K近邻算法(三)--kaggle竞赛之Titanic
小白好难得会用python做第分类,实践一下用于kaggle入门赛之泰坦尼克生还预测
问题介绍:泰坦尼克电影大家都看过,大灾难过后有些人生还了,有些人却遭遇了不信,官方提供了1309名乘客的具体信息以及提供了其中891名乘客的最后的存活情况,让我们去预测另外418乘客的存活情况。是很基本的二分类问题。
一、数据分析
官方所给的数据长这样:
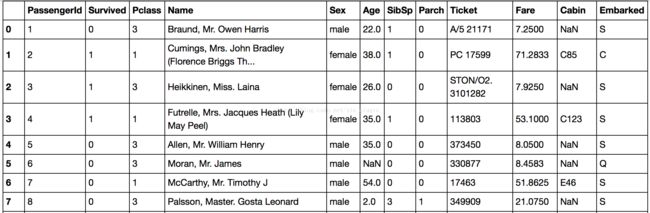
Survived:是否存活(0代表否,1代表是)
Pclass:社会阶级(1代表上层阶级,2代表中层阶级,3代表底层阶级)
Name:船上乘客的名字
Sex:船上乘客的性别
Age: 船上乘客的年龄(可能存在 NaN)
SibSp:乘客在船上的兄弟姐妹和配偶的数量
Parch:乘客在船上的父母以及小孩的数量
Ticket:乘客船票的编号
Fare:乘客为船票支付的费用
Cabin:乘客所在船舱的编号(可能存在 NaN)
Embarked:乘客上船的港口( S 代表从 Southampton 登船, C 代表从 Cherbourg 登船,Q 代表从 Queenstown 登船,)
我们面临的主要问题有两个,一个是age和cabin存在很多缺失值(Age(年龄)属性只有714名乘客有记录,Cabin(客舱)只有204名乘客是已知的),很可能会影响模型性能;另一个是训练样本就891个,训练集过小,很容易造成过拟合。
二、数据处理
由于影响因素太多,我们先对特征向量进行筛选。根据信息增益比进行排序画图(详细知识点见《机器学习》周志华)
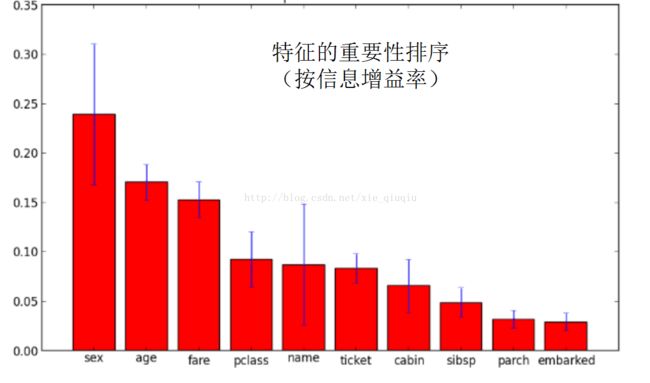
故我们就保留前三个影响因子。推测性别女士优先,年龄小孩优先,票价可能影响到其所在船舱而影响其存活率。
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0#确保指针在最前面
for line in fr.readlines():
line = line.strip()
listFromLine = line.split(',')
if listFromLine[5]=='male':
listFromLine[5]='0'
else:
listFromLine[5]='1'
if listFromLine[6]=='':
listFromLine[6]=29.7
if listFromLine[7]=='':
listFromLine[7]=35.6
#年龄的缺省用平均年龄29.7代替
returnMat[index,:] = listFromLine[5:8] #对应着性别,年龄和船票价
classLabelVector.append(int(listFromLine[1]))
index += 1
return returnMat,classLabelVector#return的位置一定要找对
二、分析数据
import matplotlib
import matplotlib.pyplot as plt
from os import listdir
import numpy as np
dataset,classlabel=file2matrix('train1.csv')
classlabel=array(classlabel)
id0=np.where(classlabel==0)
id1=np.where(classlabel==1)
fig=plt.figure()
ax=fig.add_subplot(111)
p1=ax.scatter(dataset[id1,1],dataset[id1,2],color = 'r',label='1',s=20)
p0=ax.scatter(dataset[id0,1],dataset[id0,2],color ='b',label='0',s=10)
plt.legend(loc = 'upper right')
plt.show 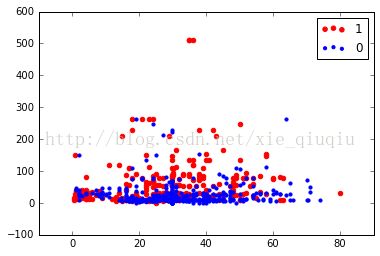
这是以年龄和船票价分的
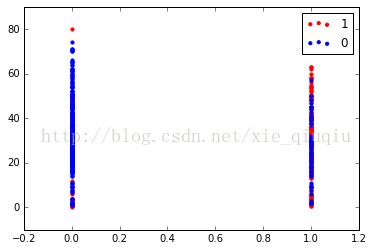
这是以年龄和性别分的
这是以性别和船票价分的
其实这里应该继续探讨特征间的相互联系,做集成算法。不过初步先直接选定年龄和船票价为分类标准吧(谁叫小白还不会处理定性特征值呢)
三、准备数据
归一化数值
def autoNorm(dataSet):
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))#建立框架
m = dataSet.shape[0]#行数
normDataSet = dataSet - tile(minVals, (m,1))#每个数减该列最小
normDataSet = normDataSet/tile(ranges, (m,1)) #差再除以max-min
return normDataSet, ranges, minVals 四、测试算法
导入核心算法
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]#4l
diffMat = tile(inX, (dataSetSize,1)) - dataSet#inx按4*1重复排列再与sataset做差
sqDiffMat = diffMat**2#每个元素平方
sqDistances = sqDiffMat.sum(axis=1)#一个框里的都加起来
distances = sqDistances**0.5#加起来之后每个开根号
sortedDistIndicies = distances.argsort() #返回的是数组值从小到大的索引值,最小为0
classCount={}
for i in range(k):#即0到k-1.最后得到的classCount是距离最近的k个点的类分布,即什么类出现几次如{'A': 1, 'B': 2}
voteIlabel = labels[sortedDistIndicies[i]]#返回从近到远第i个点所对应的类
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1#字典模式,记录类对应出现次数.这里.get(a,b)就是寻找字典classcount的a对应的值,如果没找到a,就显示b
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]测试算法
def surviorclasstest():
hoRatio = 0.10 #hold out 10%
dataset,classlabel=file2matrix('train1.csv') #load data setfrom file
normMat, ranges, minVals = autoNorm(dataset)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],classlabel[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classlabel[i])
if (classifierResult != classlabel[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount得到
the total error rate is: 0.269如果选择较小的k值,就相当于用较小的领域中的训练实例学习,其近似误差会小,但估计误差会大,其泛化性能会比较差,因为预测结果会对近邻的实例点非常敏感,即k值越小就意味着整体模型越复杂,容易发生过拟合;相对地,用较大的k值,可以减小学习的估计误差,但是近似误差会增大,这时与输入实例较远的不相似的训练实例也会起预测作用,使预测发生错误,夸张一点k=N时无论输入什么实例都返回整个训练集占多数的类,k值越大意味着整体模型变得简单,有可能欠拟合。在应用中,通常采用交叉验证法来选取较优的k值。
(from《机器学习》周志华)
这里我比较懒加上之前提过这里样本少很容易过拟合,再加上能上75%的准确率我已经很满意啦。这里就选择k=10吧。
五、使用算法
def classifyperson():
dataset,classlabel=file2matrix('train1.csv')
normMat, ranges, minVals = autoNorm(dataset)
testset,whatever=file2matrix('test.csv')
normMattest, rangestset, minValstest = autoNorm(testset)
h=testset.shape[0]
for i in range(h):
classifierResult = classify0(normMattest[i,:],normMat[:,:],classlabel[:],10)
print classifierResult得到一串01的序列就可以提交啦。
六、优化方向

感觉靠谱的还有逻辑回归,决策树和支持向量机(SVM)另外可以尝试集成学习
另外可以Bagging :有放回的自助采样,生成多棵决策树训练以及在此基础上再引入随机属性,进一步增加“多样性”(随机森林)(据说这一串下来可以到81%)