网络I/O模型和netty的模型
五种网络I/O模型分别是阻塞I/O,非阻塞I/O,多路复用I/O,信号驱动I/O,异步I/O,netty使用的是第三种:多路复用I/O,下面我们分别介绍下下面各种I/O。
1:阻塞I/O

这幅图看起来不太友好,特别是对新接触网络编程的新手来说,可能一头雾水,其实这个网络模型的特征就在于发起系统调用的同时,内核空间在等待数据到来,这个时候数据还没准备好,程序会一直阻塞,当数据到来,数据从内核到用户态转变,拷贝数据完成,才把数据返回。这么说可能还不太好理解,那么直接贴代码:
try {
int port=8000;
ServerSocket server=new ServerSocket(port);
Socket socket=server.accept();
InputStream inputStream = socket.getInputStream();
byte[] b = new byte[1024];
int len = -1;
while ((len = inputStream.read(b)) > 0) {
}
} catch (IOException e) {
e.printStackTrace();
}上面的图对应代码就是inputStream.read(b)这句话,如果数据没有准备好,线程是阻塞在这里的,直到数据准备好,线程继续执行,所谓的阻塞就是阻塞在这些未就绪的操作上,数据来了才会就绪,上面只是以read为例,阻塞和非阻塞也是针对用户线程来说的。
2:非阻塞I/O
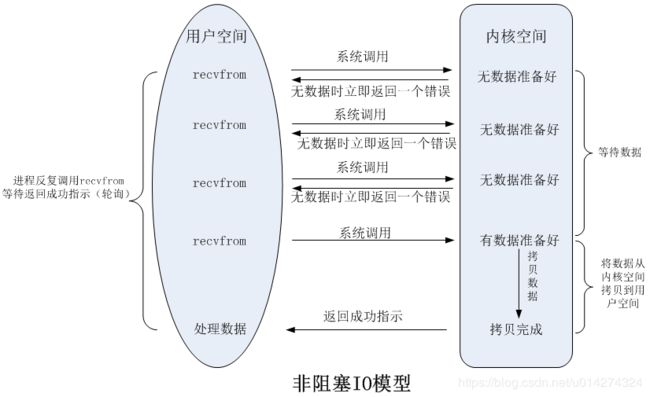
看完第一幅图之后再看第二幅图就很美好了,当发生系统调用的时候,如果没有数据准备好,立即先返回给用户一个信息,而不是让用户线程一直傻傻的等,下面贴下代码:
//得到一个网络通道
SocketChannel socketChannel = SocketChannel.open();
//设置非阻塞
socketChannel.configureBlocking(false);
//提供服务器端的ip 和 端口
InetSocketAddress inetSocketAddress = new InetSocketAddress("127.0.0.1", 6666);
//连接服务器
if (!socketChannel.connect(inetSocketAddress)) {
while (!socketChannel.finishConnect()) {
System.out.println("因为连接需要时间,客户端不会阻塞,可以做其它工作..");
}
}
//...如果连接成功,就发送数据
String str = "hello, 666~";
//Wraps a byte array into a buffer
ByteBuffer buffer = ByteBuffer.wrap(str.getBytes());
//发送数据,将 buffer 数据写入 channel
socketChannel.write(buffer);
ByteBuffer bufferRead = ByteBuffer.allocate(1024);
while (socketChannel.read(bufferRead) != -1) {
}上面这段代码执行socketChannel.read(bufferRead)的时候,用户线程并不会堵塞,如果没有数据,此时read函数就会返回0,-1代表异常结束,线程一直会轮训,从上面的时候也可以看出,阻塞I/O和非阻塞I/O并没有谁好不好之分,如果请求不频繁,这个时候阻塞,把cpu让出去执行别的任务更好,如果请求频繁,主动让出cpu就会降低系统吞吐,在不同的场景下,有不同的选择,基于这种纠结的方式,所以就有了多路复用,这也是目前互联网大厂一般所用的I/O模型。
3:多路复用I/O

多路复用I/O也叫事件驱动I/O,顾名思义,就是事件驱动程序I/O运行,从图中可以看出,多路复用I/O分为2步,第一步系统调用,没有数据准备好,就阻塞应用线程,直到数据到来,返回给用户线程可读的指示,第二步用户线程直接读取数据,许多人可能有疑问了,这不是和阻塞I/O一模一样么?仔细的同学可能已经看出来了,第一步是select/epoll,而不是recvfrom,那么第一步的意义是什么?多路复用的意思是多条路(channel)能够公用一些东西,这个东西就是select/epoll,也就是如果我们有1000个路(channel),交给select,epoll统一管理,我们先阻塞当前用户线程,知道数据来了,我知道哪一个路(channel)有数据,我把这个路(channel)给用户线程,用户线程去取数据,这样我们1000条路只阻塞在一条上,而阻塞I/O可能要阻塞在1000条路上,这就是不同,下面贴下代码:
//创建ServerSocketChannel -> ServerSocket
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
//得到一个Selecor对象
Selector selector = Selector.open();
//绑定一个端口6666, 在服务器端监听
serverSocketChannel.socket().bind(new InetSocketAddress(6666));
//设置为非阻塞
serverSocketChannel.configureBlocking(false);
//把 serverSocketChannel 注册到 selector 关心 事件为 OP_ACCEPT
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
//serverSocketChannel.register(selector, 0);
System.out.println("注册后的selectionkey 数量=" + selector.keys().size()); // 1
//循环等待客户端连接
while (true) {
//这里我们等待1秒,如果没有事件发生, 返回
if(selector.select(1000) == 0) { //没有事件发生
System.out.println("selector服务器等待了1秒,无连接");
continue;
}
//如果返回的>0, 就获取到相关的 selectionKey集合
//1.如果返回的>0, 表示已经获取到关注的事件
//2. selector.selectedKeys() 返回关注事件的集合
// 通过 selectionKeys 反向获取通道
Set selectionKeys = selector.selectedKeys();
System.out.println("selectionKeys 数量 = " + selectionKeys.size());
//遍历 Set, 使用迭代器遍历
Iterator keyIterator = selectionKeys.iterator();
while (keyIterator.hasNext()) {
//获取到SelectionKey
SelectionKey key = keyIterator.next();
int readyOps = key.readyOps();
//根据key 对应的通道发生的事件做相应处理
if(key.isAcceptable()) { //如果是 OP_ACCEPT, 有新的客户端连接
//该该客户端生成一个 SocketChannel
SocketChannel socketChannel = serverSocketChannel.accept();
//将 SocketChannel 设置为非阻塞
socketChannel.configureBlocking(false);
//将socketChannel 注册到selector, 关注事件为 OP_READ, 同时给socketChannel
//关联一个Buffer
socketChannel.register(selector, SelectionKey.OP_READ,
ByteBuffer.allocate(1024));
System.out.println("客户端连接后 ,注册的selectionkey 数量=" +
selector.keys().size()); //2,3,4..
}
if(key.isReadable()) { //发生 OP_READ
//通过key 反向获取到对应channel
SocketChannel channel = (SocketChannel)key.channel();
//获取到该channel关联的buffer
ByteBuffer buffer = (ByteBuffer)key.attachment();
channel.read(buffer);
}
//手动从集合中移动当前的selectionKey, 防止重复操作
keyIterator.remove();
}
}
} 先把channel注册到selector上,然后阻塞在selector.select(1000)这句话上,所有的channel都阻塞在这个上面,然后如果有数据到来就去除相应的channel进行操作,这种模型大大降低了I/O模型中应用线程的阻塞个数,也避免了无意义的轮训,但是在链接数很少的时候优势并不明显,链接数超过1000之后就会有很明显的效果了,号称单台服务器可以支持百万链接,当然不能同时来数据,另一种情况是在弱网(不稳定的网络环境下)很突出,线上的网络环境都是不稳定的,有的时候可能一大批数据同时到来,这个时候排队就很重要了,多路复用的作用就突出了。
4:信号驱动I/O
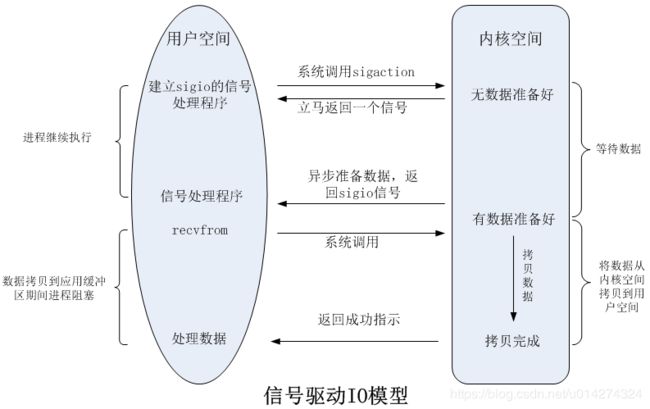
在信号驱动IO模型中,当用户线程发起一个IO请求操作,会给对应的socket注册一个信号函数,然后用户线程会继续执行,当内核数据就绪时会发送一个信号给用户线程,用户线程接收到信号之后,便在信号函数中调用IO读写操作来进行实际的IO请求操作。
5:异步I/O
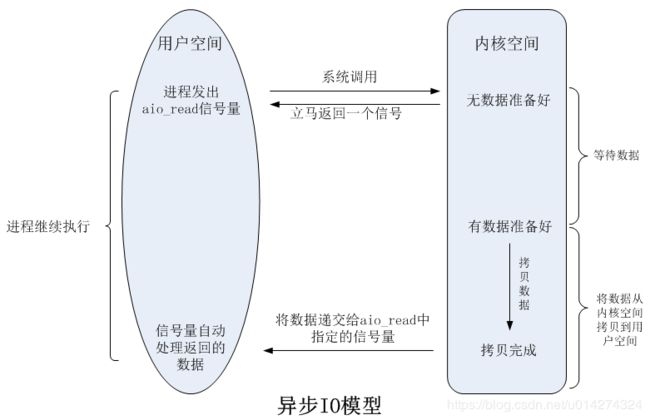
异步IO模型才是最理想的IO模型,在异步IO模型中,当用户线程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从内核的角度,当它受到一个异步读取之后,它会立刻返回,说明read请求已经成功发起了,因此不会对用户线程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户线程,当这一切都完成之后,内核会给用户线程发送一个信号,告诉它read操作完成了。也就说用户线程完全不需要关心实际的整个IO操作是如何进行的,只需要先发起一个请求,当接收内核返回的成功信号时表示IO操作已经完成,可以直接去使用数据了。
这二种我现实中没用到过,就不说了,引用了别人的观点,如果后面我用到了,我会把用到的补充上去。
6:Reactor模型
谈到网络模型,肯定撇不开reactor模型的,网络模型能够发扬光大,离不开reactor模型,他的地位举足轻重,下面说下几种不同演进的reactor的模式。
6.1:单Reactor单线程模型
/**
* 等待事件到来,分发事件处理
*/
class Reactor implements Runnable {
private Reactor() throws Exception {
SelectionKey sk =
serverSocket.register(selector,
SelectionKey.OP_ACCEPT);
// attach Acceptor 处理新连接
sk.attach(new Acceptor());
}
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
it.remove();
//分发事件处理
dispatch((SelectionKey) (it.next()));
}
}
} catch (IOException ex) {
//do something
}
}
void dispatch(SelectionKey k) {
// 若是连接事件获取是acceptor
// 若是IO读写事件获取是handler
Runnable runnable = (Runnable) (k.attachment());
if (runnable != null) {
runnable.run();
}
}
}
/**
* 连接事件就绪,处理连接事件
*/
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
new Handler(c, selector);
}
} catch (Exception e) {
}
}
}
/**
* 处理读写业务逻辑
*/
class Handler implements Runnable {
public static final int READING = 0, WRITING = 1;
int state;
final SocketChannel socket;
final SelectionKey sk;
public Handler(SocketChannel socket, Selector sl) throws Exception {
this.state = READING;
this.socket = socket;
sk = socket.register(selector, SelectionKey.OP_READ);
sk.attach(this);
socket.configureBlocking(false);
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == WRITING) {
write();
}
}
private void read() {
process();
//下一步处理写事件
sk.interestOps(SelectionKey.OP_WRITE);
this.state = WRITING;
}
private void write() {
process();
//下一步处理读事件
sk.interestOps(SelectionKey.OP_READ);
this.state = READING;
}
/**
* task 业务处理
*/
public void process() {
//do something
}
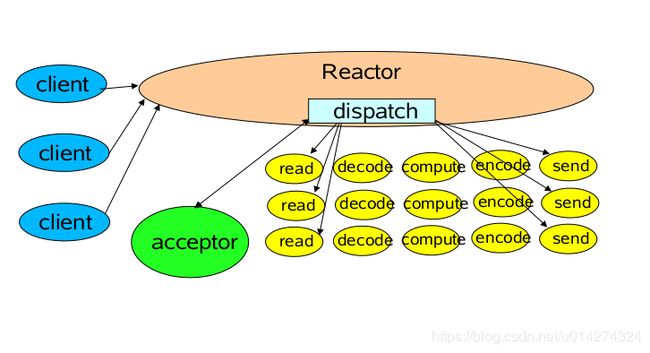
}这是最基本的单Reactor单线程模型。其中Reactor线程,负责多路分离套接字,有新连接到来触发connect 事件之后,交由Acceptor进行处理,有IO读写事件之后交给hanlder 处理。
Acceptor主要任务就是构建handler ,在获取到和client相关的SocketChannel之后 ,绑定到相应的hanlder上,对应的SocketChannel有读写事件之后,基于racotor 分发,hanlder就可以处理了(所有的IO事件都绑定到selector上,有Reactor分发)。
该模型 适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
6.2:单Reactor多线程模型
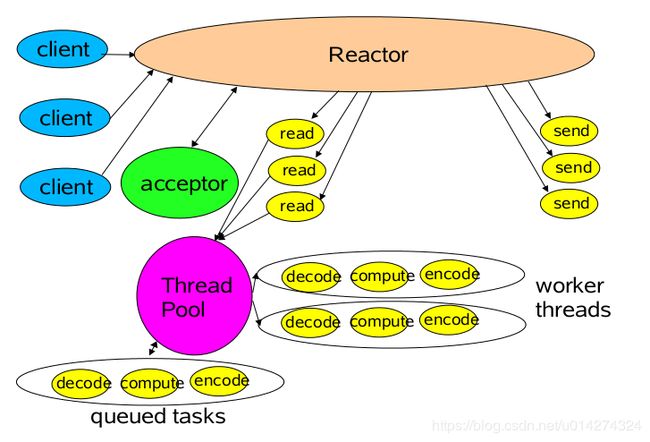
相对于第一种单线程的模式来说,在处理业务逻辑,也就是获取到IO的读写事件之后,交由线程池来处理,这样可以减小主reactor的性能开销,从而更专注的做事件分发工作了,从而提升整个应用的吞吐。我们看下实现方式:
/**
* 多线程处理读写业务逻辑
*/
class MultiThreadHandler implements Runnable {
public static final int READING = 0, WRITING = 1;
int state;
final SocketChannel socket;
final SelectionKey sk;
//多线程处理业务逻辑
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public MultiThreadHandler(SocketChannel socket, Selector sl) throws Exception {
this.state = READING;
this.socket = socket;
sk = socket.register(selector, SelectionKey.OP_READ);
sk.attach(this);
socket.configureBlocking(false);
}
@Override
public void run() {
if (state == READING) {
read();
} else if (state == WRITING) {
write();
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理写事件
sk.interestOps(SelectionKey.OP_WRITE);
this.state = WRITING;
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
//下一步处理读事件
sk.interestOps(SelectionKey.OP_READ);
this.state = READING;
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}6.3:多Reactor多线程模型
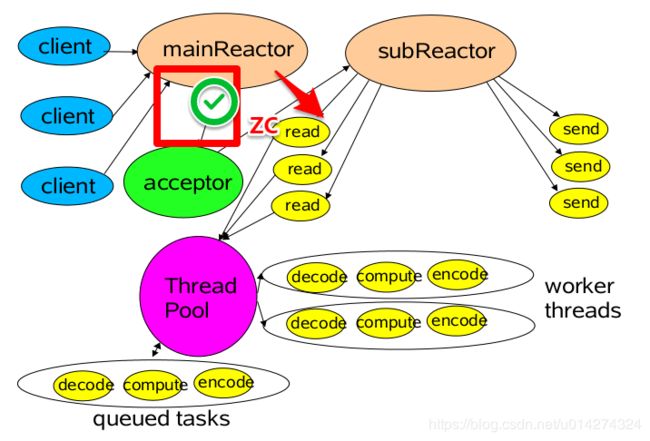
第三种模型比起第二种模型,是将Reactor分成两部分,
- mainReactor负责监听server socket,用来处理新连接的建立,将建立的socketChannel指定注册给subReactor。
- subReactor维护自己的selector, 基于mainReactor 注册的socketChannel多路分离IO读写事件,读写网 络数据,对业务处理的功能,另其扔给worker线程池来完成。
我们看下实现方式:
/**
* 多work 连接事件Acceptor,处理连接事件
*/
class MultiWorkThreadAcceptor implements Runnable {
// cpu线程数相同多work线程
int workCount =Runtime.getRuntime().availableProcessors();
SubReactor[] workThreadHandlers = new SubReactor[workCount];
volatile int nextHandler = 0;
public MultiWorkThreadAcceptor() {
this.init();
}
public void init() {
nextHandler = 0;
for (int i = 0; i < workThreadHandlers.length; i++) {
try {
workThreadHandlers[i] = new SubReactor();
} catch (Exception e) {
}
}
}
@Override
public void run() {
try {
SocketChannel c = serverSocket.accept();
if (c != null) {// 注册读写
synchronized (c) {
// 顺序获取SubReactor,然后注册channel
SubReactor work = workThreadHandlers[nextHandler];
work.registerChannel(c);
nextHandler++;
if (nextHandler >= workThreadHandlers.length) {
nextHandler = 0;
}
}
}
} catch (Exception e) {
}
}
}
/**
* 多work线程处理读写业务逻辑
*/
class SubReactor implements Runnable {
final Selector mySelector;
//多线程处理业务逻辑
int workCount =Runtime.getRuntime().availableProcessors();
ExecutorService executorService = Executors.newFixedThreadPool(workCount);
public SubReactor() throws Exception {
// 每个SubReactor 一个selector
this.mySelector = SelectorProvider.provider().openSelector();
}
/**
* 注册chanel
*
* @param sc
* @throws Exception
*/
public void registerChannel(SocketChannel sc) throws Exception {
sc.register(mySelector, SelectionKey.OP_READ | SelectionKey.OP_CONNECT);
}
@Override
public void run() {
while (true) {
try {
//每个SubReactor 自己做事件分派处理读写事件
selector.select();
Set keys = selector.selectedKeys();
Iterator iterator = keys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isReadable()) {
read();
} else if (key.isWritable()) {
write();
}
}
} catch (Exception e) {
}
}
}
private void read() {
//任务异步处理
executorService.submit(() -> process());
}
private void write() {
//任务异步处理
executorService.submit(() -> process());
}
/**
* task 业务处理
*/
public void process() {
//do IO ,task,queue something
}
}
第三种模型中,我们可以看到,mainReactor 主要是用来处理网络IO 连接建立操作,通常一个线程就可以处理,而subReactor主要做和建立起来的socket做数据交互和事件业务处理操作,它的个数上一般是和CPU个数等同,每个subReactor一个县城来处理。此种模型中,每个模块的工作更加专一,耦合度更低,性能和稳定性也大量的提升,支持的可并发客户端数量可达到上百万级别。
这些是我从别人那借过来的,让我写的话,我感觉也很难写这么出色,还是要说一下第三种的理论基础是:一个selector可以拥有很多channel,但是一个channel只能有一个selector,所以相当于是当第一个reactor收到accept请求,就把channel注册到第二个reactor上。
7:netty
netty就是依据多reactor多线程模型,父reactor注册SelectionKey.OP_ACCEPT事件,子reactor注册SelectionKey.OP_READ事件,reactor在netty中是什么?EventLoopGroup封装NioEventLoop,可以理解为EventLoopGroup就是reactor,这个也是netty里面最核心的东西,下面看下netty的基本使用代码:
int port = 6666;
//看做一个死循环,程序永远保持运行
EventLoopGroup bossGroup = new NioEventLoopGroup(1); //完成线程的接收,将连接发送给worker
EventLoopGroup workerGroup = new NioEventLoopGroup(); //完成连接的处理
try {
//对于相关启动信息进行封装
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap
.group(bossGroup, workerGroup) //注入两个group
.channel(NioServerSocketChannel.class)
.childHandler(new EchoServerHandler());
//绑定端口对端口进行监听,启动服务器
ChannelFuture channelFuture = serverBootstrap.bind("127.0.0.1", port).sync();
Thread.sleep(1000 * 1000);
channelFuture.channel().closeFuture().sync();
} finally {
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}parentReator就是bossGroup,入参是1,代表父reactor有1个selector,subReactor就是workerGroup,默认参数代表是NettyRuntime.availableProcessors() * 2,代表有cpu*2的selector,

8:netty3和netty4线程模型对比
netty3和netty4的线程模型发生了重大的改变,现在比较下他们的区别:
8.1:netty3.x线程模型

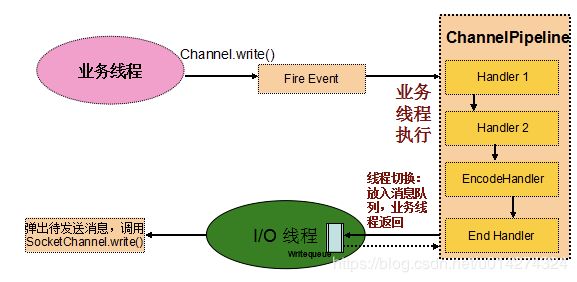
netty3的线程模型,图一(Inbound)的线程和图二(Outbound)的线程不是同一个,Inbound是I/O线程,Outbound是work线程,
Inbound操作的主要处理流程如下:
- I/O线程(Work线程)将消息从TCP缓冲区读取到SocketChannel的接收缓冲区中;
- 由I/O线程负责生成相应的事件,触发事件向上执行,调度到ChannelPipeline中;
- I/O线程调度执行ChannelPipeline中Handler链的对应方法,直到业务实现的Last Handler;
- Last Handler将消息封装成Runnable,放入到业务线程池中执行,I/O线程返回,继续读/写等I/O操作;
- 业务线程池从任务队列中弹出消息,并发执行业务逻辑。
Outbound操作的主要处理流程如下,业务线程发起Channel Write操作,发送消息;
- Netty将写操作封装成写事件,触发事件向下传播;
- 写事件被调度到ChannelPipeline中,由业务线程按照Handler Chain串行调用支持Downstream事件的Channel Handler;
- 执行到系统最后一个ChannelHandler,将编码后的消息Push到发送队列中,业务线程返回;
- Netty的I/O线程从发送消息队列中取出消息,调用SocketChannel的write方法进行消息发送。
8.2:netty4.x线程模型
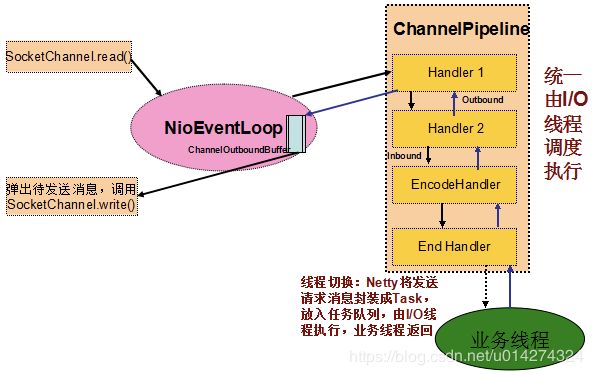
netty4的Inbound和Outbound都统一由I/O线程来执行,主要处理流程如下:
- I/O线程NioEventLoop从SocketChannel中读取数据报,将ByteBuf投递到ChannelPipeline,触发ChannelRead事件;
- I/O线程NioEventLoop调用ChannelHandler链,直到将消息投递到业务线程,然后I/O线程返回,继续后续的读写操作;
- 业务线程调用ChannelHandlerContext.write(Object msg)方法进行消息发送;
- 如果是由业务线程发起的写操作,ChannelHandlerInvoker将发送消息封装成Task,放入到I/O线程NioEventLoop的任务队列中,由NioEventLoop在循环中统一调度和执行。放入任务队列之后,业务线程返回;
- I/O线程NioEventLoop调用ChannelHandler链,进行消息发送,处理Outbound事件,直到将消息放入发送队列,然后唤醒Selector,进而执行写操作。
netty3和netty4各有好处,netty3如果我们有很复杂的handler处理,很耗时,编解码处理耗时,处理起来速度会快很多,netty4由于线程模型一致,我们的编程将不需要考虑线程切换的场景,复杂性降低,没有额外的上下文切换,性能也会好点,推荐netty4,会让程序少很多bug。netty还解决了臭名昭著的空轮训的bug,这个感兴趣的可以自己看下。
9:ByteBuffer之DirectBuffer

put
写模式下,往buffer里写一个字节,并把postion移动一位。写模式下,一般limit与capacity相等。
flip
写完数据,需要开始读的时候,将postion复位到0,并将limit设为当前postion。
get
从buffer里读一个字节,并把postion移动一位。上限是limit,即写入数据的最后位置。
clear
将position置为0,并不清除buffer内容。
mark & reset
mark相关的方法主要是mark()(标记)和reset()(回到标记).
上面是使用的api,ByteBuffer主要有三个:DirectByteBuffer,HeapByteBuffer,MappedByteBuffer:HeapByteBuffer是byte[],MappedByteBuffer和DirectByteBuffer同属于堆外内存,MappedByteBuffer对于4kb以下的小字节很快,DirectByteBuffer对4kb以上的优势明显,netty最重要的还是采用了DirectByteBuffer,省去了网卡->内核态->用户态的拷贝,变成网卡->用户态。
10:总结
这篇写的很轻松,大多数都是从别的人哪里借来的,加上了我自己的总结和理解。