CPU Cache与缓存行
引言
先看下面这两个循环遍历哪个快?
int[][] array = new int[64 * 1024][1024];
// 横向遍历
for(int i = 0; i < 64 * 1024; i ++)
for(int j = 0; j < 1024; j ++)
array[i][j] ++;
// 纵向遍历
for(int i = 0; i < 1024; i ++)
for(int j = 0; j < 64 * 1024; j ++)
array[j][i] ++;在CPU处理器参数为 2.3 GHz Intel Core i5 的Mac上的结果是:
横向遍历: 80ms
纵向遍历: 2139ms
横向遍历的 CPU cache 命中率高,所以它比纵向遍历约快这么多倍!
Gallery of Processor Cache Effects 用 7 个源码示例生动的介绍 cache 原理,深入浅出!但是可能因操作系统的差异、编译器是否优化,以及近些年 cache 性能的提升,有些样例在 Mac 的效果与原文相差较大。
CPU Cache
CPU 访问内存时,首先查询 cache 是否已缓存该数据。如果有,则返回数据,无需访问内存;如果不存在,则需把数据从内存中载入 cache,最后返回给理器。在处理器看来,缓存是一个透明部件,旨在提高处理器访问内存的速率,所以从逻辑的角度而言,编程时无需关注它,但是从性能的角度而言,理解其原理和机制有助于写出性能更好的程序。Cache 之所以有效,是因为程序对内存的访问存在一种概率上的局部特征:
- Spatial Locality:对于刚被访问的数据,其相邻的数据在将来被访问的概率高。
- Temporal Locality:对于刚被访问的数据,其本身在将来被访问的概率高。
比 mac OS 为例,可用 命令 sysctl -a 查询 cache 信息,单位是字节Byte。
$ sysctl -a
hw.cachelinesize: 64
hw.l1icachesize: 32768
hw.l1dcachesize: 32768
hw.l2cachesize: 262144
hw.l3cachesize: 4194304
machdep.cpu.cache.L2_associativity: 4
machdep.cpu.core_count: 2
machdep.cpu.thread_count: 4
machdep.cpu.tlb.inst.large: 8
machdep.cpu.tlb.data.small: 64
machdep.cpu.tlb.data.small_level1: 64- CacheLine size:64 Byte
- L1 Data Cache:32KB
- L1 Instruction Cache:32KB
- L2 Cache:256KB
- L3 Cache:4MB
Mac下也可以点击坐上角关于本机 -> 概览 -> 系统报告来查看硬件信息:

下图是计算机存储的基本结构。L1、L2、L3分别表示一级缓存、二级缓存、三级缓存。越靠近CPU的缓存,速度越快,容量也越小。L1缓存小但很快,并且紧靠着在使用它的CPU内核。分为指令缓存和数据缓存;L2大一些,也慢一些,并仍然只能被一个单独的CPU核使用;L3更大、更慢,并且被单个插槽上的所有CPU核共享;最后是主存,由全部插槽上的所有CPU核共享。

当CPU执行运算的时候,它先去L1查找所需的数据、再去L2、然后是L3,如果最后这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以要尽量确保数据在L1缓存中。
Martin和Mike的 QCon presentation 演讲中给出了一些缓存未命中的消耗数据,也就是从CPU访问不同层级数据的时间概念:
| 从CPU到 | 大约需要的CPU时钟周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80ns | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
可见CPU读取主存中的数据会比从L1中读取慢了近2个数量级。
我们在每隔 64 Byte (cache line size) 访问 array 一次,访问固定次数。随着array的增大,看看能不能测试出 L1, L2 和 L3 cache size 的大小:
/**
* 每隔64Byte访问数组固定次数,看Array大小对耗时的影响
*/
public class Test {
public static void main(String[] args) {
for (int ARRAY_SIZE = 512; ARRAY_SIZE <= 128 * 1024 * 1024; ARRAY_SIZE <<= 1) {
int steps = 640 * 1024 * 1024; // Arbitrary number of steps
int length_mod = ARRAY_SIZE - 1;
char[] arr = new char[ARRAY_SIZE];
marked = System.currentTimeMillis();
for (int i = 0; i < steps; i += 64) {
arr[i & length_mod]++; // (i & length_mod) is equal to (i % length_mod)
}
long used = (System.currentTimeMillis() - marked);
System.out.println(formatSize(ARRAY_SIZE) + "\t" + used);
}
}
/**
* 把size单位转化为KB, MB, GB
*/
public static String formatSize(long size) {
String hrSize = null;
double b = size;
double k = size/1024.0;
double m = ((size/1024.0)/1024.0);
double g = (((size/1024.0)/1024.0)/1024.0);
double t = ((((size/1024.0)/1024.0)/1024.0)/1024.0);
DecimalFormat dec = new DecimalFormat("0");
if ( t>1 ) {
hrSize = dec.format(t).concat(" TB");
} else if ( g>1 ) {
hrSize = dec.format(g).concat(" GB");
} else if ( m>1 ) {
hrSize = dec.format(m).concat(" MB");
} else if ( k>1 ) {
hrSize = dec.format(k).concat(" KB");
} else {
hrSize = dec.format(b).concat(" Bytes");
}
return hrSize;
}
}运行的结果如下:
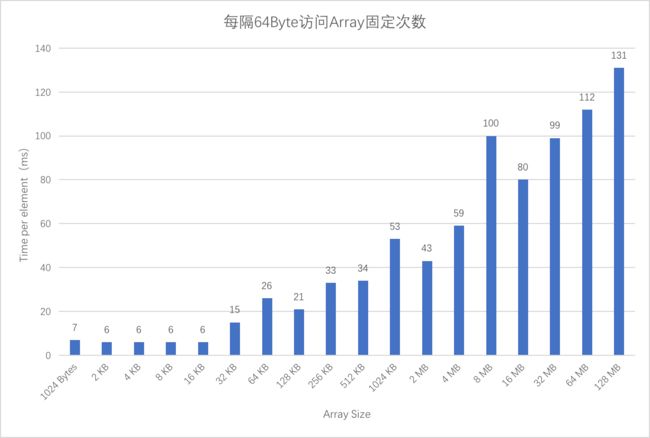
可以看到32KB,256KB,4MB之后耗时均有明显上升。
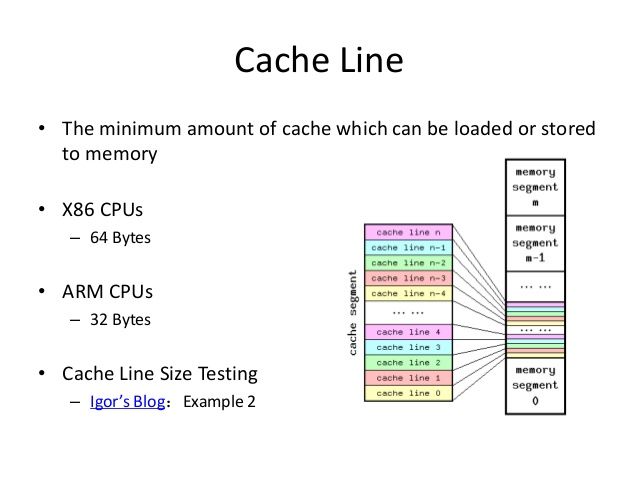
缓存行Cache Line
Cache是由很多个 Cache line 组成的。Cache line 是 cache 和 RAM 交换数据的最小单位,通常为 64 Byte。当 CPU 把内存的数据载入 cache 时,会把临近的共 64 Byte 的数据一同放入同一个Cache line,因为空间局部性:临近的数据在将来被访问的可能性大。
以大小为 32 KB,cache line 的大小为 64 Byte 的L1级缓存为例,对于不同存放规则,其硬件设计也不同,下图简单表示一种设计:

伪共享False Sharing
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。

下面我们通过一段代码,看看伪共享对性能的影响。
public final class FalseSharingNo implements Runnable {
public final static long ITERATIONS = 500L * 1000L * 100L;
private int arrayIndex = 0;
private static ValuePadding[] longs;
public FalseSharingNo(final int arrayIndex) {
this.arrayIndex = arrayIndex;
}
public static void main(final String[] args) throws Exception {
for(int i = 1; i < 10; i++){
System.gc();
final long start = System.currentTimeMillis();
runTest(i);
System.out.println(i + " Threads, duration = " + (System.currentTimeMillis() - start));
}
}
private static void runTest(int NUM_THREADS) throws InterruptedException {
Thread[] threads = new Thread[NUM_THREADS];
longs = new ValuePadding[NUM_THREADS];
for (int i = 0; i < longs.length; i++) {
longs[i] = new ValuePadding();
}
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new FalseSharingNo(i));
}
for (Thread t : threads) {
t.start();
}
for (Thread t : threads) {
t.join();
}
}
public void run() {
long i = ITERATIONS + 1;
while (0 != --i) {
longs[arrayIndex].value = 0L;
}
}
public final static class ValuePadding {
protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
protected long p9, p10, p11, p12, p13, p14;
protected long p15;
}
public final static class ValueNoPadding {
// protected long p1, p2, p3, p4, p5, p6, p7;
protected volatile long value = 0L;
// protected long p9, p10, p11, p12, p13, p14, p15;
}
}在分别使用 ValuePadding 和 ValueNoPadding 两种对象,让多线程分别访问数组中相邻的对象,试图构建一个伪共享的场景。在有Padding填充的情况下,看看运行结果:
1 Threads, duration = 398
2 Threads, duration = 645
3 Threads, duration = 537
4 Threads, duration = 638
5 Threads, duration = 786
6 Threads, duration = 954
7 Threads, duration = 1133
8 Threads, duration = 1286
9 Threads, duration = 1432
把代码中 ValuePadding 都替换为 ValueNoPadding 后的结果:
1 Threads, duration = 404
2 Threads, duration = 1250
3 Threads, duration = 1283
4 Threads, duration = 1179
5 Threads, duration = 2510
6 Threads, duration = 2733
7 Threads, duration = 2451
8 Threads, duration = 2652
9 Threads, duration = 2189
Cache Line伪共享解决方案
处理伪共享的两种方式:
- 字节填充:增大元素的间隔,使得不同线程存取的元素位于不同的cache line上,典型的空间换时间。
- 在每个线程中创建对应元素的本地拷贝,结束后再写回全局数组。
我们这里只看第一种字节填充。保证不同线程的变量存在于不同的 CacheLine 即可,这样就不会出现伪共享问题。在代码层面如何实现图中的字节填充呢?
Java6 中实现字节填充
public class PaddingObject{
public volatile long value = 0L; // 实际数据
public long p1, p2, p3, p4, p5, p6; // 填充
}PaddingObject 类中需要保存一个 long 类型的 value 值,如果多线程操作同一个 CacheLine 中的 PaddingObject 对象,便无法完全发挥出 CPU Cache 的优势(想象一下你定义了一个 PaddingObject[] 数组,数组元素在内存中连续,却由于伪共享导致无法使用 CPU Cache 带来的沮丧)。
不知道你注意到没有,实际数据 value + 用于填充的 p1~p6 总共只占据了 7 * 8 = 56 个字节,而 Cache Line 的大小应当是 64 字节,这是有意而为之,在 Java 中,对象头还占据了 8 个字节,所以一个 PaddingObject 对象可以恰好占据一个 Cache Line。
Java7 中实现字节填充
在 Java7 之后,一个 JVM 的优化给字节填充造成了一些影响,上面的代码片段 public long p1, p2, p3, p4, p5, p6; 会被认为是无效代码被优化掉,有回归到了伪共享的窘境之中。
为了避免 JVM 的自动优化,需要使用继承的方式来填充。
abstract class AbstractPaddingObject{
protected long p1, p2, p3, p4, p5, p6;// 填充
}
public class PaddingObject extends AbstractPaddingObject{
public volatile long value = 0L; // 实际数据
}Tips:实际上我在本地 mac 下测试过 jdk1.8 下的字节填充,并不会出现无效代码的优化,个人猜测和 jdk 版本有关,不过为了保险起见,还是使用相对稳妥的方式去填充较为合适。
Java8 中实现字节填充
//JDK 8中提供的注解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.FIELD, ElementType.TYPE})
public @interface Contended {
/**
* The (optional) contention group tag.
* This tag is only meaningful for field level annotations.
*
* @return contention group tag.
*/
String value() default "";
}在 JDK 8 里提供了一个新注解@Contended,可以用来减少false sharing的情况。JVM在计算对象布局的时候就会自动把标注的字段拿出来并且插入合适的大小padding。
因为这个功能暂时还是实验性功能,暂时还没到默认普及给用户代码用的程度。要在用户代码(非bootstrap class loader或extension class loader所加载的类)中使用@Contended注解的话,需要使用 -XX:-RestrictContended 参数。
比如在JDK 8的 ConcurrentHashMap 源码中,使用 @sun.misc.Contended对静态内部类 CounterCell 进行了修饰。
/* ---------------- Counter support -------------- */
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@sun.misc.Contended
static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}Thread
Thread 线程类的源码中,使用 @sun.misc.Contended 对成员变量进行修饰。
// The following three initially uninitialized fields are exclusively
// managed by class java.util.concurrent.ThreadLocalRandom. These
// fields are used to build the high-performance PRNGs in the
// concurrent code, and we can not risk accidental false sharing.
// Hence, the fields are isolated with @Contended.
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;RingBuffer
来源于一款优秀的开源框架 Disruptor 中的一个数据结构 RingBuffer。
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields extends RingBufferPad{} 使用字节填充和继承的方式来避免伪共享。
面试题扩展
问:说说数组和链表这两种数据结构有什么区别?
问:快速排序和堆排序两种排序算法各自的优缺点是什么?
了解了 CPU Cache 和 Cache Line 之后想想可不可以有一些特殊的回答技巧呢?
参考资料
- 7个示例科普CPU CACHE:Gallery of Processor Cache Effects
- 理解 CPU Cache
- 高性能队列——Disruptor — 美团点评技术团队
- JAVA 拾遗 — CPU Cache 与缓存行
- 写Java也得了解CPU–CPU缓存
- 关于CPU Cache – 程序猿需要知道的那些事
- Java专家系列:CPU Cache与高性能编程