w^Tx^{(i)}+b)≥1,\quad\quad i=1,2,...,m\tag6 w,bmax∣∣w∣∣2s.t.y(i)(wTx(i)+b)≥1,i=1,2,...,m(6)
我们可以转化为如下的二次优化问题:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 s . t . y ( i ) ( w T x ( i ) + b ) ≥ 1 , i = 1 , 2 , . . . , m (7) \min_{w,b}\frac12{||w||}^2\\ s.t.\quad y^{(i)}(w^Tx^{(i)}+b)≥1,\quad\quad i=1,2,...,m\tag7 w,bmin21∣∣w∣∣2s.t.y(i)(wTx(i)+b)≥1,i=1,2,...,m(7)
硬间隔与软间隔
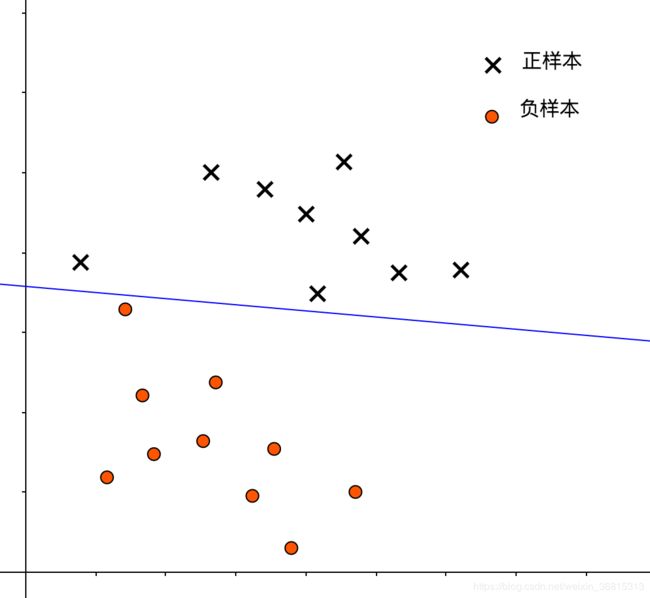
下图中,红色的决策边界表示了一种较硬的间隔划分,这种划分,能将所有正、负样本区分开来:
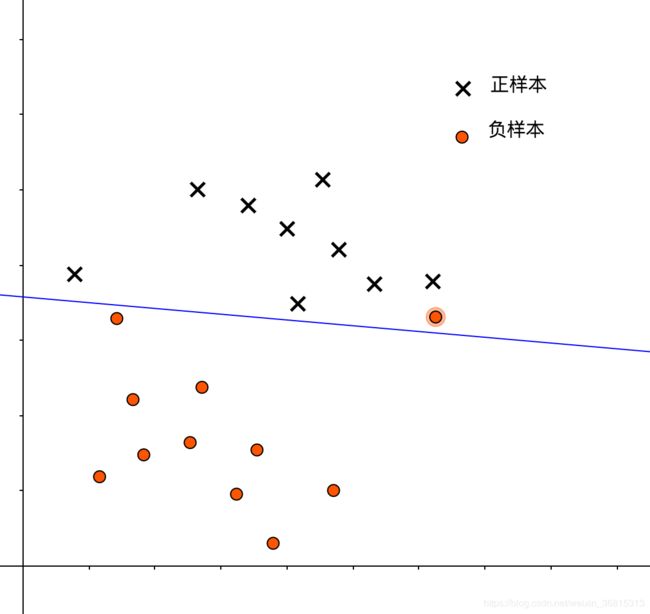
硬间隔并不一定好,就像我们在回归问题中提到的那样,这只是对于训练样本作出了极佳的拟合,但容易造成过度拟合。比如我们现在有了一个新的负样本,他被错误地分类为了正样本:
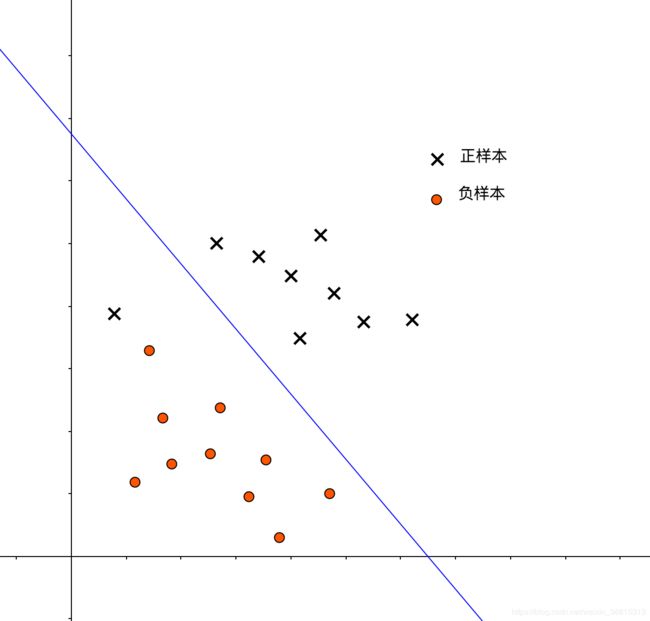
而下图则展示了一种较软的间隔,这样的决策边界允许了一部分分类异常,避免了过拟合问题,但如果过软,也容易造成欠拟合问题:
鉴于此,我们在优化过程中,添加一个参数 C C C 来控制间隔的“软硬”:
min w , b 1 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ℓ ( y ( i ) ( w T x ( i ) ) − 1 ) s . t . y ( i ) ( w T x ( i ) + b ) ≥ 1 , i = 1 , 2 , . . . , m (8) \min_{w,b}\frac1{||w||^2}+C\sum_{i=1}^m ℓ(y^{(i)}(w^Tx^{(i)})-1)\\ s.t.\quad y^{(i)}(w^Tx^{(i)}+b)≥1,\quad\quad i=1,2,...,m\tag8 w,bmin∣∣w∣∣21+Ci=1∑mℓ(y(i)(wTx(i))−1)s.t.y(i)(wTx(i)+b)≥1,i=1,2,...,m(8)
其中, ℓ ( z ) ℓ(z) ℓ(z) 是损失函数,其衡量了样本 x x x 与真实值 y ( i ) y^{(i)} y(i) 的近似程度,当 C C C 取值越大时,为了最优化问题,需要 ℓ ( z ) ℓ(z) ℓ(z) 越小,即各个样本都要尽可能分类正确,这提高了训练准确率,但也面临过拟合的问题。

