Docker入门(十二):制作hadoop3.0.3集群镜像
文章目录
- 一、环境
- 二、运行zookeeper集群镜像
- 三、配置环境变量
- 四、修改配置文件(三台服务器同步操作)
- 4.1 修改hadoop-env.sh文件
- 4.2 修改core-site.xml文件
- 4.3 修改yarn-site.xml文件
- 4.4 修改mapred-site.xml文件
- 4.5 修改hdfs-site.xml文件(master)
- 4.6 修改hdfs-site.xml文件(slave1)
- 4.7 修改hdfs-site.xml文件(slave2)
- 4.8 修改workers文件
- 4.9 修改start-dfs.sh和stop-dfs.sh文件
- 4.10 修改start-yarn.sh和stop-yarn.sh文件
- 五、启动Hadoop集群
- 5.1初始化NameNode(在master上操作)
- 5.2启动HDFS(在master上操作)
- 5.3启动yarn(在master上操作)
- 5.4查看进程
- 5.5访问
- 六、保存,上传镜像
https://blog.csdn.net/sujiangming/article/details/88884679
一、环境
docker版本
[root@localhost opt]# docker --version
Docker version 19.03.1, build 74b1e89
docker网络
[root@localhost opt]# docker network ls
NETWORK ID NAME DRIVER SCOPE
d05f84a8746f bridge bridge local
398d73e5b1ed hadoop_net bridge local
da5e746c4d2e host host local
bfa3adcc971d none null local
| IP | 主机名 | HDFS | MapReduce/Yarn |
|---|---|---|---|
| 172.10.0.2 | master | NameNode | ResourceManager |
| 172.10.0.3 | slave1 | DataNode | NodeManager |
| 172.10.0.4 | slave2 | DataNode | NodeManager |
安装hadoop参考之前的博客:https://blog.csdn.net/qq_39680564/article/details/89513162#51NameNode_232
二、运行zookeeper集群镜像
镜像制作方法:https://blog.csdn.net/qq_39680564/article/details/97941048
从仓库拉取镜像
docker pull 192.168.0.20:5000/zookeeper:slave2
docker pull 192.168.0.20:5000/zookeeper:slave1
docker pull 192.168.0.20:5000/zookeeper:master
启动master:
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.2 \
-h master \
-p 10022:22 \
-p 2181:2181 \
-p 2887:2888 \
-p 3887:3888 \
-p 9870:9870 \
-p 8088:8088 \
--restart always \
--name master \
192.168.0.20:5000/zookeeper:master
启动slave1:
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.3 \
-h slave1 \
-p 20022:22 \
-p 2182:2181 \
-p 2888:2888 \
-p 3888:3888 \
-p 9864:9864 \
-p 8042:8042 \
--restart always \
--name slave1 \
192.168.0.20:5000/zookeeper:slave1
启动slave2:
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.4 \
-h slave2 \
-p 30022:22 \
-p 2183:2181 \
-p 2889:2888 \
-p 3889:3888 \
-p 9865:9864 \
-p 8043:8042 \
--restart always \
--name slave2 \
192.168.0.20:5000/zookeeper:slave2
三、配置环境变量
将hadoop包复制到容器中
docker cp hadoop-3.0.3 master:/opt/
docker cp hadoop-3.0.3 slave1:/opt/
docker cp hadoop-3.0.3 slave2:/opt/
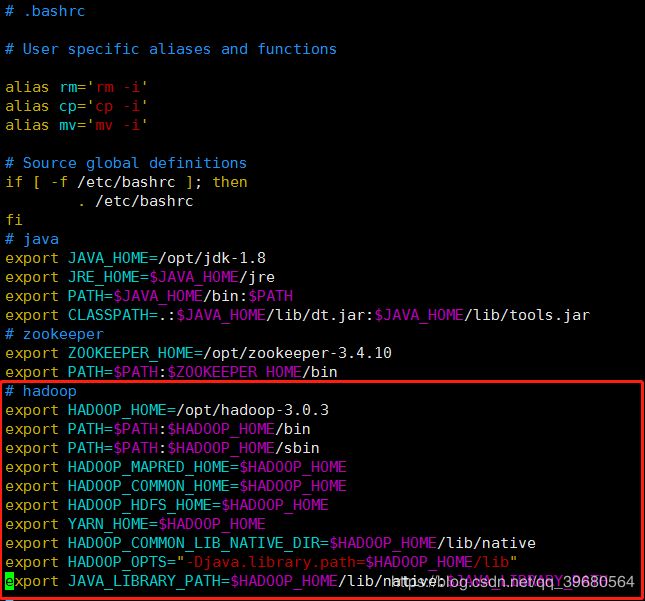
vim ~/.bashrc
新增内容
# hadoop
export HADOOP_HOME=/opt/hadoop-3.0.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
刷新生效
source ~/.bashrc
如图
四、修改配置文件(三台服务器同步操作)
4.1 修改hadoop-env.sh文件
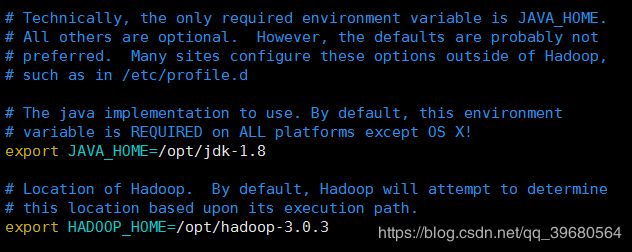
vim /opt/hadoop-3.0.3/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/jdk-1.8
export HADOOP_HOME=/opt/hadoop-3.0.3
如图
4.2 修改core-site.xml文件
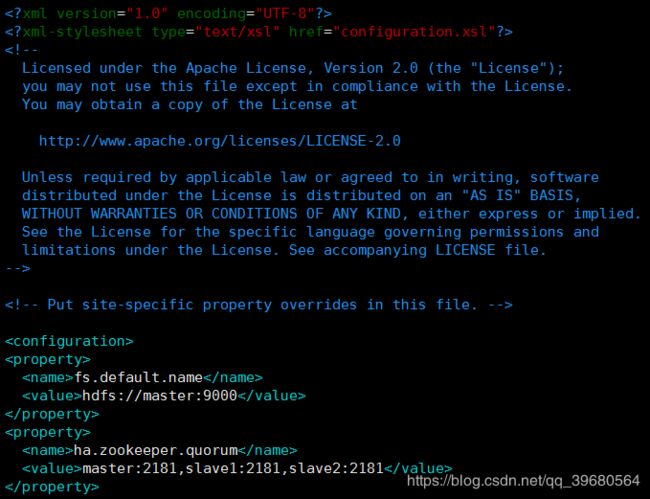
vim /opt/hadoop-3.0.3/etc/hadoop/core-site.xml
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>master:2181,slave1:2181,slave2:2181value>
property>
如图
4.3 修改yarn-site.xml文件
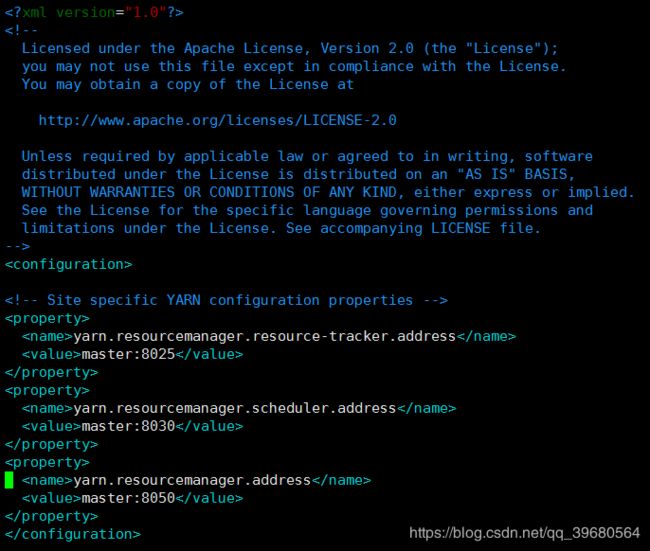
vim /opt/hadoop-3.0.3/etc/hadoop/yarn-site.xml
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8025value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8050value>
property>
如图
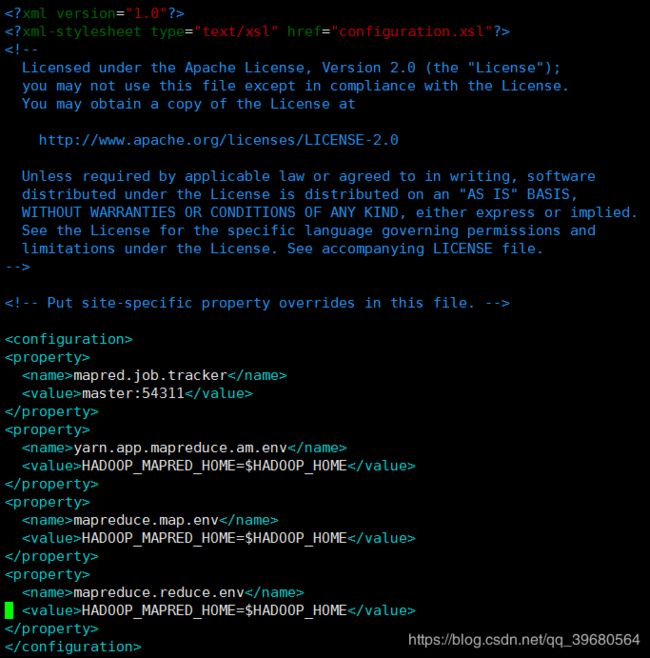
4.4 修改mapred-site.xml文件
vim /opt/hadoop-3.0.3/etc/hadoop/mapred-site.xml
<property>
<name>mapred.job.trackername>
<value>master:54311value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOMEvalue>
property>
如图
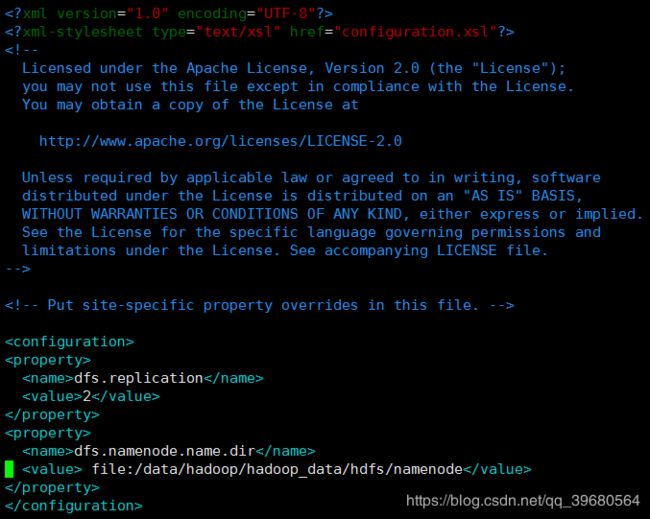
4.5 修改hdfs-site.xml文件(master)
创建数据目录
mkdir -p /data/hadoop/hadoop_data/hdfs/namenode
chown -R root:root /data/hadoop
vim /opt/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value> file:/data/hadoop/hadoop_data/hdfs/namenodevalue>
property>
如图
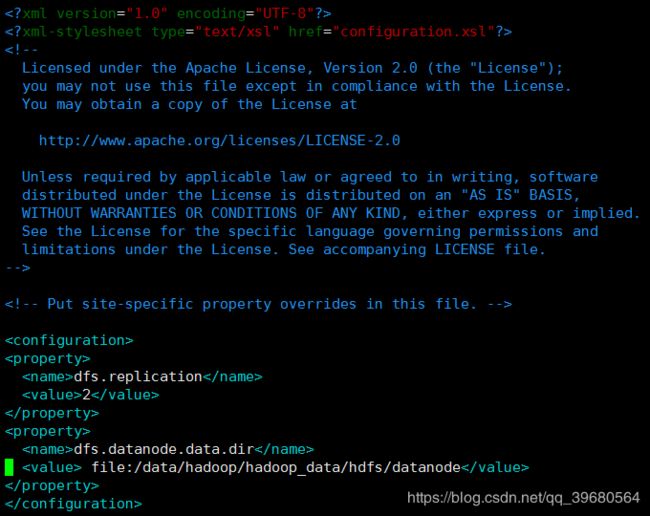
4.6 修改hdfs-site.xml文件(slave1)
创建数据目录
mkdir -p /data/hadoop/hadoop_data/hdfs/datanode
chown -R root:root /data/hadoop
vim /opt/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value> file:/data/hadoop/hadoop_data/hdfs/datanodevalue>
property>
如图
4.7 修改hdfs-site.xml文件(slave2)
创建数据目录
mkdir -p /data/hadoop/hadoop_data/hdfs/datanode
chown -R root:root /data/hadoop
vim /opt/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value> file:/data/hadoop/hadoop_data/hdfs/datanodevalue>
property>
如图
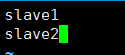
4.8 修改workers文件
vim /opt/hadoop-3.0.3/etc/hadoop/workers
slave1
slave2
如图
4.9 修改start-dfs.sh和stop-dfs.sh文件
vim /opt/hadoop-3.0.3/sbin/start-dfs.sh
vim /opt/hadoop-3.0.3/sbin/stop-dfs.sh
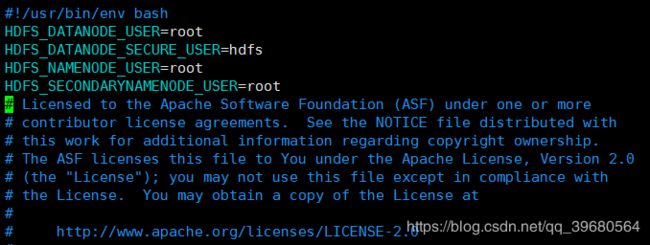
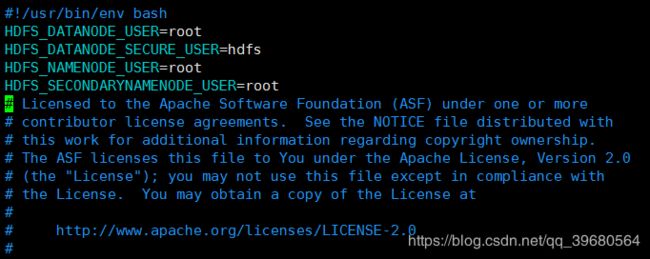
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
如图
4.10 修改start-yarn.sh和stop-yarn.sh文件
vim /opt/hadoop-3.0.3/sbin/start-yarn.sh
vim /opt/hadoop-3.0.3/sbin/stop-yarn.sh
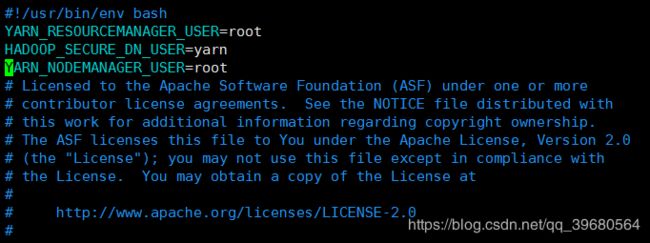
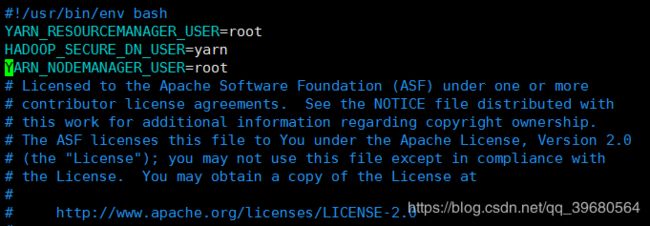
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
如图
五、启动Hadoop集群
5.1初始化NameNode(在master上操作)
/opt/hadoop-3.0.3/bin/hadoop namenode -format
初始化成功,为0成功

5.2启动HDFS(在master上操作)
/opt/hadoop-3.0.3/sbin/start-dfs.sh
[root@master ~]# /opt/hadoop-3.0.3/sbin/start-dfs.sh
Starting namenodes on [master]
Last login: 四 8月 1 14:01:36 CST 2019 on pts/0
Starting datanodes
Last login: 四 8月 1 14:02:36 CST 2019 on pts/0
Starting secondary namenodes [master]
Last login: 四 8月 1 14:02:39 CST 2019 on pts/0
2019-08-01 14:03:03,804 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable

5.3启动yarn(在master上操作)
/opt/hadoop-3.0.3/sbin/start-yarn.sh
[root@master ~]# /opt/hadoop-3.0.3/sbin/start-yarn.sh
Starting resourcemanager
Last login: 四 8月 1 14:02:50 CST 2019 on pts/0
Starting nodemanagers
Last login: 四 8月 1 14:05:12 CST 2019 on pts/0

5.4查看进程
master
[root@master ~]# jps
33 QuorumPeerMain
249 NameNode
507 SecondaryNameNode
1067 Jps
749 ResourceManager
slave1
[root@slave1 ~]# jps
33 QuorumPeerMain
249 NodeManager
138 DataNode
382 Jps
slave2
[root@slave2 ~]# jps
33 QuorumPeerMain
243 NodeManager
132 DataNode
376 Jps
5.5访问
HDFS
192.168.0.138:9870
192.168.0.138:9864
192.168.0.138:9865
YARN
192.168.0.138:8088
192.168.0.138:8042
192.168.0.138:8043
六、保存,上传镜像
保存镜像
docker commit master 192.168.0.20:5000/hadoop:master
docker commit slave1 192.168.0.20:5000/hadoop:slave1
docker commit slave2 192.168.0.20:5000/hadoop:slave2
上传镜像至仓库
docker push 192.168.0.20:5000/hadoop:master
docker push 192.168.0.20:5000/hadoop:slave1
docker push 192.168.0.20:5000/hadoop:slave2
启动方法
master
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.2 \
-h master \
-p 10022:22 \
-p 2181:2181 \
-p 2887:2888 \
-p 3887:3888 \
-p 9870:9870 \
-p 8088:8088 \
--restart always \
--name master \
192.168.0.20:5000/hadoop:master
slave1
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.3 \
-h slave1 \
-p 20022:22 \
-p 2182:2181 \
-p 2888:2888 \
-p 3888:3888 \
-p 9864:9864 \
-p 8042:8042 \
--restart always \
--name slave1 \
192.168.0.20:5000/hadoop:slave1
slave2
docker run -d \
--add-host master:172.10.0.2 \
--add-host slave1:172.10.0.3 \
--add-host slave2:172.10.0.4 \
--net hadoop_net \
--ip 172.10.0.4 \
-h slave2 \
-p 30022:22 \
-p 2183:2181 \
-p 2889:2888 \
-p 3889:3888 \
-p 9865:9864 \
-p 8043:8042 \
--restart always \
--name slave2 \
192.168.0.20:5000/hadoop:slave2
先启动zookeeper,再启动hdfs,最后启动yarn
/opt/zookeeper-3.4.10/bin/zkServer.sh start #每台服务器启动zookeeper
/opt/zookeeper-3.4.10/bin/zkServer.sh status #查看启动状态
/opt/hadoop-3.0.3/sbin/start-dfs.sh #master启动HDFS
/opt/hadoop-3.0.3/sbin/start-yarn.sh #master启动yarn