Linux性能优化
导言:在linux系统中检查指标和影响性能的主要分为以下四个大块:
1、CPU
2、内存
3、文件系统和I/O模块
4、网络
一、CPU
1、CPU的性能指标主要由:CPU使用率、上下文切换、平均负载、CPU缓存命中率所影响。
2、检查工具:top(可现实内存使用情况,CPU使用率)、pidstat(可查看每个进程的CPU使用率)、ps(查看进程的运行端口等信息),uptime(用来查看1min,5min,15min的平均负载------这里的平均负载应注意不单单指的是cpu还包括I/O的情况。)
3、进程的状态:
S:可中断睡眠状态
R:运行状态
Z:僵尸状态
T:中断状态
D:不可中断状态(读取磁盘的时候)
4、系统压力测试工具:stress(模拟进程),sysbench(模拟线程)
5、CPU的上下文切换:主要分为3种(上下文的切换涉及到系统调用,耗费系统的性能)
(1)进程上下文切换:不同进程之间的切换,进程的切换涉及到栈、堆等信息的保存
(2)线程上下文切换:进程的调度和管理是由内核来管理的,而其中所管理的单位就是线程,进程知识给每个线程提供了虚拟内存、全局变量等信息。线程切换也要保存临时信息
(3)中断上下文切换:比如磁盘请求等,中断指的是当前系统运行某个请求,这时候有另外一个请求来了,系统必须通知该请求。
6、软中断和硬中断
硬中断:外部硬件设备、磁盘、键盘灯中断
软中断:由软件、程序内的定时器、RCU锁、网路请求分发(软硬中断均有)
7、 一般的检查流程:
<1> top 查看iostat,看是I/O引起的还是CPU引起的
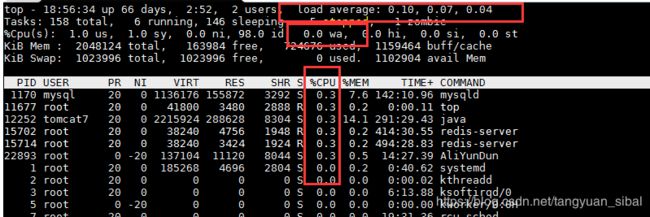
<2>pidstat 查看是哪个程序所引起的,查看哪个程序的CPU使用率比较高
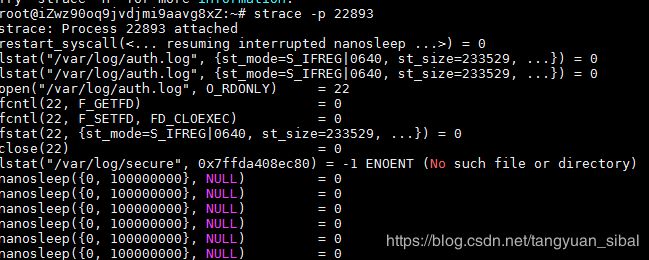
<3>strace追踪程序调用栈查看是那一部分出现的问题。
<4>如果是中断引起的,还可以查看proc文件夹下的(这个文件夹主要保存着用户和内核的交互文件)
2、内存
1、内存的性能指标:系统内存指标、进程内存指标、swap
2、linux通常是通过内存映射来管理内存的
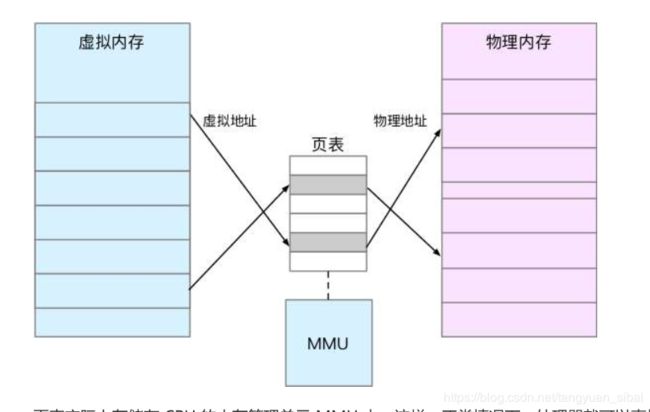
通常真正的物理内存不是很大,所以通过虚拟内存的方式,将磁盘的地址映射到物理地址的某一段空间。
3、虚拟内存的空间通常由以下几个部分组成
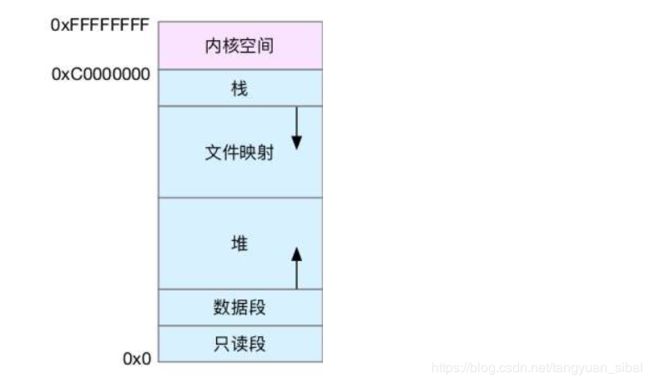
其中的堆和文件映射时动态分配,其他都是静态分配,比如数据段和只读段、栈在运行时自动创建,而堆和文件映射可由用户进行配置。
4、在出现内存紧张的时候,系统会进行一系列的机制来进行内存回收
<1>回收缓存(LRU算法)
<2>回收不常访问的内存,把不常用的内存通过交换分区换到磁盘上面(swap分区),注意这里是整个进行,而页面置换算法只是置换进程的某一部分。
<3>杀死进程,< OOM >,直接杀掉占用大量内存的进程
5、
(1)常用命令:free(查看总的内存情况,使用情况,空闲情况,缓存情况)

其中要区分buffer和cache,一个是磁盘的缓存,一个是文件系统的缓存,通常为了给用户更好的使用,操作系统会提供文件系统,通过文件系统在到磁盘,但是也有可能存在直接I/O的。
(2)用top查看进程的内存使用情况
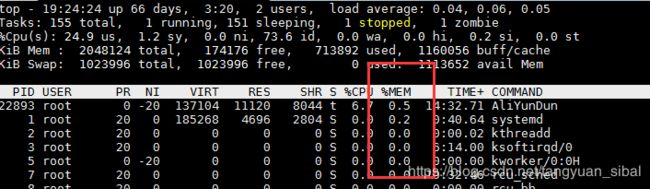
(3)vmstat

3、文件系统和I/O模块
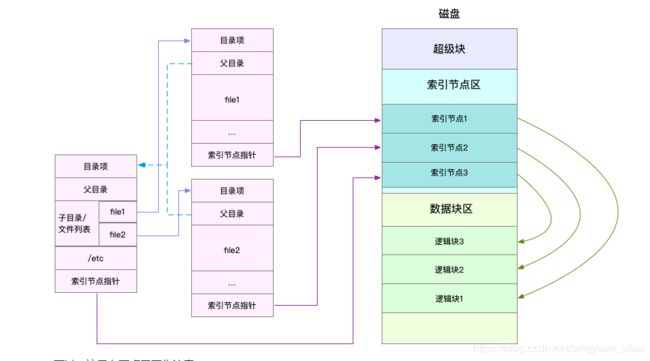
1、每个文件系统都为文件分配两个数据结构,一个是索引节点(inode)和目录项
(1)索引节点:索引节点,简称为inode,用来记录文件的元数据,比如inode编号、文件大小、访问权限、修改日期、数据的位置等。索引节点和文件一一对应,它跟文件内容一样,都会被持久化存储到磁盘中。所以记住,索引节点同样占用磁盘空间。
(2)目录项,简称为dentry,用来记录文件的名字、索引节点指针以及与其他目录项的关联关系。多个关联的目录项,就构成了文件系统的目录结构。不过,不同于索引节点,目录项是由内核维护的一个内存数据结构,所以通常也被叫做目录项缓存。
换句话说,索引节点是每个文件的唯一标志,而目录项维护的正是文件系统的树状结构。目录项和索引节点的关系是多对一,你可以简单理解为,一个文件可以有多个别名。
其中组织形式如图:
2、虚拟文件系统
目录项、索引节点、逻辑块以及超级块,构成了Linux文件系统的四大基本要素。
第一,目录项本身就是一个内存缓存,而索引节点则是存储在磁盘中的数据。在前面的Buffer和Cache原理中,我曾经提到过,为了协调慢速磁盘与快速CPU的性能差异,文件内容会缓存到页缓存Cache中。
那么,你应该想到,这些索引节点自然也会缓存到内存中,加速文件的访问。
第二,磁盘在执行文件系统格式化时,会被分成三个存储区域,超级块、索引节点区和数据块区。其中,
超级块,存储整个文件系统的状态。
索引节点区,用来存储索引节点。
数据块区,则用来存储文件数据。
不过,为了支持各种不同的文件系统,Linux内核在用户进程和文件系统的中间,又引入了一个抽象层,也就是虚拟文件系统VFS(Virtual File System)。
VFS 定义了一组所有文件系统都支持的数据结构和标准接口。这样,用户进程和内核中的其他子系统,只需要跟VFS 提供的统一接口进行交互就可以了,而不需要再关心底层各种文件系统的实现细节。
这里,我画了一张Linux文件系统的架构图,帮你更好地理解系统调用、VFS、缓存、文件系统以及块存储之间的关系。
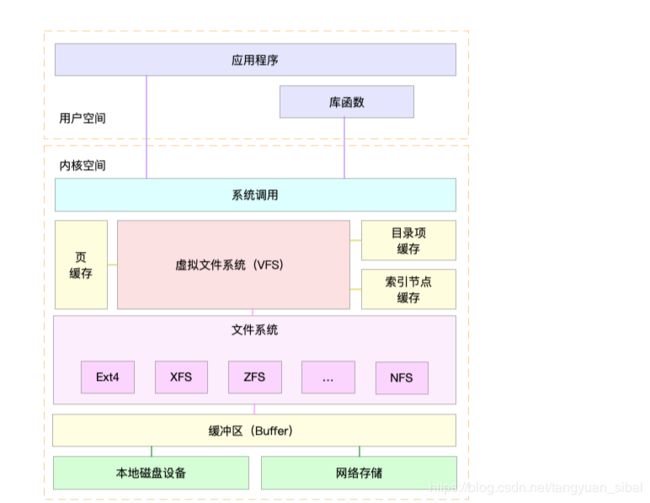
通过这张图,你可以看到,在VFS的下方,Linux支持各种各样的文件系统,如Ext4、XFS、NFS等等。按照存储位置的不同,这些文件系统可以分为三类。
第一类是基于磁盘的文件系统,也就是把数据直接存储在计算机本地挂载的磁盘中。常见的Ext4、XFS、OverlayFS等,都是这类文件系统。
第二类是基于内存的文件系统,也就是我们常说的虚拟文件系统。这类文件系统,不需要任何磁盘分配存储空间,但会占用内存。我们经常用到的 /proc 文件系统,其实就是一种最常见的虚拟文件系统。此外,/sys 文件系统也属于这一类,主要向用户空间导出层次化的内核对象。
第三类是网络文件系统,也就是用来访问其他计算机数据的文件系统,比如NFS、SMB、iSCSI等。
这些文件系统,要先挂载到 VFS 目录树中的某个子目录(称为挂载点),然后才能访问其中的文件。拿第一类,也就是基于磁盘的文件系统为例,在安装系统时,要先挂载一个根目录(/),在根目录下再把其他文件系统(比如其他的磁盘分区、/proc文件系统、/sys文件系统、NFS等)挂载进来。
3、
(1)查看文件系统的磁盘空间情况命令df

(2)sar(系统活动情况报告)
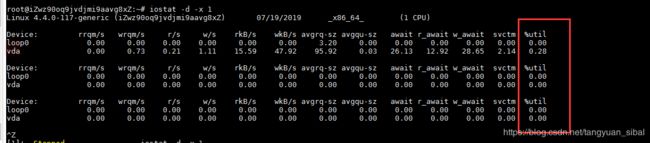
(3)iostat,(读写指标,使用情况分析)
4、网络
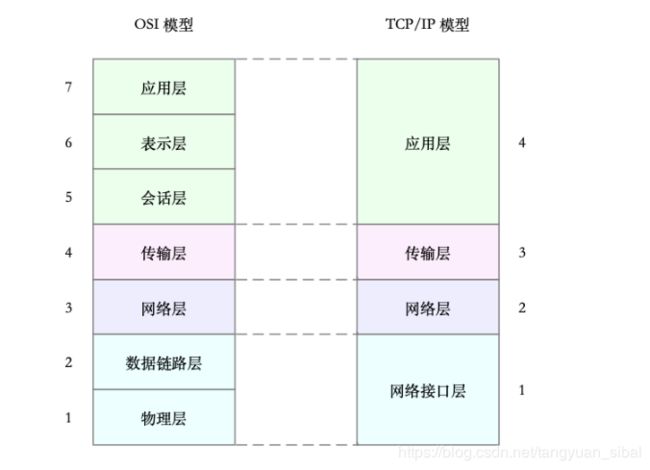
(1)OSI网络模型和TCP/IP模型
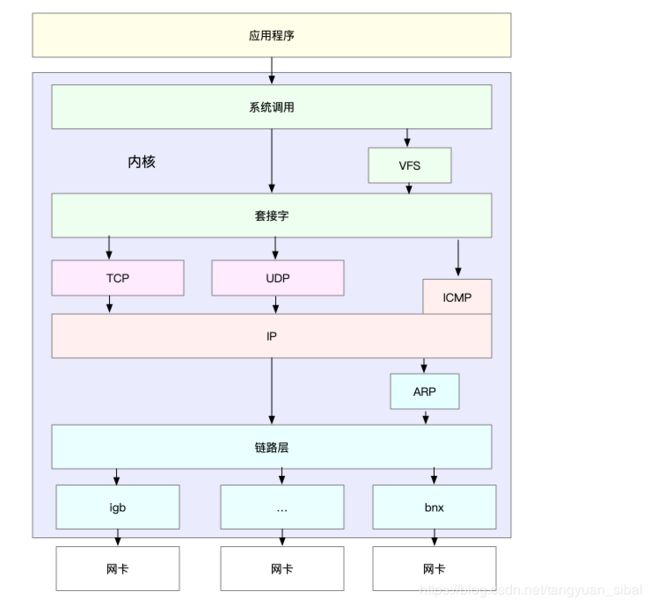
(2)IP网络栈示意图
(3)一个网络包的处理过程
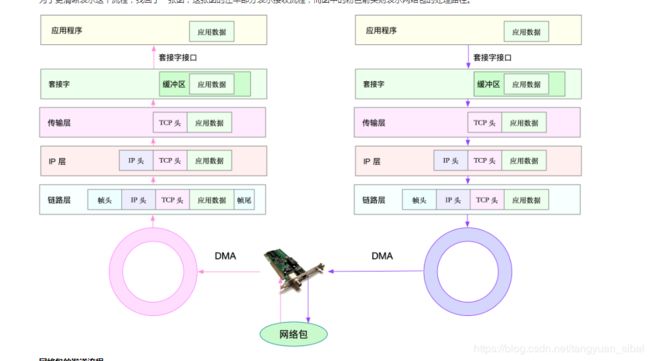
网路包的发送接收过程
首先,应用程序调用 Socket API(比如 sendmsg)发送网络包。
由于这是一个系统调用,所以会陷入到内核态的套接字层中。套接字层会把数据包放到 Socket 发送缓冲区中。
接下来,网络协议栈从 Socket 发送缓冲区中,取出数据包;再按照 TCP/IP 栈,从上到下逐层处理。比如,传输层和网络层,分别为其增加 TCP 头和 IP 头,执行路由查找确认下一跳的 IP,并按照 MTU 大小进行分片。
分片后的网络包,再送到网络接口层,进行物理地址寻址,以找到下一跳的 MAC 地址。然后添加帧头和帧尾,放到发包队列中。这一切完成后,会有软中断通知驱动程序:发包队列中有新的网络帧需要发送。
最后,驱动程序通过 DMA ,从发包队列中读出网络帧,并通过物理网卡把它发送出去。
(5)常用命令ip、ifconfig、netstat、ping

(6)网络I/O模型优化-------I/O多路复用
水平触发: 只要文件描述符可以非阻塞地执行 I/O ,就会触发通知。也就是说,应用程序可以随时检查文件描述符的状态,然后再根据状态,进行 I/O 操作。
边缘触发: 只有在文件描述符的状态发生改变(也就是 I/O 请求达到)时,才发送一次通知。这时候,应用程序需要尽可能多地执行 I/O,直到无法继续读写,才可以停止。如果 I/O 没执行完,或者因为某种原因没来得及处理,那么这次通知也就丢失了。
<1> 第一种,使用非阻塞 I/O 和水平触发通知,比如使用 select 或者 poll。
根据刚才水平触发的原理,select 和 poll 需要从文件描述符列表中,找出哪些可以执行 I/O ,然后进行真正的网络 I/O 读写。由于 I/O 是非阻塞的,一个线程中就可以同时监控一批套接字的文件描述符,这样就达到了单线程处理多请求的目的。
所以,这种方式的最大优点,是对应用程序比较友好,它的 API 非常简单。
但是,应用软件使用 select 和 poll 时,需要对这些文件描述符列表进行轮询,这样,请求数多的时候就会比较耗时。并且,select 和 poll 还有一些其他的限制。
select 使用固定长度的位相量,表示文件描述符的集合,因此会有最大描述符数量的限制。比如,在 32 位系统中,默认限制是 1024。并且,在select 内部,检查套接字状态是用轮询的方法,再加上应用软件使用时的轮询,就变成了一个 O(n^2) 的关系。
而 poll 改进了 select 的表示方法,换成了一个没有固定长度的数组,这样就没有了最大描述符数量的限制(当然还会受到系统文件描述符限制)。但应用程序在使用 poll 时,同样需要对文件描述符列表进行轮询,这样,处理耗时跟描述符数量就是 O(N) 的关系。
除此之外,应用程序每次调用 select 和 poll 时,还需要把文件描述符的集合,从用户空间传入内核空间,由内核修改后,再传出到用户空间中。这一来一回的内核空间与用户空间切换,也增加了处理成本。
有没有什么更好的方式来处理呢?答案自然是肯定的。
<2> 使用非阻塞 I/O 和边缘触发通知,比如 epoll。
既然 select 和 poll 有那么多的问题,就需要继续对其进行优化,而 epoll 就很好地解决了这些问题。
epoll 使用红黑树,在内核中管理文件描述符的集合,这样,就不需要应用程序在每次操作时都传入、传出这个集合。
epoll 使用事件驱动的机制,只关注有 I/O 事件发生的文件描述符,不需要轮询扫描整个集合。
不过要注意,epoll 是在 Linux 2.6 中才新增的功能(2.4 虽然也有,但功能不完善)。由于边缘触发只在文件描述符可读或可写事件发生时才通知,那么应用程序就需要尽可能多地执行 I/O,并要处理更多的异常事件。
<3> 使用异步 I/O(Asynchronous I/O,简称为 AIO)。
在前面文件系统原理的内容中,我曾介绍过异步I/O 与同步 I/O 的区别。异步I/O 允许应用程序同时发起很多 I/O 操作,而不用等待这些操作完成。而在 I/O完成后,系统会用事件通知(比如信号或者回调函数)的方式,告诉应用程序。这时,应用程序才会去查询 I/O 操作的结果。
参考文献:极客时间 Linux性能优化实战 倪朋飞