数据挖掘课设----适合练练手
本组成员利用id3和c4.5对数据进行分析和处理,在获取相关数据方面,本组将数据写入excel文件中,并将其命名为data,然后进度读取和分析处理。
数据预处理是分别利用c4.5和id3
实验数据:
| 收入 | 身高 | 长相 | 体型 | 是否见面 |
| 一般 | 高 | 丑 | 胖 | 否 |
| 高 | 一般 | 帅 | 瘦 | 是 |
| 一般 | 一般 | 一般 | 一般 | 否 |
| 高 | 高 | 丑 | 一般 | 是 |
| 一般 | 高 | 帅 | 胖 | 是 |
下面是对决策树的实验代码:
首先调用matplotlib包
# 绘制决策树
import matplotlib.pyplot as plt
再进行文本框的和箭头格式的定义
decisionNode = dict(boxstyle="round4", color='#ccccff') # 定义判断结点为圆角长方形,填充浅蓝色
leafNode = dict(boxstyle="circle", color='#66ff99') # 定义叶结点为圆形,填充绿色
arrow_args = dict(arrowstyle="<-", color='#ffcc00') # 定义箭头及颜色
上述代码中 boxstyle用于指定边框类型
此方法是对带箭头的注释:
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
然后是对叶子节点数的计算
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
在对树的层数进行计算:
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth
return maxDepth
# 在父子结点间填充文本信息
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt):
numLeafs = getNumLeafs(myTree)
depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0]
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt) # 在父子结点间填充文本信息
plotNode(firstStr, cntrPt, parentPt, decisionNode) # 绘制带箭头的注释
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
plotTree(secondDict[key], cntrPt, str(key))
else:
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(inTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops)
plotTree.totalW = float(getNumLeafs(inTree))
plotTree.totalD = float(getTreeDepth(inTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(inTree, (0.5, 1.0), '')
plt.show()
以上算法写的是决策树的创建
下面是写的是id3算法和c4.5算法的代码:
首先是对包的调用:
from math import log
import operator
import numpy as np
import pandas as pd
计算数据的熵
def dataentropy(data, feat):
lendata = len(data) # 数据条数
labelCounts = {} # 数据中不同类别的条数
for featVec in data:
category = featVec[-1] # 每行数据的最后一个字(叶子节点)
if category not in labelCounts.keys():
labelCounts[category] = 0
labelCounts[category] += 1 # 统计有多少个类以及每个类的数量
entropy = 0
for key in labelCounts:
prob = float(labelCounts[key]) / lendata # 计算单个类的熵值
entropy -= prob * log(prob, 2) # 累加每个类的熵值
return entropy
针对写入数据的处理(只能对特定格式的数据进行处理);
def Importdata(datafile):
dataa = pd.read_excel(datafile) # datafile是excel文件,所以用read_excel,如果是csv文件则用read_csv
# 将文本中不可直接使用的文本变量替换成数字
productDict = {'高': 1, '一般': 2, '低': 3, '帅': 1, '丑': 3, '胖': 3, '瘦': 1, '是': 1, '否': 0}
dataa['income'] = dataa['收入'].map(productDict) # 将每一列中的数据按照字典规定的转化成数字
dataa['hight'] = dataa['身高'].map(productDict)
dataa['look'] = dataa['长相'].map(productDict)
dataa['shape'] = dataa['体型'].map(productDict)
dataa['is_meet'] = dataa['是否见面'].map(productDict)
data = dataa.iloc[:, 5:].values.tolist() # 取量化后的几列,去掉文本列
b = dataa.iloc[0:0, 5:-1]
labels = b.columns.values.tolist() # 将标题中的值存入列表中
return data, labels
# 按某个特征value分类后的数据
def splitData(data, i, value):
splitData = []
for featVec in data:
if featVec[i] == value:
rfv = featVec[:i]
rfv.extend(featVec[i + 1:])
splitData.append(rfv)
return splitData
ID3 选择最优的分类特征:
def BestSplit(data):
numFea = len(data[0]) - 1 # 计算一共有多少个特征,因为最后一列一般是分类结果,所以需要-1
