第十三章、集合---Collection集合、迭代器、增强for、List集合、Set集合
Collection
文章目录
- Collection
- 主要内容
- 学习目标
- 第十三章 集合(续)
- 13.2 集合框架
- 13.3 Collection 常用功能
- 13.4 Iterator迭代器
- 13.4.1 Iterator接口
- 13.4.2 迭代器的实现原理
- 13.4.3 使用Iterator迭代器删除元素
- 13.4.4 增强for
- 练习1:遍历数组
- 练习2:遍历集合
- 13.4.5 java.lang.Iterable接口
- 13.4.6 Java中modCount的用法,快速失败(fail-fast)机制
- 13.4.7 foreach和 Iterator的关系?
- 13.5 List集合
- 13.5.1 List接口介绍
- 13.5.2 List接口中常用方法
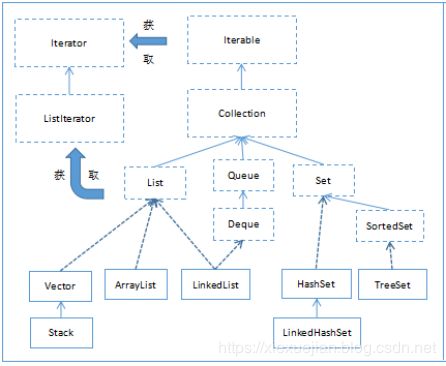
- 13.5.3 List的实现类
- ArrayList集合
- Vector集合
- Stack集合
- LinkedList集合
- 补充:动态数组与LinkedList的区别
- 补充:我们使用时,如何选择ArrayList或LinkdeList?
- 13.5.4 ListIterator
- 13.5.5 源码分析
- (1)Vector源码分析
- (2)ArrayList源码分析
- (3)LinkedList源码分析
- 13.6 Set集合
- 13.6.1 HashSet
- 13.6.2 LinkedHashSet
- 13.6.3 TreeSet
- 自然顺序
- 定制排序
- 13.6.4 如何选用HashSet、LinkedHashSet、TreeSet
- 13.6.5 补充:Set不可重复的讲解
- 13.6.6 小总结
主要内容
- Collection集合
- 迭代器
- 增强for
- List集合
- Set集合
学习目标
- 能够说出集合与数组的区别
- 说出Collection集合的常用功能
- 能够使用迭代器对集合进行取元素
- 能够说出集合的使用细节
- 能够使用集合存储自定义类型
- 能够使用foreach循环遍历集合
- 能够说出List集合和Set集合的区别
- 能够说出List集合各种实现类的区别
- 能够说出Set集合各种实现类的区别
第十三章 集合(续)
13.2 集合框架
- 集合:集合是java中提供的一种容器,可以用来存储多个数据。
集合和数组既然都是容器,它们有啥区别呢?
- 数组的长度是固定的。集合的长度是可变的。
- 数组中存储的是同一类型的元素,可以存储基本数据类型值。集合存储的都是对象。而且对象的类型可以不一致。在开发中一般当对象多的时候,使用集合进行存储。
为了可以满足用户数据更多种的逻辑关系,而设计的一系列的不同于数组的可变的聚合的抽象数据类型。这些接口和类在java.util包中,因为类型很丰富,因此我们通常称为集合框架集。
集合主要分为两大系列:Collection和Map,Collection 表示一组对象,Map表示一组映射关系或键值对。
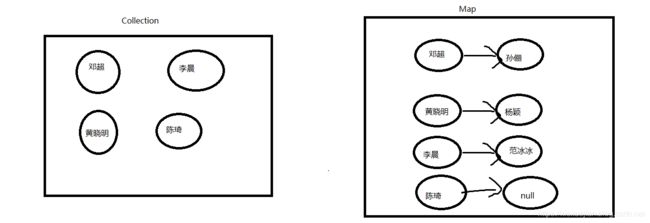
-
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。JDK 不提供此接口的任何直接实现:它提供更具体的子接口(如 Set 和 List、Queue)实现。此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。
- List:有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
- Queue:队列通常(但并非一定)以 FIFO(先进先出)的方式排序各个元素。不过优先级队列和 LIFO 队列(或堆栈)例外,前者根据提供的比较器或元素的自然顺序对元素进行排序,后者按 LIFO(后进先出)的方式对元素进行排序。
- Set:一个不包含重复元素的 collection。更确切地讲,set 不包含满足 e1.equals(e2) 的元素对 e1 和 e2,并且最多包含一个 null 元素。正如其名称所暗示的,此接口模仿了数学上的 set 抽象。
- SortedSet进一步提供关于元素的总体排序 的 Set。这些元素使用其自然顺序进行排序,或者根据通常在创建有序 set 时提供的 Comparator进行排序。该 set 的迭代器将按元素升序遍历 set。提供了一些附加的操作来利用这种排序。
-
Map:将键映射到值(key,value)的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。 Map 接口提供三种collection 视图,允许以键集、值集或键-值映射关系集的形式查看某个映射的内容。映射顺序 定义为迭代器在映射的 collection 视图上返回其元素的顺序。某些映射实现可明确保证其顺序,如 TreeMap 类;另一些映射实现则不保证顺序,如 HashMap 类。
- SortedMap进一步提供关于键的总体排序 的 Map。该映射是根据其键的自然顺序进行排序的,或者根据通常在创建有序映射时提供的 Comparator 进行排序。

补充
/*
* 集合:
* 容器,用一种数据结构来存储数据。
*
* 数组:
* (1)长度固定的
* (2)数组中的元素的类型是一致的
* (3)数组的元素可以是基本数据类型,也可以是引用数据类型
*
* 集合:
* (1)可以自动扩容
* (2)集合中的元素可以是各种数据类型
* (3)集合中的元素必须是引用数据类型
* (4)集合的类型有很多种,更丰富
*
* 集合有两大类:
* (1)Collection系列:
* 对象之间是没有关系的,一个一个的对象
* 单身party
* (2)Map系列
* 存储的是键值对(key,value)
* 情侣party
*
* java.util.Collection:接口。
* Collection是Collection系列的集合的根接口。
* 存到Collection集合中的对象是单个的,这个对象称为元素。
* 一些 collection 允许有重复的元素(List),而另一些则不允许(Set)。
* 一些 collection 是有序的(ArrayList,TreeSet。。。),而另一些则是无序的(HashSet。。。)。
* JDK 不提供此接口的任何直接 实现:它提供更具体的子接口(如 Set 和 List)实现。
* 此接口通常用来传递 collection,并在需要最大普遍性的地方操作这些 collection。 即Collection中是单值集合的共性的操作。
*/
13.3 Collection 常用功能
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
1、添加元素
(1)add(E obj):添加元素对象到当前集合中
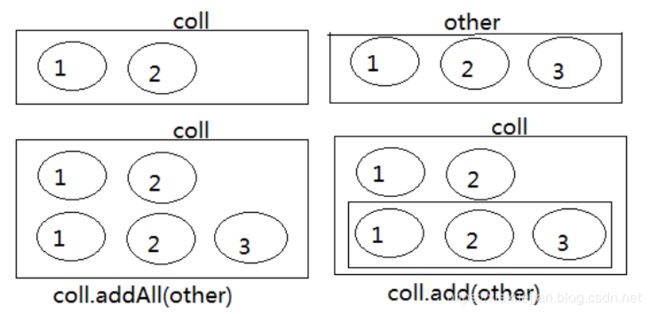
(2)addAll(Collection other):添加other集合中的所有元素对象到当前集合中,即this = this ∪ other
2、删除元素
(1) boolean remove(Object obj) :从当前集合中删除第一个找到的与obj对象equals返回true的元素。
(2)boolean removeAll(Collection coll):从当前集合中删除所有与coll集合中相同的元素。即this = this - this ∩ coll
3、判断元素
(1)boolean isEmpty():判断当前集合是否为空集合。
(2)boolean contains(Object obj):判断当前集合中是否存在一个与obj对象equals返回true的元素。
(3)boolean containsAll(Collection c):判断c集合中的元素是否在当前集合中都存在。即c集合是否是当前集合的“子集”。
4、查询
(1)int size():获取当前集合中实际存储的元素个数
(2)Object[] toArray():返回包含当前集合中所有元素的数组
5、交集
(1)boolean retainAll(Collection coll):当前集合仅保留与c集合中的元素相同的元素,即当前集合中仅保留两个集合的交集,即this = this ∩ coll; 注意:这个方法要保证this和coll中的元素数据类型一致才有效。否则不可能有交集
方法演示:
import java.util.ArrayList;
import java.util.Collection;
public class Demo1Collection {
public static void main(String[] args) {
// 创建集合对象
// 使用多态形式
Collection<String> coll = new ArrayList<String>();
// 使用方法
// 添加功能 boolean add(String s)
coll.add("小李广");
coll.add("扫地僧");
coll.add("石破天");
System.out.println(coll);
// boolean contains(E e) 判断o是否在集合中存在
System.out.println("判断 扫地僧 是否在集合中"+coll.contains("扫地僧"));
//boolean remove(E e) 删除在集合中的o元素
System.out.println("删除石破天:"+coll.remove("石破天"));
System.out.println("操作之后集合中元素:"+coll);
// size() 集合中有几个元素
System.out.println("集合中有"+coll.size()+"个元素");
// Object[] toArray()转换成一个Object数组
Object[] objects = coll.toArray();
// 遍历数组
for (int i = 0; i < objects.length; i++) {
System.out.println(objects[i]);
}
// void clear() 清空集合
coll.clear();
System.out.println("集合中内容为:"+coll);
// boolean isEmpty() 判断是否为空
System.out.println(coll.isEmpty());
}
}
@Test
public void test2(){
Collection coll = new ArrayList();
coll.add(1);
coll.add(2);
System.out.println("coll集合元素的个数:" + coll.size());
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(3);
coll.addAll(other);
// coll.add(other);
System.out.println("coll集合元素的个数:" + coll.size());
}
注意:coll.addAll(other);与coll.add(other);
@Test
public void test5(){
Collection coll = new ArrayList();
coll.add(1);
coll.add(2);
coll.add(3);
coll.add(4);
coll.add(5);
System.out.println("coll集合元素的个数:" + coll.size());//5
Collection other = new ArrayList();
other.add(1);
other.add(2);
other.add(8);
coll.retainAll(other);//保留交集
System.out.println("coll集合元素的个数:" + coll.size());//2
}
13.4 Iterator迭代器
13.4.1 Iterator接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK专门提供了一个接口java.util.Iterator。Iterator接口也是Java集合中的一员,但它与Collection、Map接口有所不同,Collection接口与Map接口主要用于存储元素,而Iterator主要用于迭代访问(即遍历)Collection中的元素,因此Iterator对象也被称为迭代器。
想要遍历Collection集合,那么就要获取该集合迭代器完成迭代操作,下面介绍一下获取迭代器的方法:
public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
下面介绍一下迭代的概念:
- 迭代:即Collection集合元素的通用获取方式。在取元素之前先要判断集合中有没有元素,如果有,就把这个元素取出来,继续在判断,如果还有就再取出出来。一直把集合中的所有元素全部取出。这种取出方式专业术语称为迭代。
Iterator接口的常用方法如下:
public E next():返回迭代的下一个元素。public boolean hasNext():如果仍有元素可以迭代,则返回 true。
接下来我们通过案例学习如何使用Iterator迭代集合中元素:
public class IteratorDemo {
public static void main(String[] args) {
// 使用多态方式 创建对象
Collection<String> coll = new ArrayList<String>();
// 添加元素到集合
coll.add("串串星人");
coll.add("吐槽星人");
coll.add("汪星人");
//遍历
//使用迭代器 遍历 每个集合对象都有自己的迭代器
Iterator<String> it = coll.iterator();
// 泛型指的是 迭代出 元素的数据类型
while(it.hasNext()){ //判断是否有迭代元素
String s = it.next();//获取迭代出的元素
System.out.println(s);
}
}
}
tips::在进行集合元素取出时,如果集合中已经没有元素了,还继续使用迭代器的next方法,将会发生java.util.NoSuchElementException没有集合元素的错误。
13.4.2 迭代器的实现原理
我们在之前案例已经完成了Iterator遍历集合的整个过程。当遍历集合时,首先通过调用集合的iterator()方法获得迭代器对象,然后使用hashNext()方法判断集合中是否存在下一个元素,如果存在,则调用next()方法将元素取出,否则说明已到达了集合末尾,停止遍历元素。
Iterator迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,为了让初学者能更好地理解迭代器的工作原理,接下来通过一个图例来演示Iterator对象迭代元素的过程:

在调用Iterator的next方法之前,迭代器的索引位于第一个元素之前,不指向任何元素,当第一次调用迭代器的next方法后,迭代器的索引会向后移动一位,指向第一个元素并将该元素返回,当再次调用next方法时,迭代器的索引会指向第二个元素并将该元素返回,依此类推,直到hasNext方法返回false,表示到达了集合的末尾,终止对元素的遍历。
13.4.3 使用Iterator迭代器删除元素
java.util.Iterator迭代器中有一个方法:
void remove() ;
那么,既然Collection已经有remove(xx)方法了,为什么Iterator迭代器还要提供删除方法呢?
因为Collection的remove方法,无法根据条件删除。
例如:要删除以下集合元素中,名字是三个字的人名
@Test
public void test02(){
Collection<String> coll = new ArrayList<>();
coll.add("陈琦");
coll.add("李晨");
coll.add("邓超");
coll.add("黄晓明");
//删除名字有三个字的
// coll.remove(o)//无法编写
Iterator<String> iterator = coll.iterator();
while(iterator.hasNext()){
String element = iterator.next();
if(element.length()==3){
// coll.remove(element);//错误的
iterator.remove();
}
}
System.out.println(coll);
}
注意:不要在使用Iterator迭代器进行迭代时,调用Collection的remove(xx)方法,否则会报异常java.util.ConcurrentModificationException,或出现不确定行为。
13.4.4 增强for
增强for循环(也称for each循环)是JDK1.5以后出来的一个高级for循环,专门用来遍历数组和集合的。
格式:
语法格式:
for(集合的元素类型 集合的元素名 : 集合名称){
}
for(数组的元素类型 数组的元素名 : 数组名称){
}
//集合的元素名和数组的元素名自己命名的。
它用于遍历Collection和数组。通常只进行遍历元素,不要在遍历的过程中对集合元素进行增删操作。
foreach和for循环的区别?
(1)foreach更快更简洁
(2)foreach没有下标信息
(3)foreach不能用于 修改元素,可以修改元素的属性
练习1:遍历数组
public class NBForDemo1 {
public static void main(String[] args) {
int[] arr = {3,5,6,87};
//使用增强for遍历数组
for(int a : arr){//a代表数组中的每个元素
System.out.println(a);
}
}
}
练习2:遍历集合
public class NBFor {
public static void main(String[] args) {
Collection<String> coll = new ArrayList<String>();
coll.add("小河神");
coll.add("老河神");
coll.add("神婆");
//使用增强for遍历
for(String s :coll){//接收变量s代表 代表被遍历到的集合元素
System.out.println(s);
}
}
}
tips: 新for循环必须有被遍历的目标。目标只能是Collection等或者是数组。新式for仅仅作为遍历操作出现。
13.4.5 java.lang.Iterable接口
java.lang.Iterable接口,实现这个接口允许对象成为 “foreach” 语句的目标。
Java 5时Collection接口继承了java.lang.Iterable接口,因此Collection系列的集合就可以直接使用foreach循环遍历。
java.lang.Iterable接口的抽象方法:
- public Iterator iterator(): 获取对应的迭代器,用来遍历数组或集合中的元素的。
代码示例:
让昨天我们自定义的动态数组支持foreach遍历
自定义动态数组:
import java.util.Arrays;
import java.util.Iterator;
import java.util.NoSuchElementException;
public class MyArrayList<E> implements Iterable<E>{
private Object[] all;
private int total;
public MyArrayList(){
all = new Object[5];
}
public void add(E e) {
ensureCapacityEnough();
all[total++] = e;
}
private void ensureCapacityEnough() {
if(total >= all.length){
all = Arrays.copyOf(all, all.length*2);
}
}
//...省略其他代码
@Override
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E>{
int cursor;
@Override
public boolean hasNext() {
return cursor<=total;
}
@SuppressWarnings("unchecked")
@Override
public E next() {
return (E) all[cursor++];
}
}
}
测试类:
public class TestForeach {
public static void main(String[] args) {
MyArrayList<String> my = new MyArrayList<String>();
my.add("hello");
my.add("java");
my.add("world");
my.add("atguigu");
my.add("list");
my.add("data");
for (String string : my) {
System.out.println(string);
}
}
}
同理,因为foreach本质上就是使用Iterator迭代器进行遍历的,所以也不要在foreach遍历的过程使用Collection的remove()方法。否则,要么报异常java.util.ConcurrentModificationException,要么行为不确定。
@Test
public void test07(){
Collection<Student> coll = new ArrayList<>();
coll.add(new Student("陈琦"));
coll.add(new Student("李晨"));
coll.add(new Student("邓超"));
coll.add(new Student("黄晓明"));
//调用ArrayList里面的Iterator iterator()
for (Student student : coll) {
if("黄晓明".equals(student.getName())){
coll.remove(student);
}
}
System.out.println(coll);
}
13.4.6 Java中modCount的用法,快速失败(fail-fast)机制
当使用foreach或Iterator迭代器遍历集合时,同时调用迭代器自身以外的方法修改了集合的结构,例如调用集合的add和remove方法时,就会报ConcurrentModificationException。
@Test
public void test01() {
Collection<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("world");
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
list.delete(iterator.next());
}
}
如果在Iterator、ListIterator迭代器创建后的任意时间从结构上修改了集合(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
这样设计是因为,迭代器代表集合中某个元素的位置,内部会存储某些能够代表该位置的信息。当集合发生改变时,该信息的含义可能会发生变化,这时操作迭代器就可能会造成不可预料的事情。因此,果断抛异常阻止,是最好的方法。这就是Iterator迭代器的快速失败(fail-fast)机制。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在不同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的方式是错误的,正确做法是:*迭代器的快速失败行为应该仅用于检测 bug。*例如:
@Test
public void test02() {
ArrayList<String> list = new ArrayList<>();
list.add("hello");
list.add("java");
list.add("atguigu");
list.add("world");
//以下代码没有发生ConcurrentModificationException异常
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String str = iterator.next();
if("atguigu".endsWith(str)){
list.remove(str);
}
}
}
那么如何实现快速失败(fail-fast)机制的呢?
- 在ArrayList等集合类中都有一个modCount变量。它用来记录集合的结构被修改的次数。
- 当我们给集合添加和删除操作时,会导致modCount++。
- 然后当我们用Iterator迭代器遍历集合时,创建集合迭代器的对象时,用一个变量记录当前集合的modCount。例如:
int expectedModCount = modCount;,并且在迭代器每次next()迭代元素时,都要检查expectedModCount != modCount,如果不相等了,那么说明你调用了Iterator迭代器以外的Collection的add,remove等方法,修改了集合的结构,使得modCount++,值变了,就会抛出ConcurrentModificationException。
下面以AbstractList和ArrayList.Itr迭代器为例进行源码分析:
AbstractList类中声明了modCount变量:
/**
* The number of times this list has been structurally modified.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* fail-fast behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
*
Use of this field by subclasses is optional. If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;
modCount是这个list被结构性修改的次数。结构性修改是指:改变list的size大小,或者,以其他方式改变他导致正在进行迭代时出现错误的结果。
这个字段用于迭代器和列表迭代器的实现类中,由迭代器和列表迭代器方法返回。如果这个值被意外改变,这个迭代器将会抛出 ConcurrentModificationException的异常来响应:next,remove,previous,set,add 这些操作。在迭代过程中,他提供了fail-fast行为而不是不确定行为来处理并发修改。
子类使用这个字段是可选的,如果子类希望提供fail-fast迭代器,它仅仅需要在add(int, E),remove(int)方法(或者它重写的其他任何会结构性修改这个列表的方法)中添加这个字段。调用一次add(int,E)或者remove(int)方法时必须且仅仅给这个字段加1,否则迭代器会抛出伪装的ConcurrentModificationExceptions错误。如果一个实现类不希望提供fail-fast迭代器,则可以忽略这个字段。
Arraylist的Itr迭代器:
private class Itr implements Iterator<E> {
int cursor;
int lastRet = -1;
int expectedModCount = modCount;//在创建迭代器时,expectedModCount初始化为当前集合的modCount的值
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();//校验expectedModCount与modCount是否相等
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)//校验expectedModCount与modCount是否相等
throw new ConcurrentModificationException();//不相等,抛异常
}
}
13.4.7 foreach和 Iterator的关系?
java.lang.Iterable:可迭代的接口
Iterator iterator()
java.util.Iterator:迭代器接口
Collection:接口
Collection继承了Iterable接口,所以Collection系列的集合有Iterator iterator() 方法。
实现了Iterarable接口的类型,就允许对象成为 “foreach” 语句的目标。
foreach底层也是使用Iterator迭代器进行迭代的
同理,Iterator迭代时,要删除元素的话使用,Iterator自己的remove方法,
同理,foreach迭代时,也不能调用Collection的remove(xx)方法。
切记:在用Iterator迭代和foreach迭代时都不要使用Collection的remove,add等会修改Collection的元素个数的操作。
否则要么会报错,要么会有意外。
13.5 List集合
我们掌握了Collection接口的使用后,再来看看Collection接口中的子类,他们都具备那些特性呢?
13.5.1 List接口介绍
java.util.List接口继承自Collection接口,是单列集合的一个重要分支,习惯性地会将实现了List接口的对象称为List集合。
List接口特点:
- List集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是11、22、33。那么集合中,元素的存储就是按照11、22、33的顺序完成的)
- 它是一个元素存取有序的集合。即元素的存入顺序和取出顺序一致。
- 它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
- 集合中可以有重复的元素,通过元素的equals方法,来比较是否为重复的元素。
List集合类中元素有序、且可重复。这就像银行门口客服,给每一个来办理业务的客户分配序号:第一个来的是“张三”,客服给他分配的是0;第二个来的是“李四”,客服给他分配的1;以此类推,最后一个序号应该是“总人数-1”。

注意:
List集合关心元素是否有序,而不关心是否重复,请大家记住这个原则。例如“张三”可以领取两个号。
补充
List接口的实现类们:
- (1)ArrayList:动态数组
- (2)Vector:动态数组
- (3)LinkedList:链表
- (4)Stack:栈
13.5.2 List接口中常用方法
List作为Collection集合的子接口,不但继承了Collection接口中的全部方法,而且还增加了一些根据元素索引来操作集合的特有方法,如下:
List除了从Collection集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
1、添加元素
- void add(int index, E ele)
- boolean addAll(int index, Collection eles)
2、获取元素
- E get(int index)
- List subList(int fromIndex, int toIndex)
3、获取元素索引
- int indexOf(Object obj)
- int lastIndexOf(Object obj)
4、删除和替换元素
- E remove(int index)
- E set(int index, E ele)
List集合特有的方法都是跟索引相关:
public class ListDemo {
public static void main(String[] args) {
// 创建List集合对象
List<String> list = new ArrayList<String>();
// 往 尾部添加 指定元素
list.add("图图");
list.add("小美");
list.add("不高兴");
System.out.println(list);
// add(int index,String s) 往指定位置添加
list.add(1,"没头脑");
System.out.println(list);
// String remove(int index) 删除指定位置元素 返回被删除元素
// 删除索引位置为2的元素
System.out.println("删除索引位置为2的元素");
System.out.println(list.remove(2));
System.out.println(list);
// String set(int index,String s)
// 在指定位置 进行 元素替代(改)
// 修改指定位置元素
list.set(0, "三毛");
System.out.println(list);
// String get(int index) 获取指定位置元素
// 跟size() 方法一起用 来 遍历的
for(int i = 0;i<list.size();i++){
System.out.println(list.get(i));
}
//还可以使用增强for
for (String string : list) {
System.out.println(string);
}
}
}
在JavaSE中List名称的类型有两个,一个是java.util.List集合接口,一个是java.awt.List图形界面的组件,别导错包了。
13.5.3 List的实现类
ArrayList集合
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。
许多程序员开发时非常随意地使用ArrayList完成任何需求,并不严谨,这种用法是不提倡的。
Vector集合
ArrayList与Vector的区别?
它们的底层物理结构都是数组,我们称为动态数组。
- ArrayList是新版的动态数组,线程不安全,效率高,Vector是旧版的动态数组,线程安全,效率低。
- 动态数组的扩容机制不同,ArrayList扩容为原来的
1.5倍,Vector扩容增加为原来的2倍。 - 数组的初始化容量,如果在构建ArrayList与Vector的集合对象时,没有显式指定初始化容量,那么Vector的内部数组的初始容量默认为10,而ArrayList在JDK1.6及之前的版本也是10,而JDK1.7之后的版本ArrayList初始化为长度为0的空数组,之后在添加第一个元素时,再创建长度为10的数组。
- Vector因为版本古老,支持Enumeration 迭代器。但是该迭代器不支持快速失败。而Iterator和ListIterator迭代器支持快速失败。如果在迭代器创建后的任意时间从结构上修改了向量(通过迭代器自身的 remove 或 add 方法之外的任何其他方式),则迭代器将抛出
ConcurrentModificationException。因此,面对并发的修改,迭代器很快就完全失败,而不是冒着在将来不确定的时间任意发生不确定行为的风险。
Vector中的Enumeration迭代器:
public void test(){
Vector<String> v = new Vector<>();
v.addElement("hello");
v.addElement("java");
//Enumeration迭代器不支持快速失败
Enumeration<String> elements = v.elements();
while(elements.hasMoreElements()){
String e = elements.nextElement();
System.out.println(e);
}
}
Stack集合
java.util.Stack是Vector集合的子类。
比List多了几个方法
- (1)peek:查看栈顶元素,不弹出
- (2)pop:弹出栈
-
(3)push:压入栈 即添加到链表的头
-
建议:如果想要使用堆栈的数据结构来解决问题,建议使用ArrayQueue或LinkedList,而不是Stack。
@Test
public void test3(){
Stack<Integer> list = new Stack<>();
list.push(1);
list.push(2);
list.push(3);
System.out.println(list);
/*System.out.println(list.pop());
System.out.println(list.pop());
System.out.println(list.pop());
System.out.println(list.pop());//java.util.NoSuchElementException
*/
System.out.println(list.peek());
System.out.println(list.peek());
System.out.println(list.peek());
}
LinkedList集合
java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
除了实现 List 接口外,LinkedList 类还为在列表的开头及结尾 get、remove 和 insert 元素提供了统一的命名方法。这些操作允许将链接列表用作堆栈、队列或双端队列。
LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下

JDK1.6之后LinkedList实现了Deque接口。双端队列也可用作 LIFO(后进先出)堆栈。如果要使用堆栈结构的集合,可以考虑使用LinkedList,而不是Stack。
| 堆栈方法 | 等效Deque方法 |
|---|---|
| push(e) | addFirst(e) |
| pop() | removeFirst() |
| peek() | peekFirst() |
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
//入栈
list.addFirst(1);
list.addFirst(2);
list.addFirst(3);
//出栈: LIFO(后进先出)
System.out.println(list.removeFirst());//3
System.out.println(list.removeFirst());//2
System.out.println(list.removeFirst());//1
//栈空了,会报异常java.util.NoSuchElementException
System.out.println(list.removeFirst());
}
Stack与LinkedList都能作为栈结构,对外表现的功能效果是一样,但是它们的物理结构不同,Stack的物理结构是顺序结构的数组,而LinkedList的物理结构是链式结构的双向链表。我们推荐使用LinkedList。
用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。
| Queue 方法 | 等效 Deque 方法 |
|---|---|
| add(e) | addLast(e) |
| offer(e) | offerLast(e) |
| remove() | removeFirst() |
| poll() | pollFirst() |
| element() | getFirst() |
| peek() | peekFirst() |
public static void main(String[] args) {
LinkedList<Integer> list = new LinkedList<>();
//入队
list.addLast(1);
list.addLast(2);
list.addLast(3);
//出队, FIFO(先进先出)
System.out.println(list.pollFirst());//1
System.out.println(list.pollFirst());//2
System.out.println(list.pollFirst());//3
//队空了,返回null
System.out.println(list.pollFirst());//null
}
每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
| 第一个元素(头部) | 第一个元素(头部) | 最后一个元素(尾部) | 最后一个元素(尾部) | |
|---|---|---|---|---|
| 抛出异常 | 特殊值 | 抛出异常 | 特殊值 | |
| 插入 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 移除 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 检查 | getFirst() | peekFirst() | getLast() | peekLast() |
补充:动态数组与LinkedList的区别
动态数组的物理结构是数组
LinkedList的物理结构是双向链表数组:(1)需要扩容
(2)添加和删除需要移动元素
(3)可能会造成空间浪费
(4)需要开辟连续的整块的存储空间
(5)优点:根据[index]查询的速度很快链表:(1)不需要扩容
(2)在添加和删除元素时,不需要移动元素,只要修改前后元素的引用关系
(3)来一个连接一个,删除一个少一个,没有空间浪费
(4)不需要连续的存储空间
(5)查找元素的速度比较慢,只能从first或last开始查找LinkedList它不仅仅实现了List接口,还实现Queue,Deque等接口,提供的很多方法,
使得LinkedList的集合可以作为普通列表,堆栈,队列,双端队列等数据结构来使用。
/*
*动态数组的物理结构:数组
* LinkedList的物理结构:双向链表
* 单向链表的结点:
* class OneWayLinkedList{
* private Node head;
* private int total;
private staic class Node{
E element;
Node next;
}
}
* 双向链表的结点:
* class LinkedList{
* private Node first;
* private Node last;
* private int size;
*
* private static class Node{
* Node prev;
* E element;
* Node next;
* }
* }
*
* 数组:
* (1)可以通过[index]快速的定位到某个元素
* (2)当插入、删除元素的时候,需要移动元素System.arraycopy(...)
* (3)当添加时,还需要自动扩容
* 当不断扩容时,空闲的元素的越来越多,空间利用率低
* (4)数组需要连续的存储空间
* 当数组比较大的时候,寻找连续的存储空间比较费劲。
*
*
* 链表:
* (1)当插入、删除元素时,不需要移动元素,修要修改前后的关系
* 例如:插入newNode,在node1和node2之间插入
* 插入: node1.next = newNode
* newNode.prev = node1;
* node2.prev = newNode;
* newNode.next = node2;
* 例如:删除node
* 找到node的前一个 node1,以及node的后一个结点node2
* node1.next = node2;
* node2.prev = node1;
*
* 以下操作,使得node结点彻底称为垃圾,被回收
* node.prev = null;
* node.next = null;
* node.element = null;
* (2)当不断添加元素时,只是增加结点的个数,不会有多余的空间浪费
* (3)链表的元素的地址不需要连续,因为前后元素的关系不是靠下标,而是通过next,prev来查找即可。这个更灵活
* (4)在查找时,如果是单链表只能从前往后,
* 如果是双链表,可以从前往后,或从后往前
* (5)因为链表没有下标,如果你调用和[index]相关的方法时,都要从头或从尾现数
* LindedList也是List的实现类,List接口中有和[index]相关的方法
*
*/
//假设:LinkedList要实现get(int index)的方法,如何实现?
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
补充:我们使用时,如何选择ArrayList或LinkdeList?
如果你接下来的操作是查询多,那么使用ArrayList更快。
如果你接下来的操作是添加,删除等多,而且元素的个数非常不确定,但是比较多,那么建议使用LinkedList更好。
13.5.4 ListIterator
List 集合额外提供了一个 listIterator() 方法,该方法返回一个 ListIterator 对象, ListIterator 接口继承了 Iterator 接口,提供了专门操作 List 的方法:
- void add():通过迭代器添加元素到对应集合
- void set(Object obj):通过迭代器替换正迭代的元素
- void remove():通过迭代器删除刚迭代的元素
- boolean hasPrevious():如果以逆向遍历列表,往前是否还有元素。
- Object previous():返回列表中的前一个元素。
- int previousIndex():返回列表中的前一个元素的索引
- boolean hasNext()
- Object next()
- int nextIndex()
public static void main(String[] args) {
List<Student> c = new ArrayList<>();
c.add(new Student(1,"张三"));
c.add(new Student(2,"李四"));
c.add(new Student(3,"王五"));
c.add(new Student(4,"赵六"));
c.add(new Student(5,"钱七"));
//从指定位置往前遍历
ListIterator<Student> listIterator = c.listIterator(c.size());
while(listIterator.hasPrevious()){
Student previous = listIterator.previous();
System.out.println(previous);
}
}
13.5.5 源码分析
(1)Vector源码分析
public Vector() {
this(10);//指定初始容量initialCapacity为10
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);//指定capacityIncrement增量为0
}
public Vector(int initialCapacity, int capacityIncrement增量为0) {
super();
//判断了形参初始容量initialCapacity的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//创建了一个Object[]类型的数组
this.elementData = new Object[initialCapacity];//默认是10
//增量,默认是0,如果是0,后面就按照2倍增加,如果不是0,后面就按照你指定的增量进行增量
this.capacityIncrement = capacityIncrement;
}
//synchronized意味着线程安全的
public synchronized boolean add(E e) {
modCount++;
//看是否需要扩容
ensureCapacityHelper(elementCount + 1);
//把新的元素存入[elementCount],存入后,elementCount元素的个数增1
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
//看是否超过了当前数组的容量
if (minCapacity - elementData.length > 0)
grow(minCapacity);//扩容
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//获取目前数组的长度
//如果capacityIncrement增量是0,新容量 = oldCapacity的2倍
//如果capacityIncrement增量是不是0,新容量 = oldCapacity + capacityIncrement增量;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//如果按照上面计算的新容量还不够,就按照你指定的需要的最小容量来扩容minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果新容量超过了最大数组限制,那么单独处理
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//把旧数组中的数据复制到新数组中,新数组的长度为newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
public boolean remove(Object o) {
return removeElement(o);
}
public synchronized boolean removeElement(Object obj) {
modCount++;
//查找obj在当前Vector中的下标
int i = indexOf(obj);
//如果i>=0,说明存在,删除[i]位置的元素
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
public int indexOf(Object o) {
return indexOf(o, 0);
}
public synchronized int indexOf(Object o, int index) {
if (o == null) {//要查找的元素是null值
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)//如果是null值,用==null判断
return i;
} else {//要查找的元素是非null值
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))//如果是非null值,用equals判断
return i;
}
return -1;
}
public synchronized void removeElementAt(int index) {
modCount++;
//判断下标的合法性
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
//j是要移动的元素的个数
int j = elementCount - index - 1;
//如果需要移动元素,就调用System.arraycopy进行移动
if (j > 0) {
//把index+1位置以及后面的元素往前移动
//index+1的位置的元素移动到index位置,依次类推
//一共移动j个
System.arraycopy(elementData, index + 1, elementData, index, j);
}
//元素的总个数减少
elementCount--;
//将elementData[elementCount]这个位置置空,用来添加新元素,位置的元素等着被GC回收
elementData[elementCount] = null; /* to let gc do its work */
}
(2)ArrayList源码分析
JDK1.6:
public ArrayList() {
this(10);//指定初始容量为10
}
public ArrayList(int initialCapacity) {
super();
//检查初始容量的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
//数组初始化为长度为initialCapacity的数组
this.elementData = new Object[initialCapacity];
}
JDK1.7
private static final int DEFAULT_CAPACITY = 10;//默认初始容量10
private static final Object[] EMPTY_ELEMENTDATA = {};
public ArrayList() {
super();
this.elementData = EMPTY_ELEMENTDATA;//数组初始化为一个空数组
}
public boolean add(E e) {
//查看当前数组是否够多存一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == EMPTY_ELEMENTDATA) {//如果当前数组还是空数组
//minCapacity按照 默认初始容量和minCapacity中的的最大值处理
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//看是否需要扩容处理
ensureExplicitCapacity(minCapacity);
}
//...
JDK1.8
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;//初始化为空数组
}
public boolean add(E e) {
//查看当前数组是否够多存一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
//存入新元素到[size]位置,然后size自增1
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
//如果当前数组还是空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//那么minCapacity取DEFAULT_CAPACITY与minCapacity的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//查看是否需要扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//修改次数加1
// 如果需要的最小容量 比 当前数组的长度 大,即当前数组不够存,就扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;//当前数组容量
int newCapacity = oldCapacity + (oldCapacity >> 1);//新数组容量是旧数组容量的1.5倍
//看旧数组的1.5倍是否够
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//看旧数组的1.5倍是否超过最大数组限制
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//复制一个新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
public boolean remove(Object o) {
//先找到o在当前ArrayList的数组中的下标
//分o是否为空两种情况讨论
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {//null值用==比较
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {//非null值用equals比较
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;//修改次数加1
//需要移动的元素个数
int numMoved = size - index - 1;
//如果需要移动元素,就用System.arraycopy移动元素
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将elementData[size-1]位置置空,让GC回收空间,元素个数减少
elementData[--size] = null; // clear to let GC do its work
}
public E remove(int index) {
rangeCheck(index);//检验index是否合法
modCount++;//修改次数加1
//取出[index]位置的元素,[index]位置的元素就是要被删除的元素,用于最后返回被删除的元素
E oldValue = elementData(index);
//需要移动的元素个数
int numMoved = size - index - 1;
//如果需要移动元素,就用System.arraycopy移动元素
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//将elementData[size-1]位置置空,让GC回收空间,元素个数减少
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
public E set(int index, E element) {
rangeCheck(index);//检验index是否合法
//取出[index]位置的元素,[index]位置的元素就是要被替换的元素,用于最后返回被替换的元素
E oldValue = elementData(index);
//用element替换[index]位置的元素
elementData[index] = element;
return oldValue;
}
public E get(int index) {
rangeCheck(index);//检验index是否合法
return elementData(index);//返回[index]位置的元素
}
public int indexOf(Object o) {
//分为o是否为空两种情况
if (o == null) {
//从前往后找
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public int lastIndexOf(Object o) {
//分为o是否为空两种情况
if (o == null) {
//从后往前找
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
(3)LinkedList源码分析
int size = 0;
Node<E> first;//记录第一个结点的位置
Node<E> last;//记录最后一个结点的位置
private static class Node<E> {
E item;//元素数据
Node<E> next;//下一个结点
Node<E> prev;//前一个结点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
public boolean add(E e) {
linkLast(e);//默认把新元素链接到链表尾部
return true;
}
void linkLast(E e) {
final Node<E> l = last;//用l 记录原来的最后一个结点
//创建新结点
final Node<E> newNode = new Node<>(l, e, null);
//现在的新结点是最后一个结点了
last = newNode;
//如果l==null,说明原来的链表是空的
if (l == null)
//那么新结点同时也是第一个结点
first = newNode;
else
//否则把新结点链接到原来的最后一个结点的next中
l.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
}
public boolean remove(Object o) {
//分o是否为空两种情况
if (o == null) {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);//删除x结点
return true;
}
}
} else {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);//删除x结点
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {//x是要被删除的结点
// assert x != null;
final E element = x.item;//被删除结点的数据
final Node<E> next = x.next;//被删除结点的下一个结点
final Node<E> prev = x.prev;//被删除结点的上一个结点
//如果被删除结点的前面没有结点,说明被删除结点是第一个结点
if (prev == null) {
//那么被删除结点的下一个结点变为第一个结点
first = next;
} else {//被删除结点不是第一个结点
//被删除结点的上一个结点的next指向被删除结点的下一个结点
prev.next = next;
//断开被删除结点与上一个结点的链接
x.prev = null;//使得GC回收
}
//如果被删除结点的后面没有结点,说明被删除结点是最后一个结点
if (next == null) {
//那么被删除结点的上一个结点变为最后一个结点
last = prev;
} else {//被删除结点不是最后一个结点
//被删除结点的下一个结点的prev执行被删除结点的上一个结点
next.prev = prev;
//断开被删除结点与下一个结点的连接
x.next = null;//使得GC回收
}
//把被删除结点的数据也置空,使得GC回收
x.item = null;
//元素个数减少
size--;
//修改次数增加
modCount++;
//返回被删除结点的数据
return element;
}
13.6 Set集合
Set接口是Collection的子接口,set接口没有提供额外的方法。但是比Collection接口更加严格了。
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败,即最后一个相同的元素覆盖前面相同的元素。
Set集合支持的遍历方式和Collection集合一样:foreach和Iterator。
Set的常用实现类有:HashSet、TreeSet、LinkedHashSet。
13.6.1 HashSet
HashSet 是 Set 接口的典型实现,大多数时候使用 Set 集合时都使用这个实现类。
java.util.HashSet底层的实现其实是一个java.util.HashMap支持,然后HashMap的底层物理实现是一个Hash表。(什么是哈希表,下一节在HashMap小节在细讲,这里先不展开)
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取和查找性能。HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法比较相等,并且两个对象的 equals() 方法返回值也相等。因此,存储到HashSet的元素要重写hashCode和equals方法。
示例代码:定义一个Employee类,该类包含属性:name, birthday,其中 birthday 为 MyDate类的对象;MyDate为自定义类型,包含年、月、日属性。要求 name和birthday一样的视为同一个员工。
public class Employee {
private String name;
private MyDate birthday;
public Employee(String name, MyDate birthday) {
super();
this.name = name;
this.birthday = birthday;
}
public Employee() {
super();
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public MyDate getBirthday() {
return birthday;
}
public void setBirthday(MyDate birthday) {
this.birthday = birthday;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((birthday == null) ? 0 : birthday.hashCode());
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (birthday == null) {
if (other.birthday != null)
return false;
} else if (!birthday.equals(other.birthday))
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
@Override
public String toString() {
return "姓名:" + name + ", 生日:" + birthday;
}
}
public class MyDate {
private int year;
private int month;
private int day;
public MyDate(int year, int month, int day) {
super();
this.year = year;
this.month = month;
this.day = day;
}
public MyDate() {
super();
}
public int getYear() {
return year;
}
public void setYear(int year) {
this.year = year;
}
public int getMonth() {
return month;
}
public void setMonth(int month) {
this.month = month;
}
public int getDay() {
return day;
}
public void setDay(int day) {
this.day = day;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + day;
result = prime * result + month;
result = prime * result + year;
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
MyDate other = (MyDate) obj;
if (day != other.day)
return false;
if (month != other.month)
return false;
if (year != other.year)
return false;
return true;
}
@Override
public String toString() {
return year + "-" + month + "-" + day;
}
}
import java.util.HashSet;
public class TestHashSet {
@SuppressWarnings("all")
public static void main(String[] args) {
HashSet<Employee> set = new HashSet<>();
set.add(new Employee("张三", new MyDate(1990,1,1)));
//重复元素无法添加,因为MyDate和Employee重写了hashCode和equals方法
set.add(new Employee("张三", new MyDate(1990,1,1)));
set.add(new Employee("李四", new MyDate(1992,2,2)));
for (Employee object : set) {
System.out.println(object);
}
}
}
13.6.2 LinkedHashSet
LinkedHashSet是HashSet的子类,它在HashSet的基础上,在结点中增加两个属性before和after维护了结点的前后添加顺序。java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。LinkedHashSet插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("张三");
set.add("李四");
set.add("王五");
set.add("张三");
System.out.println("元素个数:" + set.size());
for (String name : set) {
System.out.println(name);
}
运行结果:
元素个数:3
张三
李四
王五
13.6.3 TreeSet
底层结构:里面维护了一个TreeMap,都是基于红黑树实现的!
特点:
1、不允许重复
2、实现排序
自然排序或定制排序
如何实现去重的?
如果使用的是自然排序,则通过调用实现的compareTo方法
如果使用的是定制排序,则通过调用比较器的compare方法
如何排序?
方式一:自然排序
让待添加的元素类型实现Comparable接口,并重写compareTo方法
方式二:定制排序
创建Set对象时,指定Comparator比较器接口,并实现compare方法
自然顺序
如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。对于 TreeSet 集合而言,它判断两个对象是否相等的唯一标准是:两个对象通过 compareTo(Object obj) 方法比较返回值为0。
代码示例一:按照字符串Unicode编码值排序
@Test
public void test1(){
TreeSet<String> set = new TreeSet<>();
set.add("zhangsan"); //String它实现了java.lang.Comparable接口
set.add("lisi");
set.add("wangwu");
set.add("zhangsan");
System.out.println("元素个数:" + set.size());
for (String str : set) {
System.out.println(str);
}
}
定制排序
如果放到TreeSet中的元素的自然排序(Comparable)规则不符合当前排序需求时,或者元素的类型没有实现Comparable接口。那么在创建TreeSet时,可以单独指定一个Comparator的对象。使用定制排序判断两个元素相等的标准是:通过Comparator比较两个元素返回了0。
代码示例:学生类型未实现Comparable接口,单独指定Comparator比较器,按照学生的学号排序
public class Student{
private int id;
private String name;
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
//......这里省略了name属性的get/set
@Override
public String toString() {
return "Student [id=" + id + ", name=" + name + "]";
}
}
@Test
public void test3(){
TreeSet<Student> set = new TreeSet(new Comparator<Student>(){
@Override
public int compare(Student o1, Student o2) {
return o1.getId() - o2.getId();
}
});
set.add(new Student(3,"张三"));
set.add(new Student(1,"李四"));
set.add(new Student(2,"王五"));
set.add(new Student(3,"张三风"));
System.out.println("元素个数:" + set.size());
for (Student stu : set) {
System.out.println(stu);
}
}
13.6.4 如何选用HashSet、LinkedHashSet、TreeSet
HashSet:如果不需要保证添加顺序,只是不可重复,就用HashSet。
因为如果你每次添加删除时,还要维护前后元素的关系,就效率低了。
要依赖于元素hashCode()和equals()
底层的存储是哈希表。
TreeSet:只有当你要求元素按照大小顺序,并且不可重复,那么才使用它。
要依赖于元素的compareTo()或定制比较器的compare()
底层的存储是红黑树(自平衡的二叉树)
LinkedHashSet:当你如果遇到,既要保证元素的添加顺序,又要保证元素不可重复
要依赖于元素hashCode()和equals()
它是HashSet的子类。
比HashSet中的结点类型,多维护了一个前后结点的引用。
Set系列:本质上内部是Map
- HashSet内部是HashMap
- TreeSet内部是TreeMap
- LinkedHashSet内部是LinkedHashMap
13.6.5 补充:Set不可重复的讲解
/*
*Set:也是Collection子接口。
* Set这个接口没有扩展Collection的方法。
* 但是它的实现类们对Collection的方法的实现更加严格。
* Set系列的集合:元素不能重复的。
*
* Collection支持foreach,Iterator迭代器,那么Set也一样。
* Set的实现类们:HashSet,TreeSet,LinkedHashSet
*
* 是否Set有序,有争议:
* 说无序,从存储的结构,物理结构来说的,
* 说TreeSet和LinkedHashSet有序,从遍历的结果来说
*/
不可重复:
-
HashSet:添加到HashSet中的元素,不可重复,依赖于hashCode和equals方法
-
LinkedHashSet:添加到LinkedHashSet中的元素,不可重复,依赖于hashCode和equals方法
-
TreeSet:
-
(1)添加到TreeSet中的元素必须实现Comparable接口,元素是不可重复调用compareTo()比较的,
它认为大小相等的就是重复元素。
-
(2)如果添加到TreeSet的元素没有实现Comparable接口,或者实现的Comparable接口的方式不满足我当前的排序需求,那么可以给TreeSet指定一个Comparator定制比较器对象
-
13.6.6 小总结
1、Set系列的集合的特点:不可重复的
是否有序:
如果从元素的存储位置来看,是无序的;
如果从遍历的结果来看,其中TreeSet是按照大小顺序,LinkedHashSet是按照添加的顺序。2、Set的实现类们:
HashSet:依赖于元素的hashCode和equals方法TreeSet:
依赖于元素的compareTo()或定制比较器对象的compare()LinkedHashSet:
依赖于元素的hashCode和equals方法3、底层实现
HashSet:内部维护的是HashMap,添加到HashSet中的元素是作为HashMap的key,value使用一个Object类型的PRESENT常量对象。TreeSet:
内部维护的是TreeMap,添加到TreeSet中的元素是作为TreeMap的key,value使用一个Object类型的PRESENT常量对象。LinkedHashSet:
内部维护的是LinkedHashMap,添加到LinkedHashSet中的元素是作为LinkedHashSet的key,value使用一个Object类型的PRESENT常量对象。