redis系列(一) redis安装以及基本类型简介
目录
redis安装方式:
1. Docker安装方式:
2. Git 源码方式:
3. 直接按装方式
2.redis对象简介
五种基本类型:
redis适配的规则:
2.1 String对象有三种编码:
2.2 List 对象
2.3 Hash对象,字典结构
2.4 Set对象:集合对象的编码可以是intset或者hashtable;
2.5 有序集合对象:有序集合对象额编码可以是ziplist或者ziplist
3. redis另外三种数据结构 bitmap+GeoHash+HyperLogLog;
3.1 bitmap:
3.2 HyperLogLog
4. Streams
| 序号 | 标题 | 链接 |
| 1 | redis系列(一) redis安装以及基本类型简介 | https://blog.csdn.net/qq_38130094/article/details/103760529 |
| 2 | redis系列(二) redis持久化 | https://blog.csdn.net/qq_38130094/article/details/103836261 |
| 3 | redis系列(三) redis主从复制 | https://blog.csdn.net/qq_38130094/article/details/103837263 |
| 4 | redis系列(四) redis哨兵模式与集群 | https://blog.csdn.net/qq_38130094/article/details/103842044 |
| 5 | redis系列(五) redis 缓存设计 | https://blog.csdn.net/qq_38130094/article/details/103842216 |
redis安装方式:
1. Docker安装方式:
#拉取redis镜像
> docker pull redis
#运行 redis 容器将容器的6379端口映射到主机的6379端口
> docker run --name myredis -d -p 6379:6379 redis
#执行容器中的redis-cli 可以直接使用命令操作redis
>docker exec -it myredis redis-cli2. Git 源码方式:
#下载源码
> git clone --branch 3.2 --depth 1 [email protected]:anthirez/redis.git
cd redis
#编译
>make
>cd src
#运行服务器,修改配置文件redis.conf daemonize表示在后台运行
>./redis-server --dameomize yes
#使用客户端连接
>./redis-cli3. 直接按装方式
#mac
>brew install redis
#ubuntu
>apt-get install redis
#redhat
>yum install redis
#运行客户端
>./redis-cli2.redis对象简介
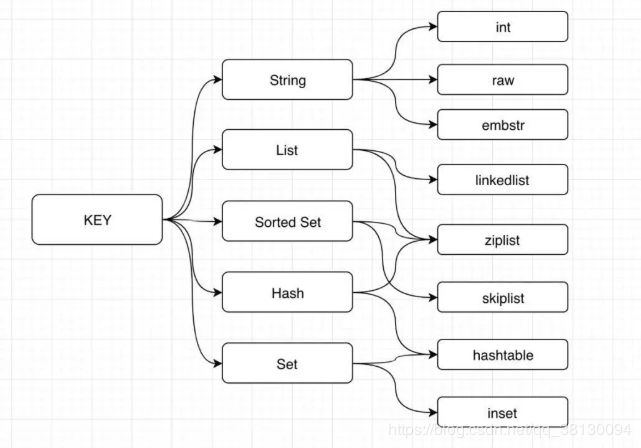
五种基本类型:
字符串:String 列表:List 集合:Set 哈希:Hash 有序集合:Sorted Set
redis对象在存储的时候编码类型都不一样
| 类型 | 编码 | 对象 |
| OBJ_STRING | OBJ_ENCODING_INT | 整数类型的字符串对象 |
| OBJ_STRING | OBJ_ENCODING_EMBSTR | EMBSTR字符串对象 |
| OBJ_STRING | OBJ_ENCODING_RAW | 动态字符串对象 |
| OBJ_LIST | OBJ_ENCODING_QUICKLIST | 快速列表实现的列表对象 |
| OBJ_HASH | OBJ_ENCODING_ZIPLIST | 压缩表实现的哈希对象 |
| OBJ_HASH | OBJ_ENCODING_HT | 字典表实现的哈希对象 |
| OBJ_SET | OBJ_ENCODING_INTSET | 整数集合实现的集合对象 |
| OBJ_SET | OBJ_ENCODING_HT | 字典实现的集合对象 |
| OBJ_ZSET | OBJ_ENCODING_ZIPLIST | 压缩实现的有序集合 |
| OBJ_ZSET | OBJ_ENCODING_SKIPLIST | 跳跃表实现的有序集合对象 |
redis适配的规则:
作用:通过设置encoding属性来设定对象所使用的编码。而不是为特定对象关联一种固定的编码。极大的提升了redis的灵活性和效率,因为redis可以根据使用场景来为一个对象设置不同的编码,从而优化对象在某个场景下的效率
| 一般情况 | 少量数据 | 特殊情况 | |
| String |
RAW | EMBSTR | INT |
| List | QUICKLIST(3.2版本以后) | ZIPLIST | |
| Set | HT | INTSET | |
| Hash | HT | ZIPLIST | |
| Sort Set | SKIPLIST | ZIPLIST |
2.1 String对象有三种编码:
- INT:可以用long类型保存数据
- EMBSTR:可以用long double 类型保存浮点数,字符长度小于等于44
- RAW:长度太大无法用long类型表示整数,长度太长无法使用long double 表示浮点型字符长度大于44
EMBSTR与RAW的对比:1:embstr编码将创建字符串对象所需的内存次数从raw编码的两次降低为一次。2:释放embstr编码的字符串对象只需调用一次内存释放函数,而释放raw编码字符串对象所需调用两次内存函数。3:embstr编码字符串对象的所有数据都保存在一块连续的内存例,所以更好的利用缓存带来的优势
127.0.0.1:6379>set number "7890"
OK
127.0.0.1:6379>objectencoding number
"int"
127.0.0.1:6379>set name "a1234567890123456789012345678901234567890123"
OK
127.0.0.1:6379> object encoding name
"embstr"
127.0.0.1:6379> set name "a12345678901234567890123456789012345678901234"
OK
127.0.0.1:6379> object encoding name
"raw"2.2 List 对象
List对象的编码是quicklislt;
list-max-ziplist-size参数的含义解释,取正值时表示quicklist节点ziplist包含的数据项,取负值表示按照占用字节来限定quicklsit节点ziplist的长度
- -5:每个quicklsit节点上的ziplist大小不能超过64k
- -4:每个quicklsit节点上的ziplist大小不能超过32K
- -3:每个quicklsit节点上的ziplist大小不能超过16K
- -2:每个quicklsit节点上的ziplist大小不能超过8K(默认值)
- -1:每个quicklsit节点上的ziplist大小不能超过4K
list-compress=depth。list设计最容易被访问的列表两端的数据,中间的访问频率最低,如果符合这个场景,list还有一个配置。可以对中间节点进行压缩,(采用的LZF--一种无损压缩算法)进一步节省内存
- 0:是个特殊值,表示不压缩(默认值)
- 1:表示quicklislt两端各有一个节点不压缩,中间节点压缩
- 2:表示quicklist两端各有2个节点不压缩,中间节点压缩
2.3 Hash对象,字典结构
hash对象的编码可以是ziplist或者是hashTable;
当哈希对象同时满足两个条件时,hash对象使用ziplist编码:
- 哈希对象保存的所有键值元素的长度都在64字节,可以通过配置文件中的hash-max-ziplist-value属性进行设置
- 哈希对象保存的键值对数量小于512个,可以通过配置文件中的hash-max-ziplist-entries属性改变默认值
HashTable采用渐进式rehash,负载因子=已使用节点数量/哈希表大小,在两种情况下哈希表进行扩展
- 当服务未执行BGSAVE或者NGWRITAOP,并且负载因子>1
- 当服务执行BGSAVE或者NGWRITAOP,并且负载因子>5
当负载因子<0.1对哈希表进行收缩
2.4 Set对象:集合对象的编码可以是intset或者hashtable;
当集合对象同时满足一下两个条件时,集合对象使用intset编码
集合对象保存的所有元素都是整数值
结合对象保存的键值对数量不超过512个,可以通过修改配置文件中的set-max-inset-entries属性改变默认值
2.5 有序集合对象:有序集合对象额编码可以是ziplist或者ziplist
当有序集合对象同时满足一下两个条件时,有序集合对象使用ziplsit编码
- 有序集合对象保存的所有成员长度小于64字节,可以通过配置文件zset-ziplist-value属性改变默认值
- 有序集合对象保存的所有元素数量小于128,可通过修改配置文件的zet-max-ziplist-entries属性改变默认值
Redis这样设计有两个好处:
可以自定义改进内部编码,而对外的数据结构和命令没有影响,这样一旦开发出更优秀的内部编码,无需改动对外数据结构和命令。
多种内部编码实现可以在不同场景下发挥各自的优势。例如ziplist比较节省内存,但是在列表元素比较多的情况下,性能会有所下降。这时候Redis会根据配置选项将列表类型的内部实现转换为linkedlist。
3. redis另外三种数据结构 bitmap+GeoHash+HyperLogLog;
1Byte=8bit;1int=4byte; float=4byte;long=8byte;char=2byte;
3.1 bitmap:
Redis提供setbit、getbit、bitcount、bitop、bitpos五个个命令处理二进制数组位;
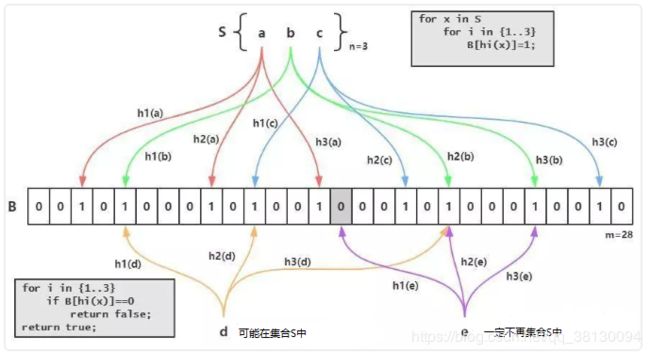
这个就是Redis实现的BloomFilter,BloomFilter非常简单,如下图所示,假设已经有3个元素a、b和c,分别通过3个hash算法h1()、h2()和h2()计算然后对一个bit进行赋值,接下来假设需要判断d是否已经存在,那么也需要使用3个hash算法h1()、h2()和h2()对d进行计算,然后得到3个bit的值,恰好这3个bit的值为1,这就能够说明:d可能存在集合中。再判断e,由于h1(e)算出来的bit之前的值是0,那么说明:e一定不存在集合中:
一、getbit key
1.计算byte = offset / 8,该值记录了offset偏移量指定的二进制位保存在位数组的哪个字节。
2.计算bit = (offset mod 8)+1,bit值记录了offset偏移量指定的二进制位是byte字节的第几个二进制位。
3.根据byte与bit返回位数组中指定的二进制位的值。
二、setbit key
1.计算所需位数组长度,len=(offset / 8)+1,len记录了保存offset指定的二进制位至少需要多少字节
2.检查key保存的位数组长度是否小于len,小于则扩展字符串长度位len字节,并将扩展的二进制位的值设置位0;
3.计算byte = offset / 8,该值记录了offset偏移量指定的二进制位保存在位数组的哪个字节
4.计算bit = (offset mod 8)+1,bit值记录了offset偏移量指定的二进制位是byte字节的第几个二进制位。
5.根据byte与bit设置位数组中指定的二进制位的值。
6.向客户端返回原值
三、bitcount key
bitcount [start][end]
四、bitop
bitop op destkey key[key....]
bitop是一个复合操作,它可以做多个Bitmaps的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在destkey中。
五、bitpos
bitpos key targetBit [start] [end]
bitops有两个选项[start]和[end],分别代表起始字节和结束字节bit位
3.2 HyperLogLog
HyperLogLog提供了3个命令:pfadd、pfcount、pfmerge。
在有些情况下, 我们只想要知道在线用户的人数, 而不需要知道具体的在线用户名单, 这时bitmap和集合储存的信息就会显得多余了。在需要尽可能地节约内存并且只需要知道在线用户数量的情况下, 我们可以使用HyperLogLog 来对在线用户进行统计: HyperLogLog 是一个概率算法, 它可以对元素的基数进行估算, 并且每个 HyperLogLog 只需要耗费 12 KB 内存, 对于用户数量非常多但是内存却非常紧张的系统, 这一方案无疑是最佳之选。
1.添加:pfadd key element [element … ],添加成功返1,失败返回0
2.统计数量:pfcount key [key …],返回数量
3.合并:pfmerge destkey sourcekey [sourcekey ...]
3.3GEO
geo两项关键技术:
- 使用geohash存储地理位置的坐标
- 使用有序集合(zset)存储地理位置的集合
geohash计算步骤:
-
首先将经度范围(-180, 180)平分成两个区间(-180,0)、(0, 180),如果目标经度位于前一个区间,则编码为0,否则编码为1。经度的编码长度为26位。
-
用同样的方法将纬度范围(-85.05112878,85.05112878)平分成两个区间(-85.05112878,0)、(0, 85.05112878)。如果目标纬度位于前一个区间,则编码为0,否则编码为1。纬度的编码长度为26位。
-
接下来将经度和纬度的编码合并,奇数位是纬度,偶数位是经度,得出52位的二进制经纬度值
-
将二进制经纬度转换成的整形数值保存到zset有序集合中,score为geohahs的52整形值,member为命令中的成员。
geohash有如下特点:
-
GEO的数据类型为zset,Redis将所有地理位置信息的geohash存放在zset中。
-
字符串越长表示的位置更精确。Redis使用的geohash编码长度为26位。可以精确到0.59m的精度。
-
两个字符串越相似,它们之间的距离越近,Redis利用字符串前缀匹配算法实现相关的命令。
-
geohash编码和经纬度是可以相互转换的。
命令:
1.增加地理位置信息:geoadd key longitude latitude member [longitude latitude member ...]
有效的经度是[-180,180]
-
有效的纬度是[-85.05112878,85.05112878]
2.获取地理位置信息:geopos key member [member ...]
3.获取两个地理位置的距离:geodist key member1 member2 [unit]
其中unit代表返回结果的单位,包含以下四种:
·m(meters)代表米。
·km(kilometers)代表公里。
·mi(miles)代表英里。
·ft(feet)代表尺。
4.获取指定位置范围内的地理信息位置集合:georadius key longitude latitude radiusm|km|ft|mi [withcoord] [withdist]
[withhash] [COUNT count] [asc|desc] [store key] [storedist key]
georadiusbymember key member radiusm|km|ft|mi [withcoord] [withdist]
[withhash] [COUNT count] [asc|desc] [store key] [storedist key]
·withcoord:返回结果中包含经纬度。
·withdist:返回结果中包含离中心节点位置的距离。
·withhash:返回结果中包含geohash,有关geohash后面介绍。
·COUNT count:指定返回结果的数量。
·asc|desc:返回结果按照离中心节点的距离做升序或者降序。
·store key:将返回结果的地理位置信息保存到指定键。
·storedist key:将返回结果离中心节点的距离保存到指定键。
6. 获取geohash:geohash key member [member ...]
从指定member中读取geohash整形值转为52位二进制数据,然后进行base32编码。
该命令最终将返回11个字符的Geohash字符串。
7. 删除地理位置信息:zrem key member
4. Streams
这是Redis5.0引入的全新数据结构,用一句话概括Streams就是Redis实现的内存版kafka。而且,Streams也有Consumer Groups的概念。通过Redis源码中对stream的定义我们可知,streams底层的数据结构是radix tree:
在Redis源码的rax.h文件中有一段这样的描述,这样看起来就比较直观:

Radix Tree(基数树) 事实上就几乎相同是传统的二叉树。仅仅是在寻找方式上,以一个unsigned int类型数为例,利用这个数的每个比特位作为树节点的推断。能够这样说,比方一个数10001010101010110101010,那么依照Radix 树的插入就是在根节点,假设遇到0,就指向左节点,假设遇到1就指向右节点,在插入过程中构造树节点,在删除过程中删除树节点。如下是一个保存了7个单词的Radix Tree: