A NEW METHOD OF REGION EMBEDDING FOR TEXT CLASSIFICATION
A NEW METHOD OF REGION EMBEDDING FOR TEXT CLASSIFICATION

1、ABSTRACT
To represent a text as a bag of properly identified “phrases” and use the representation for processing the text is proved to be useful.The key question here is how to identify the phrases and represent them.
传统方法:n-grams can be regarded as an approximation of the approach
缺陷:Such a method can suffer from data sparsity, however, particularly when the length of n-gram is large.
因此: we propose “region embeddings”,In our models, the representation of a word has two parts, the embedding of the word itself, and a weighting matrix to interact with the local context, referred to as local context unit.
应用于文本分类任务中,在各类数据集上outperforms existing methods,结果还表明该方法确实能捕捉到文本中突出的短语表达。
2、INTRODUCTION
A simple yet effective approach for text classification is to represent documents as bag-of-words, and train a classifier on the basis of the representations.
但基于词袋模型的文本表示没有考虑到词序信息。为了改进,人们提出了N-gram模型,但还是存缺点:当序列较长时,n-gram表示产生的参数规模庞大,且容易受数据稀疏的影响。FastText提出,可以 learn and use distributed embeddings of n-grams。
一个词的语义是由其自身含义以及周围词的含义共同确定的,the representation of a word has two parts, the embedding of the word itself, and a weighting matrix to interact with the local context, referred to as local context unit.The embedding of a word is a column vector, and the local context unit of a word is a matrix in which the columns are used to interact with words in the local context.
3、METHOD
In this paper, we focus on learning the representations of small text regions which preserve the local internal structural information for text classification.
regions:fixed length contiguous subsequences of the document.
specifically:wi代表文档中第i个词,region(i, c):2 * c + 1 length region with middle word ![]()
instance:The food is not very good in this hotel, region(3, 2) means the subsequence food is not very good.
在这篇文章中,作者使用 词和相应的 local context unit之间的相互作用来生成region embeddings。
3.1、LOCAL CONTEXT UNIT
词 ![]() 的词向量
的词向量 ![]() 是使用look up table 从词向量矩阵
是使用look up table 从词向量矩阵 ![]() 中取出相应的列得到,
中取出相应的列得到, ![]() 是词典的size,
是词典的size, ![]() 是词向量的维度。
是词向量的维度。
为了利用词语 “相对位置” 信息 和 “局部上下文”信息,除了词向量之外,我们还为每个单词学习了一个局部语境单元local context unit,词向量和局部语境单元都是模型要学习的参数,随机初始化赋予初始值。
词 ![]() 的局部语境单元
的局部语境单元 ![]() 是一个矩阵,可以根据
是一个矩阵,可以根据 ![]() 在字典中的index从张量
在字典中的index从张量 ![]() 中look up出来。
中look up出来。

![]() 中的每一列可以被用于与对应位置的词向量
中的每一列可以被用于与对应位置的词向量 ![]() 的相互作用,事实上,每一个局部语境单元
的相互作用,事实上,每一个局部语境单元 ![]() 中的列可以被视作一个对相应位置词语的distinctive linear projection functions。The parameters of these projection functions(i.e.,columns of each unit matrix) can be learned to capture the semantic and syntactic influence of the word to its context.
中的列可以被视作一个对相应位置词语的distinctive linear projection functions。The parameters of these projection functions(i.e.,columns of each unit matrix) can be learned to capture the semantic and syntactic influence of the word to its context.
![]() 是
是 ![]() 在第 i 个词向量的视野范围内经过映射后输出的向量;
在第 i 个词向量的视野范围内经过映射后输出的向量;
![]() 是
是 ![]() 的第(c + t)列(-c <= t <= c)
的第(c + t)列(-c <= t <= c)
给定 ![]() 的局部语境单元
的局部语境单元 ![]() ,和第
,和第 ![]() 个词的词向量
个词的词向量 ![]() ,使用对应元素相乘
,使用对应元素相乘 ![]() 来计算
来计算 ![]() 。
。
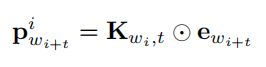
对于每一个在wi的不同相对位置上的词语,总有一个相应的 linear projection functions(也就是 ![]() 中的一列),因此,我们提出的局部语境单元可以一种新颖的方式利用局部词序信息。
中的一列),因此,我们提出的局部语境单元可以一种新颖的方式利用局部词序信息。 ![]() 的中间一列
的中间一列 ![]() 可以被视作对于单词
可以被视作对于单词 ![]() 自身的线性映射函数,作用是将
自身的线性映射函数,作用是将 ![]() 映射到与其他映射后的词向量的相同空间。
映射到与其他映射后的词向量的相同空间。
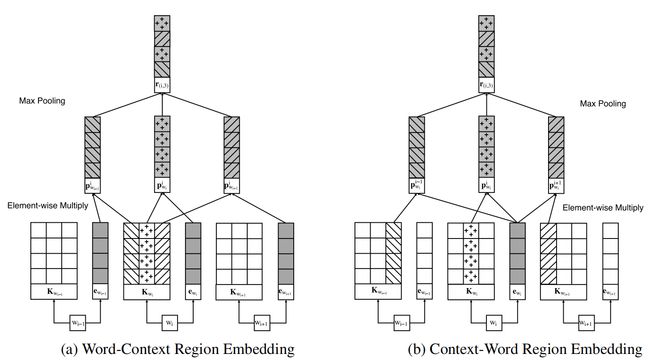
3.2 、WORD-CONTEXT REGION EMBEDDING
作者从不同的角度提出了两种实现区域嵌入的体系结构。
在第一种体系重点研究了中间词的上下文语境对于周围词的影响。For example, in the sentence The food is not very good in this hotel, the occurrence of word not might bring a semantic reversal to the local region。第二种方式研究周围词词的上下文语境对于中间词的影响。
同样,首先,

然后,最大池化:region(i, c)的计算
中间语境对周围词:
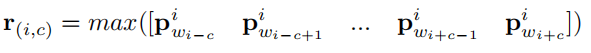
周围语境对中间词:
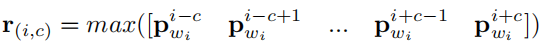
4、实验及结果分析

EFFECT OF REGION SIZE
Our method uses a fixed size of region as contextual information just like CNN. So the selection of region size really matters.A small region may lose some long distance patterns, whereas large regions will bring into more noises.
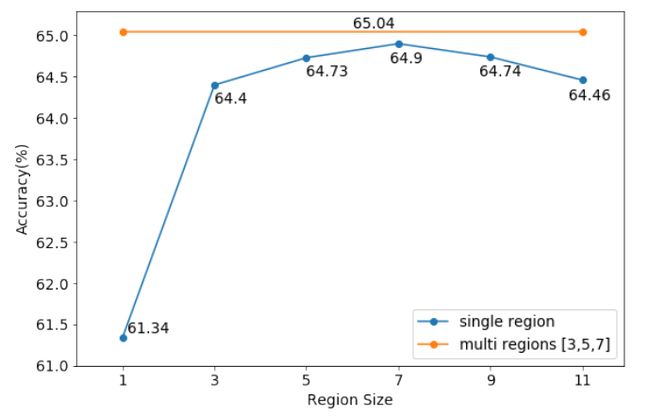
In figure 2a, the combination of multi region sizes 3,5,7 is slightly better than the best single region size 7. The effectiveness of multi-size combination can be explained by the difference of influence ranges between words. For example, in sentiment analysis, word very only emphasizes the next word while however may lay stress on a wide range of the following words.
VISUALIZATION

颜色深浅代表受中间词的影响程度,however、but的右侧词要比左侧词颜色深,因为however、but后接的一般是语义反转类信息。very后的第一个位置的词要比其他位置更重要,因为very happy,very bad这类。对于good,bad,可能整体语义会受not good, not bad, not that good这类的影响。food和morning的分布不同,因为delicious food ,food was very delicious,但是morning较少有类似表达。
we would like to believe this feature helps capture syntactic and semantic influences of words on surrounding words at relative positions.

绿色代表正面情绪,红色负面情绪,颜色深浅表示情绪的强弱。With C-unit and No C-unit代表使用和未使用区域语境单元。对于句子get your wallet ready, the prices are crazy high,未使用C-unit,crazy的绿色程度要高于high的红色程度,因此短语prices are crazy high整体为正面情绪。而使用了C-unit,crazy的语义淡化,high的语义提升,因此短语整体语义为负面,正确。
再次印证了作者这种方法的有效性。