JDK,hessian序列化源码分析
分析 dubbo 序列化实现
选中几个协议分析 源码 必选 msgpack hessian.
主流 序列化协议性能对比
先找个简单的分析FastJsonSerialization
public class FastJsonSerialization implements Serialization {
@Override
public byte getContentTypeId() { //获取协议ID
return 6;
}
@Override
public String getContentType() {//协议类型
return "text/json";
}
@Override
public ObjectOutput serialize(URL url, OutputStream output) throws IOException {
return new FastJsonObjectOutput(output);//创建ObjectOutput
}
@Override
public ObjectInput deserialize(URL url, InputStream input) throws IOException {
return new FastJsonObjectInput(input);//创建ObjectInput
}
用到 serialize的位置如下
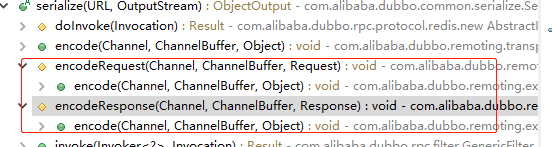
以encodeRequest为例
执行 序列化的地方
encodeRequestData(channel, out, req.getData());
protected void encodeResponseData(ObjectOutput out, Object data) throws IOException {
out.writeObject(data);
}
最后序列化调用的是 ObjectOutput.writeObject(data);对应 fastjson类型 就是FastJsonObjectOutput.writeObject(data);
Serialization.deserialize 在 DecodeableRpcResult.decode(Channel, InputStream) 中调用
Type[] returnType = RpcUtils.getReturnTypes(invocation);
setValue(returnType == null || returnType.length == 0 ? in.readObject() :
(returnType.length == 1 ? in.readObject((Class) returnType[0])
: in.readObject((Class) returnType[0], returnType[1])));
对应 fastjson类型 就是FastJsonObjectInput.readObject()
下面需要搞清楚 FastJsonObjectOutput.writeObject(data); FastJsonObjectInput.readObject()都干了什么
先画出 类图
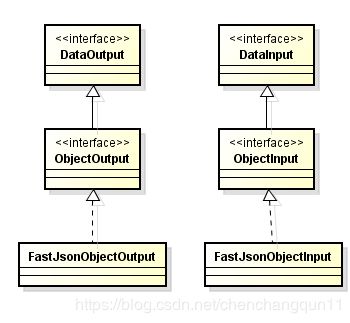
DataOutput: 与OutputStream 定义相似,定义了 写入基本类型,String, byte[] 和flushBuffer 方法。
DataInput:与InputStream定义相似,定义了 读出基本类型,String, byte[]方法
ObjectOutput:定义了写入 Object的方法
ObjectInput:定义了读出Object的方法, 无参数读出Object, 根据Class读出Object,根据Class和Type读出
FastJsonObjectOutput.writeBool(boolean)
public void writeBool(boolean v) throws IOException {
writeObject(v);
}
FastJsonObjectOutput.writeObject(Object)
使用FastJson完成序列化
public void writeObject(Object obj) throws IOException {
SerializeWriter out = new SerializeWriter();
JSONSerializer serializer = new JSONSerializer(out);
serializer.config(SerializerFeature.WriteEnumUsingToString, true);
serializer.write(obj);
out.writeTo(writer);
out.close(); // for reuse SerializeWriter buf
writer.println();//注意 这里写入了换行符
writer.flush();// 最后调用 ByteArrayOutputStream 的flush(),啥也没干
}
dubbo java序列化
JavaObjectOutput
public void writeObject(Object obj) throws IOException {
if (obj == null) {
getObjectOutputStream().writeByte(0);
} else {
getObjectOutputStream().writeByte(1);
getObjectOutputStream().writeObject(obj);
}
}
NativeJavaObjectOutput
public void writeObject(Object obj) throws IOException {
outputStream.writeObject(obj);
}
JavaObjectInput
public Object readObject() throws IOException, ClassNotFoundException {
byte b = getObjectInputStream().readByte();
if (b == 0)
return null;
return getObjectInputStream().readObject();
}
NativeJavaObjectInput
public Object readObject() throws IOException, ClassNotFoundException {
return inputStream.readObject();
}
JavaObjectOutput,JavaObjectInput在原生 的基础上 增加了对null对象的处理
JDK序列化分析
序列化
被序列化的Object中的 Object属性必须实现 Serializable接口,否则报异常, 基本类型默认可以序列化。static 和transient关键字修饰的变量不会被实例化
父类A没有实现Serializable 接口,子类B实现了Serializable 接口, A a=new B() 此时A可以序列化
A a=new A() 此时 B不可以序列化,也就是 被序列化的是指向的是实现了 Serializable 接口的实例才可以。
父类A没有实现Serializable 接口,子类B实现了Serializable 接口 序列化类B的实例,不会序列化父类A,就是 父类实例的数据不会被写入,反序列化后 获取不到父类的数据。 反序列化会调用 父类无参的构造方法。
序列化格式
先写类描述 包含类,序列化id,所有字段的描述,数据
字段描述:类型简写1个byte 字段名 类型描述 (Object类型需要写类型描述,如Ljava/lang/String)
name SerialVersionUID flags 字段列表描述
TC_OBJECT=115 TC_CLASSDESC=114
TC_OBJECT TC_CLASSDESC com.changqun.demo.serialization.Worker 1 2 I age L name Ljava/lang/String; 120
没有父类写入空标识 112,如果有父类,先写子类描述,后写父类描述,迭代调用直到找不父类。如此完成所有父类描述的写入
数据部分 先写 基本类型,后写Object类型。
计算出所有基本类型字段的总长度,单位 byte, 创建一个这个长度的byte数组,将这些字段的值存入。
(这里面的字段应该有默认顺序,否则无法解析,这个顺序是什么,有待研究。)
Object 如果是String,isArray,Enum按照固定格式写入,否则必须实现Serializable ,调用写入Object方法(相当于迭代调用)。
ObjectOutputStream.writeObject0(Object, boolean) line: 1168
//String 类型 先写长度再写值
writeString((String) obj, unshared);
有父子类关系的 先写父类数据,后写子类数据
集合类型字段的写入
把集合类型当做Object 类型 迭代调用ObjectOutputStream.writeObject0(Object, boolean)
使用反射调用 了HashMap writeObject方法 ,ArrayList也是如此。
ObjectStreamClass.lookup(Class, boolean) line: 357
//这里创建并缓存了 类结构辅助类。
try {
entry = new ObjectStreamClass(cl);
} catch (Throwable th) {
entry = th;
}
if (future.set(entry)) {
Caches.localDescs.put(key, new SoftReference
}
写入和解析基本类型
共同步骤:解析出 字段个数,每个字段在对象内位移值,每个字段相对应存值数组的开始位置,每个字段的类型。
写入基本类型字段过程
解析的时候根据固定顺序读出字段在对象内位移值,字段相对应存值数组的开始位置,字段的类型 ,根据不同的类型 unsafe.getXXX获取值,Bits.putChar写入(boolean类型 buf[off] = unsafe.getByte(obj, key))。
解析基本类型字段过程
解析的时候根据固定顺序读出字段在对象内位移值,字段相对应存值数组的开始位置,字段的类型 ,根据不同的类型 Bits.getXXX获取值 Unsafe.putXXX赋值。
创建对象调用 class.getInstance()
反序列化
先解析描述,后解析数据
流程基本与序列化顺序一致,不同的是 代表类结构信息的 ObjectStreamClass是从序列化的后的数据读出并解析后创建。,而序列化过程中ObjectStreamClass是解析对象类创建的
注意JDK 的反序列化 只有 result= input.readObject(); 没有可以传入参数类型的
如果是对象字段,迭代调用。
Object是主要的读取流程, 如果是String,Array,Enum按照固定格式读取。
Hessian序列化
序列化
序列化结果如下

序列化格式:MT 0 类全名长度 类全名 [字段列表] 结束标志 z(小写)
字段列表:字段名 字段类型 字段值
Int类型 字段类型 I 字段值 int类型 32位, 存储 前8位,前16位,前24位,后8位
String类型 字段类型 S 长度前24位 完整长度 s
UnsafeSerializer.writeObject10(Object, AbstractHessianOutput) line: 187
protected void writeObject10(Object obj, AbstractHessianOutput out)
throws IOException
{
for (int i = 0; i < _fields.length; i++) {
Field field = _fields[i];
out.writeString(field.getName());//字段名
_fieldSerializers[i].serialize(out, obj);//字段值
}
hessian1 中字段名 字段类型 字段值是个联系并循环的顺序。
序列化流程如下图
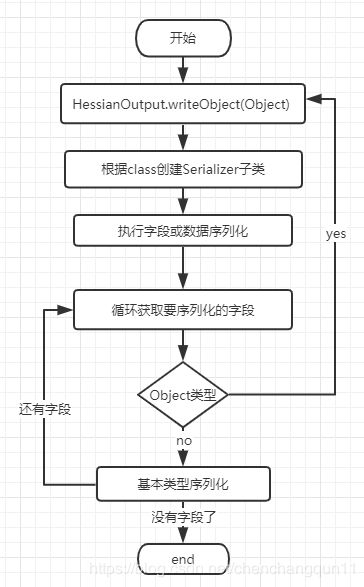
第一次serializer.writeObject(object, this) serializer 类型是UnsafeSerializer(执行Object 所有字段的序列化,其中Object 类型的字段 迭代调用 out.writeObject(value);)。
过程中会创建_fieldSerializers,其中的每一个元素都是FieldSerializer的子类,解析 字段生成的 。这个数组非常重要,字段的写入就是完全调用其write方法 完成的。
以后写Object 类型会创建不同的Serializer子类,如MapSerializer。
创建 get set 都使用了unsafe.
protected Object instantiate()
throws Exception
{
return _unsafe.allocateInstance(_type);
}
每一个类型都有独立的序列化类,都实现了FieldSerializer
包括基本类型 Boolean Byte Char Double Float Int Long Short
Object类型:Object String Date
其中 ObjectFieldSerializer serialize 调用 out.writeObject(value);
Date类型实现: 存储时间戳
out.writeUTCDate(value.getTime());
public void writeUTCDate(long time)
throws IOException
{
os.write('d');
os.write((byte) (time >> 56));
os.write((byte) (time >> 48));
os.write((byte) (time >> 40));
os.write((byte) (time >> 32));
os.write((byte) (time >> 24));
os.write((byte) (time >> 16));
os.write((byte) (time >> 8));
os.write((byte) (time));
}
注意如果有多个 Object字段 会创建多个 ObjectFieldSerializer。
有些类型使用了比较大的类型存储,如char 调用writeString short调用WriteInt float 调用writeDouble
不知原因。
生成的Serializer子类会被缓存。
Map类型:MapSerializer 执行serializer.writeObject(object, this); 格式: M T null [key value]列表
List类型:CollectionSerializer执行serializer.writeObject(object, this); 格式:V l 4字节长度 [value]列表
写入的类名 读出后 用于创建 类结构解析器Deserializer,字段解析器, 创建 Object实例
创建Objects使用了_unsafe.allocateInstance
protected Object instantiate()
throws Exception
{
return _unsafe.allocateInstance(_type);
}
反序列化
创建对象 set 各个类型value 都使用了unsafe.
与序列化相同 多个类型都实现了FieldDeserializer2,还多了 SqlDate SqlTimeStamp类型实现.
创建FieldDeserializer2子类的逻辑
当前类作为初始值,循环后获取父类作为当前类
获取当前类的declaredFields,循环创建 FieldDeserializer2子类,如果是静态或者是transient 类型则跳过。(declaredFields数组的顺序按照字段在对象内书写顺序,创建的子类数组中,前面是子类的字段,后面是父类的字段)
细节: 传入field获取字段offset.
以IntFieldDeserializer为例
IntFieldDeserializer
IntFieldDeserializer(Field field)
{
_field = field;//save field
_offset = _unsafe.objectFieldOffset(_field);//获取字段offset
}
public void deserialize(AbstractHessianInput in, Object obj)
throws IOException
{
int value = 0;
try {
value = in.readInt();//读取 特定类型值
_unsafe.putInt(obj, _offset, value);// 为对象字段赋值。
} catch (Exception e) {
logDeserializeError(_field, obj, value, e);
}
}
}
序列化和反序列化创建的Serializer,Deserializer子类都会被缓存。
hessian2序列化
格式:C0 类全名长度 类全名 字段长度 字段名列表 [字段值列表] 结束标志 z(小写)
字段值列表: 字段类型 字段值
byte范围:-128 到 127
相比hessian改进点
- 序列化后的byte值先缓存起来,后面一次性写入
- 优化数值类型的存储格式,尽量使用少的byte存储。
数值类型中为实现尽量使用少的byte存储,使用了阀值。
如果不使用阀值 当读取一个byte后无法是否还需要再读取后面的byte来拼接数值。
写字段定义
字段个数 [字段字符串列表]
字段字符串: 为空 写N,长度,字符数组。
长度:int 类型 根据大小 使用 1~3个字节存储 长度小于等于31,占一个字节。 长度小于等于1023,占2个字节,长度大于1023 第一个字节写 大写字母 S 值,后面2字节写长度
字符: 根据字符值大小 使用 1~3个字节存储
知识点:
ASCII:定义了 包含英文字母,数字,各种常用符号 128个字符。
字符值在 128以内(不含128)都用1个字节存储。
有些语言一个字符值范围不够 如法语,汉字(汉字占2字节)