HDFS集群搭建,高可用双机热备模式(HA)自动切换,hdfs+zookeeper+journalnode,步骤分步原理详解(适合初学者)
有写的不对的地方,欢迎各位同学评论指正,博主会进行修改。
作者也是初学hadoop,了解各组件的用途,并且项目中有些东西用不到,所以作者用最简化的组件搭建,避免多余资源的浪费,作者最初构想是zookeeper+hdfs搭建一个分布式文件系统,不用yarn和mapReduce,但是由于双机热备需要一个共享资源的目录,所以还是用到了yarn的journalnode。后续会进行详细说明。
作者会针对每一步进行详细说明以及原理解释,还有作者踩过的坑进行说明,不敢兴趣的同学可直接跳过,按步操作也能搭好。
本文中所有组件是用的CDH5.11组件,单独下载,之所以不用CDH安装,是因为,一是为了学习,基础学习才是王道,况且项目需要,hadoop后期需要活用,hadoop学习是必经之路,绕道去学CDH有些浪费时间。二是因为自身发展,计算机之道,学杂了对自身没好处,学习CDH对于作者规划方向帮助不大。三是,作者也曾经常常为了偷懒干活,写过不少简化工作的小工具,其中还有植入后门安装,而CDH虽然主流,它本身的出现就为了用户不用详细理解hadoop而能完成安装的工具,所以作者本能有些抵触使用别人写的工具。废话不多说,下面是作者本次搭建版本。
为了简化说明,下文开始,zookeeper简称ZK,namenode简称NN或nn,datanode简称dn或DN,jouralnode简称JN,secondaryNameNode简称SNN,都是一些主流叫法。
虚拟机----VMware
操作系统 红帽7(red hat 7)
节点说明:三节点,分别为node1,node2,node3。ip分别为,192.168.163.131、192.168.163.130、192.168.163.132(其中:1、node1和node2分别作为NN和DN,node3仅仅作为DN。2、ZK和JN三个节点都有。3、node1和node2上都有SNN,并且互相作为对方的备份,不作为自己的)
zookeeper 3.4.5版本,对应CDH5.11
hadoop 2.6版本,对应CDH5.11
对应CDH版本一致,就不用担心版本兼容问题啦!哈哈哈,作者是不是很狡猾。
2、主机名配置
在我另一篇文章有记载:http://blog.csdn.net/m0_37590135/article/details/73546534
3、ssh免密登录
集群配置所必须的,为了让节点间主节点每次去从节点取数据登录时,不用输入密码,这也在我的另一篇文章有记载,稍后会给出链接
4、zookeeper集群搭建
我另一篇文章也详细介绍了搭建过程:http://blog.csdn.net/m0_37590135/article/details/74024929
5、hadoop集群搭建----即hdfs集群搭建
5.1、下 载
下载地址:https://archive.cloudera.com/cdh5/cdh/5/
5.2、安装
解压安装到指定目录下。tar -zxvf 文件名
5.3、环境变量设置
为了方便后续操作,我们把hadoop安装目录下的bin和sbin一起写入环境变量。使得引用hadoop脚本时候不用给出全路径
[root@node1 local]# vi /etc/profile
5.4、原理说明
下图是zkfc选举以及切换原理:
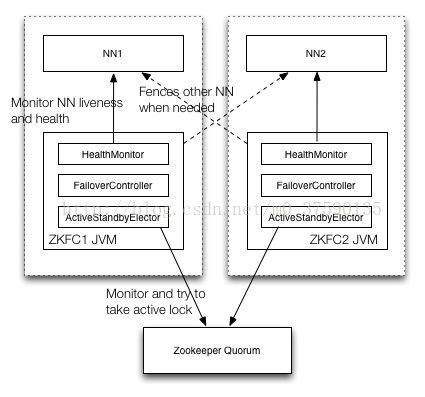
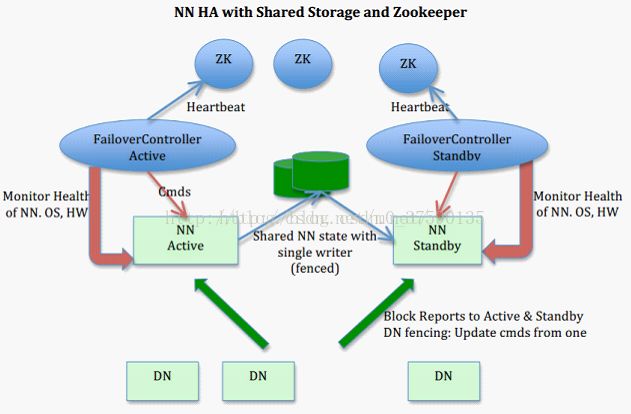
(1)、集群中多个NN,只有一个NN为激活状态
(2)、集群通过ZK来控制NN状态的变更,其中ZKFC也即是ZKFailoverConrroller用来监听心跳和处理(可以把ZKFC组件想象成介于ZK与我们的HDFS集群之间的一个协调的东西)
(3)、为了防止脑裂,集群中多个NN必须共享同一个资源,这里选用JN(博主本来抗拒使用Yarn,所以不使用JN集群。博主想到了通过共享某台服务器指定路径,也能做到,后来想到了NFS搭建。这也是HA模式主流的两种共享资源的方式,一种是JN,一种是NFS。博主想了一下,知道那帮黑帽的可怕。NFS作为最早出现在windows上的工具,被一群人找出很多安全漏洞,可以提权。所以,博主本来就是要模拟生产环境的,只能舍弃这种方式。当然,只是在测试环境玩玩的小伙伴,可以尝试一下这种思路。通过NFS共享)
5.5、配置文件配置
三个配置文件都在“${HADOOP_HOME}/etc/hadoop/”中
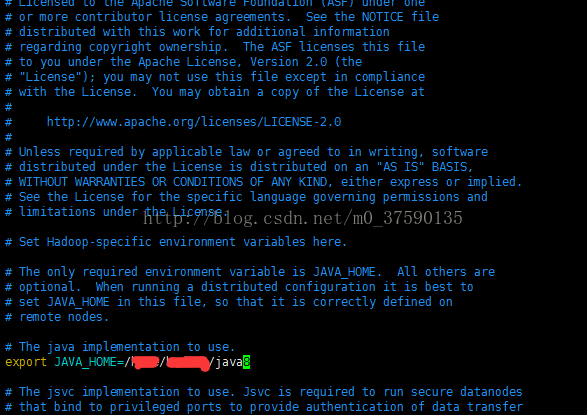
首先是hadoop-env.sh中,JAVA_HOME变量需要手动指定一下路径
其次是core-site.xml,这个是hadoop生态系统中,核心core组件对外提供配置方案的
fs.defaultFS
hdfs://cam/ //这一项必配,需要跟hdfs-site.xml中nameservices选项配套,相当于注册一套hdfs服务
hadoop.tmp.dir
file:/usr/local/hadoop/tmp //这一项没什么用,但还是建议配上,hdfs-site.xml中的nn存放路径和dn存放路径配置时这个不生效,若没配,默认使用这个路径
fs.checkpoint.period
3600
fs.checkpoint.size
67108864
fs.checkpoint.dir
${hadoop.tmp.dir}/dfs/namesecondary
ha.zookeeper.quorum
node1:2181,node2:2181,node3:2181
然后是hdfs-site.xml,这个是hadoop生态系统中,有关hdfs的配置
dfs.nameservices
cam
dfs.http.address
node1:50070
dfs.namenode.secondary.http.address.cam.nn1
node2:50071
dfs.namenode.secondary.http.address.cam.nn2
node1:50071
dfs.ha.namenodes.cam
nn1,nn2
dfs.namenode.rpc-address.cam.nn1
node1:8020
dfs.namenode.http-address.cam.nn1
node1:50070
dfs.namenode.rpc-address.cam.nn2
node2:8020
dfs.namenode.http-address.cam.nn2
node2:50070
dfs.client.failover.proxy.provider.cam
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_dsa
dfs.ha.automatic-failover.enabled.cam
true
dfs.replication
3
dfs.namenode.name.dir
file:/usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/data
dfs.namenode.shared.edits.dir
qjournal://node1:8485;node2:8485;node3:8485/cam
dfs.webhdfs.enabled
true
dfs.journalnode.edits.dir
/usr/local/hadoop-2.6.0-cdh5.11.0/journalNode
====================================================================================================================================
解析:
1、注意服务名与nn命名一一在对应地点对应,我这里是cam,nn1,nn2。可以根据你的喜好任意更改。
2、dfs.ha.fencing.methods选项中,网上很多资料会配成sshfence。跟我不一样,这里我就说一下区别。博主一开始也是配成的sshfence,搭好集群以后,出现这种情况,两个nn一个激活一个standby,当active挂掉以后,另一个nn状态不变,博主重启了挂掉的nn,结果之前的standby激活了,而重启的nn则standby。这不是我们想要的自动切换
原因:这里配置的是zkfc的回调方法,sshfence方式,是当nn1发生异常时,zkfc去停掉nn1,重启为standby,返回一个true再选举一个active。这有一个问题。假设nn1挂掉了,如kill掉,或者关机了,导致无法监听nn1的rpc端口的心跳,sshfence就会一直反复重连nn1的rpc端口,要去关掉人家,造成这样的结果。所以我们直接给定一个true。即是shell(/bin/true)。圆满解决,自动切换
3、关于hadoop.tmp.dir、dfs.datanode.data.dir、dfs.datanode.name.dir选项,最好全都配上,按照博主给定的类似规则。当时博主报了一个每次put就不行的错,找到别的原因解决了,跟hadoop.tmp.dir有没有原因就不得而知了,当时博主后来把这个加上了
4、dfs.namenode.shared.edits.dir选项,配置共享目录。这个必须配,否则两个NN同步时候会失败。一开始博主抗拒jn不使用JN,配了一个本地路径。配置方法,file://路径。结果NN同步成功了,博主很高兴,向下进行时候,两个NN脑裂了。。。数据不一致。。。博主就疯了,这里一定要用一开始讲的JN或者NFS来弄。
原因:通过file配置一个本地路径,每个NN各有一个本地路径,即使两个NN的clusterid一致,同步成功,但每次取时候都是从本地共享目录读取,共享目录内都有自己的规则,取得不是同一个目录。结果大家互相做了什么对方NN都不知道。
5、配置文件中涉及的路径最好都实现建立好,省去未知的麻烦,否则有些路径,你启动过程中会报错
