Java并发编程 | 第一篇: Java线程池
1、什么是线程池
线程池的基本思想是一种对象池,在程序启动时就开辟一块内存空间,里面存放了众多(未死亡)的线程,池中线程执行调度由池管理器来处理。当有线程任务时,从池中取一个,执行完成后线程对象归池,这样可以避免反复创建线程对象所带来的性能开销,节省了系统的资源。
2、使用线程池的好处
- 减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
- 运用线程池能有效的控制线程最大并发数,可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
- 对线程进行一些简单的管理,比如:延时执行、定时循环执行的策略等,运用线程池都能进行很好的实现
3、线程池的主要组件
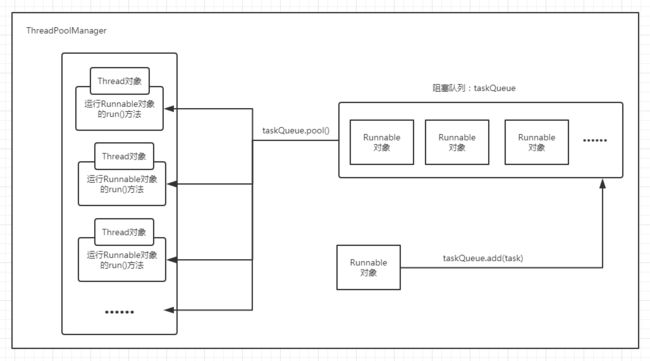
一个线程池包括以下四个基本组成部分:
- 线程池管理器(ThreadPool):用于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
- 工作线程(WorkThread):线程池中线程,在没有任务时处于等待状态,可以循环的执行任务;
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行,它主要规定了任务的入口,任务执行完后的收尾工作,任务的执行状态等;
- 任务队列(taskQueue):用于存放没有处理的任务。提供一种缓冲机制。
4、ThreadPoolExecutor类
讲到线程池,要重点介绍java.uitl.concurrent.ThreadPoolExecutor类,ThreadPoolExecutor线程池中最核心的一个类,ThreadPoolExecutor在JDK中线程池常用类UML类关系图如下:

我们可以通过ThreadPoolExecutor来创建一个线程池
new ThreadPoolExecutor(corePoolSize, maximumPoolSize,keepAliveTime,
milliseconds,runnableTaskQueue, threadFactory,handler);
1. 创建一个线程池需要输入几个参数
- corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads方法,线程池会提前创建并启动所有基本线程。
- maximumPoolSize(线程池最大大小):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是如果使用了无界的任务队列这个参数就没什么效果。
- runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。
- ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字,Debug和定位问题时非常又帮助。
- RejectedExecutionHandler(拒绝策略):当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。以下是JDK1.5提供的四种策略。n AbortPolicy:直接抛出异常。
- keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以如果任务很多,并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。
- TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS),小时(HOURS),分钟(MINUTES),毫秒(MILLISECONDS),微秒(MICROSECONDS, 千分之一毫秒)和毫微秒(NANOSECONDS, 千分之一微秒)。
2. 向线程池提交任务
我们可以通过execute()或submit()两个方法向线程池提交任务,不过它们有所不同
- execute()方法没有返回值,所以无法判断任务知否被线程池执行成功
threadsPool.execute(new Runnable() {
@Override
public void run() {
// TODO Auto-generated method stub
}
});
- submit()方法返回一个future,那么我们可以通过这个future来判断任务是否执行成功,通过future的get方法来获取返回值
try {
Object s = future.get();
} catch (InterruptedException e) {
// 处理中断异常
} catch (ExecutionException e) {
// 处理无法执行任务异常
} finally {
// 关闭线程池
executor.shutdown();
}
3. 线程池的关闭
我们可以通过shutdown()或shutdownNow()方法来关闭线程池,不过它们也有所不同
- shutdown的原理是只是将线程池的状态设置成SHUTDOWN状态,然后中断所有没有正在执行任务的线程。
- shutdownNow的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。shutdownNow会首先将线程池的状态设置成STOP,然后尝试停止所有的正在执行或暂停任务的线程,并返回等待执行任务的列表。
4. ThreadPoolExecutor执行的策略
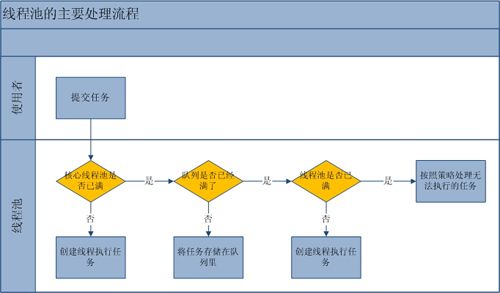
- 线程数量未达到corePoolSize,则新建一个线程(核心线程)执行任务
- 线程数量达到了corePools,则将任务移入队列等待
- 队列已满,新建线程(非核心线程)执行任务
- 队列已满,总线程数又达到了maximumPoolSize,就会由(RejectedExecutionHandler)抛出异常
新建线程 -> 达到核心数 -> 加入队列 -> 新建线程(非核心) -> 达到最大数 -> 触发拒绝策略
5. 四种拒绝策略
- AbortPolicy:不执行新任务,直接抛出异常,提示线程池已满,线程池默认策略
- DiscardPolicy:不执行新任务,也不抛出异常,基本上为静默模式。
- DisCardOldSetPolicy:将消息队列中的第一个任务替换为当前新进来的任务执行
- CallerRunPolicy:拒绝新任务进入,如果该线程池还没有被关闭,那么这个新的任务在执行线程中被调用)
5、Java通过Executors提供四种线程池
- CachedThreadPool():可缓存线程池。
- 线程数无限制
- 有空闲线程则复用空闲线程,若无空闲线程则新建线程
一定程序减少频繁创建/销毁线程,减少系统开销
- FixedThreadPool():定长线程池。
- 可控制线程最大并发数(同时执行的线程数)
- 超出的线程会在队列中等待
- ScheduledThreadPool():
- 定时线程池。
- 支持定时及周期性任务执行。
- SingleThreadExecutor():单线程化的线程池。
- 有且仅有一个工作线程执行任务
- 所有任务按照指定顺序执行,即遵循队列的入队出队规则
1. newCachedThreadPool
newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程
public class ThreadPoolExecutorTest1 {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
final int index = i;
try {
Thread.sleep(index * 1000);
} catch (Exception e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName()+":"+index);
}
});
}
}
}
2. newFixedThreadPool
newFixedThreadPool创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待,指定线程池中的线程数量和最大线程数量一样,也就线程数量固定不变
示例代码如下
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);// 每隔两秒打印3个数
for (int i = 0; i < 10; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
public void run() {
try {
System.out.println(Thread.currentThread().getName()+":"+index);
//三个线程并发
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
3. newscheduledThreadPool
newscheduledThreadPool创建一个定长线程池,支持定时及周期性任务执行。延迟执行示例代码如下.表示延迟1秒后每3秒执行一次
public class ThreadPoolExecutorTest3 {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println(Thread.currentThread().getName() + ": delay 1 seconds, and excute every 3 seconds");
}
}, 1, 3, TimeUnit.SECONDS);// 表示延迟1秒后每3秒执行一次
}
}

4. newSingleThreadExecutor
newSingleThreadExecutor创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行
public class ThreadPoolExecutorTest4 {
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
public void run() {
try {
System.out.println(Thread.currentThread().getName() + ":" + index);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
结果依次输出,相当于顺序执行各个任务。使用JDK自带的监控工具来监控我们创建的线程数量,运行一个不终止的线程,创建指定量的线程,来观察
6、线程池ThreadPoolExecutor参数设置
参数的设置跟系统的负载有直接的关系,下面为系统负载的相关参数:
- tasks,每秒需要处理的的任务数
- tasktime,处理每个任务花费的时间
- responsetime,系统允许任务最大的响应时间,比如每个任务的响应时间不得超过2秒。
corePoolSize
每个任务需要tasktime秒处理,则每个线程每钞可处理1/tasktime个任务。系统每秒有tasks个任务需要处理,则需要的线程数为:tasks/(1/tasktime),即tasks*tasktime个线程数。
假设系统每秒任务数为100 ~ 1000,每个任务耗时0.1秒,则需要100 * 0.1至1000 * 0.1,即10 ~ 100个线程。那么corePoolSize应该设置为大于10,具体数字最好根据8020原则,即80%情况下系统每秒任务数小于200,最多时为1000,则corePoolSize可设置为20。
maxPoolSize
当系统负载达到最大值时,核心线程数已无法按时处理完所有任务,这时就需要增加线程。每秒200个任务需要20个线程,那么当每秒达到1000个任务时,则需要(1000-queueCapacity)*(20/200),即60个线程,可将maxPoolSize设置为60。
queueCapacity
任务队列的长度要根据核心线程数,以及系统对任务响应时间的要求有关。队列长度可以设置为(corePoolSize/tasktime)*responsetime: (20/0.1)*2=400,即队列长度可设置为400。
队列长度设置过大,会导致任务响应时间过长,切忌以下写法:
LinkedBlockingQueue queue = new LinkedBlockingQueue();
这实际上是将队列长度设置为Integer.MAX_VALUE,将会导致线程数量永远为corePoolSize,再也不会增加,当任务数量陡增时,任务响应时间也将随之陡增。
keepAliveTime
当负载降低时,可减少线程数量,当线程的空闲时间超过keepAliveTime,会自动释放线程资源。默认情况下线程池停止多余的线程并最少会保持corePoolSize个线程。
allowCoreThreadTimeout
默认情况下核心线程不会退出,可通过将该参数设置为true,让核心线程也退出。