超全的pandas数据分析常用函数总结:下篇
↑ 关注 + 星标 ~ 有趣的不像个技术号
每晚九点,我们准时相约 

大家好,我是雅痞绅士JM
基础知识在数据分析中就像是九阳神功,熟练的掌握,加以运用,就可以练就深厚的内力,成为绝顶高手自然不在话下!
为了更好地学习数据分析,我对于数据分析中pandas这一模块里面常用的函数进行了总结。整篇总结,在详尽且通俗易懂的基础上,我力求使其有很强的条理性和逻辑性,所以制作了思维导图,对于每一个值得深究的函数用法,我也会附上官方链接,方便大家继续深入学习。
文章中的所有代码都会有讲解和注释,绝大部分也都会配有运行结果,酱紫的话,整篇总结篇幅量自然不小,所以我分成了上下两篇,这里是下篇。
《超全的pandas数据分析常用函数总结:上篇》
5. 数据预处理
先创建一个data2数据集
data2=pd.DataFrame({
"id":np.arange(102,105),
"profit":[1,10,2]
})
data2
输出结果:

再创建一个data3数据集
data3=pd.DataFrame({
"id":np.arange(111,113),
"money":[106,51]
})
data3
输出结果:

5.1 数据的合并
用merge合并
DataFrame.merge(self,right,how =‘inner’,on = None)
right指要合并的对象
on指要加入的列或索引级别名称,必须在两个DataFrame中都可以找到。
how决定要执行的合并类型:left(使用左框架中的键)、right、inner(交集,默认)、outer(并集)
data_new=pd.merge(data,data2,on='id',how='inner') # 默认取交集
data_new=pd.merge(data,data2,on='id',how='outer') # 取并集,没有值的地方填充NaN
data.merge(data2,on='id',how='inner') # 另一种写法,输出结果见下方
输出结果:

更多关于pandas.DataFrame.merge的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html
data.merge(data2,on='id',how='left') # 使用左框架中的键
输出结果:
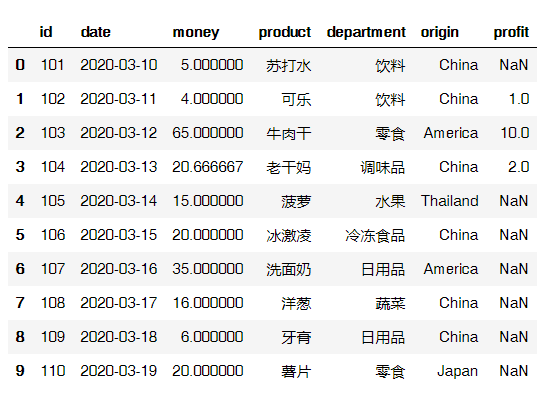
用append合并
data.append(data2) # 在原数据集的下方合并入新的数据集
输出结果:

用join合并
用下面这种方式会报错:列重叠,且没有指定后缀,因为上面的数据data和data2都有“id”列,所以需要给id列指明后缀。
data.join(data2) # 会报错
第一种修改方式:
data.join(data2,lsuffix='_data', rsuffix='_data2')
输出结果:

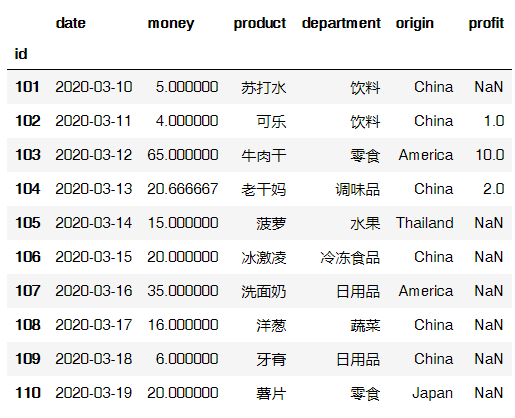
第二种修改方式:
data.set_index('id').join(data2.set_index('id'))
输出结果:
更多关于pandas.DataFrame.join的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.join.html
用concat合并
pandas.concat(objs,axis = 0,ignore_index = False,keys = None)
objs:Series,DataFrame或Panel对象的序列或映射。
axis:串联的轴,默认为0,即以索引串联(竖直拼接);如果为1,则以列串联(水平拼接)
ignore_index:清除现有索引并将其重置,默认为False。
key:在数据的最外层添加层次结构索引。
data_new=pd.concat([data,data2,data3],axis = 1,keys=['data', 'data2','data3'])
data_new
输出结果:

更多关于pandas.concat的用法,戳下面官方链接:
https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.concat.html
5.2 设置索引列
data.set_index("id") # 设置id为索引列
输出结果:

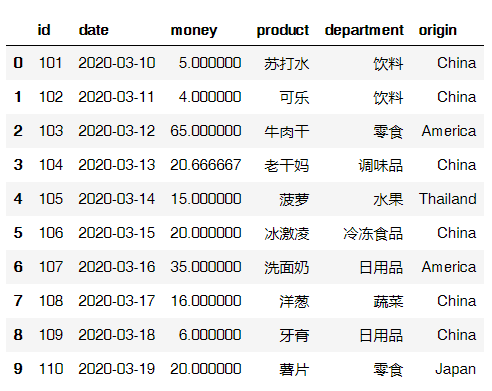
data.reset_index(drop=True) # 重置索引列,并且避免将旧索引添加为列
输出结果:
5.3 按照特定列的值排序:
按照索引列进行排序:
data.sort_index()
按照money的值进行排序:
data.sort_values(by="money",ascending = True) # ascending默认为True,即升序.
输出结果:

5.4 分类显示
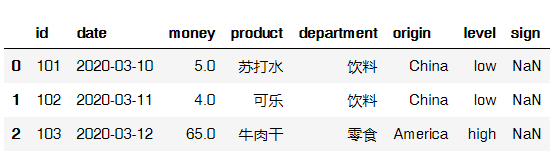
如果money列的值>=10, level列显示high,否则显示low:
data['level'] = np.where(data['money']>=10, 'high', 'low')
data
输出结果:

5.5 分组标记
data.loc[(data['level']=="high") & (data['origin']=="China"),"sign"]="棒"
data
输出结果:

5.6 切割数据
对date字段的值依次进行分列,并创建数据表,索引值为data的索引列,列名称为year\month\day。
data_split = pd.DataFrame((x.split('-') for x in data['date']), index=data.index, columns=['year','month','day'])
data_split
输出结果:

再与原数据表进行匹配:
pd.concat([data,data_split],axis=1)
输出结果:

6. 数据提取
下面这部分会比较绕:
loc函数按标签值进行提取,iloc按位置进行提取pandas.DataFrame.loc() 允许输入的值:
单个标签,例如5或’a’,(请注意,5被解释为索引的标签,而不是沿索引的整数位置)。
标签列表或数组,例如。[‘a’, ‘b’, ‘c’]
具有标签的切片对象,例如’a’:‘f’,切片的开始和结束都包括在内。
更多关于pandas.DataFrame.loc的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.loc.html#pandas.DataFrame.loc
pandas.DataFrame.iloc()
允许输入的值:整数5、整数列表或数组[4,3,0]、整数的切片对象1:7
更多关于pandas.DataFrame.iloc的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.iloc.html#pandas.DataFrame.iloc
6.1 单行索引
data.loc[6] # 提取索引值为6的那一行(即输出第7行)
输出结果:

data.iloc[6] # 提取第7行
输出结果同上!
6.2 区域索引
6.2.1 用loc取连续的多行
提取索引值为2到索引值为4的所有行,即提取第3行到第5行,注意:此时切片的开始和结束都包括在内。
data.loc[2:4]
输出结果:

提取“2020-03-13”之前的所有数据
data.loc[:"2020-03-13"]
输出结果:
6.2.2 用loc取不连续的多行
提取索引值为2和索引值为4的所有行,即提取第3行和第5行。
data.loc[[2,4]]
输出结果:

6.2.3 用loc取具体值
data.loc[6,"id"]
输出结果:107
6.2.4 用iloc取连续的多行
提取第3行到第6行
data.iloc[2:6]
输出结果:

6.2.5 用iloc取连续的多行和多列
提取第3行到第6行,第4列到第5列的值,取得是行和列交叉点的位置。
data.iloc[2:6,3:5]
输出结果:

6.2.6 用iloc取不连续的多行和多列
提取第3行和第6行,第4列和第5列的交叉值
data.iloc[[2,6],[3,5]]
输出结果:

6.2.7 用iloc取具体值
提取第3行第7列的值
data.iloc[2,6]
输出结果:‘high’
总结:文字变代码,数值少1;代码变文字,数值加1;代码从0开始计数;文字从1开始计数。
6.3 值的判断
方式一:判断origin列的值是否为China
data['origin']=="China"
方式二:判断department列的值是否为水果
data['department'].isin(['水果'])
输出结果:

data['department'].isin(['水果']).sum() # 对判断后的值进行汇总
输出结果:1
6.4 提取符合判断的值
data.loc[data['origin'].isin(['Thailand'])] # 将产地是泰国的数据进行提取
输出结果:

7. 数据筛选
7.1 使用与、或、非进行筛选
将满足origin是China且money小于35这两个条件的数据,返回其id、date、money、product、department、origin值。
data.loc[(data['origin']=="China") & (data['money']<35),['id','date','money','product','department','origin']]
输出结果:

将满足origin是China或者money小于35这两个条件之中任意一个条件的数据,返回其id、date、money、product、department、origin值。
data.loc[(data['origin']=="China") | (data['money']<35),['id','date','money','product','department','origin']]
输出结果:
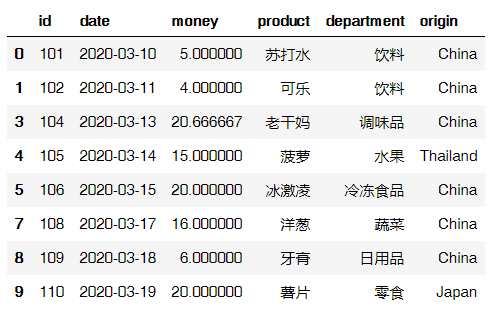
将满足origin是China且money不小于10这两个条件的数据,返回其id、date、money、product、department、origin值。
data.loc[(data['origin']=="China") != (data['money']<10),['id','date','money','product','department','origin']]
输出结果:
7.2 使用query函数进行筛选
data.query('department=="饮料"') # 单个条件筛选
data.query('department==["饮料","零食"]') # 多个条件筛选
输出结果:

更多关于pandas.DataFrame.query的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.query.html
7.3 对结果进行计数求和
data.query('department=="饮料"').count() # 对饮料类型的数据进行筛选后计数
data.query('department=="饮料"').money.count() # 对筛选后的数据按照money进行计数
输出结果:2
data.query('department=="饮料"').money.sum() # 在筛选后的数据中,对money进行求和
输出结果:9.0
8. 数据汇总
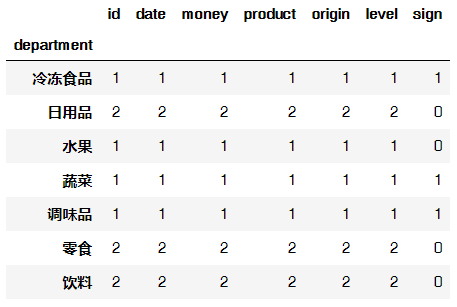
8.1 以department属性对所有列进行计数汇总
data.groupby("department").count()
输出结果:
8.2 以department属性分组之后,对id字段进行计数汇总
data.groupby("department")['id'].count()
输出结果:

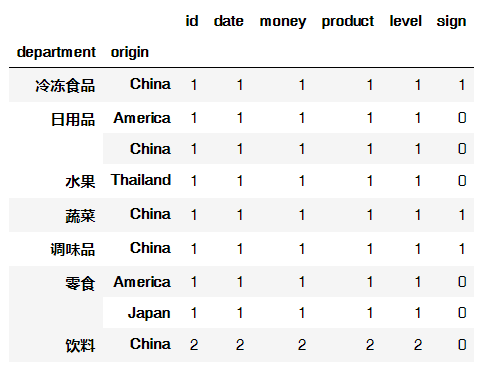
8.3 以两个属性进行分组计数
data.groupby(["department","origin"]).count()
输出结果:
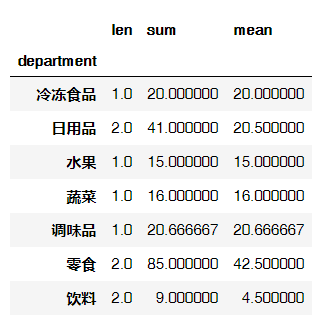
8.4 以department属性进行分组汇总并计算money的合计与均值
data.groupby("department")['money'].agg([len, np.sum, np.mean])
输出结果:
9. 数据统计
9.1 数据采样
pandas.DataFrame.sample(n = None,replace = False,weights = None)
n:样本数
replace:样本有无更换(有无放回)(默认不放回)
weights:权重
更多关于pandas.DataFrame.sample的用法,戳下面官方链接:https://pandas.pydata.org/pandas-docs/version/0.17.0/generated/pandas.DataFrame.sample.html
data.sample(3,replace=True,weights=[0.1,0.1,0.2,0.2,0.1,0.1,0.1,0.1,0,0])
输出结果:

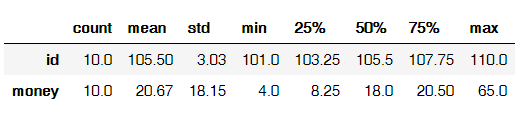
9.2 描述性统计
data.describe().round(2).T # round表示小数位数,T表示转置(这一函数之前提及过)
输出结果:
9.3 计算标准差
data['money'].std()
输出结果:18.14754345175493
9.4 计算协方差
data.cov()
输出结果:

9.5 相关性分析
data.corr()
输出结果:

思维导图

完整思维导图电子版(PDF)
关注公众号「凹凸数据」后台回复“思维导图”即可获取
参考资料:
pandas官网
pandas用法总结
Pandas 文本数据方法

如果本文对你有帮助
欢迎扫描二维码关注作者的今日头条

(或在今日头条搜索“雅痞绅士JM”)
近期文章,点击图片即可查看




后台回复关键词「进群」,即刻加入读者交流群~

五
学好潘大师,数分全不怕!

朱小五