baseEnt = dataentropy(data, -1) # 定义初始的熵,用于对比分类后信息增益的变化
bestInfo = 0
bestFeat = -1
for i in range(numFea):
featList = [rowdata[i] for rowdata in data]
uniqueVals = set(featList)
newEnt = 0
for value in uniqueVals:
subData = splitData(data, i, value) # 获取按照特征value分类后的数据
prob = len(subData) / float(len(data))
newEnt += prob * dataentropy(subData, i) # 按特征分类后计算得到的熵
info = baseEnt - newEnt # 原始熵与按特征分类后的熵的差值,即信息增益
if (info > bestInfo): # 若按某特征划分后,若infoGain大于bestInf,则infoGain对应的特征分类区分样本的能力更强,更具有代表性。
bestInfo = info # 将infoGain赋值给bestInf,如果出现比infoGain更大的信息增益,说明还有更好地特征分类
bestFeat = i # 将最大的信息增益对应的特征下标赋给bestFea,返回最佳分类特征
return bestFeat
ID3对应的树:
def createTree(data, labels):
classList = [rowdata[-1] for rowdata in data] # 取每一行的最后一列,分类结果(1/0)
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(data[0]) == 1:
return majorityCnt(classList)
bestFeat = BestSplit(data) # 根据信息增益选择最优特征
bestLab = labels[bestFeat]
myTree = {bestLab: {}} # 分类结果以字典形式保存
del (labels[bestFeat])
featValues = [rowdata[bestFeat] for rowdata in data]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestLab][value] = createTree(splitData(data, bestFeat, value), subLabels)
return myTree
C4.5选择最优的分类特征
def BestSplit_2(data):
numFea = len(data[0])-1#计算一共有多少个特征,因为最后一列一般是分类结果,所以需要-1
baseEnt = dataentropy(data,-1) # 定义初始的熵,用于对比分类后信息增益的变化
bestGainRate = 0
bestFeat = -1
for i in range(numFea):
featList = [rowdata[i] for rowdata in data]
uniqueVals = set(featList)
newEnt = 0
for value in uniqueVals:
subData = splitData(data,i,value)#获取按照特征value分类后的数据
prob =len(subData)/float(len(data))
newEnt +=prob*dataentropy(subData,i) # 按特征分类后计算得到的熵
info = baseEnt - newEnt # 原始熵与按特征分类后的熵的差值,即信息增益
splitonfo = dataentropy(subData,i) #分裂信息
if splitonfo == 0:#若特征值相同(eg:长相这一特征的值都是帅),即splitonfo和info均为0,则跳过该特征
continue
GainRate = info/splitonfo #计算信息增益率
if (GainRate>bestGainRate): # 若按某特征划分后,若infoGain大于bestInf,则infoGain对应的特征分类区分样本的能力更强,更具有代表性。
bestGainRate=GainRate #将infoGain赋值给bestInf,如果出现比infoGain更大的信息增益,说明还有更好地特征分类
bestFeat = i #将最大的信息增益对应的特征下标赋给bestFea,返回最佳分类特征
return bestFeat
并其对应的树:
def createTree_2(data, labels):
classList = [rowdata[-1] for rowdata in data] # 取每一行的最后一列,分类结果(1/0)
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(data[0]) == 1:
return majorityCnt(classList)
bestFeat = BestSplit_2(data) # 根据信息增益选择最优特征
bestLab = labels[bestFeat]
myTree = {bestLab: {}} # 分类结果以字典形式保存
del (labels[bestFeat])
featValues = [rowdata[bestFeat] for rowdata in data]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestLab][value] = createTree_2(splitData(data, bestFeat, value), subLabels)
return myTree
# 按分类后类别数量排序,取数量较大的
def majorityCnt(classList):
c_count = {}
for i in classList:
if i not in c_count.keys():
c_count[i] = 0
c_count[i] += 1
ClassCount = sorted(c_count.items(), key=operator.itemgetter(1), reverse=True) # 按照统计量降序排序
return ClassCount[0][0] # reverse=True表示降序,因此取[0][0],即最大值
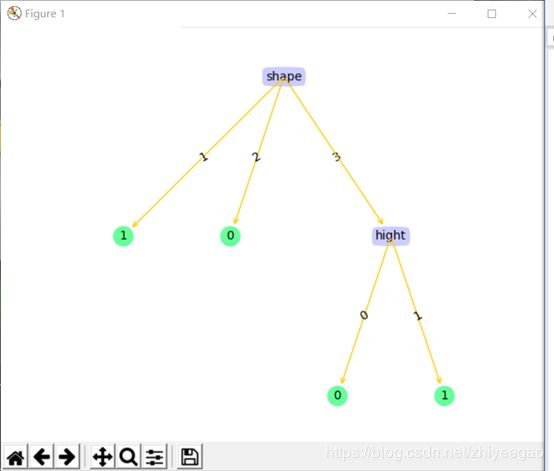
下面进行可视化的展示:

这是ID3算法:

C4.5算法: