AbstractList,AbstractSequentialList
AbstractList
看图说话

AbstractList继承了AbstractCollection实例化List接口,从AbstractCollection的基础上又特化了一层,把集合特化成列表或者可以叫做线性表的一个基类。是一个 亦叔易爷 的基类,为什么这么讲,AbstractList有两个特化出的线性表,一个是直接继承关系ArrayList,另一个是隔代继承关系LinkedList。
AbstractList - 有啥没啥
无非就是增删改查及其变种的方法,我们把抽象方法和非抽象方法分出来。
抽象方法只有一个:
abstract public E get(int index);//get获取固定位置上的元素,如果是数组的线性表那么定位下标即可,如果是链表迭代才行,这里就没具体规定非抽象方法有很多:
在AbstractCollection的基础上,伪实现了 add方法,为什么这样讲,我们看代码。
public boolean add(E e) { //貌似实现了,却又去调用了,重载的方法。我们看一下重载方法。
add(size(), e);
return true;
}
public void add(int index, E element) { //表现来看,还是没有具体实现add方法,因为他还是不确定线性表的数据结构
throw new UnsupportedOperationException();
}
因为不确定具体数据结构,也是因为抽象出线性表的概念和操作而不具体去实现它,所以 “伪”实现一些方法。
那么我们还有多少类似” 伪“实现需要子类自己重写的方法呢?
1. set方法,
public E set(int index, E element) {
throw new UnsupportedOperationException();
}2.remove方法
public E remove(int index) {
throw new UnsupportedOperationException();
}其他已经实现的非抽象方法:
1.indexOf(Object o) //基于迭代器查询线性表这个元素第一个出现的位置
public int indexOf(Object o) { //线性表正向遍历
ListIterator it = listIterator();
if (o==null) {
while (it.hasNext())
if (it.next()==null)
return it.previousIndex();
} else {
while (it.hasNext())
if (o.equals(it.next()))
return it.previousIndex();
}
return -1;
} 2. lastIndexOf(Object o) //基于迭代器查询线性表这个元素最后一个出现的位置
public int lastIndexOf(Object o) { //线性表反向遍历
ListIterator it = listIterator(size());
if (o==null) {
while (it.hasPrevious())
if (it.previous()==null)
return it.nextIndex();
} else {
while (it.hasPrevious())
if (o.equals(it.previous()))
return it.nextIndex();
}
return -1;
} 3. clear 清除集合内的元素
public void clear() {
removeRange(0, size());
}
protected void removeRange(int fromIndex, int toIndex) {
ListIterator it = listIterator(fromIndex);
for (int i=0, n=toIndex-fromIndex; i 4.rangeCheckForAdd(int index)
private void rangeCheckForAdd(int index) { //添加元素的位置是否在 [0,size]这个闭区间内
if (index < 0 || index > size())
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
5.addAll 如果不实现add(index,e)这个方法也不能用
public boolean addAll(int index, Collection c) {
rangeCheckForAdd(index);
boolean modified = false;
for (E e : c) {
add(index++, e);
modified = true;
}
return modified;
}
关于重写HashCode和equals方法
直接上代码来看:
public boolean equals(Object o) { if (o == this) //如果o为当前集合返回true return true; // 判断是否是List列表,只要实现了List接口就是List列表 if (!(o instanceof List)) return false; ListIterator// 判断是否是List列表,只要实现了List接口就是List列表 if (!(o instanceof List)) return false; ListIteratore1 = listIterator();//获取当前的集合的迭代器 ListIterator e2 = ((List) o).listIterator();//获取待比较集合的迭代器 while (e1.hasNext() && e2.hasNext()) {//都有下一个元素就遍历 E o1 = e1.next(); Object o2 = e2.next(); if (!(o1==null ? o2==null : o1.equals(o2))) //如果o1为空就看o2是否为空,o2为空的话继续往下比较 return false; //如果o1不为空,就让o1调用自己的equals或者时重写的equals和o2比较 } return !(e1.hasNext() || e2.hasNext()); //如果比较完后但凡有一个迭代器还有值就返回false都没有下一个值返回true } public int hashCode() { //为什么要重写hashCode int hashCode = 1; for (E e : this) hashCode = 31*hashCode + (e==null ? 0 : e.hashCode()); return hashCode; } e1 = listIterator();//获取当前的集合的迭代器 ListIterator e2 = ((List) o).listIterator();//获取待比较集合的迭代器 while (e1.hasNext() && e2.hasNext()) {//都有下一个元素就遍历 E o1 = e1.next(); Object o2 = e2.next(); if (!(o1==null ? o2==null : o1.equals(o2))) //如果o1为空就看o2是否为空,o2为空的话继续往下比较 return false; //如果o1不为空,就让o1调用自己的equals或者时重写的equals和o2比较 } return !(e1.hasNext() || e2.hasNext()); //如果比较完后但凡有一个迭代器还有值就返回false都没有下一个值返回true } public int hashCode() { //为什么要重写hashCode int hashCode = 1; for (E e : this) hashCode = 31*hashCode + (e==null ? 0 : e.hashCode()); return hashCode; }
为什么重写equals就必须重写hashCode
首先我们要从根源来看,也就是Object类源码,源码中equals和hashCode方法是这样定义的。Object类中的hashCode()方法,用native关键字修饰,说明这个方法是一个原生态方法,也就说这个方法的实现不是用java语言实现的,是使用c/c++实现的,并且被编译成了DLL,由java去调用,jdk源码中不包含。对于不同的平台它们是不同的,java在不同的操作系统中调用不同的native方法实现对操作系统的访问,因为java语言不能直接访问操作系统底层。
重写hashCode方法需要注意的地方:
1.在java应用程序运行时,无论多次调用同一个对象的hashCode方法,这个对象的hashCode方法都必须返回的是相同的int值。
2.如果两个对象的equals返回值为true,那么他们的hashCode必须返回相同的int值
3.如果两个对象的equals返回值为false,那么他们的hashCode返回值一定不相同
那么为什么要重写这两个方法呢,因为我们根据需求,两个不同对象的值相同我们需要认为他们是相同的,所以要重写equals方法,但是他们返回的hashCode不同我们就需要重写HashCode方法让他们返回同一个值。所以java很多的包装类都重写了这两个方法。
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
那么我们什么条件下需要重写这两个方法呢?
我们要把自己定义的类,放入集合中就必须重写这两个方法,因为就比如HashSet,因为我们没有重写这两个方法,我们先放入了一个自定义对象,然后又放入一个和这个自定义对象值相等但是不是同一个对象的对象。这是发现它是可以放进去的,因为他们两个的HashCode值不同,意味着这两个对象不是同一个对象,所以这与HashSet的概念是相违背的。我们要重写这两个方法,这也是一个良好的编程习惯。至于怎么重写,那么相等的值返回相等的int值,这个算法应该不会很难设计。
关于迭代器AbstractList实现了Iterator和ListIterator
首先来看Iterator迭代器,AbstractList定义了一个内部类,内部类实现了Iterator的接口,并实现了Iterator接口种的全部方法,
private class Itr implements Iterator {
int cursor = 0;
int lastRet = -1;
int expectedModCount = modCount; //如果在使用迭代器时,那个创造迭代器的集合被修改了,就会抛出异常这阈值时用来判断集合是否被修改的
public boolean hasNext()
public E next() // ----》 next中调用了,外部类的get方法 E next = get(i);
public void remove() // 外部类如果没有实现get则不能使用iterator的next方法迭代
final void checkForComodification() 我们调用外部类的iterator方法,会得到一个Itr的对象去操作集合,迭代集合。
public Iterator iterator() {
return new Itr();
} 辣么ListIterator是怎么实现的,我们来看源码,首先它继承了Itr类实例化ListIterator接口,它拥有了Itr的全部属性和方法,继承了ListIterator的一些方法,可以双向遍历,并且 请看下面代码红色部分,他是可以真正去修改集合内元素的值 , 改变集合的结构。
private class ListItr extends Itr implements ListIterator {
//下面这些方法都是实现好的,不过目前我们不需要关注具体的实现方式,看看都有些什么
ListItr(int index) {
cursor = index;
}
public boolean hasPrevious() { //前面有没有元素
。。。 。。。
}
public E previous() { //返回前面元素
。。。 。。。
}
public int nextIndex() { //下个元素的下标
return cursor;
}
public int previousIndex() { //上个元素的下标
return cursor-1;
}
public void set(E e) { //修改元素 e 的值
。。。 。。。
try {
AbstractList.this.set(lastRet, e);
。。。 。。。
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) { //添加一个元素值
try {
。。。 。。。
AbstractList.this.add(i, e);
。。。 。。。
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
} AbstractList.this.set(lastRet, e);
。。。 。。。
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) { //添加一个元素值
try {
。。。 。。。
AbstractList.this.add(i, e);
。。。 。。。
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}测试双向迭代器,看图说话。
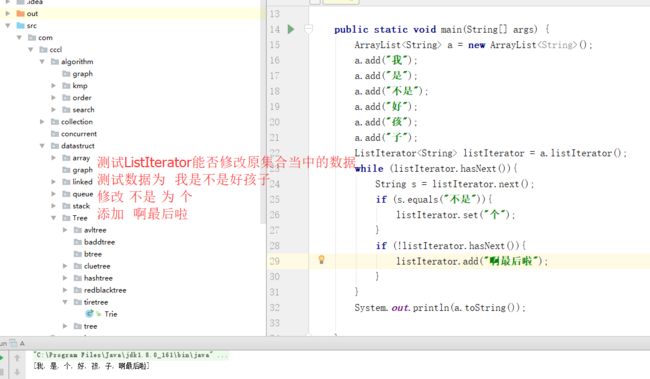
显然我们使用listIterator删除了 “不是”,添加了“啊最后啦”,结果和我们预期的是一样的,集合内容被修改了。
AbstractList中的SubList
逐本溯源,我们看AbstractList是怎么调用subList方法的,看下面代码的红色关键部分。
public List subList(int fromIndex, int toIndex) {
return (this instanceof RandomAccess ?
new RandomAccessSubList<>(this, fromIndex, toIndex) :
new SubList<>( this , fromIndex, toIndex)); //这里他把原集合的this传入了SubList的构造器里
} this , fromIndex, toIndex)); //这里他把原集合的this传入了SubList的构造器里
} 我们看一看SubList类是怎么做的,主要看一下构造器,这个list引用现在就是我们原 集合,它把自己的属性域”AbstractList
class SubListAbstractListextends AbstractList { private final AbstractList l; private final int offset; private int size; SubList(AbstractListlist , int fromIndex, int toIndex) { //原来的集合this值给了list引用 if (fromIndex < 0) throw new IndexOutOfBoundsException("fromIndex = " + fromIndex); if (toIndex > list.size()) throw new IndexOutOfBoundsException("toIndex = " + toIndex); if (fromIndex > toIndex) throw new IllegalArgumentException("fromIndex(" + fromIndex + ") > toIndex(" + toIndex + ")"); l = list; //l为原来的集合, offset和size就是我们规定的界限的视图 offset = fromIndex; size = toIndex - fromIndex; this.modCount = l.modCount; } //下面还有对这个 l 视图进行操作的方法。set add get remove 。。。等等一系列的方法 public E set(int index, E element) 。。。 。。。 。。。 。。。 。。。 。。。 不一一复制了l; private final int offset; private int size; SubList(AbstractListlist , int fromIndex, int toIndex) { //原来的集合this值给了list引用 if (fromIndex < 0) throw new IndexOutOfBoundsException("fromIndex = " + fromIndex); if (toIndex > list.size()) throw new IndexOutOfBoundsException("toIndex = " + toIndex); if (fromIndex > toIndex) throw new IllegalArgumentException("fromIndex(" + fromIndex + ") > toIndex(" + toIndex + ")"); l = list; //l为原来的集合, offset和size就是我们规定的界限的视图 offset = fromIndex; size = toIndex - fromIndex; this.modCount = l.modCount; } //下面还有对这个 l 视图进行操作的方法。set add get remove 。。。等等一系列的方法 public E set(int index, E element) 。。。 。。。 。。。 。。。 。。。 。。。 不一一复制了
测试一下subList方法是否能改变原来的集合:
//测试代码
ArrayList a = new ArrayList();
a.add("我");
a.add("是");
a.add("不是");
a.add("好");
a.add("孩");
a.add("子");
System.out.println("查看 初始化后的list: " + a.toString());
List list = a.subList(1,4);
System.out.println("查看 截取的list视图: " + list.toString());
System.out.println("在视图上添加一个元素: 一支穿云箭!嗖~ " + list.add("一支穿云箭!嗖~"));
System.out.println("查看 视图的结构: " + list.toString());
System.out.println("查看 原list是否改变: " + a.toString()); 
显然SubList能改变原集合的值,所以我们在使用时要慎重,如果不想改变原集合的值,那么我们就要把这个subList保存到另一个集合中使用它。
List list = new ArrayList<>(a.subList(1,4)); AbstractList还有一个类叫做RandomAccessSubList,继承了SubList,实现了RandomAccess接口,实现这个接口其目的也就是为了能在执行Collections下的binarySearch中调用indexedBinarySearch方法,如果没有实现RandomAccess就只能调用iteratorBinarySearch方法。两种方法的速度是不一样的。
public static int binarySearch(List> list, T key) {
if (list instanceof RandomAccess || list.size() AbstracSequentialtList
AbstractSequentialList继承了AbstractList,它是一个基于迭代器的抽象类,它只实现了最基本的增删改查方法,其中的所有的方法都需要根据迭代器来实现。能看出如果继承这个类,那么一定是和链表相关的类,如果是数组的话,也不能用效率这么低的Iterator来实现增删改查。
作为LinkedList的父类,它的基本实现给予了LinkedList一个很好的发挥空间。那么我们来看看AbstractSequentialList都有哪些方法。
抽象方法:
public abstract ListIterator listIterator(int index); AbstractSequentialList只有一个抽象方法,那就是listIterator,而它的iterator方法返回的是一个ListIterator对象。也就是说LinkedList就是基于ListIterator这个双向迭代器来实现的。这里我们回顾一下,双向迭代器是可以修改原集合中的内容的。
非抽象方法:
1.get方法,通过双向迭代器返回集合中元素
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}2.set方法 通过迭代器设置集合中的元素
public E set(int index, E element) {
try {
ListIterator e = listIterator(index);
E oldVal = e.next();
e.set(element);
return oldVal;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
} 3.add方法 通过迭代器添加一个元素
public void add(int index, E element) {
try {
listIterator(index).add(element);
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}4.remove方法 通过迭代器将固定位置的元素拿到集合外面
public E remove(int index) {
try {
ListIterator e = listIterator(index);
E outCast = e.next();
e.remove();
return outCast;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
} 5.addAll方法 通过迭代器在固定位置添加一个集合的元素
public boolean addAll(int index, Collection c) {
try {
boolean modified = false;
ListIterator e1 = listIterator(index);
Iterator e2 = c.iterator(); //展现了iterator的优点 凡是实现iterator 的集合都可以在这里进行插入
while (e2.hasNext()) {
e1.add(e2.next());
modified = true;
}
return modified;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
} 6.Iterator方法 返回的是一个listIterator对象
public Iterator iterator() {
return listIterator();
}
AbstractSequentialList总结
AbstractSequentialList可以这么讲,他是一个按次序访问的线性表的简化版,它是一个超类,他规定了其子类必须去实现ListIterator这个接口。必须用迭代的方式完成对线性表的各项操作。当我们在使用AbstractSequentialList的子类对象时,遍历操作最好是使用迭代器,因为for循环的get也是使用迭代器所以我们不要多此一举再去增加个for循环调用迭代方法了。
总结:
AbstractList,AbstractSequentialList基本上内容也就是这些,至于为什么这么设计,以我浅显的修为来看,其实如果直接从AbstractList延伸出ArrayList和LinkedList也未尝不可。但是既然这么设计了,我觉得它的好处可能是在于AbstractList支持RandomAccess,而我们的链表实现的线性表跟这种随机访问根本不搭边,不如再次由AbstractList特化出一个只针对于链表的超类,这样在定义LinkedList就有一个绝对的定位,它就是一个纯次序访问的链表集合,不允许有歧义和瑕疵。
这样层次分明,定位清楚,不但是开发方便,我们使用理解起来也比较方便。