dpdk无锁队列
这篇博客是从网上博客整理摘抄而来,具体参考的博客内容在文末给出。
Linux无锁队列
kfifo概述
Linux内核中有一个先进先出的数据结构,采用环形队列的数据结构来实现,提供一个无边界的字节流服务。最重要的是,这个队列采用的是无锁的方式来实现。即当它用于只有一个入队线程和一个出队线程的场景时,两个线程可以并发操作,而不需要任何加锁行为,就可以保证kfifo的线程安全。 这个队列名为kfifo。
kfifo结构体如下:
struct kfifo {
unsigned char *buffer; /* 存储数据的缓冲 */
unsigned int size; /* 缓冲长度 */
unsigned int in; /* in指向buffer中队头 */
unsigned int out; /* out指向buffer中的队尾 */
spinlock_t *lock;
};使用spin_lock_irqsave在于你不期望在离开临界区后,改变中断的开启,关闭状态。进入临界区是关闭的,离开后它同样应该是关闭的。
如果自旋锁在中断处理函数中被用到,那么在获取该锁之前需要关闭本地中断,spin_lock_irqsave 只是下列动作的一个便利接口:
1. 保存本地中断状态
2. 关闭本地中断
3. 获取自旋锁
解锁时通过 spin_unlock_irqrestore完成释放锁、恢复本地中断到之前的状态等工作
结构示意图如下:
+--------------------------------------------------------------+
| |<----------data---------->| |
+--------------------------------------------------------------+
^ ^ ^
| | |
out in sizekfifo主要提供的主要操作有:
//根据给定buffer创建一个kfifo
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size,
gfp_t gfp_mask, spinlock_t *lock);
//给定size分配buffer和kfifo
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask,
spinlock_t *lock);
//释放kfifo空间
void kfifo_free(struct kfifo *fifo)
//向kfifo中添加数据
unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//从kfifo中取数据
unsigned int kfifo_get(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
//获取kfifo中有数据的buffer大小
unsigned int kfifo_len(struct kfifo *fifo)kfifo功能描述
kfifo的结构体中包含了一个自旋锁(spinlock)指针,这个自旋锁的功能是防止多线程或者多进程并发使用kfifo,是因为这里的in在多个线程写的时候需要加锁,out在多个线程读的时候需要加锁。
kfifo_init创建kfifo
struct kfifo *kfifo_init(unsigned char *buffer, unsigned int size, //指定内存创建
gfp_t gfp_mask, spinlock_t *lock)
{
struct kfifo *fifo;
/* size must be a power of 2 */
BUG_ON(!is_power_of_2(size)); //向上扩展至2的次幂
fifo = kmalloc(sizeof(struct kfifo), gfp_mask); //以给定的缓冲区初始化kfifo结构(kmalloc保证申请的内存在物理上连续,申请大小一般不超过128kb)
if (!fifo)
return ERR_PTR(-ENOMEM);
fifo->buffer = buffer;
fifo->size = size;
fifo->in = fifo->out = 0;
fifo->lock = lock;
return fifo;
}kfifo_alloc创建kfifo
struct kfifo *kfifo_alloc(unsigned int size, gfp_t gfp_mask, spinlock_t *lock) //根据指定长度创建
{
unsigned char *buffer;
struct kfifo *ret;
//使用size & (size – 1)来判断size 是否为2幂,如果条件为真,则表示size不是2的幂,然后调用roundup_pow_of_two将之向上扩展为2的幂。
if (!is_power_of_2(size)) {
BUG_ON(size > 0x80000000);
size = roundup_pow_of_two(size); //向上扩展至2的次幂
}
buffer = kmalloc(size, gfp_mask); //创建buffer内存块
if (!buffer)
return ERR_PTR(-ENOMEM);
ret = kfifo_init(buffer, size, gfp_mask, lock); //调用kfifo_init
if (IS_ERR(ret))
kfree(buffer);
return ret;
}这两个初始化的函数都将kfifo的缓冲区长度向上扩展至2的次幂,原因是因为对kfifo->size取模运算可以转化为与运算,如:kfifo->in % kfifo->size 可以转化为 kfifo->in & (kfifo->size – 1)
kfifo_put和kfifo_get的入队和出队
kfifo的巧妙之处在于in和out定义为无符号类型,在put和get时,in和out都是增加,当达到最大值时,产生溢出,使得从0开始,进行循环使用。
入队操作:
//put操作往里面写数据
static inline unsigned int kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
//保存本地终端的当前状态,禁止本地中断并获取指定的锁
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_put(fifo, buffer, len);
//释放执行的锁,并让本地终端恢复到之前的状态
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
unsigned int __kfifo_put(struct kfifo *fifo,
const unsigned char *buffer, unsigned int len)
{
unsigned int l;
//buffer中还未存放数据的内存长度
len = min(len, fifo->size - fifo->in + fifo->out);
smp_mb();
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1))); //取模操作(in到缓冲区尾部长度)
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l); //拷贝进去的数据
/* 拷贝生下来的数据到缓冲区头到out之间的区域 */
memcpy(fifo->buffer, buffer + l, len - l);
/*
* Ensure that we add the bytes to the kfifo -before-
* we update the fifo->in index.
*/
smp_wmb();
fifo->in += len; //每次累加,到达最大值后溢出,自动转为0
return len;
}出队操作:
//get操作往外面读数据
static inline unsigned int kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned long flags;
unsigned int ret;
//保存本地终端的当前状态,禁止本地中断并获取指定的锁
spin_lock_irqsave(fifo->lock, flags);
ret = __kfifo_get(fifo, buffer, len);
//当fifo->in == fifo->out时,buffer为空
if (fifo->in == fifo->out)
fifo->in = fifo->out = 0;
//释放执行的锁,并让本地终端恢复到之前的状态
spin_unlock_irqrestore(fifo->lock, flags);
return ret;
}
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
//有数据的缓冲区的长度
len = min(len, fifo->in - fifo->out);
/*
* Ensure that we sample the fifo->in index -before- we
* start removing bytes from the kfifo.
*/
smp_rmb();
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
/*
* Ensure that we remove the bytes from the kfifo -before-
* we update the fifo->out index.
*/
smp_mb();
fifo->out += len; //每次累加,到达最大值后溢出,自动转为0
return len;
}在kfifo的入队和出队操作中,使用了三个函数smp_mb()、smp_rmb()、smp_wmb()。这三个函数主要是实现内存屏障,功能分别是:
| 函数名称 | 功能 |
|---|---|
| smp_mb() | 适用于多处理器的内存屏障 |
| smp_rmb() | 适用于多处理器的读内存屏障 |
| smp_wmb() | 适用于多处理器的写内存屏障 |
在多线程处理的时候,CPU进行优化后的代码可能不是原来的执行顺序,我们需要一些手段来干预编译器和CPU, 使其限制指令顺序。内存屏障就是这样的干预手段. 他们能保证处于内存屏障两边的内存操作满足部分有序。( 这里”部分有序”的意思是, 内存屏障之前的操作都会先于屏障之后的操作, 但是如果几个操作出现在屏障的同一边, 则不保证它们的顺序.)
- 写(STORE)内存屏障:在写屏障之前的STORE操作将先于所有在写屏障之后的STORE操作。
- 数据依赖屏障:两条Load指令,第二条Load指令依赖于第一条Load指令的结果,则数据依赖屏障保障第二条指令的目标地址将被更新。
- 读(LOAD)内存屏障:读屏障包含数据依赖屏障的功能, 并且保证所有出现在屏障之前的LOAD操作都将先于所有出现在屏障之后的LOAD操作被系统中的其他组件所感知。
- 通用内存屏障.:通用内存屏障保证所有出现在屏障之前的LOAD和STORE操作都将先于所有出现在屏障之后的LOAD和STORE操作被系统中的其他组件所感知。
- LOCK操作:它的作用相当于一个单向渗透屏障.它保证所有出现在LOCK之后的内存操作都将在LOCK操作被系统中的其他组件所感知之后才能发生. 出现在LOCK之前的内存操作可能在LOCK完成之后才发生。LOCK操作总是跟UNLOCK操作配对出现。
- UNLOCK操作。它保证所有出现在UNLOCK之前的内存操作都将在UNLOCK操作被系统中的其他组件所感知之前发生。
而上述代码调用了内存屏障函数之后,可以保证对kfifo的数据读写是按顺序进行的,这样对于单生产者,单消费者使用队列时,将不需要使用加锁操作。
这就是linux内部的无锁队列kfifo,概念非常简洁明了,仅仅是一块buff,两个指针的计算。读指针指向环形缓冲区中可读的数据,写指针指向环形缓冲区中可写的数据,通过移动读写指针就可以实现缓冲区的数据读取和写入。对于多线程进行调用的时候,如果是多生产者,则需要对生产者进行加锁限制,如果是多消费者,则需要对消费者进行加锁限制。
DPDK无锁队列
定义
DPDK无锁队列的定义
struct rte_ring {
TAILQ_ENTRY(rte_ring) next; /**< Next in list. */
//ring的唯一标示,不可能同时有两个相同name的ring存在
char name[RTE_RING_NAMESIZE]; /**< Name of the ring. */
int flags; /**< Flags supplied at creation. */
/** Ring producer status. */
struct prod {
uint32_t watermark; /**< Maximum items before EDQUOT. */
uint32_t sp_enqueue; /**< True, if single producer. */
uint32_t size; /**< Size of ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Producer head. */
volatile uint32_t tail; /**< Producer tail. */
} prod __rte_cache_aligned;
/** Ring consumer status. */
struct cons {
uint32_t sc_dequeue; /**< True, if single consumer. */
uint32_t size; /**< Size of the ring. */
uint32_t mask; /**< Mask (size-1) of ring. */
volatile uint32_t head; /**< Consumer head. */
volatile uint32_t tail; /**< Consumer tail. */
#ifdef RTE_RING_SPLIT_PROD_CONS
/*这个属性就是要求gcc在编译的时候,把cons/prod结构都单独分配到一个cache行,为什么这样做?
因为如果没有这些的话,这两个结构在内存上是连续的,编译器不会把他们分配到不同cache 行,而
一般上这两个结构是要被不同的核访问的,如果连续的话这两个核就会产生伪共享问题。*/
} cons __rte_cache_aligned;
#else
} cons;
#endif
#ifdef RTE_LIBRTE_RING_DEBUG
struct rte_ring_debug_stats stats[RTE_MAX_LCORE];
#endif
void * ring[0] __rte_cache_aligned; /**< Memory space of ring starts here.
* not volatile so need to be careful
* about compiler re-ordering */
};DPDK的环形缓冲区是由两个组组成,一组被生产者使用,一组被消费者使用。
创建队列:
struct rte_ring *rte_ring_create(const char *name, unsigned count,
int socket_id, unsigned flags);name:ring的name
count:ring队列的长度必须是2的幂次方。原因同kfifo。
socket_id:ring位于的socket。
flags:指定创建的ring的属性:单/多生产者、单/多消费者两者之间的组合。
0表示使用默认属性(多生产者、多消费者)。不同的属性出入队的操作会有所不同。
出入队的API为:
static __rte_always_inline int
rte_ring_enqueue(struct rte_ring *r, void *obj);
static __rte_always_inline int
rte_ring_dequeue(struct rte_ring *r, void **obj_p);创建的具体过程如下:
在rte_ring_list链表中创建一个rte_tailq_entry节点。在memzone中根据队列的大小count申请一块内存(rte_ring的大小加上count*sizeof(void ))。紧邻着rte_ring结构的void 数组用于放置入队的对象(单纯的赋值指针值)。rte_ring结构中有生产者结构prod、消费者结构cons。初始化参数之后,把rte_tailq_entry的data节点指向rte_ring结构地址。
可以注意到cons.head、cons.tail、prod.head、prod.tail的类型都是uint32_t(32位无符号整形)。除此之外,队列的大小count被限制为2的幂次方。这两个条件放到一起构成了一个很巧妙的情景。因为队列的大小一般不会是最大的2的32次方那么大,所以,把队列取为32位的一个窗口,当窗口的大小是2的幂次方,则32位包含整数个窗口。这样,用来存放ring对象的void *指针数组空间就可只申请一个窗口大小即可。无符号数计算距离的技巧。根据二进制的回环性,可以直接用(uint32_t)( prod_tail - cons_tail)计算队列中有多少生产的产品(即使溢出了也不会出错,如(uint32_t)5-65535 = 6)。
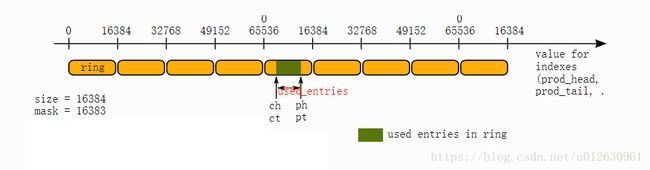
消费者生产者的入队出队
DPDK这里的入队和出队同kfifo一样,单生产者,单消费者都是不用加锁的,对于多生产者来说,只需要写入的时候加锁,对于多消费者来说,只需要读取的时候加锁。
有个地方可能让人纳闷,为什么prod和cons都定义了head和tail。其实这就是为了实现同时出入队。
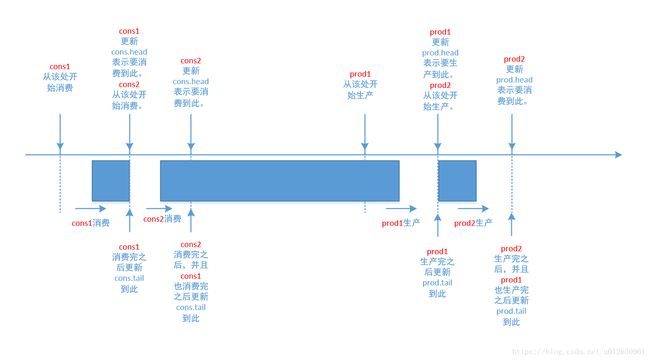
- 移动prod.head表示生产者预定的生产数量
- 当该生产者生产结束,且在此之前的生产也都结束后,移动prod.tail表示实际生产的位置
- 同样,移动cons.head表示消费者预定的消费数量
- 当该消费者消费结束,且在此之前的消费也都结束后,移动cons.tail表示实际消费的位置
入队的流程是:
static inline int __attribute__((always_inline))
__rte_ring_mp_do_enqueue(struct rte_ring *r, void * const *obj_table,
unsigned n, enum rte_ring_queue_behavior behavior)
{
uint32_t prod_head, prod_next;
uint32_t cons_tail, free_entries;
const unsigned max = n;
int success;
unsigned i;
uint32_t mask = r->prod.mask;
int ret;
/* move prod.head atomically */
do {
/* Reset n to the initial burst count */
n = max;
prod_head = r->prod.head;
cons_tail = r->cons.tail;
/*在这里dpdk提供的索引计算方法,能保证即使prod_head > cons_tail,
*取模求得的值也始终落在0~size(ring)-1范围内
*/
free_entries = (mask + cons_tail - prod_head);
/* check that we have enough room in ring */
if (unlikely(n > free_entries)) {
if (behavior == RTE_RING_QUEUE_FIXED) {
__RING_STAT_ADD(r, enq_fail, n);
return -ENOBUFS;
}
else {
/* No free entry available */
if (unlikely(free_entries == 0)) {
__RING_STAT_ADD(r, enq_fail, n);
return 0;
}
n = free_entries;
}
}
prod_next = prod_head + n;
/*这里使用CAS指令来移动r->prod.head,去掉了锁操作,也算优化
*点
*/
success = rte_atomic32_cmpset(&r->prod.head, prod_head,
prod_next);
} while (unlikely(success == 0));
/* write entries in ring */
ENQUEUE_PTRS();
/*COMPILER_BARRIER 是一个宏定义,它的作用就是确保上面的ENQUEUE_PTRS
*宏处理在下面r->prod.tail = prod_next;之前执行?大家可能会问,
*ENQUEUE_PTRS怎么可能会跑到r->prod.tail = prod_next之后执行?
*其实是有可能的,GCC为了提高性能,它会优化代码,它可能会调整代码的
*执行顺序,把后面的指令放到前面,GCC这些编译器是依据单核情况实现,
*所以这种情况下,程序员必须介入,上面这条指令,就是告诉编译器不允许
*调整这个指令顺序。
*/
rte_compiler_barrier();
/* if we exceed the watermark */
if (unlikely(((mask + 1) - free_entries + n) > r->prod.watermark)) {
ret = (behavior == RTE_RING_QUEUE_FIXED) ? -EDQUOT :
(int)(n | RTE_RING_QUOT_EXCEED);
__RING_STAT_ADD(r, enq_quota, n);
}
else {
ret = (behavior == RTE_RING_QUEUE_FIXED) ? 0 : n;
__RING_STAT_ADD(r, enq_success, n);
}
/*
* If there are other enqueues in progress that preceeded us,
* we need to wait for them to complete
*/
while (unlikely(r->prod.tail != prod_head))
rte_pause();
r->prod.tail = prod_next;
return ret;
}其中ENQUEUE_PTRS的实现:
#define ENQUEUE_PTRS() do { \
const uint32_t size = r->prod.size; \
//这里idx每次循环加4,也是针对CPU的特殊优化
//至于为什么是4个交替写,这块我还没怎么理解
uint32_t idx = prod_head & mask; \
if (likely(idx + n < size)) { \
for (i = 0; i < (n & ((~(unsigned)0x3))); i+=4, idx+=4) { \
r->ring[idx] = obj_table[i]; \
r->ring[idx+1] = obj_table[i+1]; \
r->ring[idx+2] = obj_table[i+2]; \
r->ring[idx+3] = obj_table[i+3]; \
} \
switch (n & 0x3) { \
case 3: r->ring[idx++] = obj_table[i++]; \
case 2: r->ring[idx++] = obj_table[i++]; \
case 1: r->ring[idx++] = obj_table[i++]; \
} \
} else { \
for (i = 0; idx < size; i++, idx++)\
r->ring[idx] = obj_table[i]; \
for (idx = 0; i < n; i++, idx++) \
r->ring[idx] = obj_table[i]; \
} \
} while(0)1 检查free空间是否足够
把free_entries = (mask + cons_tail - prod_head);写成free_entries = (mask + 1 + cons_tail - prod_head -1);就容易理解了。
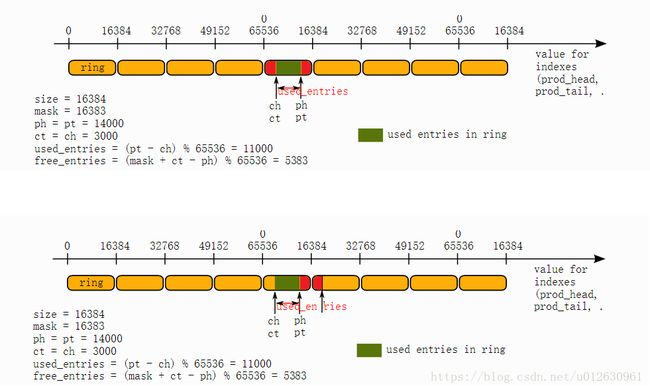
mask + 1 + cons_tail是把cons_tail移到下一个窗口对应的位置上。那么从上面2个图中,下面图中的红色面积等于上图中红色面积(按数学的几何学是这样的,但这里会有1的差错,下面介绍)。
2 生产预约
利用cas操作,移动r->prod.head,预约生产。
cas:这是一种可以称为基于冲突检测的乐观锁。cas操作是原子性的,由CPU硬件指令实现保证 。这种模式下,已经没有所谓的锁概念了,每条线程都直接先去执行操作,计算完成后检测是否与其他线程存在共享数据竞争,如果没有则让此操作成功,如果存在共享数据竞争则可能不断地重新执行操作和检测,直到成功为止,可叫CAS自旋。
乐观锁的核心算法是CAS(Compareand Swap,比较并交换),它涉及到三个操作数:内存值、预期值、新值。当且仅当预期值和内存值相等时才将内存值修改为新值。这样处理的逻辑是,首先检查某块内存的值是否跟之前我读取时的一样,如不一样则表示期间此内存值已经被别的线程更改过,舍弃本次操作,否则说明期间没有其他线程对此内存值操作,可以把新值设置给此块内存。有两个线程可能会差不多同时对某内存操作,线程二先读取某内存值作为预期值,执行到某处时线程二决定将新值设置到内存块中,如果线程一在此期间修改了内存块,则通过CAS即可以检测出来,假如检测没问题则线程二将新值赋予内存块。
所以多生产者的流程是:
- 在所有核上,将ring->prod_head和ring->cons_tail拷贝到本地变量中。prod_next本地变量指向prod_head的下一个元素,或者多个元素(bulk enqueue情况下);如果ring中空间不够,直接报错退出
- 在每个核上,修改ring->prod_head指向本地变量prod_next。这个动作的完成需要使用CAS指令,该指令自动完成下述动作:
- 如果ring->prod_head和本地变量的prod_head不相等,CAS操作失败,重新执行
- 如果ring->prod_head和本地变量的prod_head相等,CAS操作成功,继续
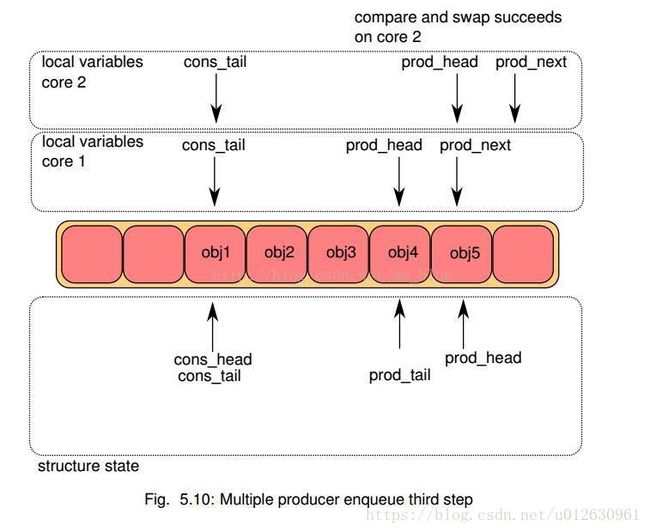
- 这样如果两个核同时更新该索引,一次就能保证只有一个能成功,另一个失败后会自动尝试继续比较,再第一次添加的基础上继续更新添加。当CAS都更新成功后,core 1添加obj4, core 2添加obj5
- 当CAS都更新成功后,core 1添加obj4, core 2添加obj5
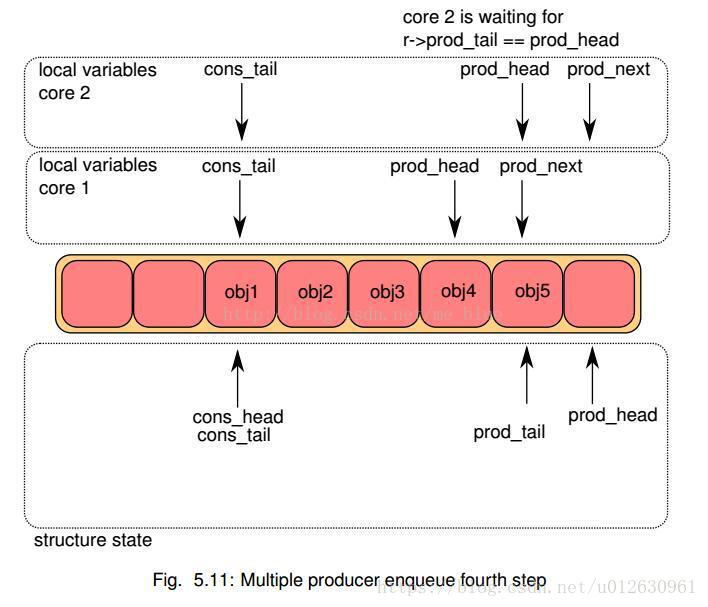
- 每个核都尝试更新ring->prod_tail. 比较ring->prod_tail是否等于本地prod_head,只有true的core能够执行,第一次是core 1成功
- 当core 1更新成功后,core 2继续判断,此时应该也可以更新了,完成更新。

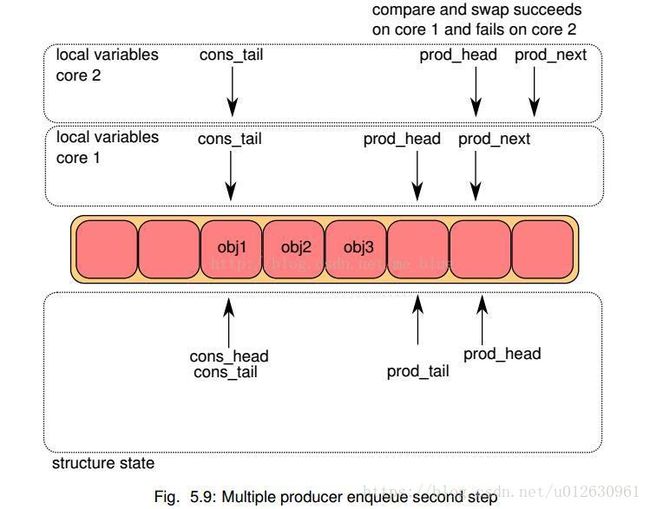
3 检查是否到了阈值,并添加到统计中
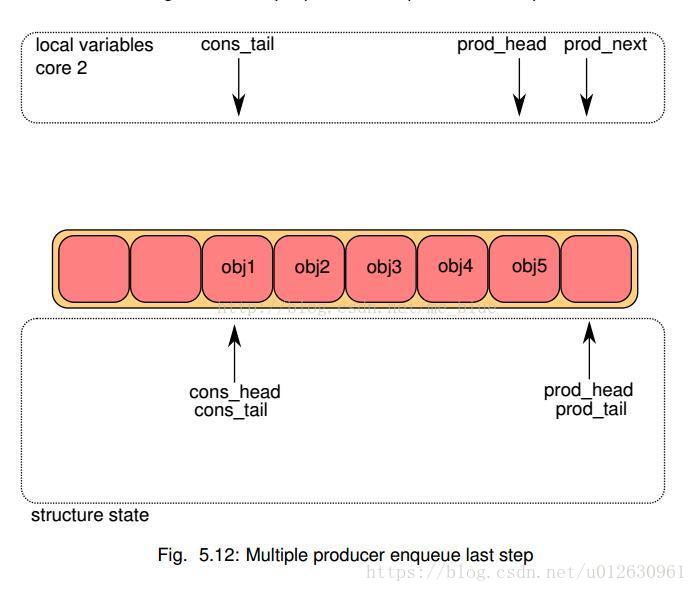
4 等待之前的入队操作完成,移动实际位置
检查在此生产者之前的生产者都生产完成后,移动r->prod.tail,移动实际生产了的位置。
2 出队流程
“`c++
static inline int attribute((always_inline))
__rte_ring_mc_do_dequeue(struct rte_ring *r, void **obj_table,
unsigned n, enum rte_ring_queue_behavior behavior)
{
uint32_t cons_head, prod_tail;
uint32_t cons_next, entries;
const unsigned max = n;
int success;
unsigned i, rep = 0;
uint32_t mask = r->prod.mask;
/* Avoid the unnecessary cmpset operation below, which is also
* potentially harmful when n equals 0. */
if (n == 0)
return 0;
/* move cons.head atomically
cgm
1.检查可消费空间是否足够
2.cms消费预约*/
do {
/* Restore n as it may change every loop */
n = max;
cons_head = r->cons.head;
prod_tail = r->prod.tail;
/* The subtraction is done between two unsigned 32bits value
* (the result is always modulo 32 bits even if we have
* cons_head > prod_tail). So 'entries' is always between 0
* and size(ring)-1. */
entries = (prod_tail - cons_head);
/* Set the actual entries for dequeue */
if (n > entries) {
if (behavior == RTE_RING_QUEUE_FIXED) {
__RING_STAT_ADD(r, deq_fail, n);
return -ENOENT;
}
else {
if (unlikely(entries == 0)){
__RING_STAT_ADD(r, deq_fail, n);
return 0;
}
n = entries;
}
}
cons_next = cons_head + n;
success = rte_atomic32_cmpset(&r->cons.head, cons_head,
cons_next);
} while (unlikely(success == 0));
/* copy in table */
DEQUEUE_PTRS();
rte_smp_rmb();
/*
* If there are other dequeues in progress that preceded us,
* we need to wait for them to complete
cgm 等待之前的出队操作完成
*/
while (unlikely(r->cons.tail != cons_head)) {
rte_pause();
/* Set RTE_RING_PAUSE_REP_COUNT to avoid spin too long waiting
* for other thread finish. It gives pre-empted thread a chance
* to proceed and finish with ring dequeue operation. */
if (RTE_RING_PAUSE_REP_COUNT &&
++rep == RTE_RING_PAUSE_REP_COUNT) {
rep = 0;
sched_yield();
}
}
__RING_STAT_ADD(r, deq_success, n);
r->cons.tail = cons_next;
return behavior == RTE_RING_QUEUE_FIXED ? 0 : n;
}
参考内容
[1]巧夺天工的kfifo(修订版)
[2]linux内核数据结构之kfifo
[3]内存屏障(Memory Barriers)
[4]深入理解dpdk rte_ring无锁队列
[5]dpdk介绍系列之ring