Redis的跳跃表确定不了解下
redis源码分析系列文章
[Redis源码系列]在Liunx安装和常见API
为什么要从Redis源码分析
String底层实现——动态字符串SDS
双向链表都不懂,还说懂Redis?
面试官:说说Redis的Hash底层 我:......(来自阅文的面试题)
前言
hello,大家好,周五见了。前面几周我们一起看了Redis底层数据结构,如动态字符串SDS,双向链表Adlist,字典Dict,如果有对Redis常见的类型或底层数据结构不明白的请看上面传送门。

今天我们来看下ZSET的底层架构,如果不知道ZSET是什么的,可以看上面传送门第一篇。简单来说,ZSET是Redis提供的根据数据和分数来判断其排名的数据结构。最常见的就是微信运动的排名,每个用户对应自己的步数,每天晚上可以给出用户的排名。
有小伙伴可能会想,如果是实现排名的话,各种排序方法都可以实现的,没必要引入Redis的ZSET结构啊?
当然,如果是采用排序方法的话,是可以实现相同功能的,但是代码里面需要硬编码,会添加工作量,还会提供代码的Bug哦,哈哈哈。而且Redis的底层是C实现的,直接操作内存,速度也会比Java方法实现提升。
综上,使用Redis的ZSET结构,好处多多。那话不多说,开始把。在正式开始之前,我们需要引入下跳跃表的概念,其是ZSET结构的底层实现。以下可能有点枯燥,我尽量说的简单点哈。

什么是跳跃表?
对于数据量大的链表结构,插入和删除比较快,但是查询速度却很慢。那是因为无法直接获取某个节点,需要从头节点开始,借助某个节点的next指针来获取下一节点。即使数据是有序排放的,想要查询某个数据,只能从头到尾遍历变量,查询效率会很低,时间复杂度为O(n)。
如果我们需要快速查询链表有啥办法呢?有同学说用数组存放,但是如果不改数据结构呢?
我们可以先想想在有序数组结构中有二分法,每次将范围都缩小一半,这样查询速度提升了很多,那么在链表中能不能也使用这种思想。
这就到了今天讲的主角——跳跃表。(一点也生硬的引出概念)

步骤一 新建有序单项链表
先看下图有序单向链表,存放了1,2,3,4,5,6,7这7个元素。

步骤二 抽取二级索引节点
我们可以在链表中抽取部分节点,下图抽取了1,3,5,7四个节点,也就是每两个节点提取了一个节点到上级,抽取出来的叫做索引。
注意不是每次都能抽取到这么完美,这其实就跟抛硬币一样,每个硬币的正反两面的概率是一样的,都是1/2。当数据量小的时候,正反的概率可能差别较大。但是随着数据量的加大,正反的概率越来越接近于1/2。类比过来是一个意思,每个节点的机会都是一样的,要么停留原级,要么提取到上级,概率都是1/2。但是随着节点数量的增加,抽取的节点越来越接近与1/2。

步骤三 抽取三级索引节点
我们可以在链表中抽取部分节点,下图抽取了1,5两个节点,也就是每两个节点提取了一个节点到上级,抽取出来的叫做索引。

步骤四 类二分法查询
我们假设要查找值为6的节点,先从三级索引开始,找到值为1的节点,发现比5小,根据值为1节点的next指针,找到值为5的节点,5后面没有其他的三级索引啦。
于是顺着往下找,到了二级索引,根据值为5的节点的next指针找到值为7的节点,发现比6小,说明要找到的节点6在此范围内。
再接着到了一级索引位置,根据值为5的节点next指针指向值为6的节点,发现是想要查询的数据,所以查询过程结束。
根据上面的查询过程(下图的蓝色连线),我们发现其采用的核心思想是二分法,不断缩小查询范围,如果在上层索引找到区间,则顺延深入到下一层找到真正的数据。

总结
从上面的整个过程中可以看出,数据量小的时候,这种拿空间换时间,消耗内存方法的并不是最优解。所以Redis的zset结构在数据量小的时候采用压缩表,数据量大的时候采用跳跃表。
像这种链表加多级索引的结构,就是跳跃表。这名字起的形象,过程是跳跃着来查询的。

Redis中跳跃表图解
下图简单来说是对跳跃表的改进和再封装,首先引入了表头的概念,这与双向链表,字典结构一样,都是对数据的封装,因为他们都是采用的指针,而指针必然导致在计算长度,获取最后节点的数据问题上会产生查询太慢的性能问题,所以封装表头是为了在这些问题上提升速度,浪费的只是添加,删除等操作的时间,与此对比,是可以忽略的。
其次是引入管理所有节点的层数数组,我们可以看到有32层,即32个数组,这和后面的数据节点结构是一样的。引入它是为了便于直接根据此数组的层数定位到每个元素。
再其次是数据节点的每个level都有层级和span(也就是下图箭头指针上的数字,其是为了方便统计两个节点相距多少长度)。
最后就是数据节点的后退指针backward,引入目的是Level数组只有前指针,即只能指向下一个节点地址,而后退指针是为了能往回找节点。
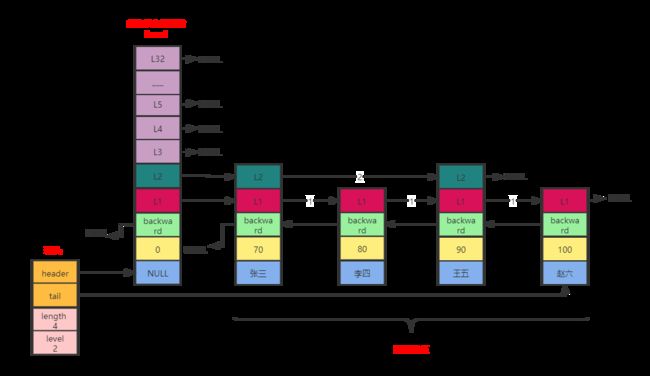
上图主要分为3大块:(这边大致看下就行,下面将对各模块进行代码详细解释)
表头
主要包括四个属性,分别是头指针header,尾指针tail,节点长度length,所有节点的最大level。
header:指向跳跃表的表头节点,通过这个指针地址可以直接找到表头,时间复杂度为O(1)。
tail:指向跳跃表的表尾节点,通过这个指针可以直接找到表尾,时间复杂度为O(1)。
length:记录跳跃表的长度,即不包含表头节点,整个跳跃表中有多少个元素。
level:记录当前跳跃表内,所有节点层数最大的level(排除表头节点)。
管理所有节点层数level的数组
其对象值为空,level数组为32层,目的是为了管理真正的数据节点。关于具体的level有哪些属性放在数据节点来说。
数据节点
主要包括四个属性对象值obj,分数score,后退指针backward和level数组。每个数据的Level数组有多少层,是随机产生的,这跟上面说过的跳跃表是一样的。
成员对象obj:真正的实际数据,每个节点的数据都是唯一的,但是节点的分数可能相同。两个相同分数的节点是按照成员对象在字典中的大小进行排序的,成员对象较小的节点会排在前面,成员对象较大的节点会排在后面。
分数score:各个节点中的数字是节点所保存的分数,在跳跃表中,节点按各自所保存的分数从小到大排列。
后退指针backward:用于从表尾向表头遍历,每个节点只有一个后退指针,即每次只能后退一步。
层级level:节点中用1,2,3等字样标记节点的各个层,L1代表第一层,L2代表第二层,L3代表第三层,并以此类推。
跳跃表的定义
表头结构zskiplist

typedef struct zskiplist {
//表头的头指针header和尾指针tail
struct zskiplistNode *header, *tail;
//一共有多少个节点length
unsigned long length;
// 所有节点最大的层级level
int level;
} zskiplist;具体数据节点zskiplistNode

//跳表的具体节点
typedef struct zskiplistNode {
sds ele; //具体的数据,对应张三
double score;//分数,对应70
struct zskiplistNode *backward;//后退指针backward
//层级数组 struct zskiplistLevel {
struct zskiplistNode *forward;//前进指针forward
unsigned int span;//跨度span
} level[];
} zskiplistNode; 跳跃表的实现(源码分析)
redis关于跳跃表的API都定义在t_zset.c文件中。
千万不要看到源码分析就跑开了,一定要看哦。

创建跳跃表
创建空的跳跃表,其实就是创建表头和管理所有的节点的level数组。首先,定义一些变量,尝试分配内存空间。其次是初始化表头的level和length,分别赋值1和0。接着创建管理所有节点的Level的数组,是调用zslCreateNode函数,输入参数为数组大小宏常量ZSKIPLIST_MAXLEVEL(32),分数为0,对象值为NULL。(此为跳跃表得以实现重点)。再接着就是为此数组每个元素的前指针forword和跨度span初始化。最后初始化尾指针并返回值。
可以参照下面的图解和源码:

//创建一个空表头的跳跃表
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
//尝试分配内存空间
zsl = zmalloc(sizeof(*zsl));
//初始化level和length
zsl->level = 1;
zsl->length = 0;
//调用下面的方法zslCreateNode,传入的参数有数组长度ZSKIPLIST_MAXLEVEL 32
//分数0,对象值NuLL
//这一步就是创建管理所有节点的数组
//并且设置表头的头头指针为此对象的地址
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//为这32个数组赋值前指针forward和跨度span
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
//设置尾指针
zsl->header->backward = NULL;
zsl->tail = NULL;
//返回对象
return zsl;
}
zskiplistNode *zslCreateNode(int level, double score, sds ele) {
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
}
插入节点
比如有下图6个元素,需要插入值为赵六,分数为101的元素,我们大致想一想,大致的步骤包括找到要插入的位置,新建一个数据节点,然后调整与之相关的头尾指针的level数组。那就看看redis咋做的,和我们想的一样不一样呢?
噔噔噔噔,答案揭晓。当然了大框架是相同的。

正文开始了:
1.遍历管理所有节点的level数组,从最大的level开始,即3,挨个对比值,如果有分数比他大的值或者分数相同,但是数据的值比他大,记录到数组里面,同时记录跨度。
这样说太抽象了。拿上图举个例子,从表头的level即3开始,首先到张三的L3,发现分数70,比目标分数101小跳过,根据其前指针找到赵六的L3,发现分数102,比目标分数101大,将赵六L3记录在待更新数组update中,同时记录跨度span为4。接着到下一层,张三的L2层,发现分数70比目标分数101小跳过,根据前指针找到王五的L2,发现分数90,比目标分数101小跳过,根据前指针找到赵六的L2,发现分数102比目标分数101大,将赵六的L2记录到待更新数组update中,同时记录跨度span为2。最后到下一层,张三的L1层,逻辑和刚才一样的,也是记录赵六的L1层和跨度span为1。
2.为新节点随机生成层级数level(通过位运算),如果生成的level大于目前level最大值3,则将将大于部分挨个遍历,并将跨度等信息记录到上面update表中。
比如,新节点生成的level为5,目前level最大值为3,说明这个节点只会有一个,并且跨越了之前的所有节点,那么我们将从第四层和第五层都遍历下,记录到待更新数组update中。
3.准备工作都做好了,找到了该节点将插入到哪一位置,处于哪一层,每层对应的跨度是多少,下面就要新增数据节点了。把上两步的信息都添加到新节点上,并且调整位置前后指针即可。
4.最后就是一些收尾工作,比如修改表头的层级level,节点大小length和尾指针tail等属性。
综上,整个流程就已经结束了。可能看着有点复杂,可以对照下面代码来。

//插入节点,输入参数为
//zsl:表头
//score:插入元素的分数score
//ele:插入元素的具体数据ele
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
//使用update数组记录每层待插入元素的前一个元素
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
//记录前置节点与第一个节点之间的跨度,即元素在列表中的排名-1
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//从最大的level开始遍历,从顶到底,找到每一层待插入的位置
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
//直接找到第一个分数比该元素大的位置
//或者分数与该元素相同但是对象的ASSICC码比该元素大的位置
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//将已走过元素的跨越元素进行计数,得到元素在列表中排名,或者是已搜寻的路径长度
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
//记录待插入位置
update[i] = x;
}
//随机产生一个层数,在1到32之间,层数越高,生成的概率越低
level = zslRandomLevel();
//如果产生的层数大于现有的最高层数,则超出层数都需要初始化
if (level > zsl->level) {
//开始循环
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
//该元素作为这些层的第一个节点,前节点就是header
update[i] = zsl->header;
//初始化后这些层每层有两个元素,走一步就是跨越所有元素
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
//创建节点
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++) {
//将新节点插入到各层链表中
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
// rank[0]是第0层的前置节点P1(也就是底层插入节点前面那个节点)与第一个节点的跨度
// rank[i]是第i层的前置节点P2(这一层里在插入节点前面那个节点)与第一个节点的跨度
// 插入节点X与后置节点Y的跨度f(X,Y)可由以下公式计算
// 关键在于f(P1,0)-f(P2,0)+1等于新节点与P2的跨度,这是因为跨度呈扇形形向下延伸到最底层
// 记录节点各层跨越元素情况span, 由层与层之间的跨越元素总和rank相减而得
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
// 插入位置前一个节点的span在原基础上加1即可(新节点在rank[0]的后一个位置)
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
// 第0层是双向链表, 便于redis常支持逆序类查找
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level
获取节点排名
担心大家忘了这张图,再粘贴一遍。如下图,这部分逻辑比较简单,就不写了,具体参考代码分析。

//得到节点的排名
//输入参数为表头结构zsl,分数score,真正的数据ele
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) {
zskiplistNode *x;
unsigned long rank = 0;
int i;
//先获取表头的头指针,即找到管理所有节点的level数组
x = zsl->header;
//从表头的level,即最大值开始循环遍历
for (i = zsl->level-1; i >= 0; i--) {
//如果找到分数小于目标分数的,排名加上其跨度
//或者分数相同,但是具体数据小于目标数据的,排名也加上跨度
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) <= 0))) {
rank += x->level[i].span;
x = x->level[i].forward;
}
//确保在第i层找到分值相同,且对象相同时才会返回排位值
if (x->ele && sdscmp(x->ele,ele) == 0) {
return rank;
}
}
return 0;
}
结语
该篇主要讲了Redis的ZSET数据类型的底层实现跳跃表,先从跳跃表是什么,引出跳跃表的概念和数据结构,剖析了其主要组成部分,进而通过多幅过程图解释了Redis是如何设计跳跃表的,最后结合源码对跳跃表进行描述,如创建过程,添加节点过程,获取某个节点排名过程,中间穿插例子和过程图。
如果觉得写得还行,麻烦给个赞,您的认可才是我写作的动力!
如果觉得有说的不对的地方,欢迎评论指出。
好了,拜拜咯。