【文献阅读】MUREL——视觉问答VQA中的多模态关系推理(R. Cadene等人,CVPR,2019)
一、文献概况
文章题目:《MUREL: Multimodal Relational Reasoning for Visual Question Answering》
CVPR2019年的文章。CVPR2019中关于VQA的文章不多,看到这一篇故记录下来。
文章下载地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/Cadene_MUREL_Multimodal_Relational_Reasoning_for_Visual_Question_Answering_CVPR_2019_paper.pdf
文章引用格式:R. Cadene, H. Ben-younes, M. Cord, N. Thome. "MUREL: Multimodal Relational Reasoning for Visual Question Answering." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
项目地址:github.com/Cadene/murel.bootstrap.pytorch
二、文章导读
网上关于这篇文章也没怎么看到解读,所以就自己记录下吧。
下来看看文章的摘要部分:
Multimodal attentional networks are currently state-ofthe-art models for Visual Question Answering (VQA) tasks involving real images. Although attention allows to focus on the visual content relevant to the question, this simple mechanism is arguably insufficient to model complex reasoning features required for VQA or other high-level tasks.
In this paper, we propose MuRel, a multimodal relational network which is learned end-to-end to reason over real images. Our first contribution is the introduction of the MuRel cell, an atomic reasoning primitive representing interactions between question and image regions by a rich vectorial representation, and modeling region relations with pairwise combinations. Secondly, we incorporate the cell into a full MuRel network, which progressively refines visual and question interactions, and can be leveraged to define visualization schemes finer than mere attention maps.
We validate the relevance of our approach with various ablation studies, and show its superiority to attention based methods on three datasets: VQA 2.0, VQA-CP v2 and TDIUC. Our final MuRel network is competitive to or outperforms state-of-the-art results in this challenging context.
虽然目前注意力网络在VQA中表现出了非常好的效果,但是注意力这种简单的机制是不足以对复杂的推理特征或者高层次的任务进行建模。因此,本文提出了MuRel,一种能够在真实图像中学习端到端推理的多模态关系网络。主要贡献有两个,一个是引入了MuRel 单元——一种通过用丰富向量表示来处理问题和图像之间的推理交互,和成对结合的区域关系的建模的结构;二是将前面的单元整合到MuRel网络中去,该网络细化了图像和文本的交互。
三、文章详细介绍
VQA发展到现在,目前需要的是对高层次信息(问题或图像中)的理解,尽管目前采用了注意力机制的模型能够获得相对较好的结果,但是却限制了与问题有关答案的视觉推理。因此本文提出了MuRel——一种多模态关系网络,该网络能够对问题和图像做进一步推理。这篇文章的主要贡献在于:
Our first contribution is to introduce the MuRel cell, an atomic reasoning primitive enabling to represent rich interactions between question and image regions. It is based on a vectorial representation that explicitly models relations between regions. (引入了MuRel单元)
Our second contribution is to embed this MuRel cell into an iterative reasoning process, which progressively refines the internal network representation to answer the question. (将该单元嵌入到迭代推理过程)

最后作者还将简化模型用于三个数据集:the VQA 2.0 dataset, VQA-CP v2, TDIUC。
1. 相关的一些背景介绍
深度学习在不断的发展,目前向着深层推理问题(complex visual reasoning problems)的解决而发展,这些问题主要包括:关系检测(relationship detection),目标识别(object recognition),多模态检索(multimodal retrieval),抽象推理(abstract reasoning),视觉因果(visual causality),视觉对话(visual dialog)。
视觉推理(Visual reasoning):做VQA的视觉推理常用数据集CLEVR,该数据集针对现实世界图像设置了一些需要推理的简单问题。目前较好的模型包括FiLM,MAC network。
真实数据的VQA(VQA on real data):VQA的一个关键就是对两种特征向量的高层次相关性的表示,在目前的多模态融合方法里面,比较有效的是用二阶交互(second order interaction),或者张量分解(tensor decomposition framework)。在VQA的关系推理中,目前多用的是软注意力(soft attention)机制,根据问题,模型会对每个区域进行重要性打分,然后再用权重求和的池化方式来进行可视化表示,多重注意力可以通过并行或者顺序计算,这里面的代表算法是Structured Attention。
MuRel的贡献(MuRel contributions):本文的模型移除了传统的注意力结构(attention framework),而采用了向量化的表示(vectorial representation),对每个区域的视觉内容和问题之间的语义交互进行建模。此外,作者还在表示(representation)中加入了空间和语义上下文的概念,即通过视觉嵌入和空间坐标之间的交互来表示成对的图像区域。
2. 模型方法
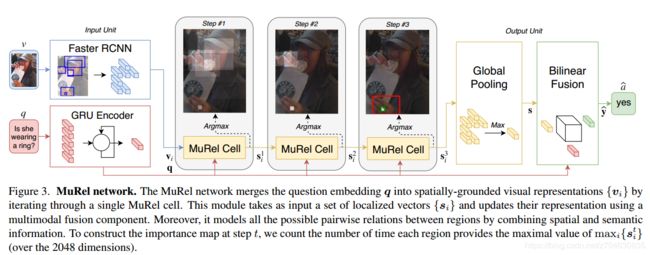
该模型可以如下图表示:
假定我们输入图像v和问题q,待遇测答案a^和真值a*,传统方法是将该问题视为一个分类问题,即:
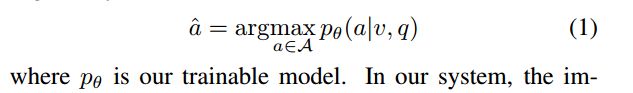
而作者提出的方法中,图像是用向量集合{vi}来表示,向量集合中的每一个元素都是图像中的一个目标,然后再引入空间坐标bi = [x, y, w, h],这里面[x, y]表示box的左上角坐标,[w, h]表示box的宽和高。对于问题来说,使用gated recurrent unit来获得句子嵌入q(sentence embedding)。
(1)MuRel cell
MuRel cell输入N个可视特征,这些特征都带有他们的坐标。它由两个模块组成:

首先是双线性融合模块,将问题q和区域特征向量s进行合并,形成局部多模态嵌入;之后紧接着pairwise modeling component进行多模态的表示。
Multimodal fusion(多模态融合):我们想把问题信息包含在可视表达s中(visual representation),就要使用到多模态,目前最有效的技术是基于三阶张量的Tucker分解,这是一种双线性融合方法。而在传统的注意力模型中,则是采用encoder的方式将图像特征和问题特征融合起来。在MuRel cell中, 局部多模态信息用向量结构表达,该结构能够编码不妥模态之间更多复杂的相关性。
Pairwise interactions(成对交互):为了获得多个目标之间的相关关系,这里采用了成对交互模型(pairwise relationship),作者灵感来自于别的文献,别的文献的做法是一个区域的K个相似区域,也就是MuRel cell邻域是由图像中的每个区域构成;另外,文献中用了标量注意力和高斯核的卷积操作,这里作者则使用空间和语义表示来建立关系向量
(2)MuRel network
MuRel网络通过利用双线性融合的能力,将视觉信息迭代地合并到上下文感知的视觉嵌入中,从而模仿了一种简单的迭代推理形式。MuRel网络表示与问题相关的区域,也使用它自己的视觉上下文信息,这种表示(resentation)是通过MuRel cell的多次迭代完成的,每个cell的权值共享,另外该模块的残差特性使它不受梯度消失的影响, 这些特性都使得该网络具有较好的泛化性和紧凑的参数化。
Visualizing MuRel network(可视化MuRel网络):模型可视化过程中,可以突出图像区域和答案之间的重要关系,MuRel网络每一次迭代的最后,可以通过最大化操作得到visual feature:

当然,也可以用MuRel cell对预测结果中的成对关系进行可视化。
Connection to previous work(与之前工作的衔接):作者主要与先前工作FiLM network网络进行了比较。简单来看下比较的内容,FiLM网络是将图像传入了一个多层残差单元,而MuRel网络是将图像传入了一个迭代的单元;多模态的交互中,FiLM用的是feature-wise affine(仿射变换)模块,而MuRel网络则使用了bilinear fusion strategy(双线性融合);二者相同的地方在于都使用了图像的空间结构来对区域之间的关系进行推理建模。
3. 实验及结果
作者首先是探究自己模型中的一些结构设计是否合理。作者先将模型用在了不同的数据集上,相较于attention model,性能大概能提升2个点左右:

用简化模型分别探究pairwise module和迭代的影响:

对于不同类型的问题探究迭代次数的影响:

接下来是对不同数据集的实验与不同模型之间的比较,数据集包括:VQA 2.0,TDIUC,VQA-CP v2。实验结果就不全贴了,最后就是质量评估,贴一张作者的图:
