2020年最新微博相关数据API+一站式获取个人微博信息+套娃、批量式获取微博用户信息
本此爬虫采取scrapy框架进行编写。
一站式获取个人微博信息
- 1. 梳理爬虫目的和思路
- 1.1 爬虫的目的
- 1.2 爬虫的思路
- 2. 分析网页源码
- 2.1 分析博主信息网页
- 2.2 分析关注列表界面
- 2.3 粉丝列表页面分析
- 2.4 微博博文页面分析
- 3. 得出2020年最新微博相关数据API
- 4. 编写代码
- 4.1 创建Scrapy爬虫项目
- 4.2 创建Spider
- 4.3 根据网页源码下user下的信息,创建自己想提取的信息所对应的Item
- 4.4 进行数据的提取
- 4.4.1 创建程序的起始请求
- 4.4.2 提取博主个人信息
- 4.4.3 提取博主关注列表及其用户信息
- 4.4.4 提取博主粉丝列表及其用户信息
- 4.4.5 提取博主微博内容
- 5. 建立相应的数据库
- 5.1 数据库如图所示:
- 6. 连接数据库并将数据存入数据库
- 6.1 启动pipline
- 7. 套娃、批量式获取微博用户信息
- 8. 代码存在的问题
- 9. 爬取的结果
- 9.1 后台结果
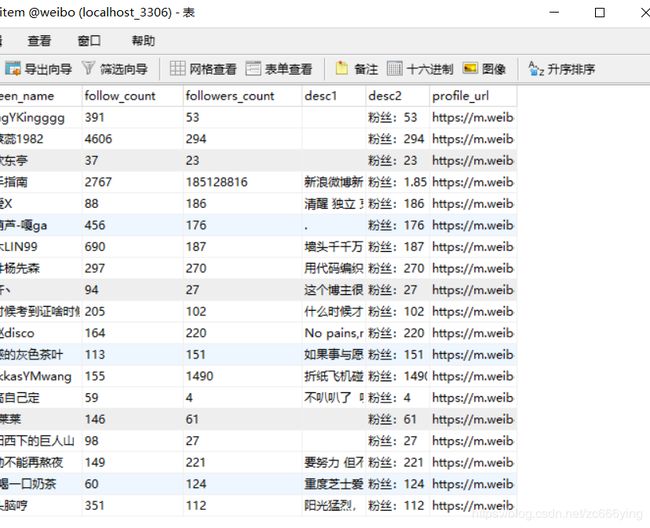
- 9.2 数据库结果
1. 梳理爬虫目的和思路
1.1 爬虫的目的
- 爬取博主的个人信息,包括名字,微博认证内容,粉丝数,关注数等
- 爬取博主的关注列表,包括列表里的每个人的个人信息
- 爬取博主的粉丝列表,包括列表里的那个人的个人信息
- 爬取博主的微博内容,包括发微博的时间,来源,图片的链接,内容等
1.2 爬虫的思路
- 分析网页源码,寻找其分装json数据响应的Request URL的规律,得到其微博相关数据API
- 请求API,捕获返回的json数据
- 分析这些json数据,提取自己有用的数据
- 将数据保存入数据库
2. 分析网页源码
爬取的微博网址是手机端微博的登陆网址
2.1 分析博主信息网页
该网页是手机端微博登陆自己的微博后,打开自己的主页,f12打开面板,直接查看XHR下的请求,因为之前爬取过微博的爬虫,采用的不是框架爬虫,
Python帮你了解你喜欢的人!爬取她的微博内容信息!(Ajax数据爬取)
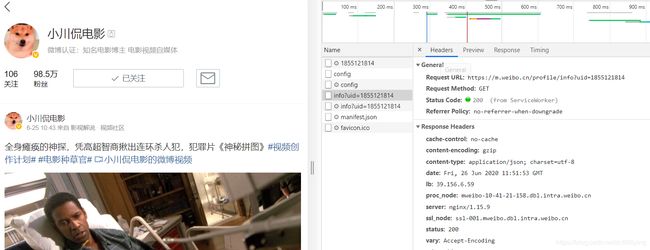
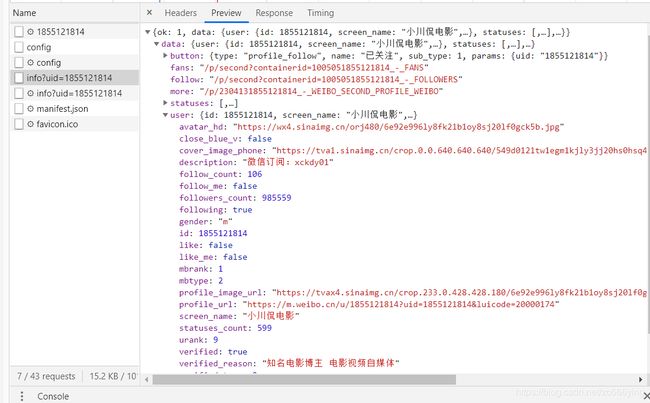
发现微博的数据是通过Ajax的方式加载的,故直接查看XHR下的响应,因为是指爬取博主的个人信息,所以不用下拉页面,直接f5刷新以下在出现的响应中进行爬取。很简单就可以找见如图所示的响应,发现个人信息就在data->user下,整体的数据返回格式是json,其RequestURL可以发现其就是最后的uid在发生变化
2.2 分析关注列表界面
点击其关注就可以进入其关注列表页面:
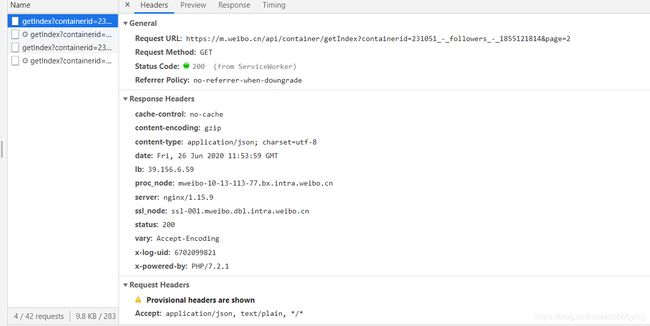
下拉页面,就会看见出现的请求响应,很明显这就是其加载关注列表的响应,分析其RequestURL链接,发现其请求变化的规律也是在于uid的变化和page的变化,其关注列表的信息在data->card_group中,列表中的每个人的信息在user中,其返回的数据格式也是json

2.3 粉丝列表页面分析
点击其粉丝便可进入其粉丝页面:
下拉粉丝也面,在XHR下也会看见加载的响应,便是存储粉丝列表的响应,其RequestURL链接的变化之初也是uid和since_id在变,一个标识用户,一个改变页数。其数据在data->cards下保存,每个粉丝的用户信息在usr中保存,数据的返回格式也是JSON。


2.4 微博博文页面分析
在其主页面,点击最下方的查看全部微博,便可以进入其微博博文页面:
下拉页面,在XHR下便可以看见加载的请求响应,其RequestURL的变化也是在于uid和page的变化,微博数据在data->cards->mblog中保存,整体的数据返回格式是JSON。
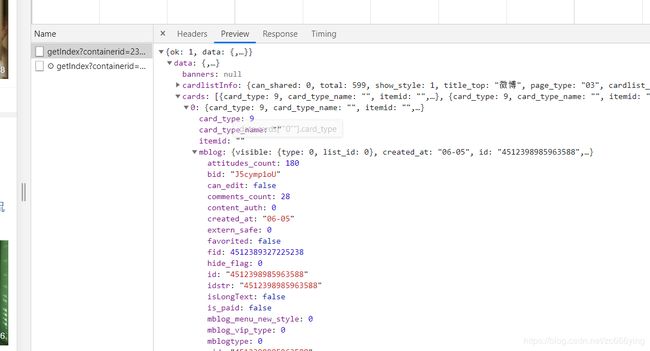

3. 得出2020年最新微博相关数据API
综上所述,得出相关的微博相关数据的API:
# 用户详情API
user_url = 'https://m.weibo.cn/profile/info?uid={uid}'
# 关注列表API
follow_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_{uid}&page={page}'
# 粉丝列表API
fan_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_{uid}&since_id={page}'
# 微博内容API
weibo_url = 'https://m.weibo.cn/api/container/getIndex?containerid=230413{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page={page}'
4. 编写代码
4.1 创建Scrapy爬虫项目
scrapy startproject weiboinfo
4.2 创建Spider
在Pycharm下端的Terminal中执行即可:
scrapy genspider weibo m.weibo.cn
4.3 根据网页源码下user下的信息,创建自己想提取的信息所对应的Item
在items.py下定义:
class UserItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
id = Field()
# 博主名字
screen_name = Field()
# 个人简介
description = Field()
# 关注数
follow_count = Field()
# 粉丝数
followers_count = Field()
# 是否关注自己
follow_me = Field()
# 自己是否关注他
following = Field()
# 微博认证
verified_reason = Field()
# 微博链接
profile_url = Field()
# 全部微博数
statuses_count = Field()
class UserAttentionItem(Item):
id = Field()
# 博主名字
screen_name = Field()
# 关注数
follow_count = Field()
# 粉丝数
followers_count = Field()
# 是否关注自己
follow_me = Field()
# 自己是否关注他
following = Field()
# 微博链接
profile_url = Field()
class UserFansItem(Item):
id = Field()
# 博主名字
screen_name = Field()
# 关注数
follow_count = Field()
# 粉丝数
followers_count = Field()
# 微博链接
profile_url = Field()
# 微博简介
desc1 = Field()
desc2 = Field()
class WeiboItem(Item):
id = Field()
# 点赞数
attitudes_count = Field()
# 评论数
comments_count = Field()
# pictuer 链接
picture_url = Field()
# 内容
raw_text = Field()
# 来源
source = Field()
# 发布时间
created_at = Field()
4.4 进行数据的提取
4.4.1 创建程序的起始请求
class WeiboSpider(scrapy.Spider):
name = 'weibo'
allowed_domains = ['m.weibo.cn']
#start_urls = ['http://m.weibo.cn/']
# 这里写的是你想要爬取博主信息的uid
start_users = ['uid']
# 用户详情API
user_url = 'https://m.weibo.cn/profile/info?uid={uid}'
# 关注列表API
follow_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_followers_-_{uid}&page={page}'
# 粉丝列表API
fan_url = 'https://m.weibo.cn/api/container/getIndex?containerid=231051_-_fans_-_{uid}&since_id={page}'
# 微博内容API
weibo_url = 'https://m.weibo.cn/api/container/getIndex?containerid=230413{uid}_-_WEIBO_SECOND_PROFILE_WEIBO&page_type=03&page={page}'
def start_requests(self):
for uid in self.start_users:
yield Request(self.user_url.format(uid=uid),callback=self.parse_user)
4.4.2 提取博主个人信息
'''
爬取博主个人信息
'''
def parse_user(self, response):
result = json.loads(response.text)
if result.get('data').get('user'):
user_info = result.get('data').get('user')
user_item = UserItem()
user_item['id'] = user_info.get('id')
user_item['screen_name'] = user_info.get('screen_name')
user_item['description'] = user_info.get('description')
user_item['follow_count'] = user_info.get('follow_count')
user_item['followers_count'] = user_info.get('followers_count')
user_item['follow_me'] = user_info.get('follow_me')
user_item['following'] = user_info.get('following')
user_item['verified_reason'] = user_info.get('verified_reason')
user_item['profile_url'] = user_info.get('profile_url')
user_item['statuses_count'] = user_info.get('statuses_count')
yield user_item
#获取博主的id,进行构造下一项的请求
id = user_info.get('id')
# 关注
yield Request(self.follow_url.format(uid=id,page=1),callback=self.parse_follows,meta={'page':1,'uid':id})
# 粉丝
yield Request(self.fan_url.format(uid=id,page=1),callback=self.parse_fans,meta={'page':1,'uid':id})
# 微博
yield Request(self.weibo_url.format(uid=id,page=1),callback=self.parse_weibos,meta={'page':1,'uid':id})
4.4.3 提取博主关注列表及其用户信息
'''
爬取博主关注列表信息
'''
def parse_follows(self,response):
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('cards') and len(result.get('data').get('cards')) and result.get('data').get('cards')[-1].get('card_group'):
follows = result.get('data').get('cards')[-1].get('card_group')
for follow in follows:
if follow.get('user'):
uid = follow.get('user').get('id')
#yield Request(self.user_url.format(uid=uid),callback=self.parse_user)
user_AttentionItem = UserAttentionItem()
user_AttentionItem['id'] = follow.get('user').get('id')
user_AttentionItem['screen_name'] = follow.get('user').get('screen_name')
user_AttentionItem['follow_count'] = follow.get('user').get('follow_count')
user_AttentionItem['followers_count'] = follow.get('user').get('followers_count')
user_AttentionItem['follow_me'] = follow.get('user').get('follow_me')
user_AttentionItem['following'] = follow.get('user').get('following')
user_AttentionItem['profile_url'] = follow.get('user').get('profile_url')
yield user_AttentionItem
# 关注列表翻页
uid = response.meta.get('uid')
page = response.meta.get('page') + 1
yield Request(self.follow_url.format(uid=uid,page=page),callback=self.parse_follows,meta={'page':page,'uid':uid})
4.4.4 提取博主粉丝列表及其用户信息
'''
爬取博主粉丝列表信息
'''
def parse_fans(self,response):
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('cards') and len(result.get('data').get('cards')) and result.get('data').get('cards')[-1].get('card_group'):
fans = result.get('data').get('cards')[-1].get('card_group')
for fan in fans:
if fan.get('user'):
uid = fan.get('user').get('id')
#yield Request(self.user_url.format(uid=uid),callback=self.parse_user)
# 分析列表
user_FansItem = UserFansItem()
user_FansItem['id'] = fan.get('user').get('id')
user_FansItem['screen_name'] = fan.get('user').get('screen_name')
user_FansItem['follow_count'] = fan.get('user').get('follow_count')
user_FansItem['followers_count'] = fan.get('user').get('followers_count')
user_FansItem['desc1'] = fan.get('desc1')
user_FansItem['desc2'] = fan.get('desc2')
user_FansItem['profile_url'] = fan.get('user').get('profile_url')
yield user_FansItem
# 分析列表 翻页
uid = response.meta.get('uid')
page = response.meta.get('page') + 1
yield Request(self.fan_url.format(uid=uid,page=page),callback=self.parse_fans,meta={'page':page,'uid':uid})
4.4.5 提取博主微博内容
'''
爬取微博内容
'''
def parse_weibos(self,response):
result = json.loads(response.text)
if result.get('ok') and result.get('data').get('cards'):
weibos = result.get('data').get('cards')
for weibo in weibos[1::]:
mblog = weibo.get('mblog')
if mblog:
weibo_item = WeiboItem()
weibo_item['id'] = mblog.get('id')
weibo_item['attitudes_count'] = mblog.get('attitudes_count')
weibo_item['comments_count'] = mblog.get('comments_count')
weibo_item['picture_url'] = mblog.get('bmiddle_pic')
weibo_item['raw_text'] = mblog.get('raw_text')
weibo_item['source'] = mblog.get('source')
weibo_item['created_at'] = mblog.get('created_at')
yield weibo_item
# 微博内容翻页
uid = response.meta.get('uid')
page = response.meta.get('page') + 1
yield Request(self.weibo_url.format(uid=uid,page=page),callback=self.parse_weibos,meta={'page':page,'uid':uid})
5. 建立相应的数据库
数据库中表的信息所建立的字段跟item中创建的Field一一对应即可。
5.1 数据库如图所示:
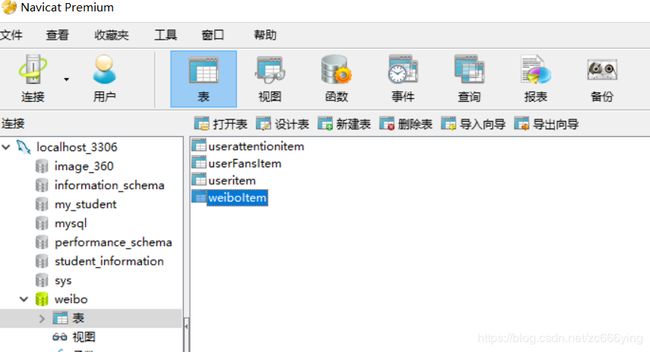
6. 连接数据库并将数据存入数据库
在 pipelines.py 中写入如下代码:
class PymysqlPipeline(object):
#连接数据库
def __init__(self):
self.connect = pymysql.connect(
host = 'localhost',
database = 'weibo',
user = 'root',
password = '123456',
charset = 'utf8',
port = 3306
)
# 创建游标对象
self.cursor = self.connect.cursor()
# 此方法是必须要实现的方法,被定义的 Item Pipeline 会默认调用这个方法对 Item 进行处理
def process_item(self,item,spider):
# 判断item是哪一类的item
if isinstance(item,UserItem):
cursor = self.cursor
sql = 'insert into userItem(id,screen_name,description,follow_count,followers_count,follow_me,following,verified_reason,statuses_count,url) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['id'],item['screen_name'],item['description'],item['follow_count'],item['followers_count'],item['follow_me'],item['following'],item['verified_reason'],item['statuses_count'],item['profile_url']
))
# 提交数据库事务
self.connect.commit()
return item
if isinstance(item,UserAttentionItem):
cursor = self.cursor
sql = 'insert into userAttentionItem(uid,screen_name,follow_count,followers_count,follow_me,following,profile_url) values (%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['id'],item['screen_name'],item['follow_count'],item['followers_count'],item['follow_me'],item['following'],item['profile_url']
))
#提交数据库事务
self.connect.commit()
return item
if isinstance(item,UserFansItem):
cursor = self.cursor
sql = 'insert into userfansitem(id,screen_name,follow_count,followers_count,desc1,desc2,profile_url) values (%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['id'],item['screen_name'],item['follow_count'],item['followers_count'],item['desc1'],item['desc2'],item['profile_url']
))
self.connect.commit()
return item
if isinstance(item,WeiboItem):
cursor = self.cursor
sql = 'insert into weiboitem(id,attitudes_count,comments_count,picture_url,raw_text,source,created_at) values (%s,%s,%s,%s,%s,%s,%s)'
cursor.execute(sql,(
item['id'],item['attitudes_count'],item['comments_count'],item['picture_url'],item['raw_text'],item['source'],item['created_at']
))
self.connect.commit()
return item
6.1 启动pipline
#开启自己写的 Pipeline
ITEM_PIPELINES = {
'weiboinfo.pipelines.PymysqlPipeline':300
}
7. 套娃、批量式获取微博用户信息
这个功能在上述的代码编写的时候就已经实现了,由于是不断的迭代爬取,后台在一直出现数据,按理来说是很难自动停下来的,所以我将构建迭代请求的代码注释掉,次全部代码的功能为分析一个人的微博用户,可以爬取其个人信息,关注列表,粉丝列表,所发的微博内容信息。
不想迭代式爬取的第二个原因是,存储困难,mysql数据库无法按自己的想法存储对应的信息,比如,我想对两位博主的信息进行爬取,将两位博主各自的关注列表,粉丝列表各存储到一个表当中,但是因为公用的是一个item,无法实现分别存放,只能生硬的存放到一个表当中,存储的方式感觉不是很得当,或者是自己没有想到更好的解决方法…
若想实现套娃、迭代式的爬取,只需将如下图的代码接触注释即可:


8. 代码存在的问题
此代码,在反爬方面仅在setting.py当中添加了不同的headers,和构造了基础的请求头信息,自己在迭代爬取的过程当中发现,当爬取的数据一次性超过1100条以上,自己的ip地址将会被短暂的禁止访问网页,所以这里的反爬做的很是不好,自己还得努力,争取学会搭建cookies池…
9. 爬取的结果
9.1 后台结果

9.2 数据库结果

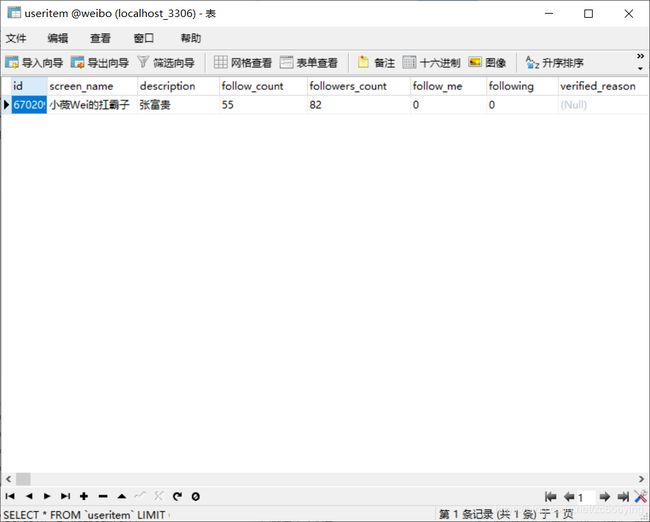
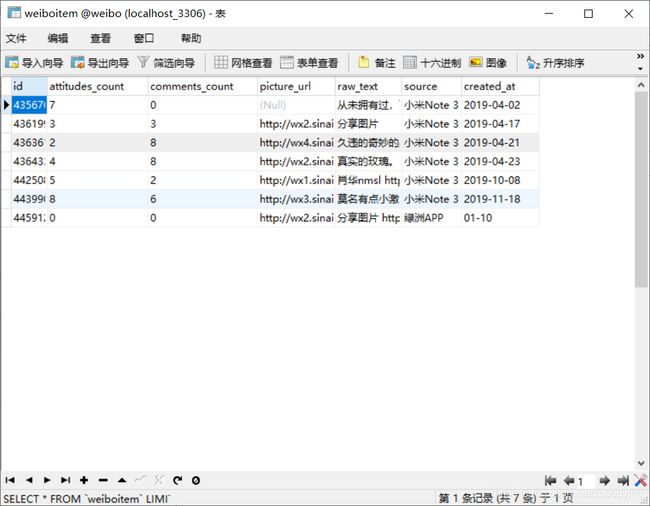
代码中有出现的错误和什么论述不对的地方,请评论或私信指出我立马改正。
大家有什么好的建议也可以评论或私信指出,小白接受任何批评