故而, C C C 扮演了回归问题中正则化参数 1 λ \frac 1λ λ1 的角色。当 C 的取值趋于 ∞ ∞ ∞ 时,模型就变为了硬间隔支持向量机。
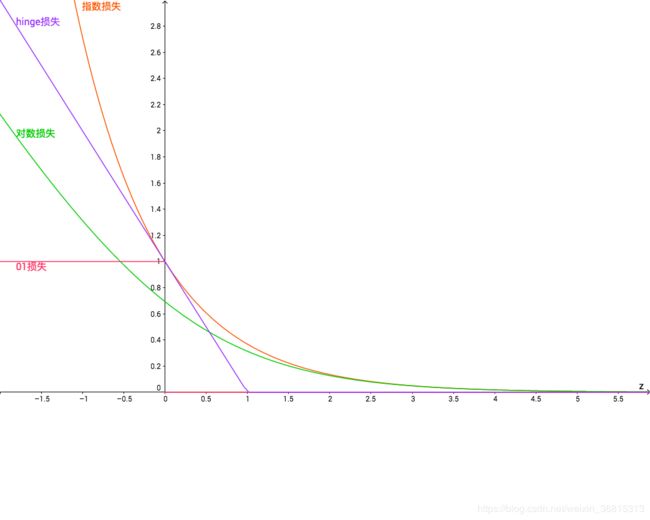
常见的损失函数有:
| 名称 | 函数式 |
|---|---|
| 0/1 损失 | ℓ ( z ) = { 1 , i f z < 0 0 , o t h e r w i s e ℓ(z)=\begin{cases}1,\quad if\ z<0\\0,\quad otherwise\end{cases} ℓ(z)={1,if z<00,otherwise |
| hinge 损失 | ℓ ( z ) = m a x ( 0 , 1 , − z ) ℓ(z)=max(0,1,-z) ℓ(z)=max(0,1,−z) |
| 指数损失 | ℓ ( z ) = e x p ( − z ) ℓ(z)=exp(-z) ℓ(z)=exp(−z) |
| 对数损失 | ℓ ( z ) = l o g ( 1 + e x p ( − z ) ) ℓ(z)=log(1+exp(-z)) ℓ(z)=log(1+exp(−z)) |
若采用 hinge 损失函数,则式 (8) 可以具体为:
min w , b 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m m a x ( 0 , 1 − y ( i ) ( w T x ( i ) + b ) ) (9) \min_{w,b}\frac12||w||^2+C\sum_{i=1}^mmax(0,1-y^{(i)}(w^Tx^{(i)}+b))\tag9 w,bmin21∣∣w∣∣2+Ci=1∑mmax(0,1−y(i)(wTx(i)+b))(9)
引入 “松弛变量(slack variables)” ξ ( i ) ≥ 0 ξ^{(i)}≥0 ξ(i)≥0 ,可以将式 (9) 改写为:
min w , b , ξ ( i ) 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 m ξ ( i ) s . t . y ( i ) ( w T x ( i ) + b ) ≥ 1 − ξ ( i ) ξ ( i ) ≥ 0 , i = 1 , 2 , 3 , . . . , m (10) \min_{w,b,ξ^{(i)}}\frac12||w||^2+C\sum_{i=1}^mξ^{(i)}\\ s.t.\quad y^{(i)}(w^Tx^{(i)}+b)≥1−ξ^{(i)}\\ ξ^{(i)}≥0,i=1,2,3,...,m\tag{10} w,b,ξ(i)min21∣∣w∣∣2+Ci=1∑mξ(i)s.t.y(i)(wTx(i)+b)≥1−ξ(i)ξ(i)≥0,i=1,2,3,...,m(10)
这就构成 “软间隔支持向量机”。
松弛变量,顾名思义,就是控制每个样本受到约束的程度。 ξ(i) 越大,则受约束程度越小(越松弛)。
