点击旋转验证码破解
以极速漫画为例
http://www.1kkk.com/

这类的网站验证码使用点击旋转,来登录。
笔者提出的思路简单暴力,直接想办法获得所有正确图片,然后在登录时爬取这4张动漫图片,做旋转对比得出点击次数

查看网页数据加载可以看到在每次点击“换一组”就会加载新的图片 查看图片加载链接 http://www.1kkk.com/image3.ashx?t=1537269577000 消除多余的参数(时间戳)
- 访问 http://www.1kkk.com/image3.ashx


- 每次访问都将获得不同的图片,这些就是网站的验证码图片
- 笔者爬取http://www.1kkk.com/image3.ashx网站循环500次拿到500张大图(16张小图)
- 循环爬到500张图片
import requests
headers = {"User-Agent": "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)"}
def pic_data():
url = 'http://www.1kkk.com/image3.ashx'
for i in range(500):
response = requests.get(url, headers=headers)
filename = './image/%s' % str(i) + '.png'
with open(filename, 'wb') as f:
f.write(response.content)
print(i)
if __name__ == '__main__':
pic_data()

- 使用Image模块中的crop方法来切割图片,得到每一种头像都有一张图片
- 循环500张大图得到2000张小图(每张图切割出第一排)
from PIL import Image
y = 0
for i in range(1,500):
im = Image.open('./images/' + str(i) + '.png')
region = im.crop(( 0, 0, 76, 76))
region.save("./images/" + str(y) + '.png')
y += 1
region = im.crop((76, 0, 152, 76))
region.save("./images/" + str(y) + '.png')
y += 1
region = im.crop((152, 0, 228, 76))
region.save("./images/" + str(y) + '.png')
y += 1
region = im.crop((228, 0, 304, 76))
region.save("./images/" + str(y) + '.png')
y += 1
print(y)
- 坐标(左,上,右,下)大小是因为大图304* 304像素,切割成小图时就是76*76
- 得到2000张小图后,其中必定有相同的图片
- 去重使用VisiPics软件去除相同的图片(笔者2000图去重剩下518)
- https://jingyan.baidu.com/article/215817f7e30cbd1eda14238e.html
- 剩下的图片还是有相同的,这些就是有可能是 方向不同
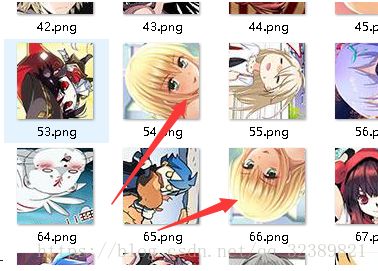
- 这样的图片还是一样的,还需要要进一步去重
- 使用直方图去重
- 参考了http://blog.sina.com.cn/s/blog_70cff2d70102wfgz.html https://blog.csdn.net/sinat_35059932/article/details/60580536
- 重命名图片名方便去重(强迫症)
import os
y = 0
for i in range(1,2000):
a = './images/' + str(i) + '.png'
if os.path.isfile(a):
y += 1
b = './images/'+ str(y) + '.png'
if not os.path.isfile(b):
os.rename(a, b)
-去重
import math
import operator
import os
from functools import reduce
from PIL import Image
for i in range(1,519):
try:
h1 = Image.open('./images/'+ str(i) +'.png').histogram()
except:
continue
for j in range(i+1,519):
try:
h2 = Image.open('./images/' + str(j) + '.png').histogram()
except:
continue
result = math.sqrt(reduce(operator.add, list(map(lambda a,b: (a-b)**2, h1, h2)))/len(h1) )
print(i,j)
if result < 7 :
print('-----------------------------')
print(i,j)
print(result)
os.remove('./images/'+ str(j) + '.png')
- 使用直方图去重,还是有相同的图片笔者还剩221,就需要我们手动将图片方向矫正,以便之后的对比及再次去重

- 将图片矫正再次使用VisiPics软件去重,笔者还剩151张图,这些图应该就是网站数据库的图了。
- 再次重新按顺序命名这些图片,方便对比时的循环(也可以使用os模块获取名字)
- 重命名
import os
y = 0
for i in range(1,2000):
a = './images/' + str(i) + '.png'
if os.path.isfile(a):
y += 1
b = './images/'+ str(y) + '.png'
if not os.path.isfile(b):
os.rename(a, b)
- 自动登录
import math
import operator
import os
import time
from functools import reduce
from io import BytesIO
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
class CrackGeetest():
def __init__(self):
self.url = 'http://www.1kkk.com/'
self.browser = webdriver.Chrome()
self.wait = WebDriverWait(self.browser, 5)
def __del__(self):
self.browser.close()
def get_geetest_button(self):
"""
获取登陆头像按钮
:return:
"""
button = self.wait.until(EC.element_to_be_clickable((By.XPATH, '/html/body/header/div/div[2]/a/img')))
button.click()
def get_position(self,a):
"""
获取验证码位置
:return: 验证码位置元组
"""
time.sleep(1)
if a == 1:
self.img1 = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/div/div[2]')))
location = self.img1.location
if a == 2:
self.img2 = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/div/div[3]')))
location = self.img2.location
if a == 3:
self.img3 = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/div/div[4]')))
location = self.img3.location
if a == 4:
self.img4 = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/div/div[5]')))
location = self.img4.location
size = {'height': 76, 'width': 76}
top, bottom, left, right = location['y'], location['y'] + size['height'], location['x'], location['x'] + size[
'width']
return (top, bottom, left, right)
def get_screenshot(self):
"""
获取网页截图
:return: 截图对象
"""
screenshot = self.browser.get_screenshot_as_png()
screenshot = Image.open(BytesIO(screenshot))
return screenshot
def get_geetest_image(self, name='captcha.png', sum='0',screensho=''):
"""
获取验证码图片
:return: 图片对象
"""
top, bottom, left, right = self.get_position(sum)
print('验证码位置', top, bottom, left, right)
captcha = screensho.crop((left, top, right, bottom))
print(left, top, right, bottom)
captcha.save(name)
return captcha
def open(self):
"""
打开网页输入用户名密码
:return: None
"""
self.browser.get(self.url)
def is_pixel(self, image1, image2):
"""
像素匹配
:param image1:图片1
:param image2: 图片2
:return: True或False
"""
for x in range(10, 60):
for y in range(10, 60):
pixel1 = image1.load()[x, y]
pixel2 = image2.load()[x, y]
threshold = 100
if not abs(pixel1[0] - pixel2[0]) < threshold and abs(pixel1[1] - pixel2[1]) < threshold and abs(pixel1[2] - pixel2[2]) < threshold:
# print(x,y)
return False
return True
def pic_contrast(self, auth_code1, auth_code2, im):
"""
图片详细对比
:param auth_code1: 网站的小图
:param auth_code2: 数据库图片
:param im: 存储点击次数
:return: im
"""
for angle in range(4):
# 像素对比
if self.is_pixel(auth_code1.rotate(90 * angle), auth_code2):
print('现在旋转角度:%d' %(90 * angle))
im.append(0 if (4 - angle) == 4 else (4 - angle))
print('点击次数:%d' % (0 if (4 - angle) == 4 else (4 - angle)))
print('------------------------')
break
def click_code(self,im):
"""
循环对比图片
:param im:存储点击次数
:return:
"""
for i in range(1, 5):
try:
h1 = Image.open(str(i) + '.png').histogram()
auth_code1 = Image.open(str(i) + '.png')
except:
continue
for j in range(1, len(os.listdir('./images'))):
try:
h2 = Image.open('./images/' + str(j) + '.png').histogram()
auth_code2 = Image.open('./images/' + str(j) + '.png')
except:
continue
result = math.sqrt(reduce(operator.add, list(map(lambda a, b: (a - b) ** 2, h1, h2))) / len(h1))
# 图片相似
if result < 20:
print('--------------------------')
print(i,j)
# 详细对比
self.pic_contrast(auth_code1, auth_code2, im)
def set_name_passwd(self, name, passwd):
"""
填写账户、密码、点击登陆
:param name: 账户
:param passwd: 密码
:return:
"""
# 用户名输入框
username = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/p[2]/input')))
# 密码输入框
password = self.wait.until(EC.presence_of_element_located((By.XPATH, '/html/body/section[3]/div/div/div/div/p[3]/input')))
# 清除用户名输入框
username.clear()
# 填写用户名数据
username.send_keys(name)
# 清除密码输入框
password.clear()
# 填写密码
password.send_keys(passwd)
time.sleep(2)
# 获取登陆按钮
login = self.wait.until(EC.presence_of_element_located((By.XPATH, '//*[@id="btnLogin"]')))
# 点击登陆
login.click()
time.sleep(10)
def crack(self, name, passwd):
# # 输入用户名密码
self.open()
self.get_geetest_button()
# # 获取验证码图片
time.sleep(1)
# 获取网页截图
screenshot = self.get_screenshot()
# 将待旋转图片截取下来
self.get_geetest_image('1.png',1,screenshot)
self.get_geetest_image('2.png',2,screenshot)
self.get_geetest_image('3.png',3,screenshot)
self.get_geetest_image('4.png',4,screenshot)
# 存储点击次数
im = []
# 待旋转图片
img = [self.img1, self.img2, self.img3, self.img4]
# 判断次数
self.click_code(im)
print(im)
# 点击旋转
for index in range(4):
for _ in range(im[index]):
img[index].click()
time.sleep(2)
# 填写用户名/密码
self.set_name_passwd(name=name, passwd=passwd)
if __name__ == '__main__':
crack = CrackGeetest()
crack.crack(name='yang', passwd='123456')
- 效果
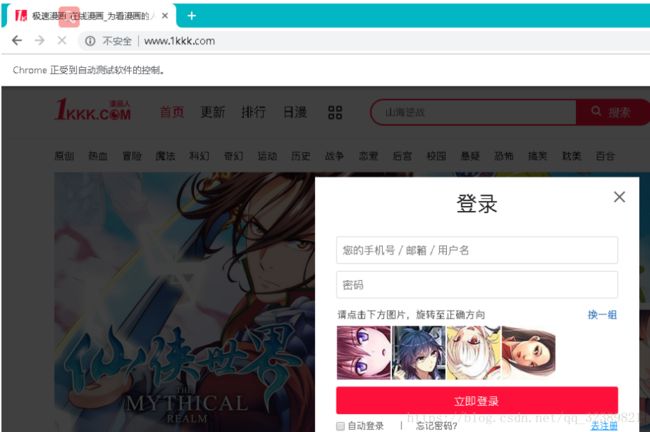


- 使用笔者代码请注意代码层级
