python训练自己的深度学习keras分类模型
一、爬取百度图片构建数据集
原理参照这篇博客
https://blog.csdn.net/xiligey1/article/details/73321152
但训练一个VGG/Inception/ResNet等分类模型,需要的图片是海量的,不建议使用文中urlib/requests + BeautifulSoup 的方法,会非常的慢。这里推出python的强大爬虫框架scrapy,原理和链接博客是一样的,具体就不展开了。代码放这里:
import scrapy
from baidu_image.items import BaiduImageItem
import re
import os
from tqdm import tqdm
kindList = ['keyword1','keyword2','keyword3'] #关键词列表
class BkSpider(scrapy.Spider):
name = 'bdimg'
# allowed_domains = ['image.baidu.com']
start_urls = ['http://image.baidu.com']
url_start = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='
url_end = '&ct=&ic=0&lm=-1&width=0&height=0'
pages = 30 #一共爬取30页
step = 30 #每次页面跳转的步长,0,30,60...百度图片的机制
def start_requests(self):
print(len(kindList))
for key_word in kindList:
path = os.path.join(r'../images', key_word)
if os.path.exists(path): #创建名为key_word的文件夹
pass
else:
os.makedirs(path)
end = self.pages * self.step
for page in range(0, end, self.step):
gsm = hex(page)
url = self.url_start + key_word + '&pn=' + str(page) + '&gsm=' + str(gsm) + self.url_end #url拼接
request = scrapy.Request(url,callback=self.get_one_page_urls, dont_filter=False)
request.meta['kind'] = key_word
request.meta['page'] = page
yield request
def parse(self, response):
print('>>>>>>>>>>>>>>>>>>>>>>>>')
item = BaiduImageItem()
item['img'] = response.body
item['kind'] = response.meta['kind']
item['name'] = response.meta['name']
item['type'] = response.meta['type']
# print('????????')
yield item
def get_one_page_urls(self,response):
kind = response.meta['kind']
page = response.meta['page']
# print(response.body)
urls = re.findall('"objURL":"(.*?)",', response.body.decode('utf-8'), re.S)
# print(urls)
for i in tqdm(range(len(urls))):
request1 = scrapy.Request(urls[i], callback=self.parse)
request1.meta['kind'] = kind
request1.meta['name'] = str(page//self.pages) + '_'+str(i) #图片名:页面_图片顺序 如1_10
request1.meta['type'] = urls[i].split('.')[-1] #图片后缀名,jpg,jpeg,png等等
yield request1
这是scrapy的主进程,其中tqdm 是一个进度条。
爬到的图片按关键词自动保存到不同的文件夹中。
git源码 :https://github.com/okfu-DL/baidu_images.git
二、标签编码
将关键词转换为独热码,需要用到sklearn.preprocessing 中的 LabelEncoder和OneHotEncoder,前者将字符类别转换为数字类别,后者将数字类别转换为独热码类别。
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
import os
import numpy as np
path = r'G:\crops_train\check'
dirnames = os.listdir(path)
label_word_dict = {}
word_label_dict = {}
num_label = LabelEncoder().fit_transform(dirnames)
print(type(num_label))
onehot_label = OneHotEncoder(sparse=False).fit_transform(np.asarray(num_label).reshape([-1,1]))
# onehot_label = list(list for each in onehot_label)
for i in range(len(dirnames)):
label_word_dict[num_label[i]] = dirnames[i]
word_label_dict[dirnames[i]] = list(onehot_label[i])
with open('label_word_dict.txt', 'w', encoding='utf-8') as f:
f.write(str(label_word_dict))
with open('word_label_dict.txt', 'w', encoding='utf-8') as f:
f.write(str(word_label_dict))
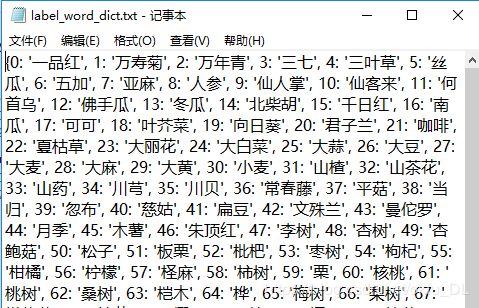
这里需要保存两个dict,一个是label_word_dict,结构为{类名:onehot_code};一个是word_label_dict,结构为{num_code:类名}。前者用于构造数据集时,查找类名获得独热码标签,后者用于模型预测阶段,输出分类后查找到类名。
word_label_dict

label_word_dict
三、图片文件转numpy adarray文件
先解释一下为什么要把图片转成npy文件。
图片数量高达百万张,不能一次性读入内存,需要分批次读取。每次读取一个npy文件训练,然后释放内存,读下一个npy文件。如果不存为npy文件会有以下三个麻烦:
1、读取时间过长。每次读取需要不断地循环读入一定数量的图片并预处理,会占用大量的时间。
2、循环读文件会将同类图片连续读入,没有打乱图片顺序,对模型的训练不友好。
3、爬取的图片有部分已损坏,应提前剔除。

先上代码
import os
from PIL import Image
from tqdm import tqdm
import numpy as np
import random
import gc
LOC = list(np.zeros((216,),dtype=int))#全局变量,长度216维向量,即对每一类图片记录一个当前文件位置。
path = r'G:\crops_train\check' #图片位置
Width, Height = 224,224
trainpath = r'G:\crops_train\dataset\train'
testpath = r'G:\crops_train\dataset\test'
valpath = r'G:\crops_train\dataset\val'
#单张图片转numpy npdarray
def img_pretreat(file):
row_img = Image.open(file)
img = row_img.resize((Width, Height))
points = np.asanyarray(img, dtype=np.float32)
points = points * 1. / 255
points = np.reshape(points, [Width, Height, 3])
return points
def img2arr_train(path,step):
if step == 6:
NUM = 50
else:
NUM = 100
with open('word_label_dict.txt', 'r', encoding='utf-8') as f:
js = eval(f.read())
img_data_list = []
row_label = []
dirnames = os.listdir(path)
for cls,dirname in enumerate(tqdm(dirnames)):
dir = os.path.join(path,dirname)
start = LOC[cls]
num = 0
for parent,_,filenames in os.walk(dir):
for filename in filenames[start:]:
LOC[cls] += 1
try:
file = os.path.join(parent,filename)
i = random.randint(0, len(img_data_list))
img_data = img_pretreat(file)
img_data_list.insert(i, img_data)
row_label.insert(i,js[dirname])
num += 1
# print(num)
if num > NUM:
break
except Exception as e:
# print(e)
continue
print(LOC[cls])
inputs = np.array(img_data_list)
labels = np.array(row_label)
save_path = ''
if step < 6:
save_path = trainpath
if step == 6:
save_path = valpath
if step == 7:
save_path = testpath
np.save(os.path.join(save_path,'inputs'+str(step)+'.npy'),inputs)
np.save(os.path.join(save_path,'labels'+str(step)+'.npy'),labels)
del inputs,labels
gc.collect()
if __name__ == "__main__":
for step in range(0,8):
img2arr_train(path,step)
循环执行img2arr8次,前6次每次在每个类别中选100张作为一组训练集(inputs0-5,labels0-5).第7次每个类别中选择50张作为验证集(inputs6,labels6),第8次每个类别中选100张作为测试集(inputs7,labels7)。我的电脑内存48g,构建一组训练集大约需要30g的内存,更具自己的内存,适当调整训练集大小。建议有条件可以搞个SSD,读写文件会快很多。
注意:
1.图片插入数组的时候不要用append,要random一个随机整数,然后用insert方法,目的是为了shuffle。如此生成,训练文件6组,验证文件1组,测试文件1组。
2.每张图片用PIL.Image.open载入要加try,因为有可能图片损坏了。此时,如果成功了cnt++,cnt代表处理成功的图片数量,达到100/50张就break。而LOC[cls]记录了第cls类文件夹下读取文件下标的位置,每次读入不论成功与否都要加1。
3.关于内存释放,每保存一个文件后,delete数组,然后用gc.collect()函数释放内存。注意,list对象转npdarray对象时一定要用np.arrary(),而不能用np.asarray()。因为后者的是映射一个npdarray对象,会造成内存无法回收。



四、keras迭代器函数
keras批次训练函数model.fit_generator,要写一个迭代函数,每个batch的训练都要从迭代函数中重新获取输入数据。不懂原理的看看官方文档:https://keras-cn.readthedocs.io/en/latest/models/sequential/#fit_generator
官方例子:
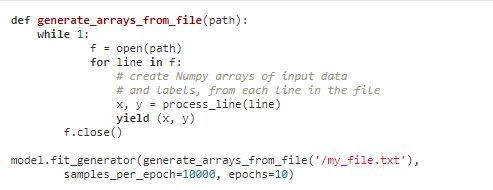
def generate_arrays_from_file(trainpath,set_len=21600,file_nums=6,has_remainder=0,batch_size=32):
'''
:param trainsetpath: 训练集路径
:param set_len: 训练文件的图片数量
:param file_nums: 训练文件数量
:param has_remainder: 是否有余数,即has_remainder = 0 if set_len % batch_size == 0 else 1
:param batch_size: 批次大小
:return:
'''
cnt = 0
pos = 0
inputs = None
labels = None
while 1:
if cnt % (set_len//batch_size+has_remainder) == 0: #判断是否读完一整个文件
pos = 0
seq = cnt//(set_len//batch_size+has_remainder) % file_nums #此次读取第seq个文件
del inputs,labels
inputs = np.load(os.path.join(trainsetpath, 'inputs'+str(seq)+'.npy'))
labels = np.load(os.path.join(trainsetpath, 'labels'+str(seq)+'.npy'))
start = pos*batch_size
end = min((pos+1)*batch_size, set_len-1)
batch_inputs = inputs[start:end]
batch_labels = labels[start:end]
pos += 1
cnt += 1
yield (batch_inputs,batch_labels)
其中,cnt每个step都会自增,pos用来标识当前文件数组的下标。每次读入新文件置零。
值得一提的是 if cnt % (set_len//batch_size+has_remainder) == 0中的has_remainder,如果batch_size不能整除set_len,则需要多出一轮处理不足batch_size的剩余数据,end = min((pos+1)*batch_size, set_len-1)相对应,end取下一个batch_size和文件长度中的较小值。
五、批次训练
这里采用ResNet50,将最后一层Dense层的节点数改为需要的分类数,其余均不变。
# coding=utf-8
from keras.models import Model,load_model
from keras.layers import Input, Dense, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D, ZeroPadding2D
from keras.layers import add, Flatten
# from keras.layers.convolutional import Conv2D,MaxPooling2D,AveragePooling2D
from keras.optimizers import SGD
import numpy as np
from keras.callbacks import TensorBoard
from keras.callbacks import ModelCheckpoint
from pretreat import *
from img2arr import img_pretreat
seed = 7
np.random.seed(seed)
def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding='same', name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter, kernel_size, padding=padding, strides=strides, activation='relu', name=conv_name)(x)
x = BatchNormalization(axis=3, name=bn_name)(x)
return x
def Conv_Block(inpt, nb_filter, kernel_size, strides=(1, 1), with_conv_shortcut=False):
x = Conv2d_BN(inpt, nb_filter=nb_filter[0], kernel_size=(1, 1), strides=strides, padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[1], kernel_size=(3, 3), padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter[2], kernel_size=(1, 1), padding='same')
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt, nb_filter=nb_filter[2], strides=strides, kernel_size=kernel_size)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x
def resnet50():
inpt = Input(shape=(224, 224, 3))
x = ZeroPadding2D((3, 3))(inpt)
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
x = Conv_Block(x, nb_filter=[64, 64, 256], kernel_size=(3, 3), strides=(1, 1), with_conv_shortcut=True)
x = Conv_Block(x, nb_filter=[64, 64, 256], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[64, 64, 256], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[128, 128, 512], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[256, 256, 1024], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[512, 512, 2048], kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = Conv_Block(x, nb_filter=[512, 512, 2048], kernel_size=(3, 3))
x = Conv_Block(x, nb_filter=[512, 512, 2048], kernel_size=(3, 3))
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(216, activation='softmax')(x)
model = Model(inputs=inpt, outputs=x)
model.summary()
return model
def train():
val_X = np.load(os.path.join(valpath,'inputs6.npy'))
val_Y = np.load(os.path.join(valpath,'labels6.npy'))
print('load ok')
model = resnet50()
sgd = SGD(lr=0.0001, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
model.fit_generator(generate_arrays_from_file_1(trainpath, batch_size=32), epochs=100, verbose=1, workers=1, steps_per_epoch=4050,validation_data=(val_X,val_Y))
model.save('model/res50_216class_01.h5')
model.fit_generator(generate_arrays_from_file_1(trainpath, batch_size=32), epochs=100, verbose=1, workers=1, steps_per_epoch=4050,validation_data=(val_X,val_Y))
steps_per_epoch一定要计算正确,否则会有不可预见的错误。顾名思义,就是一个epoch的steps数,也就是