【MySQL笔记】正确的理解MySQL中让你想到就烦的各种锁(一)
正确的理解MySQL中让你想到就烦的各种锁(一)
如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!博客目录 | 先点这里
MySQL的锁知识,跟索引知识一样,都同样的复杂,甚至更复杂。所以还需要一些耐心哟!同时因为本篇整理的内容过多,近约2w多字。所以很可能会在一些地方存在描述有误,或是废话太多。希望大家可以帮我挑出毛病,一同进步。
!首先声明,MySQL的测试环境是8.0
- 前提概念
- MySQL中锁的分类
- MySQL支持三种层级的锁定
- 如何学习MySQL中的锁知识
- 事务持有锁的SQL
- MyISAM引擎支持的锁
- MyISAM下的表锁
- MyISAM下的共享锁和排他锁
- 知识总结
- InnoDB引擎支持的锁
- 官方列举的InnoDB引擎的锁
- InnoDB下的表锁和行锁
- InnoDB下的共享锁和排他锁
- InnoDB下的意向锁
- InnoDB下的记录锁,间隙锁,临键锁
- InnoDB下的插入意向锁
- 知识总结
- 相关问题
- 验证索引与锁之间的"锁哪里"关系
- 参考资料
前提概念
MySQL中锁的分类
下图为MySQL部分存储引擎所支持的锁
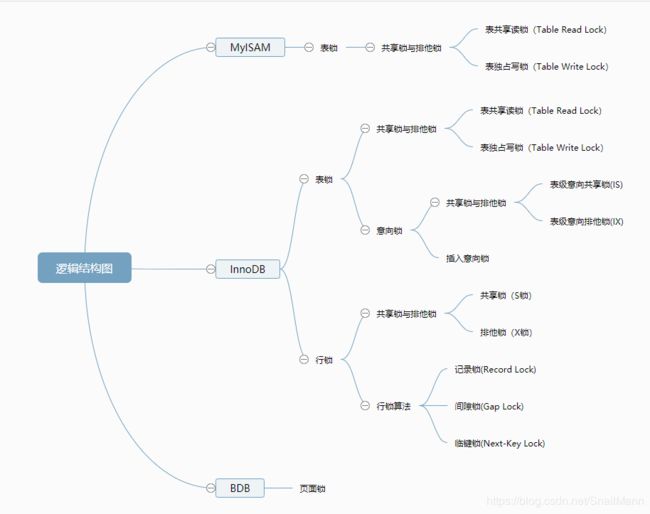
MySQL支持三种层级的锁定
我们知道,MySQL支持三种层级的锁定,分别为
- 表级锁定
表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定 - 页级锁定
页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁 - 行级锁定
行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大
从上到下,锁的粒度逐渐细粒化, 但实现开销逐渐增大。 同时我们也要须知,表锁,页锁,行锁并不是一个具体的锁,仅代表将数据库某个层级上的数据进行锁定。具体怎么去锁这个数据,还要看具体的锁实现是什么

如何学习MySQL中的锁知识
说实话,MySQL的锁知识,在初学的时候,真的是挺复杂的。主要是概念多,分类也多,还有各种乱七八糟,想到都烦的名词。所以学习MySQL中各种锁时,要从简单的入手,繁琐的名词暂时不要管。等有经验之后,自然会懂得。
(一) 了解MySQL大致有哪些锁,建立脑图分类
- 知道MySQL支持三个层级的锁定,但要跟不同的存储引擎来判断数据库支持哪个层级的锁
- 知道什么是表锁,行锁。什么是页锁
(二) 站在存储引擎的角度,具体学习存储引擎支持的锁
- 知道不同存储引擎支持哪个层级的锁,主要研究InnoDB和MyISAM两种存储引擎
- 研究MyISAM存储引擎下的表锁
- 研究InnoDB存储引擎下的表锁和行锁
- 研究InnoDB的排他锁和共享锁
- 研究InnoDB的意向锁
(三) 重点研究InnoDB行锁的具体实现算法
- 研究InnoDB的记录锁,间隙锁,临键锁
(四) 了解InnoDB下锁与事务,锁与索引的联系
- 了解InnoDB下的RR级别下是怎么避免幻读的?
- 了解锁与事务之间的联系,二段锁提交
了解了以上的内容,我想应该大致也能够应付很多日常的开发了。剩下的内容比较细致和繁琐,个人觉得还是需要实际的社会实践,才能更加的深有体会并记住。
事务持有锁的SQL
要认识事务,SQL,与锁的知识,最好的办法就是调试。所以我这里提供给大家MySQL 8.0以及MySQL 8.0以下的查询事务持有锁情况的SQL
MySQL 8.0 以下
show engine innodb status;
在TRANSACTION位置可以看到事务持有锁的情况,但是需要经验分析,名词比较难懂select * from information_schema.innodb_locks;
查看innodb引擎下,所有表所有事务的加锁情况,无法分别gap,record,next-key锁的具体类型。没有冲突情况无法显示持有的锁select * from information_schema.innodb_locks_wait;
查看innodb引擎下,所有表所有事务因锁的阻塞情况,谁被谁block住了
MySQL 8.0
show engine innodb status;
在TRANSACTION位置可以看到事务持有锁的情况,但是需要经验分析,名词比较难懂select * from performance_schema.data_locks;
查看数据库中所有表所有事务的加锁情况,没有冲突,也看到持有了什么锁,具有具体的分类,简单好用,更容易分析select * from performance_schema.data_locks_wait;
查看数据库中,所有表所有事务因锁的阻塞情况,谁被谁block住了

所以我个人建议还是用MySQL 8.0的分析语句来调试更好,因为更加清晰,内容更多,功能更强大。
MyISAM引擎所支持的锁
MyISAM引擎的表锁
MyISAM只支持表锁,不支持行锁和页面锁。
- 据我查到的资料中,MyISAM引擎支持的锁不多,也就是表级的排他锁和共享锁而已,官方资料上也没有专门介绍MyISAM锁的章节
- 表锁并不是一个真正的锁,只是代表对数据库表层级的数据进行锁定。具体以什么形式锁定,则要看具体的具体锁实现。

由上图可知,表锁的具体实现有表级共享锁和表级排他锁
MyISAM下的共享锁和排他锁
(一) MyISAM引擎下共享锁和排他锁
我们知道MyISAM存储引擎只支持在表层级对数据进行锁定,既只支持表锁。那么表层级具体的加锁实现有什么?既表级共享锁和表级排他锁
表共享读锁(表级共享锁)
获得表共享读锁的事务可以读取该表的任意数据。MyISAM引擎在执行select语句前,会自动给涉及的表加表共享读锁表独占写锁(表级排他锁)
获得表独占写锁的事务可以更新或删除该表中任意数据。在执行update,delete,insert等语句前,会自动给涉及的表加表独占写锁
只是很多场合更喜欢把表级共享锁和表级排他锁叫做表共享读锁和表独占写锁,实际上它们的意思是一样的
(二) 表共享读锁和表独占写锁的兼容性
| 标题 | 表共享读锁 | 表独占写锁 |
|---|---|---|
| 表共享读锁 | 兼容 |
不兼容 |
| 表独占写锁 | 不兼容 |
不兼容 |
既MyISAM的表锁可以做到,读读共享,读写互斥,写写互斥的功能
- 读读共享: 事务A获得表读锁,事务B依然可以获得表读锁
- 读写互斥: 事务A获得表读锁,事务B申请该表写锁则会阻塞,因为事务A获得了该表读锁,有互斥性
- 写写互斥: 事务A获得表写锁,事务B申请该表写锁则会阻塞,因为事务A获得了该表写锁,也有互斥性
值得注意的是
- The LOCAL modifier enables nonconflicting INSERT statements (concurrent inserts) by other sessions to execute while the lock is held. (See Section 8.11.3, “Concurrent Inserts”.) However, READ LOCAL cannot be used if you are going to manipulate the database using processes external to the server while you hold the lock. For InnoDB tables, READ LOCAL is the same as READ
- MyISAM在一定程度上还是可以支持并发的进行查询和插入操作的。既如果MyISAM表中没有空洞(即表的中间没有被删除的行),MyISAM允许在一个线程读表的同时,另一个线程从表尾插入记录。这属于MyISAM的特性,所以InnoDB存储引擎是不支持的!
知识总结
-
虽然MySQL支持表,页,行三级锁定,但MyISAM存储引擎只支持表级的数据锁定,既表锁。所以MyISAM的加锁相对比较开销低,但数据操作的并发性能相对就不高。但如果写操作都是尾插入,那么还是可以支持一定程度的读写并发
-
既MyISAM的数据操作如果导致加锁行为,那么该锁肯定是一个表锁,会对全表数据进行加锁。但也要看具体什么形式的表锁,不同形式的表锁有着不同的特性
-
同时从MyISAM所支持的锁中也可以看出,MyISAM是一个支持读读并发,但不支持通用读写并发,写写并发的数据库引擎,所以它更适合用于读多写少的应用场合
InnoDB引擎所支持的锁
官方列举的InnoDB引擎的锁
(一) 官方列举的InnoDB引擎的锁
InnoDB的功能则更为强大,MySQL官方还专门一个栏目来介绍InnoDB引擎所支持的锁

截图至InnoDB Locking | MySQL 8.0 - @作者:官方
我们从图中大概可以看出这么几种锁:
- 共享锁和排他锁 (Shared and Exclusive Locks)
- 意向锁(Intention Locks)
- 记录锁(Record Locks)
- 间隙锁(Gap Locks)
- 临键锁 (Next-Key Locks)
- 插入意向锁(Insert Intention Locks)
- 主键自增锁 (AUTO-INC Locks)
- 空间索引断言锁(Predicate Locks for Spatial Indexes)
(二) 我们重点要说的锁
为了避免陷入名词混乱的漩涡,我们这里这说明重点,并不讲主键自增锁,空间索引断言锁之类的锁
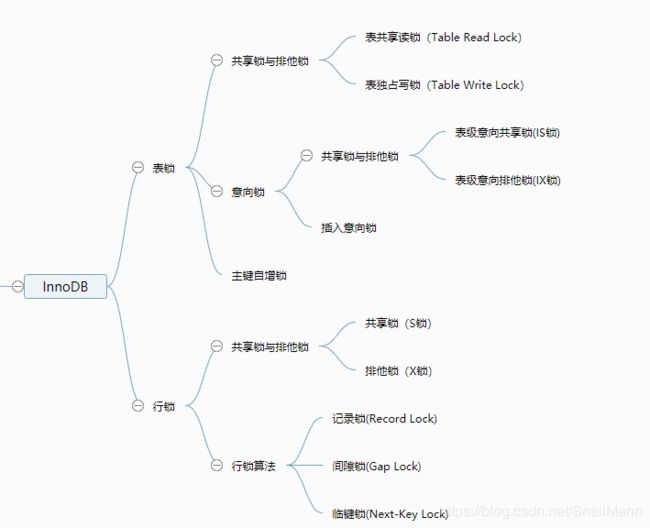
InnoDB下的表锁和行锁
(一) 表锁和行锁
InnoDB存储引擎,不仅仅支持表级锁定,还支持行级锁定。说白了就是不仅支持表锁,还支持MyISAM所不支持的行锁。
- 表锁,行锁并不是一个真正的锁,只是代表可以对数据库对应层级的数据进行锁定。具体以什么形式去锁定,则要看具体的具体锁实现
- 而表锁具体的锁实现则有共享锁,排他锁,意向锁等。而行锁则有共享锁和排他锁,另外行锁本身还有记录锁,间隙锁和临键锁的不同算法实现。
那是不是行级锁一定比表级锁要好呢?
- 那到未必,锁的粒度越细,代价越高,相比表级锁在表的头部直接加锁,行级锁还要扫描找到对应的行对其上锁,这样的代价其实是比较高的
- 总之,锁的粒度越细,需要实现的开销越大,所以表锁和行锁各有好处
(二) 表锁和行锁的分类
因为我们知道,表锁和行锁并不是一把具体的锁,仅仅代表要在数据库的那个层次结构对数据进行锁定,这也代表了表,行锁还可以被细化出一下具体的锁实现
这也的确是很绕的概念,需要慢慢领略。
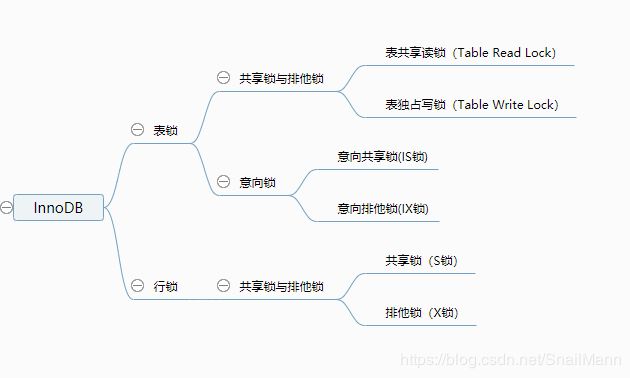
(三) InnoDB实现的行锁
InnoDB行锁是通过给索引上的索引项加锁来实现的,这一点MySQL与Oracle不同,后者是通过在数据块中对相应数据行加锁来实现的。 InnoDB这种行锁的实现也意味着,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
- InnoDB存储引擎的表在不使用索引时使用表锁
- 有了索引以后,在对索引字段查询时,使用的就是行级锁
- 由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,还是会出现锁冲突的,因为他们使用的是同一把锁
- 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁
引用至【知识库】–Mysql InnoDB 行锁实现 和 表锁实现(205)- @作者:彻夜无眠
InnoDB下的共享锁和排他锁
(一) 什么是共享锁和排他锁?
-
共享锁(Shared Lock),既S锁,又称读锁。
事务拿到某一行记录的S锁,才可以读取这一行的数据。共享锁可以实现读读共享,读写互斥 -
排他锁(Exclusive Lock),既X锁,又称写锁,独占锁。
事务拿到某一行记录的X锁,才可以修改或者删除这一行的数据。排他锁可以实现读写互斥,写写互斥
(二) 表行层次下的共享锁和排他锁
因为InnoDB支持表锁和行锁。所以在数据库层次结构的表级和行级,都可以对数据进行锁定,具体以什么方式进行锁定呢?共享锁和排他锁就是本节要讨论的具体锁实现
表级共享锁
表级共享锁,又称为表共享读锁,既在表的层级上对数据加以共享锁,实现读读共享表级排他锁
表级排他锁,又称为表独占写锁,既在表的层级上对数据加以排他锁,实现读写互斥,写写互斥行级共享锁
行级共享锁既在行的层级上,对数据加以共享锁,实现对该行数据的读读共享行级排他锁
行级排他锁既在行的层级上,对数据加以排他锁,实现对该行数据的读写互斥,写写互斥
(三) 共享锁和排它锁的兼容性
| 标题 | 共享锁 | 排他锁 |
|---|---|---|
| 共享锁 | 兼容 |
不兼容 |
| 排他锁 | 不兼容 |
不兼容 |
- 多个事务可以拿到一把S锁,可以实现读读共享
- 而只有一个事务可以拿到X锁,可以实现读写互斥,写写互斥
一句话,就是读读共享,读写互斥,写写互斥。这里要理解一个概念,上表仅仅是同一层次的共享锁和排他锁之间的兼容性,并非是表锁和行锁共存的情况。
(四) 怎么显式地加共享锁或排他锁?
select * from table lock in share mode为table的所有数据加上共享锁,既表级共享锁select * from table for update为table的所有数据加上排他锁,既表级排他锁select * from table where id = 1 for update为table中id为1的那行数据加上排他锁,既行级排他锁select * from table where id = 1 lock in share mode为table中id为1的那行数据加上共享锁,既行级共享锁
当然以上,加的是行锁的前提是,id为主键且在查询命中,否则行锁会轮为表锁
InnoDB下的意向锁
(一) 为什么会有意向锁?
InnoDB supports multiple granularity locking which permits coexistence of row locks and table locks. For example, a statement such as LOCK TABLES … WRITE takes an exclusive lock (an X lock) on the specified table. To make locking at multiple granularity levels practical, InnoDB uses intention locks.Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table
既通常情况下,表锁和行锁是相互冲突的,既获得了表锁,就无法再获得该表具体行的行锁,反之亦然。但是有的时候表锁和行锁实现部分的共存有利于更细粒度的对锁进行控制,以便得到更加的并发性能。所以InnoDB存储引擎支持多粒度(granular)锁定, 这种锁定允许一个事务中同时存在行锁和表锁。
所以InnoDB为了实现行锁和表锁共存的多粒度锁机制特性,InnoDB存储引擎也就还支持一种额外的锁方式以对多粒度锁机制进行支持,称之为意向锁(Intention Lock)。
(二) 什么是意向锁呢?
- 意向锁(Intention Lock)就是一种不与行级锁冲突的
表级锁(重点!!) - 意向锁的主要目的展示出某事务已对表中某行加锁,或即将对表中某行加锁
- 意向锁就是指,未来的某个时刻,事务可能要对某行加共享锁或排它锁了,先提前声明一个意向
《MySQL技术内幕》
若将上锁对象看作成一颗树,那么对最下层的对象进行加锁,也就是对最细粒度的对象加锁,那么首先就需要先对上层的粗粒度的对象进行上锁。
并且意向锁具体实现又可以分为以下两种:
意向共享锁(intention shared lock,IS)
事务打算给表中的某些行加行级共享锁,事务在给某些行加S锁前必须先取得该表的IS锁。意向排他锁(intention exclusive lock,IX)
事务打算给表中的某些加行级排他锁,事务在给某些行加X锁前必须先取得该表的IX锁。
总之所谓意向锁,就是提前表明了一个要加行锁的“意向”。当某表存在排他意向锁时,代表该表的某行可能存在行级排他锁。同理当某表存在共享意向锁时,代表该表的某行可能存在行级共享锁
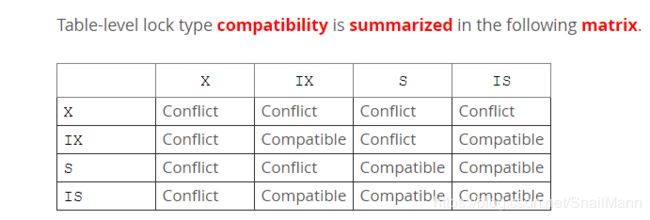
(三) 意向锁的兼容性
| 标题 | 意向共享锁(IS) | 意向排他锁(IX) | 表级共享锁(S) | 表级排他锁(X) |
|---|---|---|---|---|
| 意向共享锁(IS) | 兼容 |
兼容 |
兼容 |
不兼容 |
| 意向排他锁(IX) | 兼容 |
兼容 |
不兼容 | 不兼容 |
| 表级共享锁(S) | 兼容 |
不兼容 | 兼容 |
不兼容 |
| 表级排他锁(x) | 不兼容 | 不兼容 | 不兼容 | 不兼容 |
- 意向锁是一个比较弱的锁,所以意向锁之间互不排斥
意向锁因为是表级的锁,本身就是为了解决行表锁的共存,所以它是不会与行锁产生冲突的。所以上表的兼容性指代的是意向锁和表级共享锁,表级排他锁的兼容性。有一些书倒是没有指明这点, 比如《MySQL技术内幕》甚至还表明上表是意向锁和行锁的兼容性展示,我个人认为是错误的描述,证明可以看官网Intention Locks中有一句对该表的描述“Table-level lock type compatibility is summarized in the following matrix”
(四) 怎么使用意向锁?
- 意向锁的维护是由存储引擎隐式帮我们做了,不需要程序员操心!
- 既意向锁是由存储引擎自己维护的,用户无法手动操作意向锁,在为数据行加共享 / 排他锁之前,InooDB 会先获取该数据行所在的表的对应意向锁
(五) 详细的说说意向锁有什么作用?
意向锁好处之一
举个应用场景的粟子@发条地精
- 事务A向student表申请某一行记录的X锁(行级)。
- 事务A申请完毕后,事务B向student表整个表的X锁(表级)
- 因为事务A已经获得了student表中某行的行级X锁,所以数据库需要阻塞事务B的表级X锁申请,直到事务A释放了行级X锁
.
那么数据库如何去判断这个冲突呢?分两步,第一步OK才继续下一步
- (1)判断student表是否已经让其他事务获得了表锁?
- (2)判断表中的每一行是否已经让其他事务获得了行锁?(本质应该是遍历索引项)
.
从上两个判断,我们就可以得知,表锁和行锁是互不兼容的,不能共存的,这是其一。在不存在表锁的情况下,我们就会到步骤二中一行行的判断是否存在行锁,这样的效率是十分低下的。如果意向锁存在的话,那么步骤如下
- (1)判断student表是否已经让其他事务获得了表级X,S锁?
- (2)判断该表是否存在意向IS,IX锁,如果有意向锁,说明表中存在行锁,所以阻塞事务B的表级X锁申请
.
所以我们知道存在意向锁时,判断冲突步骤就会变得很快了,因为避免了需要逐行判断是否有行锁。
- 既意向锁是在添加行锁之前添加的。当另一个事务再向表中添加表级X锁的时候,如果没有意向锁的话,则需要遍历整个表的行去判断是否有行锁的存在,以免发生冲突,逐行遍历,效率低下。
- 如果有了意向锁,只需要判断该意向锁与即将添加的表级锁是否兼容即可。因为意向锁的存在代表了,有行级锁的存在或者即将有行级锁的存在。因而无需遍历整个表,即可获取结果,提高了判断锁兼容性的效率,这是意向锁存在的好处之一
- 引用至InnoDB 的意向锁有什么作用?- 知乎 (推荐!!)
意向锁好处之二
(1)事务A向student表申请某个行记录的S锁(行级),所以首先要为student表上IS锁。
(2)事务A获得锁完毕后,事务B向student表申请全表的S锁(表级)。于是数据库开始锁冲突的判定
(3)数据库首先判断事务B申请表锁前,student表是否已经存在表级S,X锁,发现没有
(4)数据库再判断student是否已经存在意向锁IS,IX,然后发生之前有事务A申请过IS锁
(5)根据表级S锁和意向IS锁的兼容性策略,两者是兼容的。所以事务B直接就获得对student表的表级S锁
(6)此时student表已经共存了表级S锁和行级S锁。
所以意向锁的出现也让表锁和行锁得到一定的共存,提供了部分的并发性能!
(五) IX,IS与表级X,S与行级X,S锁的关系
这里有一个小例子
(1) 事务A向student表申请a行的行级S锁,所以存储引擎自动为该表先加上IS锁
(2) 事务B向student表申请全表的表级X锁,因为表级X锁与IS锁不兼容,所以事务B的表级X锁申请被事务A阻塞
(3) 事务C向student表申b行的行级X锁, 所以存储引擎自动为该表先加上IX锁。因为IX锁和IS锁是互相兼容的,且事务A与事务C针对的行记录不同,所以事务C成功获得行级X锁
从上面的例子中,我想应该也大致的让大家感受到意向IX,IS锁与表级X,S锁与行级X,S锁之间的关系了
InnoDB下的记录锁,间隙锁,临键锁
我们的行锁根据锁的粗细粒度又可以分为三种锁,既记录锁,间隙锁和临键锁

(一) 什么是记录锁?
MySQL官网 - Record Lockl
A record lock is a lock on an index record. For example,SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE;prevents any other transaction from inserting, updating, or deleting rows where the value of t.c1 is 10.
记录锁(Record Lock)就是我们最单纯认知的行锁,既只锁住一条行记录,准确的说是一条索引记录。
InnoDB的行锁是依赖索引实现的,而其锁住某行数据的本质是锁住行数据对应在聚簇索引的索引记录。
- 例如某个事务执行了
select * from t where id=1 for update;语句,就相当于它会在id = 1的索引记录上加上一把锁,以阻止其他事务插入,更新,删除id = 1的这一行。
此行锁非彼行锁
通常字面意思的行锁,代表对一行记录加锁。但行锁实际是一个抽象,我们平时所说 行锁(1) 还分记录锁,间隙锁(Gap Lock),临键锁(Next-Key Lock)等具体的实现,但我们通常意义上单纯的 行锁(2) ,实际说的就是记录锁; 既此 行锁(1) 非彼 行锁(2),行锁(1) 更倾向是一个锁分类,代指一系列行锁 。行锁(2) 更接地气,更单纯,就是指锁单条记录的意思,随意不同场景,不同语义下,所代表的意思可能有些许不同;但通常情况下,都会被混在一起,所以也不用太介意,自己要清楚就好
(二) 什么是间隙锁?
A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. For example,
SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE;prevents other transactions from inserting a value of 15 into column t.c1, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.
间隙锁(Gap Lock),顾名思义,它会封锁索引记录中的“缝隙”,不让其他事务在“缝隙”中插入数据。 它锁定的是一个不包含索引本身的开区间范围 (index1,index2)。间隙锁是封锁索引记录之间的间隙,或者封锁第一条索引记录之前的范围,又或者最后一条索引记录之后的范围
说白了,间隙锁的目的就是为了防止索引间隔被其他事务的 “插入”。 间隙锁是InnoDB权衡性能和并发性后出来的特性。
-
间隙锁之间是互相兼容的,既不同事务的Gap锁是可以共存的,可以存在重合区域或是完全重合。多个事务的Gap锁重合代表多个事务都想阻止其他事务往该索引间隙
"插入"数据。也因为Gap一次就对插入行为锁住了一片的区域,不利于多事务并发写。所以后续MySQL也就提供了一种特殊的间隙锁(插入意向锁),以解决并发写的问题 -
间隙锁实际也分共享间隙锁,排他间隙锁,虽然有分类,但事实上他们的意义是等价毫无区别的,所以可以忽略这一层,只要知道它们的作用都是阻止其他事务往间隙插入数据。
-
间隙锁只发生在事务隔离级别为RR(
Repeatable Read)的情况下,它用于在隔离级别为RR时,阻止幻读(phantom row)的发生;隔离级别为RC时,搜索和索引扫描时,Gap锁是被禁用的,只在外键约束检查和 重复key检查时Gap锁才有效,正是因为此,RC时会幻读问题。 -
比如某个事务执行
select * from table where id between 10 and 20 for update;语句,当其他事务往表里“插入”id在(10,20)之间的值时,就会被(10,20)的间隙锁给阻塞
(三) 什么是临键锁?
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
临键锁(Next-Key Lock)其实并不能算是一把新的行锁,其实际就是记录锁(Record Lock)和间隙锁(Gap Lock)的组合,既封锁了"缝隙",又封锁了索引本身,既组合起来构成了一个半开闭区间的锁范围。既临键锁锁的是索引记录本身,以及索引记录之前的间隙(index1, index2]
比如某表有4行数据,主键分别为10,11,13,20。那么该表可能存在的临键锁锁住聚簇索引的区间如下
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)
每两个索引项之间就是一个next key锁区域,通常规则是 左开右闭 ,除了最后一个锁区间,是全开区间,代表锁住索引最大项之后的区域
(四)记录锁,间隙锁,临键锁的关系
我们知道InnoDB的行锁默认是基于B+Tree的。所以行锁依赖的索引是有序的。
- 记录锁就是单纯意义上的行锁,锁的就是单行数据,该数据是
真实存在的 - 而间隙锁则是锁住一个区间中多行数据,但这些多行的数据实际是
并不存在的。既只锁住真实数据对应索引项之间的一个空间范围 - 而临键锁说白了就是记录锁+间隙锁的组合。只要把记录锁和间隙锁组合在一起,就是临键锁,既锁住索引项本身的真实数据,又锁住两两索引之间没有数据的空间范围。
(五) 排他,共享锁与记录锁,间隙锁,临键锁的关系
的确,我们一直都说行锁是一个抽象,只代表在行层级对数据进行锁定。我们也说行锁实际有具体的实现,比如排他锁和共享锁。为什么这个时候又冒出了一些记录锁,间隙锁,临键锁的概念?!这是在懵我读书少吗?
其实排他锁,共享锁与记录锁,间隙锁,临键锁本不应该混淆在一起的,因为他们虽然都属于行锁的范畴,但却是不同维度(角度)的概念。
排他锁和共享锁的概念,注重是从行锁的功能性角度分类 ,强调的是这把行锁,允不允许被其他事务所共享,更像是描述该锁的功能模式特性记录锁等概念,注重的是从行锁的锁粒度角度分类,强调的是这把行锁,锁的是单行,还是锁的一个行区间范围,更像是描述这把锁的锁范围
所以它们只是不同角度分类下的概念,比如我们可以这么认为,如果一把行锁在锁粒度上的实现是一个记录锁,那么该行锁就是一把记录锁,而这个记录锁在功能上的实现是一把共享锁,那么这把记录锁就是一把共享锁。在这个角度上分析,此时这把行锁即是记录锁,也是共享锁。
InnoDB下的插入意向锁
(一) 什么是插入意向锁?
之前,我们学习了什么是意向锁,IS,IX的其中一个好处是兼容行级S锁和表级S锁,做到真正的读读共享。那什么是插入意向锁呢?插入意向锁一种特殊的间隙锁,属于行锁。其实插入意向锁的好处也类似,但要做到的功能并非读读共享,而是针对某个区间范围做到写写共享,但这个写写并非对同一行记录而言,而是针对某个区间范围内的写入可以并发执行,只要写入的并非同一索引项(行)。
说白了,就是插入意向锁允许多个事务的插入写操作在某个索引区间无需等待的并发执行,只要操作的不是同一行的数据
(二) 插入意向锁和意向锁的关系
- 可以说是完全没有关系,唯一的关系最多都表名一个意向。 虽然插入意向锁也表示插入的意向,但是它跟IX,IS是完全不一样的。
- 另外意向锁(IS,IX)是表级锁,而插入意向锁实际是行级锁
- 插入意向锁并不属于意向锁,而实际是一种特殊的间隙锁
(三) 插入意向锁和Gap锁的关系
相同点
- 插入意向锁是一种特殊的Gap锁,而原Gap锁相对而言就是普通的Gap锁
- 插入意向锁和普通Gap锁针对S,X的分类,都一样,都是属于等价的,所以对Gap锁而言,S,X的分类是没有意义的。
- 插入意向锁和普通Gap锁都对彼此相互不兼容。既插入意向锁锁的间隙和普通Gap锁锁的间隙不同有重合,否则会阻塞
不同点
- 普通Gap锁的目的是为了防止其他事务对锁间隙的插入行为。作用之一就是避免了在RR级别下幻读行为
- 而插入意向锁的目的是替换插入行为产生的普通Gap锁(因为普通Gap锁不支持多事物对同一间隙进行插入) ,其中最大的作用是允许多事务在锁间隙内并发写入
(四) 插入意向锁兼容性
以下我们来说说插入意向锁的兼容性
兼容性
| 标题 | 插入意向锁 | Gap锁 |
|---|---|---|
| 插入意向锁 | 兼容 |
不兼容 |
| Gap锁 | 不兼容 | 兼容 |
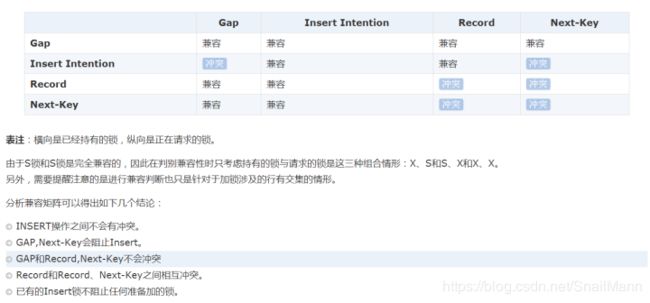
- 因为插入意向锁是特殊的Gap锁,锁的也是间隙,所以插入意向锁不与记录锁有任何冲突,因为一个锁的是索引,一个锁的是索引之间的间隙。插入意向锁跟临键锁的兼容就跟Gap锁一样,因为临键锁的组成部分就有Gap锁
- 插入意向锁和插入意向锁之间是相互兼容的,普通Gap锁与普通Gap锁之间也是相互兼容的。但是插入意向锁和Gap却是不兼容的。既如何某个事务A先获得了一个Gap锁,事务B插入新行,获得了插入意向锁。如果两者之间的间隙有重合,那么事务B的插入意向锁则会被事务A的Gap锁阻塞
(五) 插入意向锁的作用?以及为何替代Gap锁
我们已经知道了插入间隙锁最主要的作用就是站在多事务操作的不是同一行数据的基础上,可以让某个索引区间范围做到并发的插入写操作。 那么为什么又拿插入意向锁这种特殊的Gap锁去代替普通Gap锁呢?这是有什么独特之处吗?
1. 在了解插入意向锁作用之前,你得明白事务的插入行为会造成什么?
- 我们肯定简单的知道,当某个事务插入一个新行时,肯定要获取对该行的排他记录锁。看上去好像没有毛病。问题是,在新行没有生产前,怎么获取对该新行的排他记录锁? 明显就不能嘛,所以一个插入行为,在获取对新行的排他记录锁之前,我们需要先获取新行所在的索引区间的锁,既间隙锁。
- 既一个插入单行数据的行为,必须先获得一个粗粒度的锁,才能安全的保证新行生成前,没有其他事务插入同样的新行(避免冲突)。
间隙锁在这里的作用就是阻塞企图在该索引间隙中插入数据的其他事务。
2. 所以我们明白了,一个插入行为,必须要先获得粗粒度的间隙锁,才能保证生成新行,再获取细粒度该行的排他记录锁。
- 但是因为普通的Gap锁一旦锁住了某个间隙,这个间隙就不再允许其他事务插入数据了。既其他事务需要等待当前事务释放该区间的Gap锁后,才能插入数据。所以我们可以知道,因为Gap锁对插入行为的相对锁粒度比较大,就不利于提高多事务对同一个索引间隙的数据插入性能了。
- 说白了就是普通Gap锁一次就锁一个区间,如果多事务比如成多线程,那么这些多线程在执行Gap锁间隙的插入行为就是同步的。
- 而插入意向锁就不一样了,插入意向锁虽然跟Gap锁一样,一次锁的是一个区间。但是它可以允许多个事务在这个区间内执行不同数据的插入,互不干扰。
- 举个小例子,如果一张表有两行记录,主键是1和10,此时有5个并发事务准备在(1,10)区间内插入5条不同主键的数据,每次插入需要1s的时间消耗。如果插入行为提前获取的粗粒度锁是普通Gap锁,那么耗时就是5s, 如果是插入意向锁,那就是1s。这个时间开销显而易见
综上,在插入行为方面,Gap锁在这方面的功能最终是被插入意向锁所代替的,插入意向锁就是为了改善Gap锁在数据插入方面的同步开销而引入的特殊Gap锁
论 MySql InnoDB 如何通过插入意向锁控制并发插入 - @作者:Gtakerlv
Locks Set by Different SQL Statements in InnoDB - @MySQL 官网
相关问题
验证索引与锁之间的"锁哪里"关系
我们都知道InnoDB的行锁是基于索引实现的,就比如记录锁实际锁的并不是数据行,而是数据行对应的索引记录。说是这么说,但是“行锁,锁的是索引记录”这句话到底要怎么理解呢?
