文档布局分析 & 扭曲文档图像恢复

向AI转型的程序员都关注了这个号????????????
机器学习AI算法工程 公众号:datayx
对文本进行OCR前,必须分析和定义文档的逻辑结构。例如文本块、段落、行的位置;是否有应该重建的表格;是否有“图像”“条形码等”。
文档布局分析 (Document Layout Analysis) 是识别和分类文本文档的扫描图像中的感兴趣区域(RoI, Regions of Interest) 的过程。阅读系统需要从非文本区域分割文本区域,并按正确的阅读顺序排列。将文本正文,插图,数学符号和嵌入文档中的表格等不同区域(或块)的检测和标记称为几何布局分析。但文本区域在文档中扮演不同的逻辑角色(标题,标题,脚注等),这种语义标记是逻辑布局分析的范围。
文档布局分析是几何和逻辑标签的结合。它通常在将文档图像发送到OCR引擎之前执行,但也可用于检测大型存档中同一文档的重复副本,或者通过其结构或图示内容索引文档。
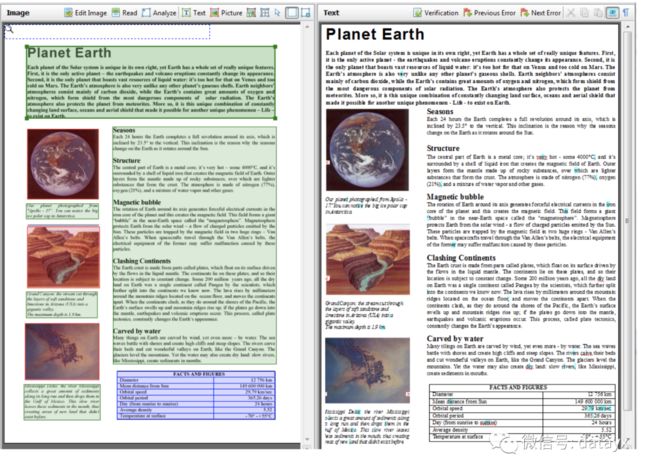
最早的算法实现 docstrum
1993年,O’ Gorman 在TPAMI中发表了自下而上的文档布局分析算法docstrum,首先将文档解析为黑白连接区域,然后将这些区域分组为单词,然后分为文本行,最后分组为文本块。
简单翻译了一下它的算法(english version):
https://en.wikipedia.org/wiki/Document_layout_analysis
算法开始的字母代表着原始论文中每小节的标题序号。原始论文中,每个小节的标题如下:
B. Preprocessing
C. Nearest-Neighbor Clustering and Docstrum Plot
D. Spacing and Initial Orientation Estimation
E. Determination of Text Lines and Accurate Orientation Measurement
F. Structural Block Determination
G. Filtering
H. Global and Local Lay-out Analysis
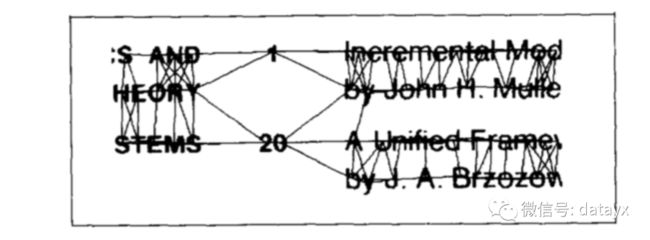
B预处理图像以去除高斯噪声和椒盐噪声。(某些噪声消除滤波器可能会将逗号和句号视为噪声,因此必须小心谨慎)B将图像二值化B将图像分割为黑色像素的连通分量(下文称 Symbol)。对于每个Symbol,计算边框和质心(bounding box, centroid)。C对于每个Symbol,确定其k近邻,且k>=4。( O’Gorman在他的论文中建议将k = 5作为鲁棒性和速度之间的良好折衷。使用至少k = 4的原因是对于文档中的符号,两个或三个最接近的符号是在相同文本行上紧邻的那些符号。第四最近的符号通常在正上方或下方的一条线上,并且在下面的最近邻居计算中包括这些符号是很重要的。)C每个Symbol的近邻对与两者质心的向量相关。如果为每对最近邻Symbol绘制这些向量,则可以得到文档的docstrum(下图)。通过来自水平的角度θ和两个最近邻居符号之间的距离D,创建最近邻角和最近邻距离直方图。D使用最近邻角度直方图,可以计算文档的歪斜。如果歪斜较小,则继续下一步。如果不是,旋转图像以消除歪斜并返回步骤3。D最近邻距离直方图具有若干峰值,并且这些峰值通常表示字符间间距,字间间距和行间间隔(between-character, between-word, between-line)。D标记每个Symbol较远的邻居,该距离在between-character或between-word的某个容差内。对于标记的每个最近邻居符号,绘制连接其质心的线段。E通过线段连接到其邻居的符号形成文本行。对于文本行中的所有质心,可以使用线性回归计算表示文本行的实际线段。(使用线性回归,是因为文本行中Symbol的所有质心都不太可能是共线的。)F对于每对文本行,可以计算它们对应的线段之间的最小距离。如果该距离在步骤7中计算的行间间隔的某个容差内,则将两个文本行分组到相同的文本块中。最后,可以为每个文本块计算边界框,并完成文档布局分析。
两个开源代码
复现了docstrum
https://github.com/chadoliver/cosc428-structor
对前一个开源代码进行了优化
https://github.com/chulwoopack/docstrum
新的研究
60多页Cattoni, Roldano, et al. “Geometric layout analysis techniques for document image understanding: a review.” ITC-irst Technical Report 9703.09 (1998).[IJDAR 2013] Bukhari, S. S., Shafait, F., & Breuel, T. M. Coupled snakelets for curled text-line segmentation from warped document images

[TPAMI 2008] Shafait, F., Keysers, D., & Breuel, T. Performance evaluation and benchmarking of six-page segmentation algorithms

ICIAR 2014 Kassis, M., Kurar, B., Cohen, R., El-Sana, J., & Kedem, K. Using Scale-Space Anisotropic Smoothing for Text Line Extraction in Historical Documents.

DAS 2012 Afzal, M. Z., Kramer, M., Bukhari, S. S., Shafait, F., & Breuel, T. M. Improvements to uncalibrated feature-based stereo matching for document images by using text-line segmentation

ICDAR 2013Bukhari, S. S., Shafait, F., & Breuel, T. M. (2013, August). Towards generic text-line extraction.

Document Dewarping
数据集[CBDAR 2007 dataset]
http://staffhome.ecm.uwa.edu.au/~00082689/downloads.html
[CBDAR 2007] Fu, Bin, et al. “A model-based book dewarping method using text line detection.”
http://www.imlab.jp/cbdar2007/proceedings/papers/P1.pdf
[TPAMI 2012] Meng et al. 2011, Metric rectification of curved document images
http://159.226.21.68/bitstream/173211/3713/1/TPAMI2012.pdf
[PR 2015] Kim et al. 2015, Document dewarping via text-line based optimization
有个同学了复现上面两个算法[githubhttps://github.com/phulin/rebook
[ICDAR 2017] Robust Document Image Dewarping Method Using Text-Lines and Line Segments
https://ieeexplore.ieee.org/document/8270077/authors#authors
[CVPR 2018] DocUNet. A state-of-the-art work from face++ probably, but no source code.
https://www3.cs.stonybrook.edu/~cvl/content/papers/2018/Ma_CVPR18.pdf
Leptonica,很好的库,注释比代码都多。它的dewarping代码貌似是基于textlines的
Python 中使用 tesseract-ocr leptonica [github] [blog]
https://github.com/ybur-yug/python_ocr_tutorial
https://realpython.com/setting-up-a-simple-ocr-server/
开源框架
scantailor 比较古老 可以将拍照的书页自动转换为无卷曲的扫描书页
https://github.com/scantailor/scantailor

leptonica 一个古老又顽强的库被Tesseract、OpenCV、jbig2enc依赖,官方有很多例子演示它好玩的算法
http://www.leptonica.com/line-removal.html



OCRopus – A free document layout analysis and OCR system, implemented in C++ and Python and for FreeBSD, Linux, and Mac OS X. This software supports a plug-in architecture which allows the user to select from a variety of different document layout analysis and OCR algorithms.
OCRFeeder – An OCR suite for Linux, written in python, which also supports document layout analysis. This software is actively being developed, and is free and open-source.
阅读过本文的人还看了以下文章:
【全套视频课】最全的目标检测算法系列讲解,通俗易懂!
《美团机器学习实践》_美团算法团队.pdf
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
特征提取与图像处理(第二版).pdf
python就业班学习视频,从入门到实战项目
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
《深度学习之pytorch》pdf+附书源码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
《Python数据分析与挖掘实战》PDF+完整源码
汽车行业完整知识图谱项目实战视频(全23课)
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
笔记、代码清晰易懂!李航《统计学习方法》最新资源全套!
《神经网络与深度学习》最新2018版中英PDF+源码
将机器学习模型部署为REST API
FashionAI服装属性标签图像识别Top1-5方案分享
重要开源!CNN-RNN-CTC 实现手写汉字识别
yolo3 检测出图像中的不规则汉字
同样是机器学习算法工程师,你的面试为什么过不了?
前海征信大数据算法:风险概率预测
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
VGG16迁移学习,实现医学图像识别分类工程项目
特征工程(一)
特征工程(二) :文本数据的展开、过滤和分块
特征工程(三):特征缩放,从词袋到 TF-IDF
特征工程(四): 类别特征
特征工程(五): PCA 降维
特征工程(六): 非线性特征提取和模型堆叠
特征工程(七):图像特征提取和深度学习
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
蚂蚁金服2018秋招-算法工程师(共四面)通过
全球AI挑战-场景分类的比赛源码(多模型融合)
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
python+flask搭建CNN在线识别手写中文网站
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

QQ群
333972581
