kafka教程:基础概念、win10下安装与配置、Java中使用kafka
目录
- 一、基础概念
- 二、安装ZooKeeper
- 三、kafka安装
- 四、Java使用
一、基础概念
Kafka是一种高吞吐量的分布式发布订阅消息系统。kafka作为一个集群运行在一个或多个服务器上,kafka集群存储的消息是以topic为类别记录的,每个消息是由一个key,一个value和时间戳构成。对于传统消息系统,消费者处理一条消息后,消息系统清除该条消息,如果消费者处理失败,该条消息也消失。kafka会将所有消息存储下来,直到它们过期(无论消息是否被消费),消费者只是读取一个偏移量,通过偏移量获取消息。
1、Topic(主题):kafka将消息分门别类,每一类的消息称之为主题(Topic)。
2、Partition(分区):对于每个Topic,kafka集群都会维护一个分区log,如图,每一个分区都是一个顺序的、不可变的消息队列,并且可以持续的添加。
3、Offset(偏移量):分区的消息被分了一个序列号,成为偏移量。偏移量由消费者控制。
4、kafka Cluster(kafka集群):已发布的消息保存在一组服务器中,称之为kafka集群。
5、Broker(代理):集群中每一个服务器都是一个代理。每个代理中的每个主题可以具有零个或多个分区。假设主题分区数为M,代理数为N:当M = N时,每个代理各自拥有一个分区;当M < N时,只有前M个代理具有一个分区,剩余的代理将不拥有该主题的任何分区;当M > N时,每个代理之间具有一个分区或多个分区共享,由于代理之间的负载分布不相等,不建议使用。
6、Producer(生产者):发布消息的对象,负责向某个Topic发送消息,生产者可以选择自己想发送到的分区。
7、Consumer(消费者):订阅消息并处理发布的对象。
8、消费组:同一组的消费者用消费组来标记自己,相当于同一组的消费者具有一个相同的标记,不同组的标记不同。
9、Leader(领导者)和Follower(追随者):每个分区有一个leader,零或多个follower。leader处理分区所有的读写请求,follower只被动的复制数据,如果leader宕机,会有一个follower被推举为新的leader。一台服务器可能同时是一个分区的leader,另一个分区的follower,这样可以平衡负载,避免所有的请求只让集群中的一台或者某几台服务器处理。leader和follower由ZooKeeper决定。
10、消费模型:消费模型有两种
发布-订阅模式:
(1)生产者定期向主题发送消息。
(2)Kafka代理存储为该特定主题配置的分区中的所有消息。 它确保消息在分区之间平等共享。 如果生产者发送两个消息并且有两个分区,Kafka将在第一分区中存储一个消息,在第二分区中存储第二消息。
(3)消费者订阅特定主题。
(4)一旦消费者订阅主题,Kafka将向消费者提供主题的当前偏移,并且还将偏移保存在Zookeeper系综中。
(5)消费者将定期请求Kafka(如100 Ms)新消息。
(6)一旦Kafka收到来自生产者的消息,它将这些消息转发给消费者。
(7)消费者将收到消息并进行处理。
(8)一旦消息被处理,消费者将向Kafka代理发送确认。
(9)一旦Kafka收到确认,它将偏移更改为新值,并在Zookeeper中更新它。 由于偏移在Zookeeper中维护,消费者可以正确地读取下一条消息,即使在服务器暴力期间。
以上流程将重复,直到消费者停止请求。
队列模式:
(1)生产者以固定间隔向某个主题发送消息。
(2)Kafka存储在为该特定主题配置的分区中的所有消息,类似于前面的方案。
(3)单个消费者订阅特定主题,假设主题为Topic-01,该消费者所在消费组的组ID为Group-1。
(4)Kafka以与发布-订阅消息相同的方式与该消费者交互,直到相同组ID的新消费者订阅相同主题Topic-01。注意:一条消息只有其中的一个消费者来处理。
(5)一旦新消费者到达,Kafka将其操作切换到共享模式,并在两个消费者之间共享数据。此共享将继续,直到用户数达到为该特定主题配置的分区数。
(6)一旦消费者的数量超过分区的数量,新消费者将不会接收任何进一步的消息,直到现有消费者取消订阅任何一个消费者。出现这种情况是因为Kafka中的每个消费者将被分配至少一个分区,并且一旦所有分区被分配给现有消费者,新消费者将必须等待。
由于Topic分区中消息只能由消费者组中的唯一一个消费者处理,所以kafka能够保证一个分区内的消息是被按顺序处理的。
二、安装ZooKeeper
zookeeper也可以不进行下载,因为kafka中内置了zookeeper。
1、下载安装
官网下载链接,本文使用的是3.4.14版本,下载后解压。
2、修改配置
复制zookeeper-3.4.14\conf目录下的zoo_sample.cfg并改名为zoo.cfg,对其zoo.cfg配置进行修改:
dataDir=C:/ZHSUN/zookeeper-3.4.14/data
3、开启服务
cmd命令进入bin目录,输入命令:
zkServer.cmd
打开服务端

如果输入命令:
zkCli.cmd
则打开客户端
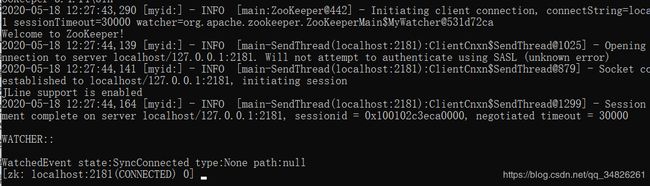
三、kafka安装
1、下载安装
官网下载链接,注意要下载二进制版本,下载后解压。

2、修改配置
进入所安装文件的config目录,打开server.properties,找到并编辑:
log.dirs=C:/ZHSUN/kafka_2.12-2.5.0/kafka-logs
进入zookeeper.properties修改:
dataDir=C:/ZHSUN/kafka_2.12-2.5.0/data
3、开启kafka内置的zookeeper
cmd命令进入kafka目录,输入命令:
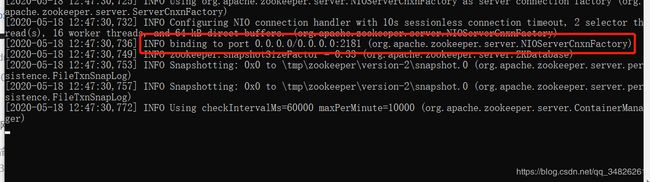
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
若出现binding to port 0.0.0.0/0.0.0.0:2181,则表示kafka内置的zookeeper启动成功。注意:不要关闭该命令窗口。

4、启动kafka服务
新打开cmd命令窗口,进入kafka目录,输入命令:
.\bin\windows\kafka-server-start.bat .\config\server.properties
打开

同样不要关闭该命令窗口。
5、简单测试:
(1)创建主题
新打开cmd命令窗口,进入kafka目录,输入命令:
.\bin\windows\kafka-topics.bat --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建Topic,不要关闭界面

(2)创建生产者
新命令窗口,进入kafka目录:
.\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
(3)创建消费者
新命令窗口,进入kafka目录:
.\bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test --from-beginning
(4)进行测试
生产者输入消息,消费者就能接收到消息,若消费者界面未收到消息,按一下回车。
四、Java使用
需要保证zookeeper和kafka已启动(参照三(3、4)),否则程序会报NullPointerException。
1、加入依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.0</version>
</dependency>
2、配置文件
在resources目录下创建kafka.properties
#produce
bootstrap.servers=localhost:9092
producer.type=sync
request.required.acks=1
serializer.class=kafka.serializer.DefaultEncoder
key.serializer=org.apache.kafka.common.serialization.StringSerializer
value.serializer=org.apache.kafka.common.serialization.StringSerializer
bak.partitioner.class=kafka.producer.DefaultPartitioner
bak.key.serializer=org.apache.kafka.common.serialization.StringSerializer
bak.value.serializer=org.apache.kafka.common.serialization.StringSerializer
#consume
zookeeper.connect=localhost:2181
group.id=kafkaDemo
zookeeper.session.timeout.ms=4000
zookeeper.sync.time.ms=200
auto.commit.interval.ms=1000
auto.offset.reset=earliest
serializer.class=kafka.serializer.StringEncoder
key.deserializer=org.apache.kafka.common.serialization.StringDeserializer
value.deserializer=org.apache.kafka.common.serialization.StringDeserializer
3、生产者代码
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.io.IOException;
import java.io.InputStream;
import java.util.Properties;
public class ProducerTest {
private static Properties properties;
/**
* 读取kafka配置
*/
private static void init() {
properties = new Properties();
InputStream inStream = KafkaProducer.class.getClassLoader().getResourceAsStream("kafka.properties");
try {
properties.load(inStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public ProducerTest() {
init();
}
/**
* 生产消息并发送
* @param topic
* @param key
* @param value
*/
public void sendMessage(String topic, String key, String value) {
// 实例化生产者
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 消息封装
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>(topic, key, value);
// 发送消息
kafkaProducer.send(producerRecord, new Callback() {
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(null != e) {
System.out.println("消息所在偏移量:" + recordMetadata.offset());
System.out.println(e.getMessage() + e);
}
}
});
// 关闭生产者
kafkaProducer.close();
}
}
4、消费者代码
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.io.IOException;
import java.io.InputStream;
import java.util.Collections;
import java.util.Properties;
public class ConsumerTest {
private static Properties properties;
private long size = 100;
private KafkaConsumer<String, String> kafkaConsumer;
/**
* 读取kafka配置
*/
private static void init() {
properties = new Properties();
InputStream inStream = KafkaConsumer.class.getClassLoader().getResourceAsStream("kafka.properties");
try {
properties.load(inStream);
} catch (IOException e) {
e.printStackTrace();
}
}
public ConsumerTest() {
init();
}
/**
* 消费消息
* @param topic
*/
public void getMessage(String topic) {
kafkaConsumer = new KafkaConsumer<String, String>(properties);
// 订阅主题
kafkaConsumer.subscribe(Collections.singletonList(topic));
while (true) {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(size);
for(ConsumerRecord<String, String> record : consumerRecords) {
System.out.printf("offset = %d, key = %s, value = %s", record.offset(), record.key(), record.value());
System.out.println();
}
}
}
/**
* 关闭生产者
*/
public void closeConsumer() {
kafkaConsumer.close();
}
}
5、测试代码
public class Main
{
public static void main( String[] args ) {
String topic = "testTopic";
ProducerTest producer = new ProducerTest();
producer.sendMessage(topic, "key0", "{\"id\": \"123\", \"name\": \"张三\"}");
producer.sendMessage(topic, "key1", "{\"id\": \"321\", \"name\": \"李四\"}");
ConsumerTest consumer = new ConsumerTest();
consumer.getMessage(topic);
consumer.closeConsumer();
}
}
