Java 序列化和反序列化(二)Serializable 源码分析 - 1
https://www.cnblogs.com/binarylei/p/10987933.html
目录
- Java 序列化和反序列化(二)Serializable 源码分析 - 1
- 1. Java 序列化接口
- 2. ObjectOutputStream 源码分析
- 2.1 ObjectOutputStream 数据结构
- 2.2 ObjectOutputStream 构造函数
- 2.3 序列化入口:writeObject
- 2.4 核心方法:writeObject0
- 2.5 序列化:writeOrdinaryObject
- 2.6 类信息序列化:writeClassDesc
- 2.7 类数据信息序列化:writeSerialData
- 3. ObjectOutputStream#BlockDataOutputStream
- 4. ObjectOutputStream#HandleTable
- 5. ObjectOutputStream#PutField
Java 序列化和反序列化(二)Serializable 源码分析 - 1
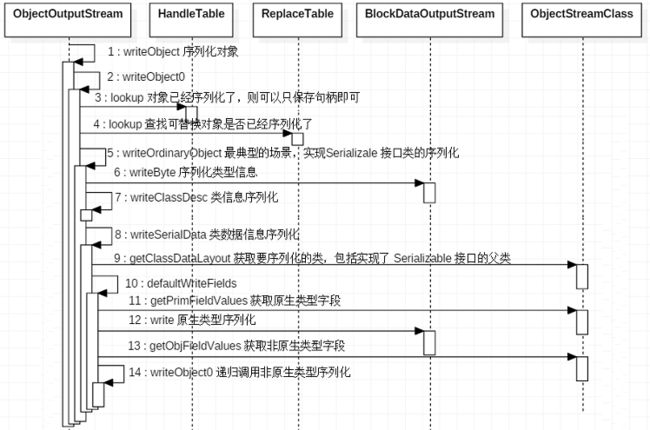
在上一篇文章中讲解了一下 Serializable 的大致用法,本节重点关注 Java 序列化的实现,围绕 ObjectOutputStream#writeObject 方法展开。
1. Java 序列化接口
Java 为了方便开发人员将 Java 对象进行序列化及反序列化提供了一套方便的 API 来支持。其中包括以下接口和类:

-
Serializable 和 Externalizable序列化接口。Serializable 接口没有方法或字段,仅用于标识可序列化的语义,实际上 ObjectOutputStream#writeObject 时通过反射调用 writeObject 方法,如果没有自定义则调用默认的序列化方法。Externalizable 接口该接口中定义了两个扩展的抽象方法:writeExternal 与 readExternal。 -
DataOutput 和 ObjectOutputDataOutput 提供了对 Java 基本类型 byte、short、int、long、float、double、char、boolean 八种基本类型,以及 String 的操作。ObjectOutput 则在 DataOutput 的基础上提供了对 Object 类型的操作,writeObject 最终还是调用 DataOutput 对基本类型的操作方法。 -
ObjectOutputStream我们一般使用 ObjectOutputStream#writeObject 方法把一个对象进行持久化。ObjectInputStream#readObject 则从持久化存储中把对象读取出来。 -
ObjectStreamClass 和 ObjectStreamFieldObjectStreamClass 是类的序列化描述符,包含类描述信息,字段的描述信息和 serialVersionUID。可以使用 lookup 方法找到/创建在此 Java VM 中加载的具体类的 ObjectStreamClass。而 ObjectStreamField 则保存字段的序列化描述符,包括字段名、字段值等。
2. ObjectOutputStream 源码分析
2.1 ObjectOutputStream 数据结构
private final BlockDataOutputStream bout; // io流
private final HandleTable handles; // 序列化对象句柄(编号)映射关系
private final ReplaceTable subs; // 替换对象的映射关系
private final boolean enableOverride; // true 则调用writeObjectOverride()来替代writeObject()
private boolean enableReplace; // true 则调用replaceObject()bout 是下层输出流,两个表是用于记录已输出对象的缓存便于之前说的重复输出的时候输出上一个相同内容的位置。
ObjectOutputStream 属性中不太好理解的是 handles 和 subs 这两个属性。HandleTable 从名称就知道这是一个轻量的 HashMap,保存序列化对象句柄(编号)映射关系,ReplaceTable 保存的是替换对象的映射关系。关于 handles 的作用,举个例子,我们知道 Java 序列化除了保存字段信息外,还保存有类信息,当同一个对象序列化两次时第二次只用保存第一次的编号,这样可以大大减少序列化的大小,具体例子参考序列化存储规则。
剩余的变量用到了再作说明。
2.2 ObjectOutputStream 构造函数
public ObjectOutputStream(OutputStream out) throws IOException {
bout = new BlockDataOutputStream(out);
handles = new HandleTable(10, (float) 3.00);
subs = new ReplaceTable(10, (float) 3.00);
enableOverride = false;
writeStreamHeader();
bout.setBlockDataMode(true);
}ObjectOutputStream 构建时会创建 BlockDataOutputStream 序列化流 bout,handles 和 subs 大致作用上面提了一下,下面还会有说明。writeStreamHeader 方法是输出序列化流的头信息,用于文件校验,和 .class 文件头的魔数及版本作用一样。如果不需要的话,可以覆盖这个方法,什么也不做,Hadoop 默认的 Java 序列化就是这样做的。
protected void writeStreamHeader() throws IOException {
bout.writeShort(STREAM_MAGIC);
bout.writeShort(STREAM_VERSION);
}2.3 序列化入口:writeObject
public final void writeObject(Object obj) throws IOException {
if (enableOverride) { // 默认为 flase,由子类复写
writeObjectOverride(obj); // 子类实现
return;
}
try {
writeObject0(obj, false); // 最核心的方法
} catch (IOException ex) {
if (depth == 0) {
writeFatalException(ex);
}
throw ex;
}
}总结: writeObject 将所有序列委托给了 writeObject0 完成,如果序列化出现异常调用 writeFatalException 方法。
depth 变量表示 writeObject0 调用的深度,比如序列化 A 对象时调用 writeObject 则 depth++,而 A 对象的字段又是一个对象,此时又会递归调用 writeObject 方法,当 writeObject 方法执行完成时 depth--。因而如果不出异常则 depth 最终会是 0,有异常则在 catch 模块时 depth 不为 0。
private void writeFatalException(IOException ex) throws IOException {
clear();
boolean oldMode = bout.setBlockDataMode(false);
try {
bout.writeByte(TC_EXCEPTION); // 异常信息
writeObject0(ex, false);
clear();
} finally {
bout.setBlockDataMode(oldMode);
}
}2.4 核心方法:writeObject0
writeObject0 比较复杂,大致可分为三个部分:一是判断需不需要序列化;二是判断是否替换了对象;三是终于可以序列化了。
private void writeObject0(Object obj, boolean unshared) throws IOException {
boolean oldMode = bout.setBlockDataMode(false);
depth++;
try {
// 1. 判断需不需要序列化
// 2. 判断是否替换了对象
// 3. 真正可以序列化了
} finally {
depth--;
bout.setBlockDataMode(oldMode);
}
}下面我们就看一下这三步都做了些什么?
int h;
// 1. 替换后的对象为 null
if ((obj = subs.lookup(obj)) == null) {
writeNull();
return;
// 2. handles存储的是已经序列化的对象句柄,如果找到了,直接写一个句柄就可以了
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
// 3. Class 对象
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
// 4. ObjectStreamClass 序列化类的描述信息
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}总结1: Java 序列化保存了很多与数据无关的数据,如类信息。但 Java 本身也做了一些优化,如 handles 保存了类的句柄,这样重复的类就只用保存一个句柄就可以了。
Object orig = obj;
Class cl = obj.getClass();
ObjectStreamClass desc;
// 1. 如果要序列化的对象中有 writeReplace 方法,则递归检查最终要输出的对象
for (;;) {
Class repCl;
desc = ObjectStreamClass.lookup(cl, true);
// 如果要序列化的对象中有 writeReplace 方法,则递归检查最终要输出的对象
if (!desc.hasWriteReplaceMethod() ||
(obj = desc.invokeWriteReplace(obj)) == null ||
(repCl = obj.getClass()) == cl) {
break;
}
cl = repCl;
}
// 2. 子类重写 ObjectOutputStream#replaceObject 方法
if (enableReplace) {
Object rep = replaceObject(obj);
if (rep != obj && rep != null) {
cl = rep.getClass();
desc = ObjectStreamClass.lookup(cl, true);
}
obj = rep;
}
// 3. 既然要序列化的对象已经被替换了,此时就需要再次做判断,和步骤1类似
if (obj != orig) {
subs.assign(orig, obj);
if (obj == null) {
writeNull();
return;
} else if (!unshared && (h = handles.lookup(obj)) != -1) {
writeHandle(h);
return;
} else if (obj instanceof Class) {
writeClass((Class) obj, unshared);
return;
} else if (obj instanceof ObjectStreamClass) {
writeClassDesc((ObjectStreamClass) obj, unshared);
return;
}
}总结2: 其实就是做了一个拦截,有机会替换要序列化的对象。做了这么多,现在终于可以序列化对象了。
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
throw new NotSerializableException(cl.getName());
}总结3: 对于 String、Array、Enum 三类对象,序列时做了特殊的处理,实现了 Serializable 接口的普通对象则调用 writeOrdinaryObject 进行序列化,在这个方法中我们可以真正看到数据的序列化。不过在这个方法中我们可以看到如果没有实现 Serializable 接口会抛出 NotSerializableException 异常。
补充:writeObject 和 writeUnshared 区别(了解):
在这之前,我们先了解一下 unshared 这个参数的作用,writeObject 和 writeUnshared 的区别是:后者会重新申请内存空间,让其地址发生改变。看下面这个例子:
oos.writeObject(user1);
int length1 = baos.toByteArray().length;
oos.writeObject(user1);
int length2 = baos.toByteArray().length;
// 1. 同一个对象写两次,长度只增加了 5
Assert.assertEquals(5, length2 - length1);
oos.writeUnshared(user1);
int length3 = baos.toByteArray().length;
// 2. length1=123; length2=128; length3=140。
// 第三个对象数据重新保存了一次,所以长度增加大于 5,也就是内存地址是非共享的
System.out.println(String.format("length1=%s; length2=%s; length3=%s", length1, length2, length3));2.5 序列化:writeOrdinaryObject
// String 类型
private void writeString(String str, boolean unshared) throws IOException {
handles.assign(unshared ? null : str);
long utflen = bout.getUTFLength(str);
if (utflen <= 0xFFFF) { // 长度小于 0xFFFF(65506)
bout.writeByte(TC_STRING); // 类型
bout.writeUTF(str, utflen); // 内容
} else { // 长度大于 0xFFFF(65506)
bout.writeByte(TC_LONGSTRING);
bout.writeLongUTF(str, utflen);
}
}
// Enum 类型
private void writeEnum(Enum en, ObjectStreamClass desc,
boolean unshared) throws IOException {
bout.writeByte(TC_ENUM); // 1. 类型
ObjectStreamClass sdesc = desc.getSuperDesc(); // 2. 类信息
writeClassDesc((sdesc.forClass() == Enum.class) ? desc : sdesc, false);
handles.assign(unshared ? null : en);
writeString(en.name(), false); // 3. 枚举类的名称
}
// 实现了 Serializable 接口的序列化
private void writeOrdinaryObject(Object obj, ObjectStreamClass desc,
boolean unshared) throws IOException {
desc.checkSerialize();
bout.writeByte(TC_OBJECT); // 1. 类型
writeClassDesc(desc, false); // 2. 类信息
handles.assign(unshared ? null : obj);
if (desc.isExternalizable() && !desc.isProxy()) {
writeExternalData((Externalizable) obj); // 3.1 实现 Externalizable 接口的类
} else {
writeSerialData(obj, desc); // 3.2 实现 Serializable 接口的类,数据序列化
}
}总结: 可以看到 Java 序列化保存了三部分的数据:一是类型信息序列化 bout.writeByte(TC_OBJECT);二是类信息序列化 writeClassDesc();三是类数据信息序列化 writeSerialData()。到这里终于可以看到 io 序列化流的操作了。
writeOrdinaryObject 这个方法主要是在 Externalizable 和 Serializable 的接口出现分支,如果实现了 Externalizable 接口并且类描述符非动态代理,则执行 writeExternalData,否则执行 writeSerialData。同时,这个方法会写类描述信息。
2.6 类信息序列化:writeClassDesc
// 递归调用 writeClassDesc 直到父类没有实现 Serializable,也就是说会保存父类的信息
private void writeClassDesc(ObjectStreamClass desc, boolean unshared) throws IOException {
int handle;
if (desc == null) {
writeNull();
} else if (!unshared && (handle = handles.lookup(desc)) != -1) {
writeHandle(handle); // 类信息已经序列化,则保存句柄即可
} else if (desc.isProxy()) {
writeProxyDesc(desc, unshared);
} else { // 非代理类信息序列化
writeNonProxyDesc(desc, unshared);
}
}
private void writeNonProxyDesc(ObjectStreamClass desc, boolean unshared) throws IOException {
bout.writeByte(TC_CLASSDESC);
handles.assign(unshared ? null : desc);
if (protocol == PROTOCOL_VERSION_1) {
desc.writeNonProxy(this);
} else {
writeClassDescriptor(desc); // 保存类信息,本质上也是调用 desc.writeNonProxy(this)
}
Class cl = desc.forClass();
bout.setBlockDataMode(true);
if (cl != null && isCustomSubclass()) {
ReflectUtil.checkPackageAccess(cl);
}
annotateClass(cl);
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
writeClassDesc(desc.getSuperDesc(), false); // 递归调用
}总结: 序列化时会先递归调用 writeClassDesc 方法,将实现 Serializable 接口的父类信息也会同时序列化。类信息都保存在 ObjectStreamClass 类中,同时也可以通过 ObjectStreamClass#getFields 获取所有要序列的字段信息 ObjectStreamField。
2.7 类数据信息序列化:writeSerialData
private void writeSerialData(Object obj, ObjectStreamClass desc)
throws IOException {
ObjectStreamClass.ClassDataSlot[] slots = desc.getClassDataLayout();
for (int i = 0; i < slots.length; i++) {
ObjectStreamClass slotDesc = slots[i].desc;
// 1. 自定义 writeObject 方法
if (slotDesc.hasWriteObjectMethod()) {
PutFieldImpl oldPut = curPut;
curPut = null;
SerialCallbackContext oldContext = curContext;
try {
curContext = new SerialCallbackContext(obj, slotDesc);
bout.setBlockDataMode(true);
slotDesc.invokeWriteObject(obj, this); // 调用自定义序列化 writeObject 方法
bout.setBlockDataMode(false);
bout.writeByte(TC_ENDBLOCKDATA);
} finally {
curContext.setUsed();
curContext = oldContext;
}
curPut = oldPut;
// 2. 默认序列化
} else {
defaultWriteFields(obj, slotDesc);
}
}
}总结: writeSerialData 首先获取需要序列化的类(desc.getClassDataLayout()),遍历进行序列化。对于重写 writeObject 方法则通过反射调用该方法,否则使用默认的序列化方式。
private class Animal { ... }
private class Person extends Animal implements Serializable { ... }
private class User extends Person { ... }上述情况下,User 序列化时通过 ObjectStreamClass#lookup(User.class) 获取其序列化类信息,getClassDataLayout 方法则获取要序列化的类 User 和 Person。关于 ObjectStreamClass 会在下面讲解。
private void defaultWriteFields(Object obj, ObjectStreamClass desc) throws IOException {
Class cl = desc.forClass();
if (cl != null && obj != null && !cl.isInstance(obj)) {
throw new ClassCastException();
}
desc.checkDefaultSerialize();
// 1. Java 原生类型序列化
int primDataSize = desc.getPrimDataSize(); // 1.1 获取原生类型字段的长度
if (primVals == null || primVals.length < primDataSize) {
primVals = new byte[primDataSize];
}
desc.getPrimFieldValues(obj, primVals); // 1.2 获取原生类型字段的值
bout.write(primVals, 0, primDataSize, false); // 1.3 原生类型序列化
// 2. Java 对象类型序列化,递归调用 writeObject0 方法
ObjectStreamField[] fields = desc.getFields(false); // 2.1 获取所有序列化的字段
Object[] objVals = new Object[desc.getNumObjFields()];
int numPrimFields = fields.length - objVals.length;
desc.getObjFieldValues(obj, objVals); // 2.2 获取所有序列化字段的值
for (int i = 0; i < objVals.length; i++) { // 2.3 递归完成序列化
writeObject0(objVals[i], fields[numPrimFields + i].isUnshared());
}
}总结: defaultWriteFields 原生类型直接序列化,而非原生类型则需要递归调用 writeObject0 来序列化。
3. ObjectOutputStream#BlockDataOutputStream
BlockDataOutputStream 是一个内部类,它继承了 OutputStream 并实现了 DataOutput 接口,缓冲输出流有两种模式:在默认模式下,输出数据和 DataOutputStream 使用同样模式;在块数据模式下,使用一个缓冲区来缓存数据到达最大长度或者手动刷新时将内容写入下层输入流,这点和 BufferedOutputStream 类似。不同之处在于,块模式在写数据之前,要先写入一个头部来表示当前块的长度。更多参考BlockDataOutputStream源码分析
4. ObjectOutputStream#HandleTable
HandleTable 也是一个内部类,这是一个轻量的 hash 表,它的作用是缓存写过的共享 class 便于下次查找,内部含有 3 个数组,spine、next 和 objs。objs 存储的是对象也就是 class,spine 是 hash 桶,next 是冲突链表,每有一个新的元素插入需要计算它的 hash 值然后用 spine 的大小取模,找到它的链表,新对象会被插入到链表的头部,它在 objs 和 next 中对应的数据是根据加入的序号顺序存储,spine 存储它的 handle 值也就是在另外两个数组中的下标。
// HandleTable 保存对象及其句柄的映射关系
private static class HandleTable {
private int[] spine; // 1. maps hash value -> candidate handle value
private int[] next; // 2. maps handle value -> next candidate handle value
private Object[] objs; // 3. maps handle value -> associated object
// 插入对象
int assign(Object obj) {
// 省略扩容代码 ...
insert(obj, size);
return size++;
}
private void insert(Object obj, int handle) {
int index = hash(obj) % spine.length;
objs[handle] = obj; // 对象表,通过 `句柄 -> 对象` 查找
next[handle] = spine[index]; // 冲突链表,保存上一个冲突的 hash 对应的 handle
spine[index] = handle; // hash桶表,保存当前 hash 对应的 handle
}
// 查找对象的句柄
int lookup(Object obj) {
if (size == 0) {
return -1;
}
int index = hash(obj) % spine.length;
for (int i = spine[index]; i >= 0; i = next[i]) {
if (objs[i] == obj) { // 查找时完成相等,非 equals 方法
return i;
}
}
return -1;
}
}总结: HandleTable 保存对象及其句柄的映射关系,如果对象已经序列化了,则在 HandleTable#lookup 返回的结果就不是 -1,此时只用保存对象的句柄就可以了,不需要重新保存一次类的信息,减小了序列化后的大小。
ReplaceTable 使用的是 HandleTable,表示可替换对象的关系表,和 HandleTable 功能类似,也是为了避免重复序列化。
private static class ReplaceTable {
private final HandleTable htab; // 1. maps object -> index
private Object[] reps; // 2. maps index -> replacement object
// 插入和查找
void assign(Object obj, Object rep) {
int index = htab.assign(obj);
reps[index] = rep;
}
Object lookup(Object obj) {
int index = htab.lookup(obj);
return (index >= 0) ? reps[index] : obj;
}
}5. ObjectOutputStream#PutField
PutField 也是一个内部类,可以通过它动态修改序列化的字段。PutField使用案例参考这里。
// 自定义序列化规则,调用 writeFields 进行序列化
private void writeObject(ObjectOutputStream out) throws Exception {
ObjectOutputStream.PutField putFields = out.putFields();
putFields.put("password", password + "-1");
out.writeFields(); // 这个方法只是调用了 putFields#writeFields
}总结: put 方法修改内容后,调用 writeFields 进行序列化。我们看一下 PutField 这个类的实现。
// Bits 是一个工具类,将 java 原生类型写入指定的 buffer 中
public void put(String name, int val) {
Bits.putInt(primVals, getFieldOffset(name, Integer.TYPE), val);
}
// 直接替换了原对象
public void put(String name, Object val) {
objVals[getFieldOffset(name, Object.class)] = val;
}
void writeFields() throws IOException {
// 1. 原生类型序列化
bout.write(primVals, 0, primVals.length, false);
// 2. 非原生类型序列化
ObjectStreamField[] fields = desc.getFields(false);
int numPrimFields = fields.length - objVals.length;
for (int i = 0; i < objVals.length; i++) {
writeObject0(objVals[i], fields[numPrimFields + i].isUnshared());
}
}总结: PutField 通过 put 方法修改属性后,还是调用 writeObject0 进行了对象的序列化。
参考: