ACM暑期集训12
今天学了后缀数组,感觉好难理解,只能搬PPT,粘模板了~~
1)后缀: suffix(i)为从下标i开始的后缀
String = “abcdef” Suffix(1) = “bcdef” Suffix(2) = “cdef”
什么是后缀数组?
把一个字符串的所有后缀按字典序进行排序。
后缀数组sa[i]表示排名为i的后缀下标是什么,
rk[i]表示下标为i的后缀排名是多少 rk和sa是一种互逆的关系
aabac sa[1] = 0 rk[0] = 1
abac sa[2] = 1 rk[1] = 2
String = “aabac” ac sa[3] = 3 rk[2] = 4
bac sa[4] = 2 rk[3] = 3
c sa[5] = 4 rk[4] = 5
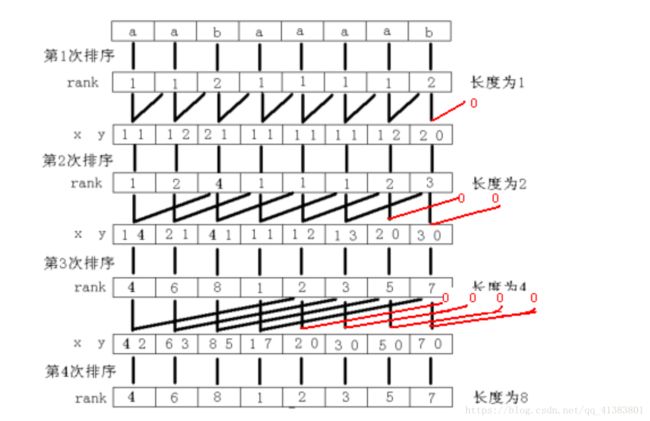
最朴素的:把所有后缀找出来,总共有n个,进行快速排序,复杂度nlogn 但是字符串比较也需要n的复杂度,所以总复杂度n^2logn。
优化:使用倍增和基数排序的方法,复杂度nlogn
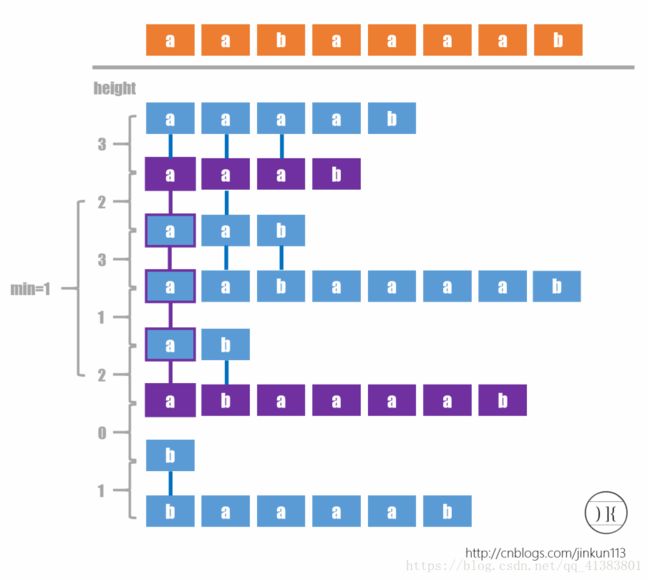
2)height数组
Height[i]表示suffix(sa[i])和suffix(sa[i-1])的最长公共前缀, 也就是排名i的后缀和排名i-1的后缀的最长公共前缀
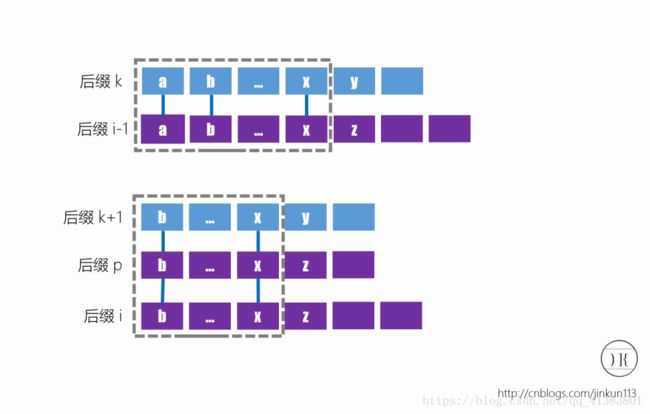
如何求height
首先定义h[i] = height(rk[i])
有一个定理h[i] >= h[i-1] -1
注意这里的i表示字符串的下标,也就是字符串 下标在每次右移时,它的height一定不会突降2 及以上。
一个比较明显的结论:两个排名越靠近的 后缀,相似度越高。
2.代码
#include
using namespace std;
//倍增算法 O(n*logn)
//待排序数组长度为n,放在0~n-1中,在最后面补一个0 num[n] = 0
const int MAXN = 10000;
char s[MAXN];
int wa[MAXN],wb[MAXN],wv[MAXN],wd[MAXN],num[MAXN],minl[MAXN][20],n;
//wa,wb是给关键字排序用的临时数组
//wd是基数排序用的临时数组
//把字符串转化成ascii放在num中
//minl用于查询区间最小值
int cmp(int *r,int a,int b,int l){
return r[a]==r[b] && r[a+l]==r[b+l];
}
int sa[MAXN],rk[MAXN],height[MAXN];
//注意 最后一个值即num[n]一定要比所有的都小
void SA(int *r,int n){//n输入长度+1,SA(str,len+1)
int *x=wa,*y=wb,m=0;
//x作为第一关键字的rank
for (int i=0;i=0; --i) sa[--wd[x[i]]]=i;
//基数排序,排名为--wd[x[i]]的下标为i,因为这里i从n-1开始,所以当出现值相等时,靠近尾部的排名值更大,靠近头部排名值更小
int p=1;
for(int j=1; p=j) y[p++]=sa[i]-j;
//从排名为0的第一关键字开始,现在要把他们当成第二关键字
//但是下标在0--j-1这些不用作为第二关键字,因为他们前面没有第一关键字
//这里比较的是第二关键字,但是y存的是第二关键字对应的第一关键字的位置,方便后面处理,所以要sa[i]-j
for(int i=0; i=0; --i) sa[--wd[wv[i]]]=y[i];//同样进行排序,这里是=y[i],因为i表示的是排名,y[i]才表示位置
//上一步只求了sa,还没有求rk,所以下面求rk
swap(x,y); x[sa[0]]=0; p=1;
for(int i=1; ib) swap(a,b);
return askRMQ(a+1,b);//这里要注意,height[a]是a和a-1比较了,不能算入。
}
//最长回文串
int main()
{
while (scanf("%s",s)!=EOF)
{
int len=strlen(s);
n=2*len+1;
for (int i=0;i maxlen)
{
maxlen = tmp*2+1;
maxpos = i;
}
tmp = lcp(n-i-1,i+1);
if (tmp*2 > maxlen)
{
maxlen = tmp*2;
maxpos = i;
}
}
if (maxlen&1)
for (int i=maxpos-maxlen/2;i<=maxpos+maxlen/2;i++)
printf("%c",s[i]);
else
for (int i=maxpos-maxlen/2+1;i<=maxpos+maxlen/2;i++)
printf("%c",s[i]);
printf("\n");
}
return 0;
}