《Java EE SSM框架》学习笔记(5、映射器)
demo链接地址:https://share.weiyun.com/5iCY76r 密码:hxf568
不使用注解的方式,实现映射器:
1、面对复杂性,SQL会显得无力。
2、注解的可读性较差。
3、注解丢失了XML上下文相互引用的功能。
resultMap:用来描述从数据库结果集中来加载对象,它是最复杂、最强大的元素。
select元素——查询语句
自动映射和驼峰映射:
在默认的情况下,自动映射功能时开启的,使用它的好处在于能有效减少大量的映射配置,从而减少工作量。
在setting元素中,有两个配置,autoMappingBehavior和mapUnderscoreToCamelCase,它们是控制自动映射和驼峰映射的开关。
驼峰命名,例如:
数据库字段为role_name,则POJO属性名为roleName
传递多个参数:
1、使用map接口传递参数:

不常使用map的原因:
(1)map是一个键值对应的集合,使用者要通过阅读它的键,才能使用它。
(2)不能限制其传递的数据类型,因此业务性质不强,可读性差。
2、使用注解传递多个参数
![]()
对应mapper的编写:

3、通过Java Bean传递多个参数
使用resultMap映射结果集:
自动映射和驼峰映射规则比较简单,但无法定义多的属性,比如typeHandler、级联等。

它的子元素id代表resultMap的主键,而result代表其属性。
分页参数RowBounds:
MyBatis不仅支持分页,还内置了一个专门处理分页的类。

mapper中,无须填写任何有关RowBounds参数的信息,它是MyBatis的一个附加参数,MyBatis会自动识别它,据此进行分页。
代码填写如下:

RowBounds分页,只能运用于一些小数据量的查询。
它的原理就是,按照偏移量和限制条数返回查询结果,对于大量的数据查询,它的性能并不佳,可使用插件。
insert元素——插入语句:
MySQL中的表格采用了自增主键。
有时候需要继续使用这个主键,因此获取到它就十分必要了。
在JDBC中,用Statement对象,在执行插入的SQL后,可通过getGeneratedKeys方法获得数据库生成的主键。
在inset语句中,有一个开关属性useGeneratedKeys开关,打开之后,通过配置keyProperty(填写POJO属性名),即可获得主键,赋值回参数POJO,若存在多个主键,则用逗号隔开。
自定义主键:

order设置为BEFORE,说明它将于当前定义的SQL前执行。
若设置为AFTER,则用于,一些插入语句内部可能有嵌入索引调用。
sql元素:
sql元素的作用在于,可以定义一条SQL的一部分,方便后面的SQL引用它,比如最典型的列名。

sql元素还支持变量传递:

参数:
一些数据库字段返回为null,系统又检测不到使用何种jdbcType进行处理时,则会发生异常。
需要定义好javaType、jdbcType和typeHandler。

resultMap元素:
针对不带没有参数的构造方法,可用constructor配置:
对于,public RoleBean(Integer id,String roleName);有:

idArg元素表示哪个列是主键,允许多个主键,多个主键则称为联合主键。
使用map存储结果集:

使用POJO存储结果集:
通过配置resultMap的形式:

配置了resultMap,就不能配置resultType。
级联:
级联是resultMap中的配置,是一个数据库实体的概念。
存在一种称为鉴别器的级联,它是一种可以选择具体实现类的级联。比如,根据性别不同,选择不同的体检表。
级联的好处是,获取关联数据十分便捷,但会增加系统的复杂度,当层级超过3层时,就不要考虑使用级联了。
级联的种类:
鉴别器(discriminator)、一对一(association,一对一的级联)、一对多(collection,一对多的级联)
MyBatis不支持多对多级联,可通过两个一对多级联进行替换。
本节所涉及的表格有:

雇员任务表是通过,任务编号和任务进行一对一关联的。
雇员表与工牌表,是一对一的关联关系;与雇员任务表,是一对多的关联关系。
相应的POJO的设计:

雇员任务表与任务表,通过task_id关联,相应的mapper编写:

ps:select配置是,命名空间+SQL id的形式,就可通过对应的SQL,将数据查询回来。
鉴别器的实现:
为多个性别健康表,建立相应的mapper:

雇员表,相应的mapper:

ps:与工牌表的一对一关系,与员工任务表的一对多关系,都体现在这个mapper中。resultMap属性表示,采用哪个ResultMap去映射。

ps:以上这两个resultMap,都会通过association元素去执行对应关联的字段和SQL。其中column=“id”的id指的是雇员表中传过来的id。
N+1问题:
假设有N个关联关系完成了级联,那么再加入一个关联关系,就变成了了N+1个级联;显然这样会有很多我们并不关心的数据被取出,这样就会造成很大的资源浪费。
延迟加载:
在myBatis配置文件中,设置如下:

lazyLoadingEnabled:决定是否开启延迟加载。
aggressiveLazyLoading:控制是否采用层级加载,但它们都是全局性的配置。即,加载雇员任务信息时,又把工卡信息给加载了,可用fetchType解决。
所谓层级加载,即将同一层级的数据,一同加载起来。
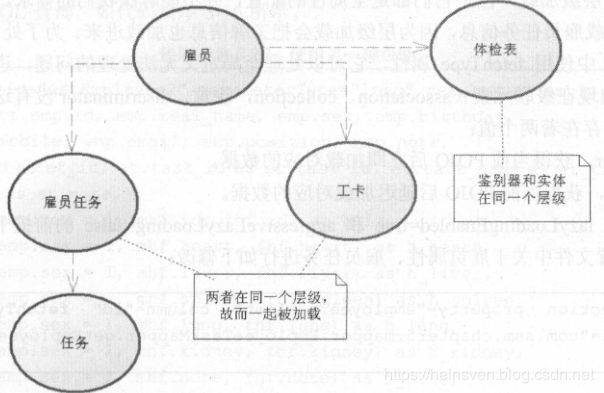
fetchType有两个配置项:
eager:获得POJO后,立即加载对应的数据。
lazy:获得POJO后,延迟加载对应的数据。
如对雇员mapper进行修改:

fetchType会自动忽略上述两个全局配置项。这样的话,就可以实现,加载雇员信息后,再加载雇员任务信息。
另一种级联:
也可以通过sql的left join语句,将一个雇员模型信息,所有的信息关联出来。

之后就可以在resultMap,直接使用查询回来的数据了,例如:

上述的association、collection等中的column表示的是,所对应表格中的外键的主键,或者是,association中的,对应表格中的主键的外键。
association通过JavaType的定义去声明实体映射,collection则是用ofType。
以上方式确实可以消除N+1问题,但会引发,SQL复杂,配置繁多,内存浪费等问题。一般用得不多。
多对多级联:
现实场景中,程序中的多对多级联,会被拆分为两个一对多级联来处理。
例如,一个用户可扮演多个角色,一个角色可由多个用户担当。
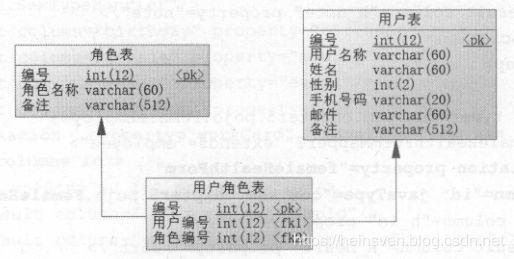
这样角色和用户,以一张用户角色表建立关联关系。
角色一对多关系的建立,POJO:

相应的user2,的mapper:

collection中,通过user的id去查找角色列表时,实质上是通过,sql用user的id去查询中间表t_user_role,然后再用查询出来的role_id去关联角色表。

缓存:
缓存一般都放置在可高速读/写的存储器上。
内存和高速缓存处理器的空间有限,只需把那些常用且命中率高的数据缓存起来。
一级缓存是在SqlSession上的缓存,二级缓存是在SqlSessionFactory上的缓存。
默认情况下,MyBatis会开启一级缓存。即,当查询同一个对象时,若第二次查询的SQL和参数没变的话,就从缓存中获取数据。
一级缓存是在SqlSession层面的,意思是:对于不同的SqlSession对象是不能共享的。开启二级缓存就能共享了。
开启二级缓存的方法就是,在相应的mapper文件中,加入
开启二级缓存之后,多个SqlSession对象可共享某个对象,例如Role,但这个Role需要实现序列化接口。
mapper加入了cache元素后,MyBatis会将,对应的命名空间内所有select元素SQL查询结果进行缓存,待其它操作后,进行更新。
使用自定义缓存,需实现Cache接口:
假设定义了一个Redis的缓存实现类:RedisCache
可在mapper中配置如下:
![]()

若对一些查询,不需要进行任何缓存,则可设置为:

useCache是select特有的,表示是否使用缓存。
flushCache表示,是否刷新缓存。
引用其它mapper里的缓存配置,则可:
![]()
存储过程:
定义:它是数据库预先编译好,放在数据库内存中的一个程序片段,所以具备性能高,可重复使用的特性。
在oracle中定义好存储过程:

在java中对应设计一个POJO:

为存储过程设计mapper:

statementType,必须声明为CALLABLE,不然会抛出异常。
调用存储过程:

游标的使用:
MyBatis也对存储过程的游标提供了支持。
若要实现分页,则需添加start和end的两个参数,还要知道是否存在下一页,则还需添加total参数。
相应的存储过程设计:

相应的POJO设计:
![]()

相应的mapper设计:

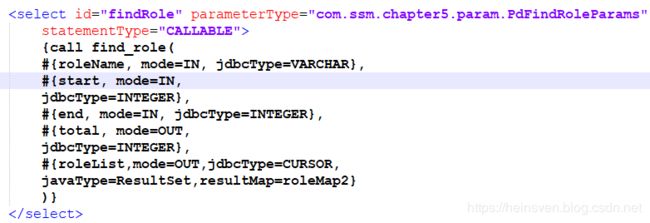
对于roleList,定义jdbcType为CURSOR,这可使得结果用ResultSet去处理,为使ResultSet能映射POJO,设置resultMap为roleMap。