HA高可用自动故障转移(最新,最详)
目录
概述:
图解:
集群规划:
配置zookeeper集群:
HDFS的NameNode的HA高可用自动故障转移:
YARN的HA高可用自动故障转移:
测试:
关闭集群:
Hadoop集群相关的开启关闭命令:
概述:
在了解自动故障转移之前,有必要了解一下手动故障转移,下面是文章的地址:
HA高可用手动故障转移
手动进行故障转移,在该模式下,即使现役NameNode已经失效,系统也不会自动从现役NameNode转移到待机NameNode,下面我们一起来看看如何配置部署HA自动进行故障转移:
相对于手动故障转移,自动故障转移增加了两个组件ZooKeeper和ZKFailoverController(ZKFC)进程。这里的zkfc是zookeeper的客户端
图解:
图一:
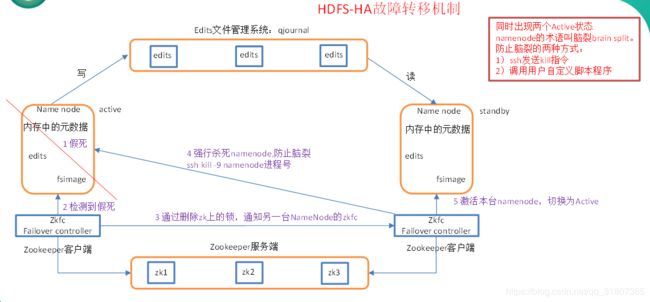
图二:
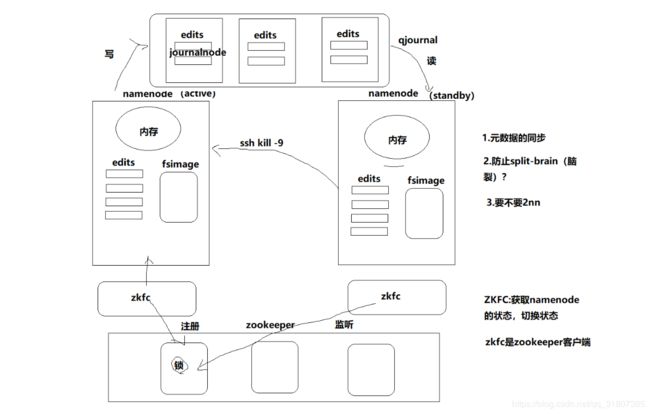
这里的zkfc 的作用就是获取namenode的状态,和切换namenode的状态;也是zookeeper集群的客户端。active负责在zookeeper中注册锁,这个锁其实就是一个文件夹,然后另外一个zkfc (standby的)来监听这把锁,一旦active 发生了变化,会通过删除锁的方法来告知standby,standby 就能够监听到这个变化,从而进行相应的处理。
集群规划:
|
|
hadoop102 |
hadoop103 |
hadoop104 |
| HDFS
|
NameNode DataNode JournalNode ZKFC |
NameNode DataNode JournalNode ZKFC |
DataNode JournalNode |
| YARN
|
ResourceManager NodeManager |
ResourceManager NodeManager |
NodeManager |
| Zookeeper |
Zookeeper |
Zookeeper |
Zookeeper |
配置zookeeper集群:
参见下面这篇文章:
分布式Zookeeper的部署与配置
HDFS的NameNode的HA高可用自动故障转移:
1,在HA高可用手动故障转移配置问价的基础上增加如下:
[isea@hadoop101 hadoop]$ vim hdfs-site.xml
dfs.ha.automatic-failover.enabled
true
[isea@hadoop101 hadoop]$ vim core-site.xml
ha.zookeeper.quorum
hadoop101:2181,hadoop102:2181,hadoop104:2181
2,配置完成之后,分发配置文件:
[isea@hadoop101 etc]$ xsync hadoop/
3,启动之前,关闭所有的hdfs服务,并在集群的机器上分别启动zookeeper
[isea@hadoop101 hadoop-2.7.2]$ sbin/stop-dfs.sh
[isea@hadoop101 hadoop-2.7.2]$ jps
6466 Jps
5124 QuorumPeerMain
4,初始化HA在zookeeper中的状态
在初始化之前,先使用其中一台机器登录zookeeper客户端,查看文件信息如下:
[isea@hadoop103 zookeeper-3.4.10]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
然后执行初始化的操作:
[isea@hadoop101 hadoop-2.7.2]$ bin/hdfs zkfc -formatZK
查看zookeeper中的文件信息如下:
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, hadoop-ha]
由此说明,HA的Namenode会向zookeeper中写入文件夹:
5,启动HDFS的服务,使用群起命令:
[isea@hadoop101 hadoop-2.7.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop101 hadoop102]
先启动zkfc的节点就是 active节点
Starting ZK Failover Controllers on NN hosts [hadoop101 hadoop102]
hadoop101: starting zkfc, logging to /opt/module/HA/hadoop-2.7.2/logs/hadoop-isea-zkfc-hadoop101.out
hadoop102: starting zkfc, logging to /opt/module/HA/hadoop-2.7.2/logs/hadoop-isea-zkfc-hadoop102.out
[isea@hadoop101 hadoop-2.7.2]$ jps
7313 Jps
5124 QuorumPeerMain
7237 DFSZKFailoverController
6805 DataNode
7032 JournalNode
6685 NameNode
YARN的HA高可用自动故障转移:
1,配置yarn-site.xml:
[isea@hadoop101 hadoop]$ vim yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
cluster-yarn1
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
hadoop101
yarn.resourcemanager.hostname.rm2
hadoop102
yarn.resourcemanager.zk-address
hadoop101:2181,hadoop102:2181,hadoop103:2181
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
2,同步到其他的节点:
[isea@hadoop101 hadoop]$ xsync yarn-site.xml
3,群起yarn,在102中单独启动resourcemanager
[isea@hadoop101 hadoop-2.7.2]$ jps
7585 NodeManager
7635 Jps
5124 QuorumPeerMain
7237 DFSZKFailoverController
6805 DataNode
7032 JournalNode
6685 NameNode
7471 ResourceManager
[isea@hadoop102 hadoop-2.7.2]$ jps
5345 NodeManager
4723 NameNode
4916 JournalNode
4087 QuorumPeerMain
5047 DFSZKFailoverController
4809 DataNode
5469 Jps
[isea@hadoop102 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
[isea@hadoop102 hadoop-2.7.2]$ jps
5345 NodeManager
4723 NameNode
4916 JournalNode
4087 QuorumPeerMain
5047 DFSZKFailoverController
4809 DataNode
5562 Jps
5517 ResourceManager
可以在客户端查看信息
测试:
http://hadoop101:50070/dfshealth.html#tab-overview active
http://hadoop102:50070/dfshealth.html#tab-overview standby
http://hadoop102:8088/cluster 输入该地址之后会直接跳转到 http://hadoop101:8088/cluster
1,杀死nn1 ,观察 nn2,在恢复nn1,在观察nn1
[isea@hadoop101 hadoop-2.7.2]$ bin/hdfs haadmin -getServiceState nn1
active
[isea@hadoop101 hadoop-2.7.2]$ bin/hdfs haadmin -getServiceState nn2
standby
[isea@hadoop101 hadoop-2.7.2]$ kill -9 6685
[isea@hadoop101 hadoop-2.7.2]$ jps
*
[isea@hadoop101 hadoop-2.7.2]$ bin/hdfs haadmin -getServiceState nn2
active
[isea@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
[isea@hadoop101 hadoop-2.7.2]$ jps
8222 NameNode
*
[isea@hadoop101 hadoop-2.7.2]$ bin/hdfs haadmin -getServiceState nn1
standby
2,杀死rm1,观察rm2,在恢复rm1,观察rm1
[isea@hadoop101 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm1
active
[isea@hadoop101 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm2
standby
[isea@hadoop101 hadoop-2.7.2]$ kill -9 7471
[isea@hadoop101 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm2
standby
[isea@hadoop101 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm2
active
注意这里切换需要时间,有延迟。
[isea@hadoop101 hadoop-2.7.2]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /opt/module/HA/hadoop-2.7.2/logs/yarn-isea-resourcemanager-hadoop101.out
[isea@hadoop101 hadoop-2.7.2]$ jps
8669 ResourceManager
*
[isea@hadoop101 hadoop-2.7.2]$ bin/yarn rmadmin -getServiceState rm1
3,上传文件试试看:
[isea@hadoop101 hadoop-2.7.2]$ bin/hadoop fs -mkdir /isea
[isea@hadoop101 hadoop-2.7.2]$ bin/hadoop fs -ls /
Found 1 items
drwxr-xr-x - isea supergroup 0 2018-11-28 19:32 /isea
关闭集群:
1,群关HDFS相关的服务
[isea@hadoop101 hadoop-2.7.2]$ sbin/stop-dfs.sh
hadoop101: stopping namenode
hadoop102: stopping namenode
hadoop101: stopping datanode
hadoop103: stopping datanode
hadoop102: stopping datanode
Stopping journal nodes [hadoop101 hadoop102 hadoop103]
hadoop103: stopping journalnode
hadoop101: stopping journalnode
hadoop102: stopping journalnode
Stopping ZK Failover Controllers on NN hosts [hadoop101 hadoop102]
hadoop102: stopping zkfc
hadoop101: stopping zkfc
2,群关YARN相关的服务
[isea@hadoop101 hadoop-2.7.2]$ sbin/stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
hadoop101: stopping nodemanager
hadoop103: stopping nodemanager
hadoop102: stopping nodemanager
no proxyserver to stop
还有rm2 上面的resourcemanager要手动关闭
[isea@hadoop102 hadoop-2.7.2]$ sbin/yarn-daemon.sh stop resourcemanager
3,手动在每一个节点上关闭zookeeper
[isea@hadoop101 zookeeper-3.4.10]$ bin/zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
[isea@hadoop101 zookeeper-3.4.10]$ pwd
/opt/module/zookeeper-3.4.10
[isea@hadoop102 zookeeper-3.4.10]$ bin/zkServer.sh stop
[isea@hadoop103 zookeeper-3.4.10]$ bin/zkServer.sh stop
Hadoop集群相关的开启关闭命令:
文章链接:
常用(HDFS,YARN,zookeeper)集群开启,关闭,状态查看命令总结