第5章 文件系统的系统调用-1 - Unix操作系统设计-读书笔记
文章目录
- 第五章 文件系统的系统调用
- 5.1系统调用open
- 算法描述
- 实例讲解
- 5.2系统调用read
- 算法描述
- 实例讲解
- 小结
第五章 文件系统的系统调用
先介绍存取已存在的文件的系统调用,如open, read, write, lseek, close
然后介绍创建新文件的系统调用,如creat, mkmod
然后管理索引节点和文件系统的系统调用:chdir, chroot, chown, chmod, stat, fstat
更高级的系统调用:pipe, dup
系统调用mount, umount扩充了对用户可见的文件系统树
link, unlink修改文件系统层次的结构
本章还给出文件系统的抽象表示,是能兼容各种文件系统的关键;
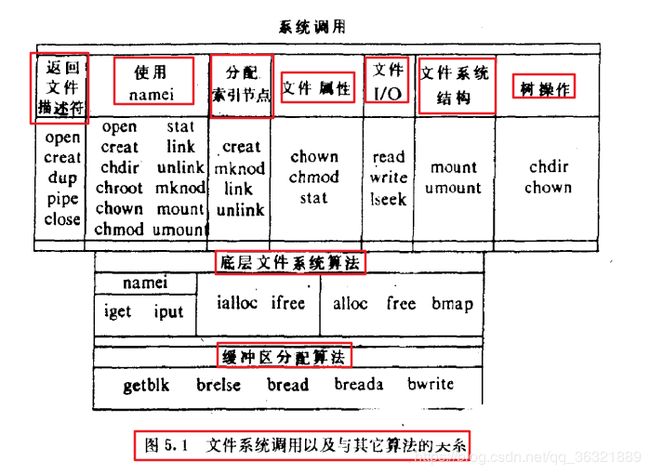
重新强调三个数据结构:
- 文件表:系统中每个打开的文件在文件表中都占有一项
- 用户文件描述符表:保存在每个进程的数据结构中,表示某个进程打开的文件列表
- 安装表:含有每个活动的文件系统的信息,这里的活动是什么意思?进程?
5.1系统调用open
系统调用open的语法格式是:fd=open(pathname, flags, modes)
参数含义:pathname表示文件路径;flags表示打开的类型(读或写);modes给出文件的许可权(如果文件正在被建立);
为什么open是系统调用啊,系统调用到底是什么样的概念?open不是一个函数嘛???
- open是Linux内核提供给C调用的一个函数
- 既然是系统提供的,那就称为系统调用????
算法描述
先看下算法open的描述:

- 首先调用namei,根据文件名找到索引节点
- 然后分配文件表项,文件表项中有一个指针,指向被打开文件的索引节点,其中还有一个域,指示文件中的偏移量;
- 还要操作下进程中的那个用户文件描述符表,其中保存文件表中的索引;
- 表项的索引就是返回给用户的用户描述符;
- 用户文件描述符表中的表项指向对应的全局文件表中的表项
这里面需要强调的是:文件表是全局的,用户文件描述符表是进程的; 其中文件表中保存了偏移量,即每次读从哪里开始,写从哪里开始等;
实例讲解
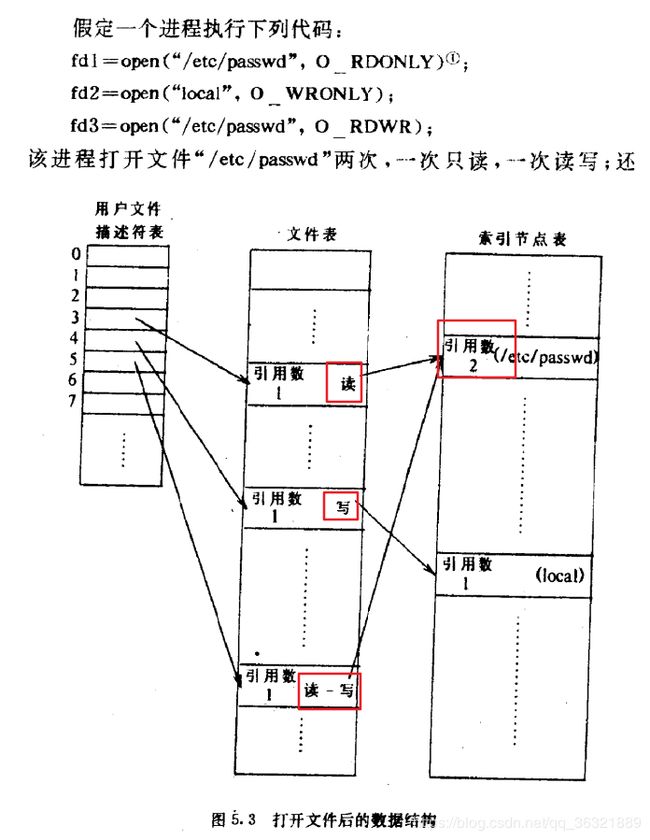
假设第二个进程执行下列代码:
fd1=open("/etc/passwd", O_RDONLY);
fd2=open(“private”, O_RDONLY);
得到如下结果:

注意点:每个open调用都导致在用户描述符表和核心文件表中分配一个唯一表项,但在核心的内容索引节点表中,对每个文件只有一个表项;
这本书里很好的解释了一些设计,比如既然用户文件描述表项和文件表表项一一对应,那么为什么还需要文件表呢?不用文件表,直接让用户文件表项和索引节点表项相互关联不就完事了嘛?
- Thompson指出,将文件表作为一个独立的数据机构来实现,是为了在若干用户文件描述符之间能够共享偏移量指针;
- 这里的含义能大概猜测下,即通过系统调用复制用户文件描述符,这样多个用户文件描述符指向同一个文件表项,也就共用了偏移量指针;
- 之后介绍的dup, fork就是通过管理这些数据结构来允许这种共享的;
上图中还展示了三项比较特殊的文件描述符,即0,1,2它们分别是标准输入、标准输出、错误输出,这个规定有助于帮助程序之间通过pipe来进行通讯;
5.2系统调用read
系统调用read的语法格式是:number=read(fd, buffer, count);
- fd是open返回的文件描述符
- buffer是用户进程中的一个数据结构的地址,用于存放读取的数据
- count是要读取的字节数
- number是实际读的字节数
算法描述
算法还是有点复杂的,看下算法描述叭:

步骤很多,不过核心思想还是很简单的:
- 使用bmap将文件的字节偏移量转换成磁盘块号
- 有了磁盘块号就可以读磁盘了,读磁盘是直接和buffer交互的,并不是直接读了磁盘
- 将某块读出来之后,然后再计算块中的偏移
- 知道了块中的偏移就可以将数据copy到传入的buffer中了
- 然后重复该过程,直到读完为止;
算法描述中,多次提到了u区中的一些参数:
- 方式:读、写
- 计数:已经读、写的字节数
- 偏移量:文件中的字节偏移量
- 地址:buffer
- 标志:指出地址是在用户空间还是在核心空间
实例讲解
#include 先看第一个read:
- 判断fd是否合法;
- 核心将buff、20、0(缓冲区地址、要读的字节数、字节偏移量)存入u区
- 核心计算出,字节偏移量0对应第0块,然后在索引节点中的第0块表项
- 将整块读入系统缓冲区,并将前20字节拷贝到用户地址buff中去
- 20变成0, 0变成20,表示下次将从文件中的第20字节处开始读数据
再看第二个read:
- 判断fd是否合法;
- 核心将bigbuff、1024、20存入u区
- 核心计算出,字节偏移量20对应第0块···,而且如果和第一次隔的时间比较短,可能还能命中缓冲,那么就节约时间了;得到磁盘块后,从20偏移处将后1004字节放入bigbuffer中;
- 然后三个参数变为:buffer、20、1024,然后读下一次磁盘块,···,
第二个read和第一个read其实没有区别,第二个read涉及到读第二个磁盘;
第三个read省略;
小结
从上面的例子说明,从文件系统块的边界开始、而且大小为块的整数倍的IO操作具有很多优点;这样能使核心避免额外地重复算法read的循环;循环会带来哪些效率的损耗呢?
- 首先是访问索引节点,以找到正确的块号
- 其次是和其他进程竞争对缓冲池的访问
关于breada,首先我们看下breada在Linux0.11中的定义,然后再讨论如何使用它:
struct buffer_head *breada(int dev, int first, ...) {
va_list args;
struct buffer_head *bh, *tmp;
va_start(args, first);
if (!(bh = getblk(dev, first))) panic("bread: getblk returned NULL\n");
if (!bh->b_uptodate) ll_rw_block(READ, bh);
while ((first = va_arg(args, int)) >= 0) {
tmp = getblk(dev, first);
if (tmp) {
if (!tmp->b_uptodate) ll_rw_block(READA, bh);
tmp->b_count--;
}
}
va_end(args);
wait_on_buffer(bh);
if (bh->b_uptodate) return bh;
brelse(bh);
return (NULL);
}
代码细节可以不用管,我们只看函数参数,是变长参数写法,所以可以预读很多磁盘块,下面我们讨论这里关于breada的应用:
- 当核心通过read循环时,它决定一个文件是否需要提前读;
- 如果一个进程顺序地读两个快,核心就假定所有后继的读都是顺序的,直到证明不是顺序的;
- 在循环的每次重复期间,核心将下一次逻辑块号保存在内存索引节点中,在下次循环期间,核心将当前逻辑块号和以前保存的逻辑块号相比较;
- 如果它们相等,核心将计算物理块号,这些物理块号为提前读的块号,将其值保存在u区,算法breada将使用它们;
- 当然,这里Unix的设计和Linux代码中的实现可能不太一样,但是思想是一样的;
讨论下有关锁的问题:
- 思考如果我们从open开始就将某个文件对应的索引节点锁住,直到close才将索引节点解开会发生什么?
- 比如,我电脑上运行了一个恶意程序,其open了/etc/passwd文件,没有close,那么如果有其他注册进程来检查/etc/passwd文件,那么其将永远睡眠,即该进程可能永远也无法得到执行,所以这样的设计并不合理;
- 真正的设计是这样的:每执行完一个系统调用都会将索引节点释放掉,那么这样也会带来问题;
- 连续两个read之间可能会有其他进程执行,将文件内容修改,那么两次read的内容将不同,的确有点出乎意料哈!
- 不过这种设计能保证核心数据结构一致,虽然用户数据可能会产生不一致的现象;
- 不过利用文件和记录上锁的方法,可以允许一个进程在保持一个文件打开期间,保证文件的一致性;
看下面代码:

该代码和只open一次,只使用一个fd1来read有什么区别呢?
- 如果只使用一个fd1的话,它们是共享文件内偏移量的;
- 如果共享文件内偏移量,那么第一个read读取之后,偏移量就改变了;
- 第二个read读取的内容和第一个read读取的内容就不一样咯;
- 需要注意的是:某个文件的偏移量保存在了全局的文件表中;