【Java源码分析】Java8的ArrayList源码分析
Java8的ArrayList源码分析
-
源码分析
- ArrayList类的定义
- 字段属性
- 构造函数
- trimToSize()函数
- Capacity容量相关的函数,比如扩容
- List大小和是否为空
- contain()函数
- indexOf()、lastIndexOf()函数
- clone()方法
- toArray()函数
- get、set、add、remove、clear函数
- xxxxAll()类函数
- writeObject()、readObject()函数
- 返回Iterator对象函数
- subList()、subListRangeCheck()函数
- foreach()函数
- spliterator()函数
- removeIf()函数
- replaceAll()函数
- sort()函数
-
内部类分析
- 内部类Itr类
- 内部类ListItr
- 内部类SubList
- 静态内部类ArrayListSpliterator类
-
一些问题
重点关注
- ArrayList集合实现了
RandomAccess,Cloneable,Serializable接口,支持快速随机访问,克隆,虚拟化等功能 - ArrayList的特性:随机访问效率高;读/更新快;删/插慢; 实际上的数组移动是依赖native的
system.arraycopy方法,实际效率其实还是挺高的 Object[] elementData是ArrayList集合实际的底层数据结构,即一个Object类型的数组trimToSize()方法可以在内存吃紧的时候使用,释放掉当前集合还未使用的剩余空间; 实际上就是将底层数据结构elementData的数组裁剪到刚好的使用容量;- ArrayList集合的初始容量是10,扩容因子是1.5倍,通过向位运算(原大小+ 右移1位的结果)实现
- ArrayList的第一次扩容,即仅是new出来,且没有赋予初始大小时的ArrayList,此时的集合容量大小为0,只有第一次使用
- ArrayList扩容相关方法有5个,只有一个是公有的,其余四个都是私有的;公有的
ensureCapacity方法可以做到当我们不知道具体的集合需要多大时,传入我们大致需要的数据大小,让集合自行扩容到合适的大小; - 具体扩容情况,可以看最下面的相关问题,核心扩容方法是
grow()
源码分析
1 - ArrayList类的定义
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
结论:
- ArrayList是一个泛型类
- ArrayList类继承于
AbstractLsit抽象类且实现了List、RandomAccess、Cloneable、java.io.Serializable四个接口 - 我们可以看到
RandomAccess其实是一个毫无内容的接口,所以根据注释,我们得知这是一个标记接口,用于标明实现该接口的List支持快速随机访问,主要目的是使算法能够在随机和顺序访问的list中表现的更加高效。 - 实现了
Cloneable接口,这也是一个标记接口,说明实现该接口的类可以通过Clone来构建新对象 - 实现了
java.io.Serializable,代表该类可以序列化
2 - 字段属性
private static final long serialVersionUID = 8683452581122892189L; //序列化ID
private static final int DEFAULT_CAPACITY = 10; //ArrayList的起始大小容量
private static final Object[] EMPTY_ELEMENTDATA = {}; //空的数组对象
//空数组对象,当调用无参数构造函数的时候默认给个空数组对象
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//transient 代表这个属性不参与序列化
//elementData是一个Object数组,这是ArrayList的本质,既底层结构是一个Object数组
transient Object[] elementData; // non-private to simplify nested class access
private int size; //ArrayList的当前大小
结论:
Object[] EMPTY_ELEMENTDATA = {}等同于Object[] EMPTY_ELEMENTDATA = new Object[0]- elementData是ArrayList数据的本质,既ArrayList的底层数据结构是一个Object数组对象,数据都是存储在Object对象中
- 所以这里要区别两个大小概念,一个是Object数组的大小,也即是ArrayList的最大容量,另一个就是size属性,这个指的是数组中有用元素的个数,既插入ArrayList元素的个数
3 - 构造函数
/**
* ArrayList有参构造函数,参数为ArrayList的容量
* 作用就是实例化initialCapacity大小的Object数组对象,既程序员的需求定义ArrayList的容量大小
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) { //容量值大于0,既实例化数组对象
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) { //如果等于0,则把EMPTY_ELEMENTDATA赋值
this.elementData = EMPTY_ELEMENTDATA;
} else { //其他情况,说明传入的initialCapacity有问题
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* ArrayList无参构造函数
* 作用就是给底层数据结构赋予默认空数组
* 此时的ArrayList容量大小和size都是0,直到执行了其他方法,才会进行扩容,变为默认大小10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; //把默认的空数组传入
}
/**
* ArrayList的有参构造函数
* 参数是一个Collection的泛型实现类,是一个上界通配符类型,可get,不可set
* 作用就是将其他集合类型构成成一个ArrayList对象,比如将Set构建成ArrayList
* 例子:ArrayList list = new ArrayList<>(new HashSet());
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray(); //将集合对象转换为数组对象,并赋值给elementData,浅拷贝,底层会关联
if ((size = elementData.length) != 0) { //如果ArrayList的元素个数等于集合的元素个数,且不等于0
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class) //则判断集合元素的类型是否是一个Object类
//不是则将集合的元素深拷贝成一个新的数组对象,再赋值到elementData
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else { //如果等于0,既集合中没有元素,则通过默认空数组来构建
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
结论:
- ArrayList有三个构造函数,第一个是根据提供的初始容量来实例化,一个是无参实例化,还有一个是根据其他集合对象来实例化
- 一个容量为initialCapacity,一个为0,一个为传入集合对象的size
- 重点介绍根据其他结合对象来实例化,elementData = c.toArray()是一个浅拷贝动作,既ArrayList的elementData数组会跟传入的集合的底层数组结构耦合在一起,其实就是同一个对象。所以后面才需要使用Arrays.copyOf来重写构建一个数组对象再赋值给elementData,这里称为深拷贝。但要清除的是Arrays.copy方法仅仅是把外部的躯壳换了一个,其里面的内容的引用依然是跟之前是一样。所以在一定的程度上,这仅仅算是一定意义的深拷贝,比较内部元素依然是一样的,只是躯壳换成另一个对象。
4 - trimToSize()函数
/**
* trimToSize是一个在内存吃紧时候的方法
* 作用就是容量大于元素个数的时候,将剩余的空间释放掉,让容量等于元素个数size
* 比如此时的容量为15,而size等于12.使用了该方法,容量就变成跟size一样大小的12
* 原理就是截取底层Object数组对象子数组,构成一个新的Object数组
*/
public void trimToSize() {
modCount++; //modCount是一个用于记录该List修改次数的变量,这里不讨论
if (size < elementData.length) { //当元素个数size小于容量大小
//如果size = 0,则elementData等于空数组
//如果不是则截取elementData的size个长度,重新赋值给elementData
elementData = (size == 0) //三元运算符
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
5 - Capacity容量相关的函数,比如扩容
/**
* 公有扩容函数 | 判断是否扩容的前置函数 | 外部调用
* 作用:就是让集合自行扩容到可以存储minCapacity大小数据的容量,传入当前集合
* 目前需要接收到的数据的容量值,根据这个参数来判断是否需要扩容,需要扩容到多大
* 意义: 有时候我们不知道集合需要多大的容量,就传入我需要的容量大小,
* 让集合自己判断需要扩容成什么样子
* 对比: 外部版本的ensureCapacityInternal方法
*
*/
public void ensureCapacity(int minCapacity) {
//minExpand只有两个结果,0 or 10 ,即数组最小的容量可能
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
? 0 : DEFAULT_CAPACITY;
//如果需要的容量大于0,或大于10则进入下一步扩容判断
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
//如果小于等于0或者10则什么都不做
}
/**
* 私有扩容函数前置函数 | 判断是否扩容的前置函数 | 内部调用
* 传入当前集合需要接受的数据大小,根据这个参数来判断是否进行扩容
* 如果这个数据大小超过了底层数组的大小范围,就要扩容,如果没有就没有事情发生
*
* 对比:内部版本的ensureCapacity
*
*/
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { //如果当前数组为空数组
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); //则取minCapacity与10的之间的最大值
}
ensureExplicitCapacity(minCapacity); //进入ensureExplicitCapacity
}
/**
* 私有扩容函数 | 判断是否扩容函数 | 内部调用
* 传入当前集合需要接收的数据的大小,拿这个大小跟底层elementData数组的
* 长度进行比较,如果比数组长度大则扩容,小于等于不扩容
* 意义: 这个才是真正的判断是否扩容的函数,一般由
* ensureCapacityInternal和ensureCapacity方法调用
*/
private void ensureExplicitCapacity(int minCapacity) {
modCount++; //ArrayList修改次数 + 1
// overflow-conscious code
if (minCapacity - elementData.length > 0) //minCapacity 大于当前对象的长度(相等依然不扩容)则扩容
grow(minCapacity);
}
//数组最大可接受的容量是Integer的最大值-8
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 私有扩容函数 | ArrayList进行动态扩容的核心方法 | 内部调用
* minCapacity是当前ArrayList至少需要多大的容量,既目前可接收的最小容量(一般接近size)
* 比如一个add操作,minCapacity的值,既可接收的最小容量为size + 1
* grow方法通过移位运算来实现1.5倍的扩容(除了初次由0容量 -> 默认值10容量)
* 再扩容一次后,发现新容量如果还小了,就直接使用minCapacity作为新容量
*/
private void grow(int minCapacity) {
int oldCapacity = elementData.length; //当前的elementData长度
//移位运算,是扩容的核心,通过移位运算实现1.5倍的扩容
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0) //如果新容量 - 旧当前容量依然小了
newCapacity = minCapacity; //那么新容量就等于当前容量,不扩容
if (newCapacity - MAX_ARRAY_SIZE > 0) //如果新容量大于最大的容量,则进入hugeCapacity方法
newCapacity = hugeCapacity(minCapacity);
// 用新容量构成新数组,覆盖就数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
/**
* 私有扩容函数 | 专门处理数据大小过大的函数 | 内部调用
* 拥有处理容量大小接近MAX_ARRAY_SIZE的处理方法
*/
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow //如果小于0,则抛异常
throw new OutOfMemoryError();
//minCapacity大于最大值返回Integer的最大值,如果小于则返回MAX_ARRAY_SIZE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
结论:
- 扩容函数中的minCapacity的意思就是当前集合需要接收的数据至少需要这么大的容量大小
- 扩容函数中,只有一个函数对外公开,既ensureCapacity()方法,用于我不知道需要扩容成多大为好,即传入我集合需要的数据大小,让集合自行扩容到我要的容量。其他都是私有方法,内部调用
- 扩容函数的核心方法就是grow方法,ArrayList的扩容因子是1.5,通过移位运算来实现
- 十进制的10,二进制为1010。向右移动1位,得到二进制101,转换为十进制就是5,所以10 + 5等于15。
- 只要进了这个ensureExplicitCapacity方法,那么集合版本必然+1,代表集合被修改过,即使没有扩容;所以一般都是add方法调用
- 扩容是核心,内容过多,翻到最下面的相关问题
6 - List大小和是否为空
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
结论:
- emmmm,没什么好说的,size是ArrayList元素的个数,非容量
7 - contain()函数
//查询ArrayList中是否含有O对象这个元素
public boolean contains(Object o) {
return indexOf(o) >= 0; //通过IndexOf实现
}
结论:
- contains方法的实现就是依赖indexOf()方法,如果在ArrayList中的元素发现了O对象,则返回true,否则返回false
8 - indexOf()、lastIndexOf()函数
/**
* 查找ArrayList中o对象第一次出现时的索引位置
* 参数为Ojbect对象
* 如果有则返回索引位置,如果没有则返回-1
*/
public int indexOf(Object o) {
if (o == null) { //o为null的情况下
for (int i = 0; i < size; i++)
if (elementData[i]==null) //一个一个遍历比较,只要发现null,返回当前位置
return i;
} else { //如果不为null
for (int i = 0; i < size; i++)
if (o.equals(elementData[i])) //一个一个比较值,发现就返回位置
return i;
}
return -1; //如果没有该元素返回-1
}
/**
* 查找ArrayList中o对象最后一次出现时的索引位置
* 参数为Ojbect对象
* 如果有则返回索引位置,如果没有则返回-1
*/
public int lastIndexOf(Object o) {
if (o == null) { //o为null的情况下
for (int i = size-1; i >= 0; i--) //从尾向头遍历,发现null就返回
if (elementData[i]==null)
return i;
} else { //如果不为null
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i])) //从尾向头一一比较,发现值相等就返回
return i;
}
return -1; //没有该元素返回-1
}
- 从源码中我们可以看到,ArrayList的查询是最普通形式的遍历,在数据量小的情况下查找,还没什么,如果数据量大的情况下,那么这种查找就很慢了,因为要一个一个的遍历。
- 如果ArrayList中存储的是有序的数值集合,不知道是否有办法可以优化ArrayList的查找,比如使用二分法来提供效率
9 - clone()方法
/**
* 克隆方法,体现了原型模式设计思想(深拷贝)
* 参数为Ojbect对象
* 如果有则返回索引位置,如果没有则返回-1
*/
public Object clone() {
try {
//通过Object.clone方法来克隆(是本地方法)ArrayList的躯壳
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size); //克隆size长度的数组赋值给v.elementData
v.modCount = 0; //v.modCount = 0,说明这是一个新对象,还未被修改过
return v; //返回克隆的ArrayList对象
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
结论:
- ArrayList的clone相对来说是一个深拷贝,比较ArrayList的躯壳是新的,底层数据结构数组对象也是新的,仅仅是数组内部的元素是旧的。
10 - toArray()函数
/**
* 转换为Object数组
* 作用是将ArrayList对象转化为数组对象,既返回一个Object类型的数组对象
*/
public Object[] toArray() {
return Arrays.copyOf(elementData, size); //使用的是Arrays.copy方法,返回新对象
}
/**
* 转换为T类型的数组,泛型方法
* 作用就是区别没有参数的toArray()方法,这种方法更加的使用,因为类型已经转换好了
* 例子: list.toArray(new String[10])
*/
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) //如果a.len小于size,则修正,拷贝size个长度的T类型新数组,既最小也是size长度
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size); //如果相等则拷贝好先
if (a.length > size) //如果a.len > size,则后面为Null
a[size] = null;
return a; //大于等于的情况下返回a
}
11 - get、set、add、remove、clear函数
/**
* 默认修饰符的方法,返回ArrayList中index位置的元素
*/
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* 返回ArrayList中index位置的元素
*
*/
public E get(int index) {
rangeCheck(index); //如果index大于size,则抛异常
return elementData(index);
}
/**
* update在index位置的元素,用新元素覆盖旧元素,并返回旧元素
* index是索引位置,element是新元素
*
*/
public E set(int index, E element) {
rangeCheck(index); //如果index大于size,则抛异常
E oldValue = elementData(index); //获得旧元素
elementData[index] = element; //新元素覆盖旧元素
return oldValue; //返回旧元素
}
/**
* 在ArrayList尾部插入一个元素,顺序插入
*/
public boolean add(E e) {
//每次add操作就需要预判是否需要扩容,因为当前容量也许不支持你add一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e; //size位置插入元素,插入后size + 1
return true; //插入成功返回true
}
/**
* 在ArrayList的index位置插入一个新元素
*
*/
public void add(int index, E element) {
rangeCheckForAdd(index); //异常检查,如果index>size or index < 0,抛异常
//每次add操作就需要预判是否需要扩容,因为当前容量也许不支持你add一个元素
ensureCapacityInternal(size + 1); // Increments modCount!!
//秒啊,利用拷贝算法,从elementData的index位置开始拷贝,拷贝size - index个长度
//从elementData的index + 1位置开始覆盖。既相当于elementData从Index位置向后拉长了一个长度
//要注意size并不是数组的长度,而是有元素的个数
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element; //然后在Index位置插入新元素
size++; //元素个数+1
}
/**
* 删除ArrayList的index位置的元素,并返回
* 数组长度没有变化,仅仅是把[index+1,size)的子数组覆盖到[index,size - 1)。
* 所以size - 1的元素就是多余了,只能取消引用,指向null,好让GC去回收
*/
public E remove(int index) {
rangeCheck(index); //异常检查,Index > size则抛异常
modCount++; //修改 + 1
E oldValue = elementData(index); //获得old元素
int numMoved = size - index - 1; //要copy个元素个数,等价于size - (index + 1)
if (numMoved > 0) //需要拷贝的情况下
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work,把引用关系取消,让GC回收
return oldValue; //返回旧元素
}
/**
* remove函数,从头向尾遍历,删除第一个出现的o对象元素
*
*/
public boolean remove(Object o) {
if (o == null) { //如果参数为null,则从头向尾遍历,发现null则删除
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else { //如果参数不为null,则从头向尾遍历,发现值能匹配的则删除
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false; //如果没有找到,则返回false
}
/**
* Private remove method that skips bounds checking and does not
* return the value removed.
* 反正就是remove(int index)的私有简化版本
*/
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
/**
* Removes all of the elements from this list. The list will
* be empty after this call returns.
* 清空ArrayList对象的所有元素,让所有元素指向Null,容量不变,size变0
*/
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
12 - xxxxAll()类函数
/**
* 将其他集合对象的元素加入到当前ArrayList对象尾部
*/
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray(); //获得参数对象集合的数组对象
int numNew = a.length; //获得参数集合对象的长度
//扩容,修改 + 1
ensureCapacityInternal(size + numNew); // Increments modCount
//将参数集合的元素从0位置开始,复制numNew个长度,到elementData中(从size位置开始覆盖)
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew; //size = size + numNew
return numNew != 0; //如果numNew = 0,则false
}
/**
* 将其他集合对象的元素加入到当前ArrayList对象的index位置
*/
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount,扩容,修改+1
int numMoved = size - index;
if (numMoved > 0) //首先index后的子数组向后移动numNew个位置
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew); //在腾出来的空间中,插入参数集合的元素
size += numNew;
return numNew != 0;
}
/**
* 这是一个不公开的函数,删除ArrayList中[fromIndex,toIndex)区间的元素
*
*/
protected void removeRange(int fromIndex, int toIndex) {
modCount++; //修改 + 1
int numMoved = size - toIndex;
System.arraycopy(elementData, toIndex, elementData, fromIndex,
numMoved);
// clear to let GC do its work
int newSize = size - (toIndex-fromIndex);
//将不要的部分指向Null,为了让GC能够识别出这些是无用对象
for (int i = newSize; i < size; i++) {
elementData[i] = null;
}
size = newSize;
}
/**
* 去交集,只留下不相交的
* 例如:list1.retainAll(list2)
* list1去掉了与list2都有的元素,只留下List1和List2不想交的元素
*/
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
/**
* 取交集,只留下相交的
* 例如:list1.retainAll(list2)
* list1去除与List2不想交的元素,既只保留list1有,list2也有的元素
*/
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
/**
* 私有方法,用于给retainAll和removeAll调用,批量删除元素
* true为retainAll,false为removeAll
*/
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
int r = 0, w = 0; //两个指针
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
结论:
- addAll、retainAll、removeAll的参数都是另一个集合对象
- retainAll是取交集的方法,removeAll是去交集
13 - writeObject()、readObject()函数
//内置的序列化方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
//内置的反序列化方法
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
结论:
- 都是私有的方法,用于序列化和反序列化
14 - 返回Iterator对象函数
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
//返回一个ListIterator实现类ListItr的实例对象,用于迭代遍历
public ListIterator<E> listIterator() {
return new ListItr(0);
}
//返回一个iterator实现类Itr的实例对象,用于迭代遍历
public Iterator<E> iterator() {
return new Itr();
}
结论:
- 作用就是用于迭代
15 - subList()、subListRangeCheck()函数
/**
* 截取ArrayList,得到子List,返回一个subList内部类实例,一般用List来接收
* 功能就类似于String的substring
* 截取区间是[fromIndex,toIndex),是半闭包的
*
*/
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, 0, fromIndex, toIndex);
}
//异常检查
static void subListRangeCheck(int fromIndex, int toIndex, int size) {
if (fromIndex < 0)
throw new IndexOutOfBoundsException("fromIndex = " + fromIndex);
if (toIndex > size)
throw new IndexOutOfBoundsException("toIndex = " + toIndex);
if (fromIndex > toIndex)
throw new IllegalArgumentException("fromIndex(" + fromIndex +
") > toIndex(" + toIndex + ")");
}
结论:
- 依赖内部类SubList,返回的也是内部类SubList的实例,一般在外部向上转型为List,不同转型为ArrayList。具体查看内部类的定义
- 使用例子
ArrayList<String> list = new ArrayList<>();
list.add(new String("a"));
list.add(new String("b"));
list.add(new String("a"));
list.add(new String("b"));
List<String> sub = list.subList(1, 3);
System.out.println(sub);
//output: [b, a]
16 - forEach()函数
/**
* 这是一个JDK1.8加入的迭代方式,用于配合Lambda表达式使用
* Consumer接口,这是一个函数式接口
*/
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action); //要求传入的函数不能为空
final int expectedModCount = modCount; //期待的版本号
@SuppressWarnings("unchecked")
//为什么多此一举,将数组和大小赋值给final对象,可能是外部自由变量在内部类调用需要声明为final吧
final E[] elementData = (E[]) this.elementData;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
action.accept(elementData[i]); //执行我们传入的lambda函数,本质上是执行重写后的accept方法
}
if (modCount != expectedModCount) { //如果预期版本与现版本不一致,抛出异常
throw new ConcurrentModificationException();
}
}
17 - spliterator()函数
@Override
public Spliterator<E> spliterator() {
return new ArrayListSpliterator<>(this, 0, -1, 0);
}
- 并行迭代器
- Spliterator是Java 8引入的新接口,顾名思义,Spliterator可以理解为Iterator的Split版本(但用途要丰富很多)。使用Iterator的时候,我们可以顺序地遍历容器中的元素,使用Spliterator的时候,我们可以将元素分割成多份,分别交于不于的线程去遍历,以提高效率。使用 Spliterator 每次可以处理某个元素集合中的一个元素 — 不是从 Spliterator 中获取元素,而是使用 tryAdvance() 或 forEachRemaining() 方法对元素应用操作。但Spliterator 还可以用于估计其中保存的元素数量,而且还可以像细胞分裂一样变为一分为二。这些新增加的能力让流并行处理代码可以很方便地将工作分布到多个可用线程上完成。
18 - removeIf()函数
/**
* 移除集合中满足给定条件的所有元素,错误或者运行时异常发生在迭代时或者把条件传递给调用者的时候。
* 结果lambda表达式的断言函数,只要满足条件的元素,都从集合中剔除。就类似于通过iterator遍历的同时删除元素
*
* @implSpec
* 默认的实现贯穿了使用迭代器iterator的集合的所有元素。每一个匹配的元素都将被用Iterator接口中的
* remove()方法移除。如果集合的迭代器不支持移除,则在第一次匹配时就会抛出异常 UnsupportedOperationException
*
* @param filter 令元素移除成功的条件
* @return {@code true} 如果所有的元素都被移除
* @throws NullPointerException 如果有一个过滤器是空的
* @throws UnsupportedOperationException 如果元素不能被从该集合中移除。如果一个匹配元素不能被移除,
* 通常来说,它就不支持移除操作,这时可能抛出这个异常。
* @since 1.8
*/
@Override
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// shift surviving elements left over the spaces left by removed elements
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
19 - replaceAll()函数
/**
* 结合Lambda的函数式接口来使用
* 将集合中所有的A替换成B,A与B都是同一类型,属于E
*/
@Override
@SuppressWarnings("unchecked")
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]); //执行
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
- UnaryOperator
是一元操作函数,效果等同于Function
20 - sort()函数
/**
* ArrayList集合的排序算法
* 参数是比较器,根据比较器的内容来决定怎么排序
*/
@Override
@SuppressWarnings("unchecked")
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);//通过Arrays.sort来排序
if (modCount != expectedModCount) { //如果在排序过程中,集合被修改了,将报错(多线程情况下)
throw new ConcurrentModificationException();
}
modCount++; //修改次数+1
}
结论:
- 说白了还是使用了Arrays工具类的sort()方法,既ArrayList的排序依赖的是数据工具类对数组的排序方法
- 当然还也以使用Collections.sort()来对集合进行排序
rangeCheck、rangeCheckForAdd、outOfBoundsMsg异常检查函数
//私有函数,检查index是否大于size
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 私有函数,检查index是否大于size且index是否小于0
* A version of rangeCheck used by add and addAll.
