Ring Buffers (环形消息缓冲区)
Ring Buffers
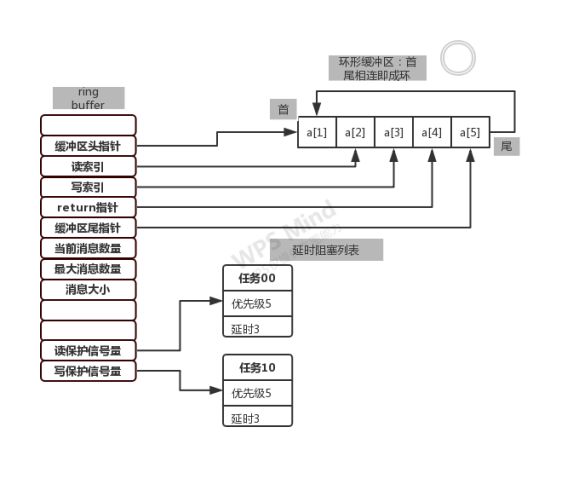
基本结构
即环形缓冲区:添加环形缓冲区是为了提供一种可以接受任意长度条目的缓冲区形式。 (内存管理) 是一种数据结构用于表示一个固定尺寸、头尾相连的缓冲区,适合缓存数据流。 内部除维护一个环形缓冲区外,还有两个二值信号量,用于读写保护:
1.发送保护信号量:二值信号量,通知被阻塞发送的任务有更多可用空间或阻塞已经超时。
2.接收保护信号量,二值信号量,通知被阻塞接收的任务指示新的数据/项已写入环形缓冲区或者阻塞超时。
为什么需要Ring Buffers
- 我们所实现的 Ring Buffer 与传统队列的区别是:buffer 里的对象不会被销毁-它们留在那儿直到下次被覆盖写入(普通队列提供可选的消耗/值拷贝的获取方式,是立即操作,即每次读取要么保留消息、要么立即删除消息),提供了可靠的消息传递特性(特别适合于通信双方循环发送数据的情况)。
- Ring Buffer 比链表要快,因为它是数组,而且有一个容易预测的访问模式。这很不错,对 CPU 高速缓存友好 (CPU-cache-friendly)-数据可以在硬件层面预加载到高速缓存,因此 CPU 不需要经常回到主内存 RAM 里去寻找 Ring Buffer 的下一条数据。
- Ring Buffer 是一个数组,你可以预先分配内存,并保持数组元素永远有效。这意味着内存垃圾收集(GC)在这种情况下几乎什么也不用做。此外,也不像链表那样每增加一条数据都要创建对象-当这些数据从链表里删除时,这些对象都要被清理掉。
- 队列通常关注于维护队列的头和尾,添加保护读取消息时的东西。所有这些东西我还没有在 Ring Buffer 一节真正提到。这是因为 Ring Buffer 本身并不负责这些事情,这些问题挪到了数据结构的外部。
- 圆形缓冲区的一个有用特性是:当一个数据元素被用掉后,其余数据元素不需要移动其存储位置。相反,一个非圆形缓冲区(例如一个普通的队列)在用掉一个数据元素后,其余数据元素需要向前搬移。换句话说,圆形缓冲区适合实现先进先出缓冲区,而非圆形缓冲区适合后进先出缓冲区。
- 圆形缓冲区适合于事先明确了缓冲区的最大容量的情形。扩展一个圆形缓冲区的容量,需要搬移其中的数据。因此一个缓冲区如果需要经常调整其容量,用链表实现更为合适。
- 写操作覆盖圆形缓冲区中未被处理的数据在某些情况下是允许的。特别是在多媒体处理时。例如,音频的生产者可以覆盖掉声卡尚未来得及处理的音频数据。
- 环形缓冲区(ring buffer),环形队列(ring queue) 多用于2个线程之间传递数据,是标准的先入先出(FIFO)模型。一般来说,对于多线程共享数据,需要使用mutex来同步,这样共享数据才不至于发生不可预测的修改/读取,然而,mutex的使用也带来了额外的系统开销,ring buffer/queue 的引入,就是为了有效地解决这个问题,因其特殊的结构及算法,可以用于2个线程中共享数据的同步,而且必须遵循1个线程push in,另一线程pull out的原则。
- ring buffer主要用于存储一段连续的数据块,例如网络接收的数据 .
- 环形缓冲区可以创建更优的队列,但它也有一个缺点:调整队列大小变得低效。但如果是一个固定大小的队列,那么ringbuffer将很适用。
分类(枚举类型)
由创建时xRingbufferCreate(size_t xBufferSize, RingbufferType_t xBufferType)的xBufferType参数决定创建的ringbuffer类型,其取值如下(枚举型):
RINGBUF_TYPE_NOSPLIT=0
No-split buffers(无拆分缓冲区) 将只在连续内存中存储一个项,而不会拆分一个项。每个条目需要8字节的头开销,并且始终在内部占用32位对齐的空间大小。 将保证将项存储在连续内存中,并且在任何情况下都不会尝试拆分项。当项目必须占用连续内存时,请使用 no-split buffers。只有这种缓冲区类型允许您自己获取数据项的地址并将数据写入该项。
RINGBUF_TYPE_ALLOWSPLIT=1
Allow-split buffers(可拆分缓冲区) 可以将项目拆分为两部分(如有必要),以便存储它。每一项都需要一个8字节的头开销,拆分会产生一个额外的头。每个项目在内部总是占据32位对齐大小的空间。
RINGBUF_TYPE_BYTEBUF=2
Byte buffers(字节型缓冲区) 可以将数据存储为字节序列,并且不维护单独的项,因此字节缓冲区没有开销。所有数据以字节序列的形式存储,每次可以发送或检索任意数量的字节。
操作
Creat/Delete(创建/删除 )
Send/Receive(发送/接收)
含中断版 有阻塞 (相关函数原型见ESP-IDF API)
Return(返回删除)
含中断版 无阻塞
与队列集相关的操作
操作示例:
\1. 向RingBuffer中发送数据
下面的图表说明了不拆分/允许拆分缓冲区和字节缓冲区在发送项目/数据方面的区别。图中假设大小为18、3和27字节的三个项目分别发送到128字节的缓冲区。

对于no split/allow split buffers,每个数据项前面都有一个8字节的头。此外,每个项目占用的空间被四舍五入到最接近的32位对齐大小,以保持总体32位对齐。但是,项目的真实大小记录在标题中,当检索到该项目时将返回该标题。
参考上图,18、3和27字节项分别取整为20、4和28字节。然后在每个项前面添加一个8字节的头。

字节缓冲区将数据视为一个字节序列,不会产生任何开销(没有头)。因此,发送到字节缓冲区的所有数据都被合并到一个项目中。
参考上图,18、3和27字节项按顺序写入字节缓冲区,并合并为48字节的单个项。
环绕
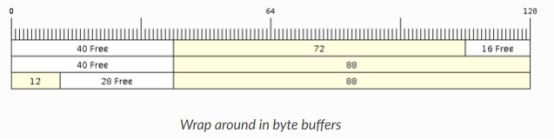
下图说明了当发送的项需要换行时,no split、allow split和byte buffers之间的区别。图中假设一个128字节的缓冲区,56字节的可用空间环绕,而发送的项目是28字节。

No split buffers将只在连续的可用空间中存储数据项,并且在任何情况下都不会拆分项。当缓冲区尾部的可用空间不足以完全存储项及其头时,尾部的可用空间将标记为虚拟数据。然后,缓冲区将环绕并将项目存储在缓冲区头部的可用空间中。
参考上图,缓冲区尾部16字节的可用空间不足以存储28字节的项。因此,16个字节被标记为伪数据,而将该项写入缓冲区头部的可用空间。

Allow split buffers:当缓冲区尾部的可用空间不足以存储项数据及其标头时,将尝试将项拆分为两部分。拆分项的两个部分都有自己的头(因此会产生额外的8字节开销)。
参考上图,缓冲区尾部16字节的可用空间不足以存储28字节的项。因此,该项被分成两部分(8和20字节),并作为两部分写入缓冲区。
注意:
Allow split buffers将分割项的两部分视为两个独立的项,因此调用xRingbufferReceiveSplit()而不是xRingbufferReceive()以线程安全的方式接收分割项的两个部分。
字节缓冲区会将尽可能多的数据存储到缓冲区尾部的可用空间中。剩下的数据将存储在缓冲区头部的空闲空间中。在字节缓冲区中包装时不会产生开销。
参考上图,缓冲区尾部的16个字节的可用空间不足以完全存储28个字节的数据。因此,16个字节的空闲空间被数据填充,剩下的12个字节被写入缓冲区头部的空闲空间。缓冲区现在在两个独立的连续部分中包含数据,并且每个连续部分都将被字节缓冲区视为一个单独的项。
\2.检索/返回:
下图说明了在检索和返回数据时不拆分/允许拆分和字节缓冲区之间的区别。

no split/allow split buffers中的项将按严格的FIFO顺序检索,必须返回以释放占用的空间。可以在返回之前检索多个项目,并且不必按照检索顺序返回这些项目。然而,空间的释放必须以FIFO顺序进行,因此不返回最早检索到的项将阻止后续项的空间被释放。 参考上图,16、20和8字节项按FIFO顺序检索。但是,在检索到的项目(20、8、16)中,不会返回这些项目。因此,在返回第一个项(16字节)之前,不会释放空间。(算是一种保护把)

字节缓冲区不允许在返回之前进行多次检索(每次检索后必须先返回一次,然后才允许进行另一次检索)。使用xRingbufferReceive()或xRingbufferReceiveFromISR()时,将检索所有连续存储的数据。xRingbufferReceiveUpTo()或xRingbufferReceiveUpToFromISR()可用于限制检索的最大字节数。因为每次检索后都必须有一个返回,所以一旦返回数据,空间就会被释放。
参考上面的图表,检索、返回和释放缓冲区尾部38字节的连续存储数据。下一次调用xRingbufferReceive()或xRingbufferReceiveFromISR()将对缓冲区头部连续存储的30个字节的数据执行同样的操作。
\3. 带队列集的环形缓冲区
可以使用xRingbufferAddToQueueSetRead()将环形缓冲区添加到FreeRTOS队列集中,这样每当环形缓冲区接收到项目或数据时,都会通知队列集。一旦添加到队列集中,每次尝试从环形缓冲区检索项目时,都应该先调用xQueueSelectFromSet()。要检查所选队列集成员是否为环形缓冲区,请调用xRingbufferCanRead()。
适用场合与建议
注意:
理想情况下,ringbufer可以在SMP(Symmetrical Multi-Processing,对称多处理架构)中,实现多个任务一起使用,其中优先级最高的任务总是首先得到服务。然而,由于在环形缓冲区的底层实现中使用了二进制信号量,在非常特殊的情况下可能会发生优先级反转。
环形缓冲区控制二进制信号量的发送,该信号量在环形缓冲区上释放空间时给出。等待发送的最高优先级任务将重复使用信号量,直到有足够的空闲空间可用或超时为止。理想情况下,这应该防止任何低优先级的任务被服务,因为信号量应该总是给最高优先级的任务。 然而,在获取信号量的两次迭代之间,关键部分有一个间隙,这可能允许另一个任务(在另一个核心上或具有更高优先级的任务)在环形缓冲区上释放一些空间,从而给出信号量。因此,在最高优先级的任务可以重新获取信号量之前,将给出信号量。这将导致等待发送的第二高优先级任务获取信号量,从而导致优先级反转。
如果同时使用环形缓冲区的任务数很低,并且环形缓冲区没有在最大容量附近运行,那么这种副作用不会显著影响环缓冲区的性能。
环形缓冲区官方翻译(ESP-IDF)
ESP-IDF FreeRTOS环形缓冲区是一个严格的FIFO缓冲区,支持任意大小的项目。在项目大小可变的情况下,环形缓冲区是比FreeRTOS队列更节省内存的方法。环形缓冲区的容量不是由它可以存储的存储项(可以认为是个消息)的个数来衡量的,而是由存储项的实际所占空间来衡量的。您可以在环形缓冲区上申请一块内存来发送一个项目,或者使用API复制数据并发送(根据您调用的SendAPI)。为了提高效率,总是通过值传递的方式从环形缓冲区中检索项(即Receive操作,获取消息的值)。因此,若想将存储项在环形缓冲区中完全删除,还必须返回所有检索到的项(即执行Return操作),以便将它们从环形缓冲区中完全删除。环形缓冲器分为以下三种类型:
No-Split buffers(禁止拆分型buffer)不能保证项目存储在连续内存中,并且在任何情况下都不会尝试拆分项目。当项目必须占用连续内存时,不要使用这种缓冲区。当项目必须占用连续内存时请使用这种ringbuffer。
Allow split buffers,即允许拆分缓冲区将允许在存储数据项时拆分项目,如果这样做能够允许存储该项目。“允许拆分缓冲区”比“不拆分缓冲区”更节省内存,但在检索时需分两部分返回完整的原项目。
Byte buffer不将数据存储为单独的项。所有数据都以字节序列的形式存储,并且每次发送或检索任意数量的字节。当不需要维护单独的项目(例如字节流)时,使用字节缓冲区。
注意:
No split/allow split buffers将始终以32位对齐的地址存储项。因此,在检索项时,保证项指针是32位对齐的。这是非常重要的,尤其是当您需要向DMA发送一些数据时。
存储在no split/allow split buffers中的每个项将需要额外的8个字节作为标头。项目大小也将四舍五入到32位对齐大小(4个字节的倍数),但是真正的项目大小记录在标头中。创建时,no split/allow split buffers的大小也将向上取整。