Customizing Clos network-on-chip for neural networks
Customizing Clos network-on-chip for neural networks – paper reading
【motivation】
神经网络可以在软件(GPU)或者定制的硬件上实现。 特别的,硬件实现对于NN的发展很关键,因为它能支持快速实时的信号处理。本文主要探讨如何在硬件上实现NN (fully-connected feedforward NN)。
NN的计算模式主要有两种1)broadcast; 2)multicast. 即每个neuron的输出都需要传输给下一层所有的节点 (当我们同时实现几个NN时,只传送给部分节点)。
NN中每个neuron之间的沟通可以想象成packet switching,而且packet一般都比较小: 仅包含neuron的输出(16bits fixed point), destination address and a sequence number.
相比于computation, neurons (放置在processing unit里用于计算weight等) 之间的 data movement 会消耗更多的 energy (and sometimes more time). 因此本文主要考虑neurons之间的通信问题.
早期NN的硬件实现主要使用shared bus topology,虽然简单便宜但是low scalability。所以现在广泛的已经被NoC取代。其中,最popular的NoC topology是Mesh:所有的node按照grid排列,每个node仅和它各个方向上的邻居相连(方便wiring和implementation).
Mesh结构的缺点也很明显,node之前通信的hop太长latency太大,特别是large size的时候。还有就是NN中typical的broadcast/multicast数据并不fit mesh topology。实验表示90%unicast+10%broadcast就会把mesh network的performance降低三倍。也有人尝试mesh+collective communication (collective communication指的就是broadcast和multicast),在有一部分multicast traffic的时候确实是可以work,但是对于全部是multicast traffic的NN,更好的solution是tailor一种先天就支持multicast traffic的topology。基于此,本文设计了ClosNN.
【关于baseline Clos nets】
Clos topology是一种multi-stage interconnection networks (MINs). MINs主要是为了取代crossbar switch而提出的。Clos的特点是low diameter,simple routing, adaptable bisection bandwidth, capability of collective communication.
Baseline Clos topology

Baseline Clos network有三个stage的crossbar switch。我们可以用一个triple ( m , n , r ) (m,n,r) (m,n,r)来表示。
stage 1: r r r crossbars, each of size n × m n\times m n×m;
stage 2: m m m crossbars, each of size r × r r\times r r×r;
stage 3: r r r crossbars, each of size m × n m\times n m×n.
其中,中间stage的数目 m m m是最重要的参数,因为对每一个输入输出pair,总共的路径数就是 m m m. m m m越大,整个模型也就有更多的path diversity/routing flexibility/bisection width.
这里需要注意的是,传统Clos是用在circuit switching里的,也就是说non-blocking property是大家关注的重点。
Strictly non-blocking: m ≥ min { 2 n − 1 , n r } m\geq \min\{2n-1, nr\} m≥min{2n−1,nr};
Rearrangeably non-blocking: m ≥ n m\geq n m≥n.
但是我们这里考虑的是packet switching network,non-blocking已经不是我们的重点了,我们重点应该在于每个switch里如何buffering和arbitration从而恰当的让所有packet共享network bandwidth.
【ClosNN】
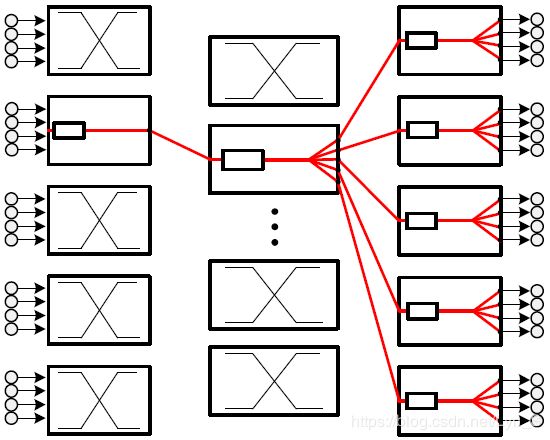
如上图所示, 我们考虑NN两个相邻层的通信问题: 所有的neurons都存放在processing elements (PE) 上, 中间有一个interconnection network把他们相连. Weights也都存储在PE上. 当然一般PE数量要小于neurons数量,因此允许一个PE上放多个neurons.
中间通信网络中的每个switch的内部结构如下:

packets → \rightarrow → N buffer → \rightarrow → head packets → \rightarrow → route computation → \rightarrow → output ports → \rightarrow → arbiter unit → \rightarrow → grant signal → \rightarrow → transmission
因为有多个输入多个输入, 因此它主要的功能就是把input按照需求map到输出port. 对于每一个input port, 都有一个buffer用来存储接收的packets. 其中buffer头部的packets会把routing request给routing unit计算他应该去往的output port (如果是multicast request, 可以是多个ports). 紧接着这一信息就给了arbiter unit 等待transmission grant的到来 (may received immediately or after some time due to collision).
让我们重新回到这个图,完整的routing过程如下:
- input-stage routing input switch要决定把input的packet送去哪一个outport (也就是middle stage). 这个routing的准则是最小化 middle-stage switch处的queueing delay, 从而使得network load 均衡的分布在所有的middle-stage switches. 因此, 每个input-stage switch总是选择buffer最空的那个middle-stage switch (注意每个input-stage switch只能access M个middle-stage switch的buffer, 1 buffer/middle-stage switch).
作者claim得知各个中间switch的queue长度没有任何overhead, 因为这个信息已经credit-based flow control unit.
这个stage takes one clock cycle. 而且接下来的middle-stage 或者third-stage 都不需要再route, 因为只有唯一的path了. - input-stage arbitration arbiter 使用round-robin的方式对每个queue的packet发grant.
这个stage takes one clock cycle. - middle and output-stage multicast/broadcast 这里就不用routing了,就直接arbitration consume 1 clock cycle. broadcast的话switch就直接broadcast到每一个port (如上图所示). multicast的话只用多加一个bit vector指示往哪里走就行.