我们知道一个表,可以有多个索引,每个索引都有对应行记录的索引记录。那么行锁要对一行数据加锁,锁的到底是哪个索引中的索引记录呢?
(1) 我们假设一张student表,sid是主键索引,name是唯一索引,tel和email是组合索引。
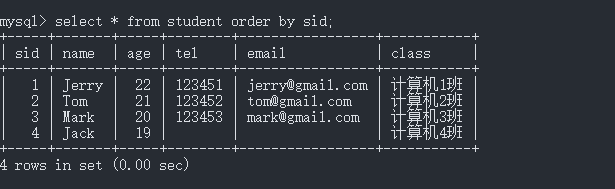
(2) 首先事务A执行select * from student where sid = 1 for update ,未提交事务。 对student执行了查询,where条件是一个主键,同时我们为该表上X锁for update。本质上就是给student表中sid = 1的行数据上行级排他锁
(3) 然后事务B执行select * from student where age= 22 for update, 未提交事务。同样student表进行查询,where条件是一个普通索引列。事务A和事务B其实查询的都是同一条行记录,但分别的where条件则是两种索引列
(4) 因为事务A给行数据加了排他锁,事务B后面又给同一条行记录加排他锁,因为事务A还没有提交事务,所以事务B自然就被阻塞了。此时我们执行select * from infomation_schema.innodb_locks,来看一下当前存储引擎下的加锁状态。会发现行锁是一个记录锁,锁的是PRIMARY索引,代表的就是主键索引

(5) 此时我们将两个事务都rollback一下。删除主键索引,让student此时只剩下name唯一索引,tel,email的组合索引。 重复步骤2和3 ,然后再看看加锁状态。发现此时行锁所锁的索引变成了以name列生成的唯一索引

(6) 此时我们将两个事务都rollback一下。再删除唯一索引name,让student此时只剩下tel,email的组合索引。 重复步骤2和3 ,然后再看看加锁状态。发现此时行锁锁的不是tel,name的组合索引,而是InnoDB内部生成的隐式索引GEN_CLUST_INDEX

所以我们可以得出结论,行锁是基于聚簇索引实现的,不管该表存在多少个索引,行锁所锁的索引记录都是属于该表的聚簇索引的,既InnoDB的行锁锁住某行数据的本质是锁住行数据对应在聚簇索引的索引记录 。 既当存在主键时,主键索引就是聚簇索引,当没有主键时,顺位第一个唯一非空列建立的索引就是聚簇索引,以上都不满足时,InnoDB就会启动内部生成隐式主键索引作为聚簇索引。
想想也是,InnoDB一个表的数据本身就是存储在该表聚簇索引的叶子结点上。锁住某行数据的另一个含义不就是锁在聚簇索引的叶子结点的索引记录上嘛,其实两者也没有太大区别啦。只是之前我考虑该问题的思维,并没有跳到聚簇索引身上,而是在主键索引,唯一索引,普通索引这一分类的维度上纠结。
参考资料
- 《MySQL技术内幕》
- InnoDB Locking | MySQL 8.0 - @作者:官方
- 数据库两大神器【索引和锁】 - @作者:Java3y
- 秒懂INNODB的锁 - @作者:RyuGou
- 详解 MySql InnoDB 中的三种行锁(记录锁、间隙锁与临键锁)- @作者:Gtaker
- 秒懂InnoDB的锁 - @作者:RyuGou
- InnoDB并发插入,居然使用意向锁? - @作者:58沈剑
- InnoDB 的意向锁有什么作用?- 知乎 (推荐!!)
- 关于关于mysql一些锁问题的总结 - @作者:arthur376
- MySQL InnoDB锁介绍及不同SQL语句分别加什么样的锁 - @作者:知音小助手(推荐!!)
- 如果觉得对你有帮助,能否点个赞或关个注,以示鼓励笔者呢?!