*/
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
//返回当前参数Index和当前Size
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
结论:
- 用于异常判断
ArrayList的内部类解析
- 内部类Itr类 - (迭代器)
- 内部类ListItr - (List专用迭代器)
- 内部类SubList - (返回截取的部分)
- 静态内部类ArrayListSpliterator类 - (并行迭代器)
内部类Itr类
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
内部类ListItr类
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
内部类SubList 类
/**
* 我们就理解成是一个ArrayList的功能缩小版本就好了
*/
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E e) {
rangeCheck(index);
checkForComodification();
E oldValue = ArrayList.this.elementData(offset + index);
ArrayList.this.elementData[offset + index] = e;
return oldValue;
}
public E get(int index) {
rangeCheck(index);
checkForComodification();
return ArrayList.this.elementData(offset + index);
}
public int size() {
checkForComodification();
return this.size;
}
public void add(int index, E e) {
rangeCheckForAdd(index);
checkForComodification();
parent.add(parentOffset + index, e);
this.modCount = parent.modCount;
this.size++;
}
public E remove(int index) {
rangeCheck(index);
checkForComodification();
E result = parent.remove(parentOffset + index);
this.modCount = parent.modCount;
this.size--;
return result;
}
protected void removeRange(int fromIndex, int toIndex) {
checkForComodification();
parent.removeRange(parentOffset + fromIndex,
parentOffset + toIndex);
this.modCount = parent.modCount;
this.size -= toIndex - fromIndex;
}
public boolean addAll(Collection<? extends E> c) {
return addAll(this.size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
int cSize = c.size();
if (cSize==0)
return false;
checkForComodification();
parent.addAll(parentOffset + index, c);
this.modCount = parent.modCount;
this.size += cSize;
return true;
}
public Iterator<E> iterator() {
return listIterator();
}
public ListIterator<E> listIterator(final int index) {
checkForComodification();
rangeCheckForAdd(index);
final int offset = this.offset;
return new ListIterator<E>() {
int cursor = index;
int lastRet = -1;
int expectedModCount = ArrayList.this.modCount;
public boolean hasNext() {
return cursor != SubList.this.size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= SubList.this.size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[offset + (lastRet = i)];
}
public boolean hasPrevious() {
return cursor != 0;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[offset + (lastRet = i)];
}
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = SubList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (offset + i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[offset + (i++)]);
}
// update once at end of iteration to reduce heap write traffic
lastRet = cursor = i;
checkForComodification();
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
SubList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(offset + lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
SubList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = ArrayList.this.modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (expectedModCount != ArrayList.this.modCount)
throw new ConcurrentModificationException();
}
};
}
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private void rangeCheck(int index) {
if (index < 0 || index >= this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private void rangeCheckForAdd(int index) {
if (index < 0 || index > this.size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+this.size;
}
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
public Spliterator<E> spliterator() {
checkForComodification();
return new ArrayListSpliterator<E>(ArrayList.this, offset,
offset + this.size, this.modCount);
}
}
静态内部类ArrayListSpliterator类
static final class ArrayListSpliterator<E> implements Spliterator<E> {
private final ArrayList<E> list;
private int index; // current index, modified on advance/split
private int fence; // -1 until used; then one past last index
private int expectedModCount; // initialized when fence set
/** Create new spliterator covering the given range */
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
if ((hi = fence) < 0) {
if ((lst = list) == null)
hi = fence = 0;
else {
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
public ArrayListSpliterator<E> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
public boolean tryAdvance(Consumer<? super E> action) {
if (action == null)
throw new NullPointerException();
int hi = getFence(), i = index;
if (i < hi) {
index = i + 1;
@SuppressWarnings("unchecked") E e = (E)list.elementData[i];
action.accept(e);
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
return true;
}
return false;
}
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
public long estimateSize() {
return (long) (getFence() - index);
}
public int characteristics() {
return Spliterator.ORDERED | Spliterator.SIZED | Spliterator.SUBSIZED;
}
}
一些问题
关于ArrayList扩容的总结
ArrayList扩容相关的方法总共有5个
ensureCapacity(int)ensureCapacityInternal(int)ensureExplicitCapacity(int)grow(int)hugeCapacity(int)
他们主要是做:
ensureCapacity和ensureCapacityInternal都是扩容前置判断函数,具有同等意义的函数,区别是一个对外公开,一个对内使用
ensureExplicitCapacity是扩容后置判断函数,只可能由前置判断函数调用,两个作用: 一是判断是否要调用grow;二是让集合的版本+1(即只要进入这个函数,集合的modCount就会加1)
grow是扩容的核心函数,真正的扩容就是在这个函数执行的
hugeCapacity函数是专门用来处理需要的容量非常大的情况的异常扩容函数,几本使用到的概率第低,只可能是由grow调用,在MAX_ARRAY_SIZE > 新容量的情况下才会触发
ensureCapacity引发的扩容:

add/addAll/readObject引发的扩容:

- 能进入ensureExplicitCapacity函数,则代表集合就会被修改,版本号 + 1
- 能引发grow函数中newCapacity > minCapacity的情况,有可能是addAll的情况,一次性add的数据大小超过了原容量的1.5倍;还有就是人为的调用了公有方法ensureCapacity,传入了一个比集合当前容量大1.5倍的数值; 当然后有使用无参构造函数得到的集合第一次扩容时,即从0 -> 10的阶段
为什么前置扩容哈数ensureCapacity和ensureCapacityInternal都需要做一个elementData == {}(空数组)的判断?
这是因为ArrayList的构造函数有三个,一个是无参构造,它构造的ArrayList集合的默认底层数组是一个空数组{}
,即Object[]; 另一个是会传入一个初始的数组容量,它构造的底层数组的大小就是传入的大小,有可能是0;最后一个就是类似克隆其他集合的数据,传入集合也有可能是空集合,三种构造函数大致会造成的情况如下图:
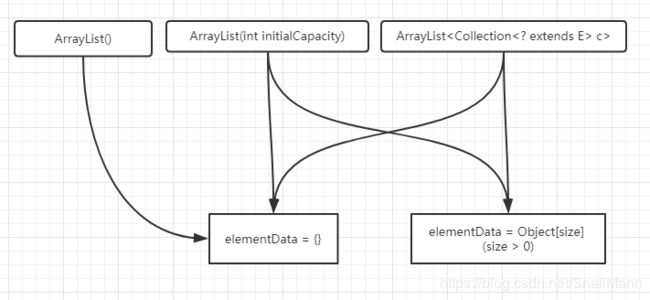
从上图看到,说白了,从一个集合被构造出来之后,它的底层数组只有两个状态,一是空数组状态,二是非空数组状态
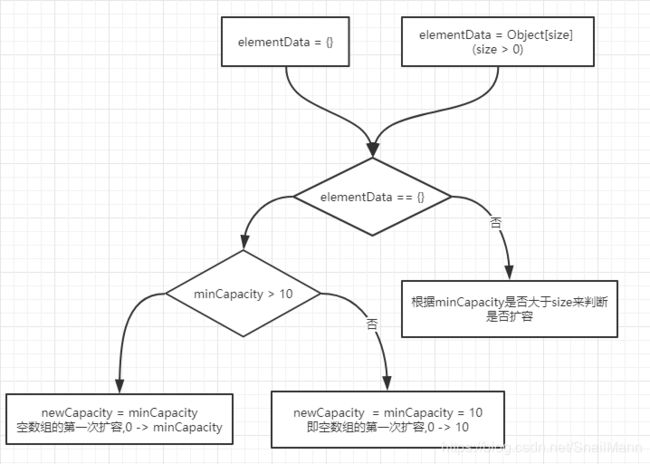
- 空数组就要做集合的第一次扩容 0 -> 10 或 0 -> minCapacity(minCapacity > 10)
- 非空数组就要拿传入的需要的大小minCapacity和size比较,判断是否需要扩容
总结:
所以我们明白前置扩容判断函数的本质功能仅仅是为了解决集合底层数组是空数组的特殊情况(即还没有被初始化),一般由构造函数构造时,为底层数组赋予默认空数组的情况,也挺常见的;而非空数组只是作为一种正常通行,交给后置判断做处理
并发情况下add方法引起的线程安全问题
由此给了我想法,我猜想是,由于没有该方法没有同步,导致出现这样一种现象,用第一次异常,即下标为15时的异常举例。当集合中已经添加了14个元素时,一个线程率先进入add()方法,在执行ensureCapacityInternal(size + 1)时,发现还可以添加一个元素,故数组没有扩容,但随后该线程被阻塞在此处。接着另一线程进入add()方法,执行ensureCapacityInternal(size + 1),由于前一个线程并没有添加元素,故size依然为14,依然不需要扩容,所以该线程就开始添加元素,使得size++,变为15,数组已经满了。而刚刚阻塞在elementData[size++] = e;语句之前的线程开始执行,它要在集合中添加第16个元素,而数组容量只有15个,所以就发生了数组下标越界异常!
ArrayList几种拷贝的方式总结
- 方式一 |
ArrayList(Collection c)| 构造方式的Copy - 方式二 |
ArrayList.clone()| Arrays.copyOf()方式 - 方式三 |
ArrayList.addAll(Collection c)| System.arraycopy()方式 - 方式四 |
Collections.copy(List dest, List src)| Java代码for循环的方式
在我自己的看来,这四种可以实现ArrayList集合的拷贝或类似拷贝功能的方式都是属于浅拷贝的范畴;这种浅拷贝指的是集合的底层结构 - 数组的外壳是新的,但是数组的内部元素(对象)依然是旧的
方式一和方式二看底层源码,我们就会知道他们的本质都是System.arraycopy()的方式,跟方式三的原理是一样的,都属于native方法System.arraycopy()的范畴
方式四,看底层代码,会发现这完全是Java层面的for遍历,从旧数组对应的位置获取元素,更新新数组的同位置的值,在我自己看了,这种方式比方式一,二,三还要低下;好歹他们是使用的经过优化的本地方法
for (int i=0; i<srcSize; i++)
dest.set(i, src.get(i));
ListIterator和Iterator区别
一.相同点
- 都是迭代器,当需要对集合中元素进行遍历不需要干涉其遍历过程时,这两种迭代器都可以使用。
二.不同点
- 使用范围不同,Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型。而ListIterator只能用于List及其子类型。
- ListIterator有add方法,可以向List中添加对象,而Iterator不能。
- ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator不可以。
- ListIterator可以定位当前索引的位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
- 都可实现删除操作,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
LinkedList和ArrayList在效率上的比较
1. 通常在LinkedList和ArrayList上的区别是:
- ArrayList善于随机访问,比如按索引读取(查/更)
- LinkedList善于删除/插入操作
随机访问测试:
private static void getTest() {
long startTime = System.currentTimeMillis();
for (int i = 0; i < 800000; i++) {
int a = arraylist.get(i);
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
startTime = System.currentTimeMillis();
for (int i = 0; i < 800000; i++) {
int a = linkedlist.get(i);
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
}
0.011 //ArrayList
... //LinkedList,等了好久
在数据量大的情况下,千万不要使用LinkedList去get数据,在数据量大的情况下,LinkedList每次get值都要进行大量的耗时遍历,这会造成很大的性能问题
头操作测试:
private static void addHeadTest(Random random) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {
arraylist.add(0,random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {
linkedlist.add(0,random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
}
0.733 // ArrayList
0.016 // LinkedList
80000条数据下的头操作,LinkedList的效率比ArrayList高; 这也验证了LinkedList
这里也说明了ArrayList善于随机访,LinkedList善于删除/插入操作;然而这不是绝对的;这可能根据数据量的大小,操作的位置的不同,也会造成不同的性能差异
2. ArrayList中部操作比LinkedList快
如果是中部操作:
private static void addMidTest(Random random) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {
arraylist.add(arraylist.size() / 2, random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {
linkedlist.add(linkedlist.size() / 2, random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
}
0.281 //ArrayList
9.827 //LinkedList
80000条数据下的集合中部位置操作,ArrayList的性能要比LinkedList高
为什么会有这样的差异呢?因为虽然ArrayList需要移动元素位置,但是是通过本地方法System.arraycopy复制的方式去移动的,该方法本身就具有很高的效率,也并不是一个一个元素取移动;另外呢,LinkedList的中部和尾部操作每次的操作都需要进行前或后的遍历,数据量大了,长度就长了,耗费的时间也就更多了;
3. 尾部操作:数据量少的时候,ListedList比ArrayList高,数据量大的时候ArrayList效率远比LinkedList高
三种情况:
- 数据量非常非常少 | ArrayList性能跟LinkedList接近,可能会高一点点
- 数据量比较少,一般 | LinkedList的性能比ArrayList更好,比如8w条数据时,但是快不了很多很多
- 数据量非常多 | LinkedList性能会骤降,ArrayList的性能会比LinkedList好很多,比如800W条数据
中等数据量测试:
private static void addTest(Random random) {
//ArrayList
long startTime = System.currentTimeMillis();
for (int i = 0; i < 80000; i++) {
arraylist.add(random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
//LinkedList
startTime = System.currentTimeMillis();
for (int i = 0; i < 8000000; i++) {
linkedlist.add(random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
}
0.016 //ArrayList
0.014 //LinkedList
普遍上是LinkedList的效率还是比ArrayList快一点
大数据量测试: 800w条数据
private static void addTest(Random random) {
//ArrayList
long startTime = System.currentTimeMillis();
for (int i = 0; i < 8000000; i++) {
arraylist.add(random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
//LinkedList
startTime = System.currentTimeMillis();
for (int i = 0; i < 8000000; i++) {
linkedlist.add(random.nextInt(1000));
}
System.out.println((double) (System.currentTimeMillis() - startTime) / 1000);
}
0.296 //ArrayList
6.432 //LinkedList
8000000次尾插入,ArrayList的效率在毫秒级,而LinkedList已经过秒了,相差有30多倍,还不是平均结果,还有差距更大的时候
其实我在8000的数据量和80w也做了测试,8000条数据时LinkedList的效率比ArrayList高挺多的;在80w的数据时是不相上下的,有时你快,有时我快。
4. ArrayList遍历要比LinkedList快
ArrayList遍历最大的优势在于内存的连续性,CPU的内部缓存结构会缓存连续的内存片段,可以大幅降低读取内存的性能开销。而虽然LinkedList是链表结果,但实际上遍历速度却慢与ArrayList
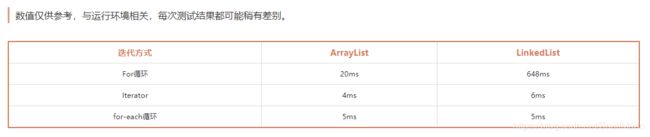
(图片截图于大佬文章) -> ArrayList与LinkedList遍历性能比较 - @作者: GcsSloop
上面的数据是遍历10000条数据得到的结果,所以,我们可以知道LinkedList在通用for循环的遍历中,差距离ArrayList还是比较明显的
!总结
总结起来,能用ArrayList就用ArrayList,在数据量较小的时候,存在很多的插入删除操作,可以使用一下LinkedList,但实际上数据量这么小,也不差这点时间;在大数据的情况下,就千万不要使用LinkedList了,性能骤降呀
参考资料
ArrayList 是怎么实现可变长度的,Capacity容量 - @作者:youz1976
ArrayList源码分析(基于JDK8) - @作者:Fighter168
转数组的toArray()和toArray(T[] a)方法 - 作者:@413899327
java 取交集方法retainAll - @作者:lanxin0802
坑人无数的Java面试题之ArrayList - @作者:老钱