====================================================================================================================================
然后slaves配置文件(这三个配置文件均在同一个目录底下)

里面配置你的DN主机名,一行一个,当然,配IP也没毛病
5.6、启动
后续内容都会附上每步解析,如果不想看解析的,又不会弄的,可以严格按照我的启动顺序操作
a、启动zookeeper和验证,可以在我的另一篇zookeeper集群内得到答案,这里不做过多赘述
b、启动journalnode集群,各个节点上
[root@node1 hadoop]# hadoop-daemon.sh start journalnodec、在node1上:
[root@node1 hadoop]# hdfs namenode -format解析:格式化一个namenode
1、千万别nn1、nn2都格式化,会产生脑裂
2、这是格式化命令,也可以使用hadoop守护进程开启命令进行格式化,效果一样。
[root@node1 hadoop]# hadoop-daemon.sh format namenode
3、如果我这两条命令你都执行不了,报错命令不存在,那就是你PATH变量没有配我的路径,需要hadoop安装路径下,bin和sbin都配上
4、千万别格式化很多次,最后你一定put不进去数据,报错dn没有权限。最后改多次DN权限都没有用,就是这一步不对,如果你已经多次格式化了,那么没关系,请看第五点
5、如果你哪里配错了,想要重来一遍,取消格式化。那么:删除配置文件中指定的name目录以及data目录,再创建。注意,每个节点都要删除
博主的环境是这么做的:
node1和node2上:
rm -rf /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/data/
rm -rf /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/name/
mkdir /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/data
mkdir /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/name
node3上:
rm -rf /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/data/
mkdir /usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/data====================================================================================================================================
d、在node1上
[root@node1 hadoop]# hadoop-daemon.sh start namenode====================================================================================================================================
解析:这条命令是在node1,只启动nn
1、验证,jps查看是否namenode
拓展:另一个命令start-dfs.sh,实际上就是就是依次启动各个节点上的nn,然后dn,最后jn
而这个命令,则是单步操作,也就是说,你分别在node1、node2上
hadoop-daemon.sh start namenode
然后三个节点上均
hadoop-daemon.sh start datanode
最后三个节点上均
hadoop-daemon.sh start journalnode
是一个效果。同理,stop-dfs.sh亦然
====================================================================================================================================
e、node2上执行
[root@node2 local]# hdfa namenode -bootstrapStandby解析:这条命令,在nn2上同步nn1
1、需要先启动nn1,否则同步不了
2、千万不要在nn2上格式化,会put不进去数据,若你做了,请重来
3、也可以把nn1上的上述配置文件下的name路径拷到nn2上,对于博主的环境来说,是这个
/usr/local/hadoop-2.6.0-cdh5.11.0/tmp/dfs/name
若没配,则拷贝,hadoop.tmp.dir的路径,上文有提到。
跟那条同步命令是一样的效果,但还是建议用命令,因为有报错你能知道,这种方式错了也不知道
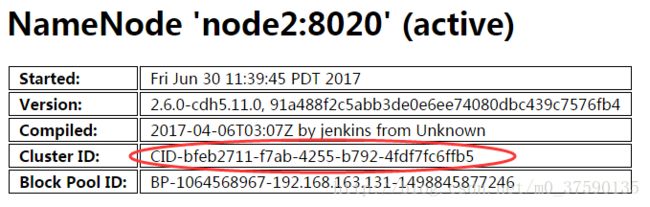
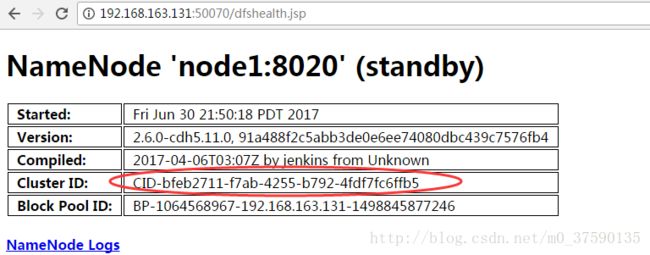
4、验证的话,等到启动两个nn时候,看看clusterid是否一样。下图是成功的
====================================================================================================================================
f、zkfc格式化,任一NN上
[root@node1 hadoop]# hdfs zkfc -formatZK====================================================================================================================================
拓展:与命令hadoop-deamon.sh format zkfc一个效果
解析:将HDFS集群与ZK集群建立联系
验证:登录zk客户端
[root@node1 hadoop]# zkCli.sh -server localhost
即是成功
====================================================================================================================================
g、启动余下的NN、DN
node2上:
[root@node2 hadoop]# hadoop-daemon.sh start namenode
[root@node2 hadoop]# hadoop-daemon.sh start datanodenode1和node3上:
[root@node1 hadoop]# hadoop-daemon.sh start datanode保证每个nn、dn都启动
====================================================================================================================================
验证:任一即可
1、每台节点上,均jps,看看对应进程,有没有你想要nn和dn
2、通过web,两个nn地址http端口访问,两个节点都是standby状态
====================================================================================================================================
h、启动ZKFC,在两个NN上启动
[root@node2 hadoop]# hadoop-daemon.sh start zkfc
[root@node1 hadoop]# hadoop-daemon.sh start zkfc====================================================================================================================================
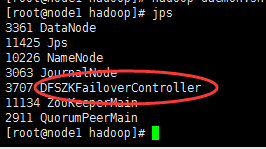
验证:任一即可
1、每台节点上,均jps,看看对应进程,有没有你想要的
2、通过web,两个nn地址http端口访问,两个节点都是standby状态
====================================================================================================================================
到此,集群搭建完成!!!
后面是验证,以及查错方法。
6、集群验证
验证方式不用多说了,可通过hadoop fs系列命令,上传一个文件每个节点查看,每个节点分别挂掉以后,命令是否可用。也需要通过web界面进行监控,nn是否激活
7、查错方法
日志路径为:安装目录下的logsNN不对劲则看对应节点下的,hadoop-root-namenode-node1.log
DN不对劲则看对应节点下的,hadoop-root-datanode-node1.log
ZKFC不对劲则看对应节点下的,hadoop-root-zkfc-node1.log
都会有记载的
8、其他问题解决
8.1、本地库无法加载
报错如图,显示本地库无法加载
问题原因:hadoop安装路径下lib/native下的jar包无法读取。
思路:可以配置ResourceManager其他库源。也可直接解决。
直接解决方案:
a、检查路径权限
b、若是native下没有文件,则找其他地方下载一套