- 当 ξ ( i ) > 1 ξ^{(i)}>1 ξ(i)>1 ,则 m a x ( 0 , 1 − y ( i ) ( w T x ( i ) + b ) ) > 1 max(0,1−y^{(i)}(w^Tx^{(i)}+b))>1 max(0,1−y(i)(wTx(i)+b))>1 ,即 y ( i ) y^{(i)} y(i) 与 ( w T x ( i ) + b ) ) (w^Tx^{(i)}+b)) (wTx(i)+b)) 异号,分类错误。
- 当 ξ ( i ) = 0 ξ^{(i)}=0 ξ(i)=0 ,则 m a x ( 0 , 1 − y ( i ) ( w T x ( i ) + b ) ) = 0 max(0,1−y^{(i)}(w^Tx^{(i)}+b))=0 max(0,1−y(i)(wTx(i)+b))=0 ,即 1 − y ( i ) ( w T x ( i ) + b ) = 0 1−y^{(i)}(w^Tx^{(i)}+b)=0 1−y(i)(wTx(i)+b)=0 ,样本落在了最大间隔边界上。
- 当 0 < ξ ( i ) ≤ 1 0<ξ^{(i)}≤1 0<ξ(i)≤1 ,则 m a x ( 0 , 1 − y ( i ) ( w T x ( i ) + b ) ) ≤ 1 max(0,1−y^{(i)}(w^Tx^{(i)}+b))≤1 max(0,1−y(i)(wTx(i)+b))≤1 ,即 0 ≤ 1 − y ( i ) ( w T x ( i ) + b ) ) ≤ 1 0≤1−y^{(i)}(w^Tx^{(i)}+b))≤1 0≤1−y(i)(wTx(i)+b))≤1 ,样本落在了最大间隔与决策边界之间。
对偶问题
对于式 (10) 的优化模型,应用拉格朗日乘子法获得的拉格朗日函数如下:
L ( w , b , a , ξ , μ ) = 1 2 ∣ ∣ ∣ ∣ 2 + C ∑ i = 1 m ξ ( i ) + ∑ i = 1 m a ( i ) ( 1 − ξ ( i ) − y i ( w T x i + b ) ) − ∑ i = 1 m μ ( i ) ξ ( i ) (11) L(w,b,a,ξ,μ)=\frac12||||^2+C\sum_{i=1}^mξ^{(i)}+\sum_{i=1}^ma^{(i)}(1-ξ^{(i)}-y_i(w^Tx_i+b))-\sum_{i=1}^mμ^{(i)}ξ^{(i)}\tag{11} L(w,b,a,ξ,μ)=21∣∣∣∣2+Ci=1∑mξ(i)+i=1∑ma(i)(1−ξ(i)−yi(wTxi+b))−i=1∑mμ(i)ξ(i)(11)
其中, α ( i ) ≥ 0 , μ ( i ) ≥ 0 α^{(i)}≥0 , μ^{(i)}≥0 α(i)≥0,μ(i)≥0 是拉格朗日乘子。
令 L ( w , b , α , ξ , μ ) L(w,b,α,ξ,μ) L(w,b,α,ξ,μ) 对 w w w , b b b , ξ ( i ) ξ^{(i)} ξ(i) 的偏导为 0 可得:
w = ∑ i = 1 m a ( i ) y ( i ) x ( i ) (12) w=\sum_{i=1}^ma^{(i)}y^{(i)}x^{(i)}\tag{12} w=i=1∑ma(i)y(i)x(i)(12) 0 = ∑ i = 1 m a ( i ) y ( i ) (13) 0=\sum_{i=1}^ma^{(i)}y^{(i)}\tag{13} 0=i=1∑ma(i)y(i)(13) C = a ( i ) + μ ( i ) (14) C=a^{(i)}+μ^{(i)}\tag{14} C=a(i)+μ(i)(14)
将其带入 (1) 式中,得:
f ( x ) = w T x + b = ∑ i = 1 m a ( i ) y ( i ) ( x ( i ) ) T x + b (15) f(x)=w^Tx+b=∑_{i=1}^ma^{(i)}y^{(i)}(x^{(i)})^Tx+b\tag{15} f(x)=wTx+b=i=1∑ma(i)y(i)(x(i))Tx+b(15)
将式 (12) - (14) 代入式 (11) 中,就得到了式 (10) 的 对偶问题:
max a ∑ i = 1 m a ( i ) − 1 2 ∑ i = 1 m ∑ j = 1 m a ( i ) a ( j ) y ( i ) y ( j ) ( x ( i ) ) T x ( j ) s . t . ∑ i = 1 m a ( i ) y ( i ) = 0 , 0 ≤ α ( i ) ≤ C , i = 1 , 2 , . . . , m (16) \max_a\sum_{i=1}^ma^{(i)}-\frac12\sum_{i=1}^m\sum_{j=1}^ma^{(i)}a^{(j)}y^{(i)}y^{(j)}(x^{(i)})^Tx^{(j)}\\ s.t.\quad \sum_{i=1}^ma^{(i)}y^{(i)}=0,\quad\quad 0≤α^{(i)}≤C,\ i=1,2,...,m\tag{16} amaxi=1∑ma(i)−21i=1∑mj=1∑ma(i)a(j)y(i)y(j)(x(i))Tx(j)s.t.i=1∑ma(i)y(i)=0,0≤α(i)≤C, i=1,2,...,m(16)
对于软间隔支持向量机,KKT 条件要求:
{ a ( i ) ≥ 0 , μ ( i ) ≥ 0 , y ( i ) f ( x ( i ) ) − 1 + ξ ( i ) ≥ 0 , a ( i ) ( y ( i ) f ( x ( i ) ) − 1 + ξ ( i ) ) = 0 , ξ ( i ) ≥ 0 , μ ( i ) ξ ( i ) = 0 (17) \begin{cases}a^{(i)}≥0,μ^{(i)}≥0,\\ y^{(i)}f(x^{(i)})-1+ξ^{(i)}≥0,\\ a^{(i)}(y^{(i)}f(x^{(i)})-1+ξ^{(i)})=0,\\ ξ^{(i)}≥0,μ^{(i)}ξ^{(i)}=0 \end{cases}\tag{17} ⎩⎪⎪⎪⎨⎪⎪⎪⎧a(i)≥0,μ(i)≥0,y(i)f(x(i))−1+ξ(i)≥0,a(i)(y(i)f(x(i))−1+ξ(i))=0,ξ(i)≥0,μ(i)ξ(i)=0(17)
由式 a ( i ) ( y ( i ) f ( x ( i ) ) − 1 + ξ ( i ) ) = 0 a^{(i)}(y^{(i)}f(x^{(i)})-1+ξ^{(i)})=0 a(i)(y(i)f(x(i))−1+ξ(i))=0可得,对于任意训练样本 ( x ( i ) , y ( i ) ) (x^{(i)},y^{(i)}) (x(i),y(i)),总有 a ( i ) = 0 a^{(i)}=0 a(i)=0 或者 y ( i ) f ( x ( i ) ) = 1 − ξ ( i ) y^{(i)}f(x^{(i)})=1-ξ^{(i)} y(i)f(x(i))=1−ξ(i)。
-
若 a ( i ) = 0 a^{(i)}=0 a(i)=0,由 C = μ ( i ) + a ( i ) C=μ^{(i)}+a^{(i)} C=μ(i)+a(i) 得 μ ( i ) = C μ^{(i)}=C μ(i)=C,进而得 ξ ( i ) = 0 ξ^{(i)}=0 ξ(i)=0:
y ( i ) f ( x ( i ) ) − 1 ≥ 0 (18) y^{(i)}f(x^{(i)})-1≥0\tag{18} y(i)f(x(i))−1≥0(18)- 此时, x ( i ) x^{(i)} x(i) 不会对模型 f ( x ) f(x) f(x) 产生影响。
-
若 0 < a ( i ) < C 0
y ( i ) f ( x ( i ) ) − 1 = 0 (19) y^{(i)}f(x^{(i)})-1=0\tag{19} y(i)f(x(i))−1=0(19)- 此时,样本 x ( i ) x^{(i)} x(i) 为支持向量。
-
若 a ( i ) = C a^{(i)}=C a(i)=C,则有 y ( i ) f ( x ( i ) ) − 1 + ξ ( i ) = 0 y^{(i)}f(x^{(i)})-1+ξ^{(i)}=0 y(i)f(x(i))−1+ξ(i)=0,由 C = μ ( i ) + a ( i ) C=μ^{(i)}+a^{(i)} C=μ(i)+a(i) 得 μ ( i ) = 0 μ^{(i)}=0 μ(i)=0,此时 ξ ( i ) > 0 ξ^{(i)}>0 ξ(i)>0,得:
y ( i ) f ( x ( i ) ) − 1 ≤ 0 (20) y^{(i)}f(x^{(i)})-1≤0\tag{20} y(i)f(x(i))−1≤0(20)- 此时,样本 x ( i ) x^{(i)} x(i) 落在最大间隔与决策边界之间 ( ξ ( i ) ≤ 0 ) (ξ^{(i)}≤0) (ξ(i)≤0),或者分类错误 ( ξ ( i ) > 1 ) (ξ^{(i)}>1) (ξ(i)>1)。亦即,样本异常,仍然不会被模型 f ( x ) f(x) f(x) 考虑。
综上,我们不但可以将 KKT 条件写为:
a ( i ) = 0 ⇔ y ( i ) f ( x ( i ) ) ≥ 1 0 < a ( i ) < C ⇔ y ( i ) f ( x ( i ) ) = 1 a ( i ) = C ⇔ y ( i ) f ( x ( i ) ) ≤ 1 (21) a^{(i)}=0\ ⇔\ y^{(i)}f(x^{(i)})≥1\\ 0
并且,还能够知道,采用了 hinge 损失函数的最终模型 f ( x ) f(x) f(x) 仅与支持向量有关。
核函数
假定我们面临的数据呈现下面这样的分布:
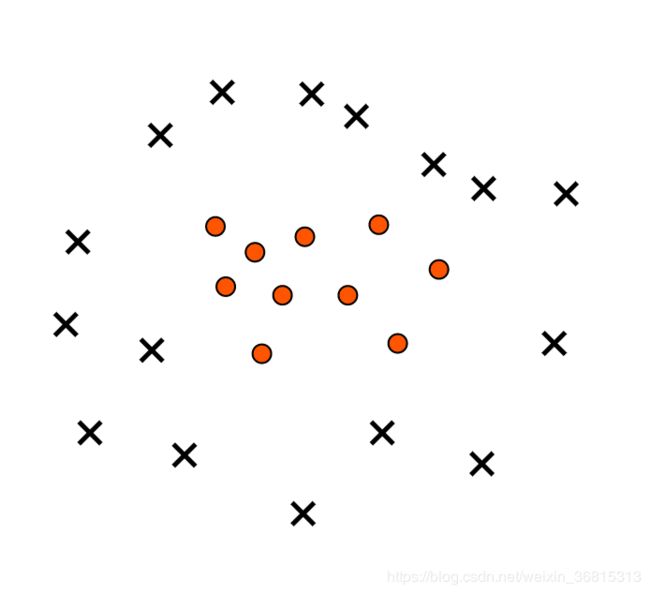
显然,这不是一个线性可分的问题,在逻辑回归中,我们会通过多项式扩展来创建新的高维特征,从而将低维度的线性不可分问题转换为了高维度的线性可分问题。
在 SVM 中,仍然是考虑将低维不可分问题转换到高维度可分问题:
f ( x ) = w T ϕ ( x ) + b (22) f(x)=w^Tϕ(x)+b\tag{22} f(x)=wTϕ(x)+b(22)
ϕ ( x ) ϕ(x) ϕ(x) 对应了 x x x 的高维度特征向量。
此时,SVM 优化模型的对偶问题为:
max a = ∑ i = 1 m a ( i ) − 1 2 ∑ i = 1 m ∑ j = 1 m a ( i ) a ( j ) y ( i ) y ( j ) ϕ ( x ( i ) ) T ϕ ( x ( i ) ) s . t . ∑ i = 1 m a ( i ) y ( i ) = 0 , 0 ≤ a ( j ) ≤ C , i = 1 , 2 , 3 , . . . , m (23) \max_a=\sum_{i=1}^m a^{(i)}-\frac12 \sum_{i=1}^m \sum_{j=1}^m a^{(i)} a^{(j)} y^{(i)} y^{(j)} ϕ(x^{(i)})^T ϕ(x^{(i)})\\ s.t. \quad \sum_{i=1}^m a^{(i)} y^{(i)}=0,\\ 0≤a^{(j)}≤C, \quad i=1,2,3,...,m \tag{23} amax=i=1∑ma(i)−21i=1∑mj=1∑ma(i)a(j)y(i)y(j)ϕ(x(i))Tϕ(x(i))s.t.i=1∑ma(i)y(i)=0,0≤a(j)≤C,i=1,2,3,...,m(23)
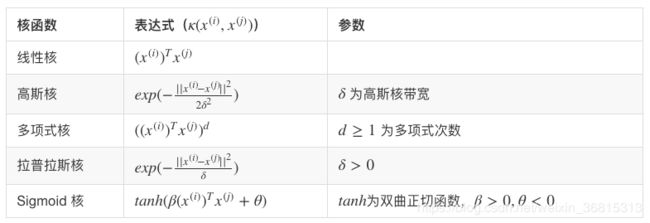
令 κ ( x ( i ) , x ( j ) ) κ(x^{(i)},x^{(j)}) κ(x(i),x(j)) 表示 x ( i ) x^{(i)} x(i) 与 x ( j ) x^{(j)} x(j)的内积:
κ ( x ( i ) , x ( j ) ) = ⟨ ϕ ( x ( i ) , ϕ ( x ( j ) ) ) ⟩ = ϕ ( x ( i ) ) T ϕ ( x ( j ) ) (24) κ(x^{(i)},x^{(j)})=⟨ϕ(x^{(i)},ϕ(x^{(j)}))⟩=ϕ(x^{(i)})^Tϕ(x^{(j)})\tag{24} κ(x(i),x(j))=⟨ϕ(x(i),ϕ(x(j)))⟩=ϕ(x(i))Tϕ(x(j))(24)
函数 κ κ κ 即表示了核函数(kernel function),引入核函数后,优化模型可以写为:
max a = ∑ i = 1 m a ( i ) − 1 2 ∑ i = 1 m ∑ j = 1 m a ( i ) a ( j ) y ( i ) y ( j ) κ ( x ( i ) , x ( j ) ) s . t . ∑ i = 1 m a ( i ) y ( i ) = 0 , 0 ≤ a ( j ) ≤ C , i = 1 , 2 , 3 , . . . , m (26) \max_a=\sum_{i=1}^m a^{(i)}-\frac12 \sum_{i=1}^m \sum_{j=1}^m a^{(i)} a^{(j)} y^{(i)} y^{(j)} κ(x^{(i)},x^{(j)})\\ s.t. \quad \sum_{i=1}^m a^{(i)} y^{(i)}=0,\\ 0≤a^{(j)}≤C, \quad i=1,2,3,...,m \tag{26} amax=i=1∑ma(i)−21i=1∑mj=1∑ma(i)a(j)y(i)y(j)κ(x(i),x(j))s.t.i=1∑ma(i)y(i)=0,0≤a(j)≤C,i=1,2,3,...,m(26)
求解后,得到模型:
f ( x ) = w T ϕ ( x ) + b = ∑ i = 1 m a ( i ) y ( i ) y ( j ) ϕ ( x ( i ) ) T ϕ ( x ) + b = ∑ i = 1 m a ( i ) y ( i ) y ( j ) κ ( x , x ( i ) ) + b (27) f(x)=w^Tϕ(x)+b=\sum_{i=1}^m a^{(i)} y^{(i)} y^{(j)} ϕ(x^{(i)})^T ϕ(x)+b=\sum_{i=1}^m a^{(i)} y^{(i)} y^{(j)} κ(x,x^{(i)})+b\tag{27} f(x)=wTϕ(x)+b=i=1∑ma(i)y(i)y(j)ϕ(x(i))Tϕ(x)+b=i=1∑ma(i)y(i)y(j)κ(x,x(i))+b(27)
参考资料
- 《机器学习》
- 支持向量机通俗导论(理解 SVM 的三层境界)
- 支持向量机