时间序列分析-python(一、自相关系数的意义)
最近在学习时间序列预测销量,做一些笔记。
参考:
自相关系数
根据自相关图判断AR/MA/ARMA模型
平稳时间序列
时间序列必须是平稳的才可以做后续分析,差分和log都是为了使时间序列平稳。
一个时间序列,如果均值和方差没有系统变化或周期性变化(均值无变化:没有明显趋势,方差无变化:波动比较稳定),就称之为平稳的。
自相关系数
平稳序列的自相关系数会快速收敛,从哪一阶开始快速收敛(忽然从一个较大的值降到0附近)就说明是哪一阶模型,例如自相关函数图拖尾,偏自相关函数图截尾,n从2或3开始控制在置信区间之内,因而可判定为AR(2)模型或者AR(3)模型。
从自相关系数原理来讲,“n从2或3开始”的含义是指:自相关系数的阶数为2阶或3阶时迅速降为0附近,即在剔除了中间的2或3个变量后,序列开始稳定。
下面是自相关系数的原理(点击打开链接):
自相关系数是不变的,是参数,不会衰减至零。xt=rho*xt-1+eslion,其中rho为自相关系数。自回归方程本质就是一个差分方程,解这个方程的根就可得到xt随着t的变化的解,如果根的模大于1,xt就是爆炸或趋于无穷的,不收敛。当自相关系数约等于1,就是单位根,也是不收敛。

我们手算一个自相关系数就明白了:

并动手编成了一个小函数,加深理解
def get_auto_corr(timeSeries,k):
'''
Descr:输入:时间序列timeSeries,滞后阶数k
输出:时间序列timeSeries的k阶自相关系数
l:序列timeSeries的长度
timeSeries1,timeSeries2:拆分序列1,拆分序列2
timeSeries_mean:序列timeSeries的均值
timeSeries_var:序列timeSeries的每一项减去均值的平方的和
'''
l = len(timeSeries)
#取出要计算的两个数组
timeSeries1 = timeSeries[0:l-k]
timeSeries2 = timeSeries[k:]
timeSeries_mean = timeSeries.mean()
timeSeries_var = np.array([i**2 for i in timeSeries-timeSeries_mean]).sum()
auto_corr = 0
for i in range(l-k):
temp = (timeSeries1[i]-timeSeries_mean)*(timeSeries2[i]-timeSeries_mean)/timeSeries_var
auto_corr = auto_corr + temp
return auto_corr看到最后计算的那部分,如果举个反例,有一个序列A{1,10,100,1000,10000}和序列B{100,1,1000,10,10000}
序列A和B的方差和均值都是相等的,所以自相关系数的取值关键看拆分的两个序列。但是序列A具有明显的递增趋势,按照前面的理解,序列A不稳定的概率要比B大。

额,结果好像有点出人意料。
我们再编一个函数画出它们的自相关系数图看看,结果好像也没有差别。
def plot_auto_corr(timeSeries,k):
'''
Descr:需要计算自相关函数get_auto_corr(timeSeries,k)
输入时间序列timeSeries和想绘制的阶数k,k不能超过timeSeries的长度
输出:k阶自相关系数图,用于判断平稳性
'''
timeSeriestimeSeries = pd.DataFrame(range(k))
for i in range(1,k+1):
timeSeriestimeSeries.loc[i-1] =get_auto_corr(timeSeries,i)
plt.bar(range(1,len(timeSeriestimeSeries)+1),timeSeriestimeSeries[0])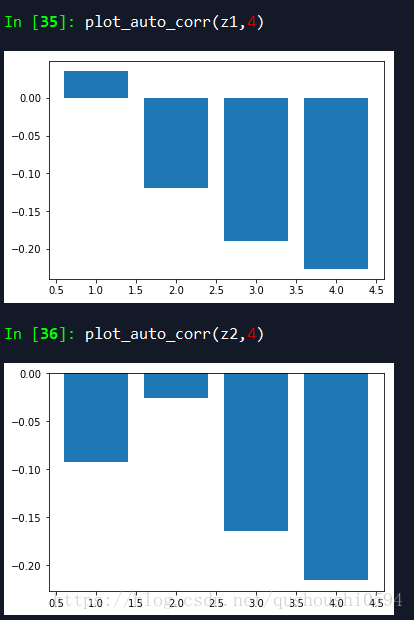
拆分一下序列A和B:
A1:{1,10,100,1000}
A2:{10,100,1000,10000}
B1: {100,1,1000,10}
B2: {1,1000,10,10000}
感觉自相关系数图不按照设想的反例的原因是分子没有加绝对值,有些项减去均值后为正,有些项减去均值后为负,抵消了。
所以为什么自相关系数迅速收敛可以判断序列平稳呢,序列平稳是没有趋势性的,而上面反例中A比B的趋势性要明显。
自相关系数应该描述的不是趋势性,而是序列1和序列2的相关性,显然如果序列1和序列2完全相同,自相关系数为0,以序列C为例{1,1,1,1,1},显然不管多少阶的自相关系数都为0
序列D{1,1,1,1,2},自相关系数的值会比较小,而且如果有序列E{2,1,1,1,1},我们可以发现D和E的自相关系数图是一样的!如果有F{1,1,2,1,1},把2放在中间才会有改变,那么再有G{2,2,3,2,2},会发现F和G的自相关系数图又会保持一致,A{2,2,2,2,3}会和序列D、E的自相关系数图一致。

