基于 PyTorch 实现 ResNet-18 并在Cifar-10数据集上进行验证
介绍
ResNet
ResNet 论文:
Deep Residual Learning for Image Recognition
通常的认识是,神经网络的深度越深,效果越好;但事实并不完全一致,太深的神经网络很容易导致梯度消失或梯度爆炸。ResNet 网络的提出,就是为了解决网络深度增加的问题。
ResNet 提出了一个新的网络块——残差块:
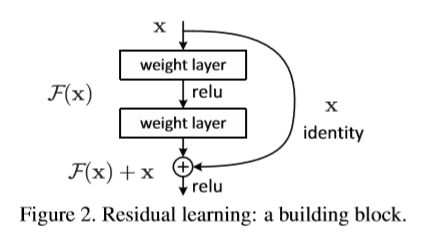
即可以把网络的输入加上后两层的输出,一起作为第三层的输入。ResNet 网络由很多个这种跨层直连的残差块组成,每个残差块(Resudual block)通过输入与输出的相加,来减少信息在传递过程的损耗,这在一定程度上缓解了网络因深度增加而导致梯度消失或梯度爆炸的现象。
不同的残差块
论文中提到了两种残差块:

右侧的 bottleneck 结构完全可以代替左侧的残差块,文章中,在层数较少的时候(18、34),使用了左侧的结构;层数较多时(50、101、152),使用了右侧的结构。三层的残差块,有先降维再升维的操作,从而使得 3x3 卷积的操作不受输入的维度影响,同时也不影响输出的维度。
结构特点
简而言之,当网络输入是 X,输出 H(X) 时,我们要学习的目标是 H(X)-X。ResNet 将学习目标改变了,学习的是输出减去输入(H(X)-X),一个残差。
关于 ResNet 很多文章中是这样形容的,我觉得形容的很贴切:
ResNet 直接将输入信息绕道传到输出,保护信息的完整性。
最后要注意的是,由于最后的输出是输入 X 和计算的结果之和,因此,二者维度一定是相同的。
实验要求
-
要求实现ResNet-18。均要求5个epoch以内达到50%的测试集精度。
-
可设定是否使用GPU,通过argparse包实现,默认参数设定为GPU
-
自行实现dataset(基于opencv或Pillow)
代码地址:lab3 ResNet
代码
代码参考了网上很多前辈们的思想,文末附有链接。
import torch
import torch.nn.functional as F
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from dataset import Cifar10Dataset
from tensorboardX import SummaryWriter
import torchvision
class ResidualBlock(nn.Module):
"""
子 module: Residual Block ---- ResNet 中一个跨层直连的单元
"""
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
# 如果输入和输出的通道不一致,或其步长不为 1,需要将二者转成一致
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
out += self.shortcut(x) # 输出 + 输入
out = F.relu(out)
return out
class ResNet(nn.Module):
"""
实现主 module: ResNet-18
ResNet 包含多个 layer, 每个 layer 又包含多个 residual block (上面实现的类)
因此, 用 ResidualBlock 实现 Residual 部分,用 _make_layer 函数实现 layer
"""
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
# 最开始的操作
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
# 四个 layer, 对应 2, 3, 4, 5 层, 每层有两个 residual block
self.layer1 = self._make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self._make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self._make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self._make_layer(ResidualBlock, 512, 2, stride=2)
# 最后的全连接,分类时使用
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, block, channels, num_blocks, stride):
"""
构建 layer, 每一个 layer 由多个 residual block 组成
在 ResNet 中,每一个 layer 中只有两个 residual block
"""
layers = []
for i in range(num_blocks):
if i == 0: # 第一个是输入的 stride
layers.append(block(self.inchannel, channels, stride))
else: # 后面的所有 stride,都置为 1
layers.append(block(channels, channels, 1))
self.inchannel = channels
return nn.Sequential(*layers) # 时序容器。Modules 会以他们传入的顺序被添加到容器中。
def forward(self, x):
# 最开始的处理
out = self.conv1(x)
# 四层 layer
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
# 全连接 输出分类信息
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def Accuracy(testloader, net, device):
# 使用测试数据测试网络
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
# 将输入和目标在每一步都送入GPU
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
return 100.0 * correct / total
def run(device):
# 超参数设置
# 批处理尺寸(batch_size)
BATCH_SIZE = 128
# 学习率
LR = 0.1
# 加载数据集
# 标准化为范围在[-1, 1]之间的张量
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 训练集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, transform=transform) # 训练数据集
# 生成一个个batch进行批训练,组成batch的时候顺序打乱取
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
# 测试集
testset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=False)
# Cifar-10的标签
# 建立神经网络
net = ResNet(ResidualBlock).to(device)
writer = SummaryWriter('./logs_resNet')
# 定义损失函数
criterion = nn.CrossEntropyLoss() # 损失函数为交叉熵,多用于多分类问题
# 优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4)
# 训练网络
# loop over the dataset multiple times
for epoch in range(5):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 取数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
# 将梯度置零
optimizer.zero_grad()
# 训练
outputs = net(inputs)
loss = criterion(outputs, labels).to(device)
loss.backward() # 反向传播
optimizer.step() # 优化
# 统计数据
running_loss += loss.item()
if i % 20 == 19: # 每 2000 张图片,打印一次
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 2000))
writer.add_scalar('train_loss', running_loss / 2000, epoch * 380 + i + 1)
running_loss = 0.0
acc = Accuracy(testloader, net, device)
writer.add_scalar('test_accuracy', acc, epoch * 380 + i + 1)
参考
-
pytorch之ResNet18(对cifar10数据进行分类准确度达到94%)
-
ResNet介绍
-
经典分类CNN模型系列其四:Resnet
-
深度残差网络RESNET
话说,ResNet 的文章真的多,很多文章都很不错,大家可以自己多看看,这里就先列出这三个吧,网络思想比较容易理解,不要想得太难。