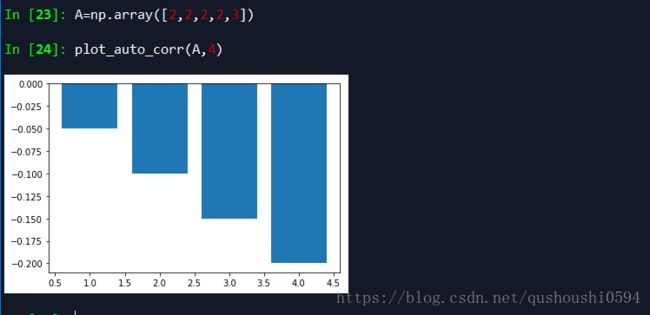


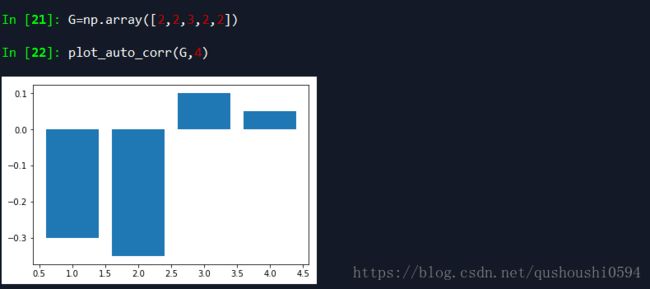
从前面可以看出,自相关系数在{1,1,1,1,1}的时候最小为0,在序列{1,2,3,4,5}的时候会比较大。所以自相关系数到底有没有一个具体的确切含义呢?
第2个例子,这3个序列的自相关系数是近似的,不完全相等,例如A的一阶相关系数大概是0.2999999999,B是3.00000000004
A=np.array([1,1,2,1,1])
B=np.array([100,100,200,100,100])
C=np.array([100,100,101,100,100])
plot_auto_corr(A,4)
Out[10]:
0
0 -0.30
1 -0.35
2 0.10
3 0.05
plot_auto_corr(B,4)
Out[11]:
0
0 -0.30
1 -0.35
2 0.10
3 0.05
plot_auto_corr(C,4)
Out[12]:
0
0 -0.30
1 -0.35
2 0.10
3 0.05
目前得出来的结论就是自相关系数可以用来衡量序列的值的差异性,但是为什么随着自相关系数的阶数增加,自相关系数迅速下降到0附近的序列就是稳定时间序列的证明。需要查阅专业书籍。
(补充“https://uqer.io/community/share/5790a091228e5b90cda2e2ea”,这个链接里面说得很清楚了,解决了许多自相关系数的疑问)先到这里,去看arch包吧。
根据自相关系数图判断使用模型
https://www.cnblogs.com/foley/p/5582358.html
完整程序:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
timeSeries = np.array([2,3,4,3,7])
k = 1
timeSeries1 = np.array([1,10,100,1000,10000])
timeSeries2 = np.array([100,1,1000,10,10000])
def get_auto_corr(timeSeries,k):
'''
Descr:输入:时间序列timeSeries,滞后阶数k
输出:时间序列timeSeries的k阶自相关系数
l:序列timeSeries的长度
timeSeries1,timeSeries2:拆分序列1,拆分序列2
timeSeries_mean:序列timeSeries的均值
timeSeries_var:序列timeSeries的每一项减去均值的平方的和
'''
l = len(timeSeries)
#取出要计算的两个数组
timeSeries1 = timeSeries[0:l-k]
timeSeries2 = timeSeries[k:]
timeSeries_mean = timeSeries.mean()
timeSeries_var = np.array([i**2 for i in timeSeries-timeSeries_mean]).sum()
auto_corr = 0
for i in range(l-k):
temp = (timeSeries1[i]-timeSeries_mean)*(timeSeries2[i]-timeSeries_mean)/timeSeries_var
auto_corr = auto_corr + temp
return auto_corr
#画出各阶自相关系数的图
k=4
def plot_auto_corr(timeSeries,k):
'''
Descr:需要计算自相关函数get_auto_corr(timeSeries,k)
输入时间序列timeSeries和想绘制的阶数k,k不能超过timeSeries的长度
输出:k阶自相关系数图,用于判断平稳性
'''
timeSeriestimeSeries = pd.DataFrame(range(k))
for i in range(1,k+1):
timeSeriestimeSeries.loc[i-1] =get_auto_corr(timeSeries,i)
plt.bar(range(1,len(timeSeriestimeSeries)+1),timeSeriestimeSeries[0])
return timeSeriestimeSeries