原文地址https://martinfowler.com/articles/serverless.html。 翻译原文是为了加深自己的理解,本人英语不够好,理解偏差,翻译错误在所难免。
以下这篇长文深入探讨了无服务架构,如果你只需要无服务架构的简洁概述, 请看这里bliki entry on serverless
无服务架构
无服务架构指的是那些非常依赖第三方后台服务(BAAS)的应用程序, 或者是依靠短暂运行在容器里(FAAS)的客户代码的应用程序。 目前最有名的无服务提供商是亚马逊AWS lambda. 无服务架构理念通过把大量行为放到前端的方式, 消灭了一个传统的架构需求, 即“应用程序后面一定要有一个24小时开着的服务器系统“。 依赖于不同的情况, 无服务架构可以显著降低系统的运维成本和系统的复杂度, 相应的代价是,系统会依赖服务器提供商,还有相应的支持服务目前还不够成熟。
目录
- 什么是无服务?
- 几个例子
- 解析功能即服务
- 什么不是无服务
- 好处
- 减少运维成本
- 后台即服务-减少开发成本
- FaaS - 可伸缩的成本
- 更容易的运维管理
- 绿色计算?
- 坏处
- 固有的劣势
- 落地方面的劣势
- 无服务的特征
- 劣势迁移
- 新模式
- 超越了功能即服务
- 测试
- 可移植的实现
- 社区
- 结论
什么是无服务?
像很多的软件新趋势一样, 在”什么是无服务?“这个问题上,没有一个清晰的观点。 即便以下两个相互重叠的不同领域时,也无助于弄清什么是无服务:
- 无服务首先被用来描述那些显著依赖或者完全依赖第三方服务(云端)来管理服务端逻辑和状态的应用程序。 例如单页的网页应用程序和手机APP, 这些是典型的胖客户端应用使用云端提供的数据库生态系统, 授权等服务。以前这些服务被描述成Baas(后台即服务), 文章后面的部分我会用Baas来表示这类应用服务.
- 无服务也被用来表示这种应用: 应用的开发者写了一部分的服务端逻辑代码, 但和传统的服务架构不同, 这些服务端代码运行被运行在无状态的计算容器里。 这些计算容器是由事件触发的, 暂时的(很多持续一次请求的时间),完全被第三方管理的。可以认为这就是功能即服务(faas)AWS lambda 是目前最流行的faas服务实现, 但别家也有提供。文章后面的部分, 我用Faas来表示这类服务.
大多数情况下, 我会讨论第二种服务,因为第二种比较新,而且明显有别于我们通常考虑的技术架构, 第二种服务一直被用来宣传无服务。
但这两种概念实际上是相互关联,交叉的概念。例如 Auth0 开始是Baas,但 Auth0 Webtask已经属于Faas了。
此外, 在很多情况下, 当我们开发一个Baas应用的时候, 特别是当我们开发一个胖客户端(移动应用或者web应用)的时候, 可能会需要一定数量的服务端功能。 在这种情况下,Faas可能是一个好的解决方案。特别是这些服务端功能一定程度上集成了你正在使用的Baas服务(数据校验, 计算密集型处理如图形图像处理)
几个例子
用户界面驱动的应用
看一下传统的三层架构的,有服务端逻辑的客户端驱动的系统。典型的应用如电商App, 以在线宠物商店为例子。
传统架构如图所示,服务端用java实现, 客户端用html/javascrip实现。
用这个架构, 客户端相对不够智能,有很多的系统逻辑如:认证,页面导航,查找, 交易等都是有服务器端应用实现的。
用无服务架构实现宠物商店, 结果会看起来像这个样子。
以上是个大大简化了的视图,但即便用这个简化视图也可以看出几点重要的变化。请注意这不是一个推荐的架构迁移方案, 我只是用它作为一个工具来展示无服务的概念。
-
- 我们删除了原来应用里的认证逻辑, 替代为第三方的Baas服务.
- 使用另一个Baas例子, 我们允许客户端直接访问我们的产品列表数据库(完全是第三方的, 例如AWS dynamo)客户端可能要有一个有别于服务器端的安全配置文件用于访问数据库.
- 前两点隐含了非常重要的一点 --- 一些原来运行在宠物商店的服务端的逻辑现在运行在了客户端里, 例如: 跟踪用户的会话, 理解用户界面结构(例如: 页面导航), 从一个数据库读取数据然后转化数据成为一个用户可以使用的的视图等操作。客户端这时候实际上已经是一个单页应用程序。
- 我们可能希望把某些用户界面相关的功能放到服务器端, 例如, 计算密集型或者数据密集型功能。以查找为例,我们可以实现一个Faas函数通过API网关来处理http请求,而不需要有一个一直运行的服务器。 我们让客户端和服务函数都从同样的数据库里读取产品数据。既然旧的服务器是用java实现的, 并且lambda也支持用java实现的faas函数, 我们就可以把这些宠物商店的服务器端搜索代码不加修改地移植成Faas函数。
- 最终我们可以用另一个Faas函数替换购买功能,出于安全考虑, 购买功能的faas函数还是运行在服务器端, 而不是由客户端重新实现。 一样也需要用API 网管来封装
消息驱动的应用
另一个例子是,后台数据处理服务。 例如你正在写一个用户为中心的应用, 它需要快速响应用户界面的请求, 但同时你也想要记录所有正在发生的各种活动。以在线广告系统为例子, 当一个用户点击了一个广告, 你期望用户马上就被引导到广告页面。 但同时你也需要搜集点击事件来改变广告主的属性(这个不是一个假设的例子, 我以前在Intent Media的团队最近做过完全一样的设计)
传统架构里, 广告服务器同步地响应客户端。 但是也会发一个异步消息通知某个用户点击处理程序来减少广告商的预算.
在无服务架构的世界里, 以上应用看起来会是这个样子:
与先前的架构相比, 有一个非常小的区别。 我们用运行在服务上提供给我们的、事件驱动的Faas函数,替换了一直运行的处理异步消息的消费者应用程序。注意: vendor同时提供消息处理和Faas环境, 消息处理和Faas函数处理是紧密的结合在一起的。
Faas也可能通过实例化多个函数拷贝,并行处理多个点击事件.
功能即服务
我们已经提到了功能即服务,但是时候深入挖掘一下FaaS到底意味着什么. 让我们看一下 亚马逊的Lambda产品描述。 我加了一些记号在一些定义上, 然后我会继续扩展它们。
AWS Lambda 让你不需要准备和管理服务器就运行代码 (1) ... 用Lambda,你可以给任何类型的应用或者后台服务运行代码 (2) - 都是零管理的, 只需要上传你的代码,Lambda会接管一切 (3) 可扩展 (4) 你的代码具备了高可用性, 你可以设置你代码为自动被AWS服务触发。(5) 或者直接从任何的网页和移动应用上调用FaaS函数 (6).
- 本质上,Faas就是:不需要管理你自己的服务器系统或者不需要管理你自己的服务器应用就可以运行后台代码。 - 其中服务器应用 - 是区分其他的现代架构趋势(例如容器和PaaS)的关键点。
回到前面用我们用Faas处理点击的例子,我们把点击处理服务器(可能不是一个物理机器,但绝对是一个专门的服务应用)替换成了某个不需要一直运行的,不需要准备服务器的东西
-
- FaaS不要求在特定的框架里编程,也不要求使用特定的库函数。 在编程语言和开发环境方面,开发Faas函数和开发正常的应用没有区别。例如Lambda函数可以用Javascript, Python,或者任何JVM语言(scala,java,clojure等)编写。 但是你的Lambda函数可以执行另一个进程,所以你实际上可以使用任何能编译成Unix进程的语言。 Faas函数也一些重要的架构限制, 特别是与状态和长执行时间相关的情况。下面很快会提到。再思考一下点击处理的例子。 移植原先的代码到Faas世界的时候,唯一需要修改的代码是Main函数或者启动代码, 剩下的代码的就没有区别了。
- 既然我们没有服务应用, 部署就变得和传统系统很不一样了。 我们给Faas服务提供方上传代码, 剩下的我们就不用管了。现在部署Faas一般就是上传一个新的代码定义(例如, 一个zip文件或者一个jar包)然后调用一下专门的API初始化更新就可以了.
- 水平扩展完全自动化, 可伸缩, 由Faas服务器提供者管理。如果你的系统需要并行处理100个请求, 你不需要做任何额外配置, Faas服务提供者帮你搞定一切。执行你的函数的‘计算容器’是暂时的, Faas服务提供者完全依赖于运行时的需要来预备和销毁这些计算容器。
- 让我们回到点击处理器的例子,假如我们在某个好日子里,用户的广告的点击量比平日里增加了10倍。你的点击处理器能应付的聊这种突发情况吗?例如我们写了同时处理多个消息的代码了吗?即使我们写了这样的代码, 一个广告点击处理器实例是否能应付的了呢?如果我们运行了多个实例, 是否是自动扩展的呢?还是我们需要手工重新配置。 使用Faas你需要写一个函数用来判断并行量, 但是除了这个,Faas服务提供者自动帮你处理所有的扩展需求。
- Faas里的函数由Faas服务提供者定义的不同的事件类型触发。亚马逊AWS里, S3文件更新,定时任务,加到消息总线里的消息(Kinesis)都可以触发Faas函数执行。你写的Faas函数一般都需要提供一个参数来声明和哪个事件绑定。 在点击事件处理器的例子里, 我们假设我们已经使用了一个支持Faas的消息代理。 如果我们还没有使用Faas提供商的消息系统, 那我们必须修改变代码来支持faas提供商的消息生产者。
- 大多数的Faas服务提供者也允许函数被集成的Http请求触发,典型地例如一些API网关,(例如: AWS API GateWay, Webtask)宠物店的查找和购买Faas函数通过http请求触发.
状态
在本地状态(机器或者实例范围内的)方面,FaaS函数有明显局限。 简而言之, 你应该认为任何一次函数调用产生的状态(无论是进程内的或者主机的, RAM里的或者是写到硬盘上的)都不应该被下一次函数调用使用到。换句话说,从单元部署的角度看, Faas函数都是无状态的。
这对应用架构是一个巨大的冲击。这架构限制并不算独特,《APP的十二个因素》概念里也有完全同样的限制。
有了这个无状态的限制后, 什么是替代品?典型地, 这个限制意味着Faas函数或者是自然无状态的, 例如完全根据他们的输入来做变化, 或者利用数据库,跨应用的缓存(redis)或者网络服务存储(例如S3)来存储跨请求的状态, 并且作为后续请求处理的输入。
执行时长
FaaS函数典型地受制于每个请求被允许的处理时长。目前AWS Lambda函数不允许执行超过5分钟, 假如超过了, 会被终止执行。.
这意味着一些长时间执行的任务不再适合Faas, 需要重构。例如你需要创建几个不同的互相配合的Faas函数。 而在传统的环境下, 你只需要一个长时间执行的任务既有调度又有执行。
启动延时
目前你的Faas函数开始响应一个请求的时间依赖于很多的因素, 有可能从10毫秒到2分钟。 听起来很糟糕, 但是让我们用AWS Lambda做具体例子来看一下。
如果你的函数使用Javascript或者Python实现的, 而且也不大(例如少于一千行代码)那么启动它们的时间应该不会多于10~100毫秒。函数越大有可能看到更长的启动时间。
如果你的Lambda函数用JVM实现的,因为JVM需要启动,所以你可能需要更长的启动时间(例如大于10秒)。 但是这种长时间启动耗时只在一下场景下发生。 function is implemented on the JVM you may occasionally see long response times (e.g. > 10 seconds) while the JVM is spun up. However this only notably happens with either of the following scenarios:
- 低频请求, 两个请求处理之间间隔了10分钟.
- 突发流量,例如, 一般每秒处理10个请求, 但在10秒之内, 流量增加到了每秒100个请求。
第一种情况可以通过每5分钟ping一下, 保持活跃来解决。
这些问题是否很关键? 这依赖于你的应用的类型和流量的走势。 我以前的团队有一个用Java实现的异步消息处理Lambda App, 每天处理几百万个消息, 他们不担心启动延迟。但是如果你正在实现一个低延迟的交易应用, 无论用什么语言实现Faas函数, 你都可能就不想用Faas系统。
无论你的app是否有这样的问题, 你都应该模拟生产环境的压力测试来检查性能。如果发现你的用户案例现在不适合用FaaS,你也可能想过几个月再试试看, 因为这个领域是Faas服务提供商们正在重点攻关解决的领域。
API网关
文章前面提到过Faas的一个特点是API网关,API网关是一个Http服务器,里面定义了路由和终端节点, 每个路由都关联到一个Faas函数。当一个API网关收到一个请求的时候, 它会去通过查找路由配置找到对应的Faas函数。 典型地, API 网关会把http请求的参数Map到Faas函数的输入参数。API网关把Faas函数的结果再转变成Http应答, 并返回给调用者。
亚马逊Web服务有自己的API网关,别的Faas服务提供商业有类似的能力。
API网关除了分配发送请求, 也执行认证,输入校验,应答映射等操作。你也许已经开始怀疑这个是否是一个好主意, 请先忍一会, 我们后面会继续讨论.
API网关+Faas的一个例子是: 利用Faas函数的可扩展性,管理方便等优点,用无服务架构设计微服务
虽然目前API网关工具在架构上还不够成熟, 但是用API网关来设计应用,绝对不是一个坏事.
工具
尽管上面提到API网关工具不成熟, 但从整体来看FaaS无服务架构,也有一些例外情况,例如: Auth0 Webtask对Developer UX工具非常依赖, Tomasz Janczuk在最近的无服务会议上很好的演示了如何使用Developer UX
无服务应用的调试和监控一般都很麻烦, 接下来我们逐步讨论这个话题.
开源
无服务的Faas应用的好处之一是不用操心准备运行环境。所以开源代码目前对无服务不像在别的地方(例如:Docker和容器)一样重要。 未来我们有可能会看到一个流行的实现, 即Faas API网关运行在开发人员的工作站或者on primise的服务器上。IBM的OpenWhisk就是类似方案的实现例子。 看着IBM的这个实现或者其他的API网关实现变得流行起来会是挺有意思的事情。
除了运行实现, 已经有一些开源工具和框架可以帮助定义,部署,和辅助运行。 例如,使用Serverless Framework 工具可以让Lambda更容易用使用。 这个工具是Javascript的, 如果你正在写一个JS API网关, 这个工具绝对值得一试。
另外一个例子是Apex, 这个项目可以轻松的 编译,部署,管理AWS lambda函数。Apex提供了一个很有趣的功能, 允许你用AWS不支持的语言来开发Lambda函数, 例如Go语言.
什么不是无服务?
到这里我已经定义了, “无服务”是 ‘后端即服务’和‘功能即服务’的组合概念。我也深入探讨了功能即服务的各种能力。
在讨论无服务的优缺点之前, 我想在无服务的定义上再花点时间, 定义一下无服务不是什么。很多人包括我最近都曾经混淆过这些概念, 所以我认为值得讨论一下澄清什么不是无服务。
与PaaS相比较
既然无服务FaaS与PaaS的12个因素方法论很像,FaaS函数是不是类似Heroku一样,只是另一种形式的PaaS呢? 我引用Adrain Cockcroft的话来简单回答一下这个问题。
如果你的PaaS应用可以在20毫秒内启动,并且运行半秒钟,那就可以叫做ServerLess. -- Adrian Cockcroft
换句话说, 大多数的PaaS应用程序不会为每一个请求启动一次,而Faas平台确实这么做。
好, 但这又怎样?如果我是一个擅长APP十二因素SaaS方法论的开发者,写代码方面两者还是没有区别吧?是的, 但是两者在运维APP的方式上,是有很大区别的。 既然我们都是擅长DevOps的工程师, 我们运维和开发上思考的是一样多的, 对吧?
FaaS和PaaS在运维方面的关键区别是可扩展性. 使用PaaS的时候, 你需要考虑扩展性, 例如用Heroku的时候要考虑需要运行多少个Dynos, 而使用FaaS,这些对你是完全透明的。 即便你搭建了一个自动扩展的PaaS应用, 你也不会把这种扩展性做到针对单个请求的粒度上(除非你有一个专门生命的流量配置文件), 所以在成本方面, Faas比PaaS更有效率。
即使FaaS有这样的好处, 为什么你仍然要使用PaaS? 工具问题和不成熟的API网关可能是最主要的原因。 此外,PaaS的12因素方法论里用到了应用内的只读Cache,这个FaaS是不能用这个方法的。
与容器的比较
使用FaaS的一个原因是为了避免在操作系统级别上管理计算进程。 PaaS(像Heroku)也可以起到同样的效果,前面已经描述过PaaS和FaaS的区别。随着Docker成为最常见的容器技术,容器成为了流行的进程抽象概念。 我们也看到了容器上的系统,Mesos和Kubernetes变得越来越流行,它们把单个的应用从操作系统级别的部署中抽象出来。更进一步, 现在也有基于云的容器平台如 ECS, 和Google Contrainer Engine, 这些云容器像FaaS一样, 让开发团队避免管理服务器系统。 所以基于以上这些容器里程碑式的成就, 还有必要考虑无服务的FaaS吗?
原则上, 我提出的PaaS的问题一样也存在于容器里, --- 无服务FaaS扩展性是自动管理的, 透明的,细粒度的。 容器平台不提供这样的解决方案。
此外,我认为容器技术尽管非常流行, 但还是不够成熟。当然我也不能说无服务FaaS就是成熟的技术了, 但目前实际情况就是这样。
我承认,我提到的容器和PaaS的缺点会日益弱化。 但真正的无管理的、自动扩展的容器平台和FaaS关心的粒度不一样。我们看到Kubernetes的Pod水平自动扩展技术体现了这种趋势。 我想像的出来,一些非常聪明的流量模式以及暗含负载的指标正在被引入到这些特性里。 此外,快速进化的Kubernetes要不了多久就会成为一个简单,稳定的平台。
如果我们看到Fass无服务和容器之间的管理和扩展性的差别变得越来越小, 选择无服务还是容易完全看你的应用的风格和类型。 例如, 可能Faas被看做是事件驱动的、只有少量事件类型的应用的一个更好选择, 而容器被看做是同步请求驱动的,有许多入口的组件选择。 我期望5年后,许多应用和团队会同时使用这两种架构方法, 而且一定会看到 同时使用两种架构方法的的很多模式出现。
#无运维
Serverless不等于没有运维, 而是说有可能没有内部系统管理员,而且也依赖于你用Serverless有多深。 这里需要考虑两件事.
首先,运维意思不只是服务器管理, 它也有, 监控,部署,安全, 网络的意思, 而且经常也包括一定数量的产品调试和系统扩展。 运维的这些问题也存在于Serverless应用中, 所以你还是需要一个运营策略处理这些问题。某些方面, Serverless的运维甚至更难, 因为以前没有Serverless运维, 这都最近的事情。
其次, 即便仍然存在系统管理, 你要做的只不过是把系统管理外包给Serverless. 外包不是一件坏事, 我们外包很多事情。但是是否是好事也依赖于你要做什么。 (译者愤然评价: 这个作者是和稀泥的。)某些方面, Serverless无运维的概念可能有些漏洞,你得知道有人类的系统管理员正支持你的无服务应用。
Charity Majors 在最近的无服务会议上做过一个有关这个主题的精彩演讲, 我推荐你在线看一下。
存储过程即服务Stored Procedures as a Service
我看到的另一个无服务的主题是 存储过程即服务, 我觉得这是因为Faas服务的很多例子(包括我在这篇文章中用到的例子)都是封装数据库访问的一小块代码。如果我们用Faas就只干这个事情, 那么我会认为这个名字是对的。 但是这实际上这只是Faas能力的一小部分, 这么称呼Faas是对Faas的一个无效的约束。
一直都有一个说法, 要认真考虑Faas是否存在存储过程的相似问题, 包括Camile在推特里提到的技术上的担忧。存储过程有很多教训值得在Faas的参考。 比如以下这些问题:
1. 通常情况下,服务提供商会指定开发语言, 或者服务提供商会指定开发框架或某种语言的扩展包。
2. 因为存储过程在数据库环境里被执行, 所以很难被测试。
3.版本控制很麻烦, 被认为是一级应用。
以上的问题没有涵盖存储过程的所有情况, 但都是我自己碰到过的问题。 让我们看看这些问题是否也适用于Faas
对于第一点,我所了解的Fass实现绝对不需要担心第一点。所以, 我们可以把这一项从列表中擦掉。
对于第二点, 由于FaaS里我们处理纯代码, 单元测试绝对应该和别的代码一样容易。 集成测试是不同的问题, 我们后面会讨论。
对于第三点, 既然FaaS函数只是代码,版本控制问题还算OK, 但在软件打包方面, FaaS还没有成熟的方案。 我前面提到的无服务框架确实提供自己的打包形式。 AWS在最近16年5月份的无服务大会上宣布他们打算做一个有关打包的产品(Flourish), 但暂时打包还只是一个合理的担心
好处
到目前为止, 我只是尽力解释和定义了无服务架构的意思。 接下来,我打算讨论一下用无服务架构设计和部署应用的好处和缺点。
需要立即注意到这个技术是很新的。 AWS lambda在写这篇文章的时候,甚至不到两岁。 两年后我们现在认为的一些好处可能变成了宣传,而一些缺点也可能解决了。
So far I've mostly tried to stick to just defining and explaining what Serverless architectures have come to mean. Now I'm going to discuss some of the benefits and drawbacks to such a way of designing and deploying applications.
It's important to note right off the bat that some of this technology is very new. AWS Lambda - a leading FaaS implementation - isn't even 2 years old at time of writing. As such some of the benefits we perceive may end up being just hype when we look back in another 2 years, on the other hand some of the drawbacks will hopefully be resolved.
Since this is an unproven concept at large scale you should definitely not take any decision to use Serverless without significant consideration. I hope this list of pros and cons helps you get to such a choice.
We're going to start off in the land of rainbows and unicorns and look at the benefits of Serverless.
Reduced operational cost
Serverless is at its most simple an outsourcing solution. It allows you to pay someone to manage servers, databases and even application logic that you might otherwise manage yourself. Since you're using a defined service that many other people will also be using we see an Economy of Scale effect - you pay less for your managed database because one vendor is running thousands of very similar databases.
The reduced costs appear to you as the total of two aspects - infrastructure costs and people (operations / development) costs. While some of the cost gains maycome purely from sharing infrastructure (hardware, networking) with other users, the expectation is that most of all you'll need to spend less of your own time (and therefore reduced operations costs) on an outsourced serverless system than on an equivalent developed and hosted by yourself.
This benefit, however, isn't too different than what you'll get from Infrastructure as a Service (IaaS) or Platform as a Service (PaaS). But we can extend this benefit in 2 key ways, one for each of Serverless BaaS and FaaS.
BaaS - reduced development cost
IaaS and PaaS are based on the premise that server and operating system management can be commoditized. Serverless Backend as a Service on the other hand is a result of entire application components being commoditized.
Authentication is a good example. Many applications code their own authentication functionality which often includes features such as sign-up, login, password management, integration with other authentication providers, etc. On the whole this logic is very similar across most applications, and so services like Auth0 have been created to allow us to integrate ready-built authentication functionality into our application without us having to develop it ourselves.
On the same thread are BaaS databases, like Firebase's database service. Some mobile applications teams have found it makes sense to have the client communicate directly with a server-side database. A BaaS database removes much of the database administration overhead, plus it will typically provide mechanisms to provide appropriate authorization for different types of users, in the patterns expected of a Serverless app.
Depending on your background you may squirm at both of these ideas (for reasons that we'll get into in the drawbacks section - don't worry!) but there is no denying the number of successful companies who have been able to produce compelling products with barely any of their own server-side code. Joe Emison gave a couple of examples of this at the recent Serverless Conference.
FaaS - scaling costs
One of the joys of serverless FaaS is, as I put it earlier in this article, that 'horizontal scaling is completely automatic, elastic, and managed by the provider'. There are several benefits to this but on the basic infrastructural side the biggest benefit is that you only pay for the compute that you need, down to a 100ms boundary in the case of AWS Lambda. Depending on your traffic scale and shape this may be a huge economic win for you.
Example - occasional requests
For instance say you're running a server application that only processes 1 request every minute, that it takes 50 ms to process each request, and that your mean CPU usage over an hour is 0.1%. From one point of view this is wildly inefficient - if 1000 other applications could share your CPU you'd all be able to do your work on the same machine.
Serverless FaaS captures this inefficiency, handing the benefit to you in reduced cost. In this scenario you'd be paying for just 100ms of compute every minute, which is 0.15% of the time overall.
This has the following knock-on benefits:
- For would-be microservices that have very small load requirements it gives support to breaking down components by logic / domain even if the operational costs of such fine granularity might have been otherwise prohibitive.
- Such cost beneftis are a great democratizer. As companies or teams want to try out something new they have extremely small operational costs associated with ‘dipping their toe in the water’ when they use FaaS for their compute needs. In fact if your total workload is relatively small (but not entirely insignificant) you may not need to pay for any compute at all due to the 'free tier' provided by some FaaS vendors.
Example - inconsistent traffic
Let's look at another example. Say your traffic profile is very 'spikey' - perhaps your baseline traffic is 20 requests / second but that every 5 minutes you receive 200 requests / second (10 times the usual number) for 10 seconds. Let's also assume for the sake of example that your baseline performance maxes out your preferred server, and that you don't want to reduce your response time during the traffic spike phase. How do you solve for this?
In a traditional environment you may need to increase your total hardware capability by a factor of 10 to handle the spikes, even though they only account for less than 4% of total machine uptime. Auto-scaling is likely not a good option here due to how long new instances of servers will take to come up - by the time your new instances have booted the spike phase will be over.
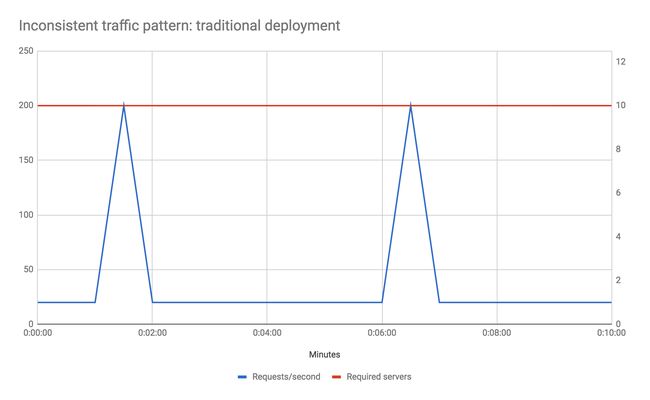
With Serverless FaaS however this becomes a non-issue. You literally do nothing differently than if your traffic profile was uniform and only pay for the extra compute capacity during the spike phases.
Obviously I've deliberately picked examples here for which Serverless FaaS gives huge cost savings, but the point is to show that unless you have a very steady traffic shape that consistently uses a whole number's worth of server systems that you may save money using FaaS purely from a scaling viewpoint.
One caveat about the above - if your traffic is uniform and would consistently make good utilization of a running server you may not see this cost benefit and may actually spend more using FaaS. You should do some math with current provider costs vs the equivalents of running full-time servers to check to see whether costs are acceptable.
Optimization is the root of some cost savings
There is one more interesting aspect to FaaS costs - any performance optimizations you make to your code will not only increase the speed of your app but will also have a direct and immediate link to reduction in operational costs, subject to the granularity of your vendor’s charging scheme. For example if each of your operations currently take 1 second to run and you reduce that to 200ms you’ll immediately see 80% savings in compute costs without making any infrastructural changes.
Easier Operational Management
This section comes with a giant asterisk - some aspects of operations are still tough for Serverless, but for now we’re sticking with our new unicorn and rainbow friends…
On the Serverless BaaS side of the fence it’s fairly obvious why operational management is more simple than other architectures: less components that you support equals less work.
On the FaaS side there are a number of aspects at play though and I’m going to dig into a couple of them.
Scaling benefits of FaaS beyond costs
While scaling is fresh in our minds from the previous section it’s worth noting that not only does the scaling functionality of FaaS reduce compute cost it also reduces operational management because the scaling is automatic.
In the best case if your scaling process was manual, e.g. a human being needs to explicitly add and remove instances to an array of servers, with FaaS you can happily forget about that and let your FaaS vendor scale your application for you.
Even in the case that you’ve got to the point of using ‘auto-scaling’ in a non FaaS architecture then that still requires setup and maintenance - this work is no longer necessary with FaaS.
Similarly since scaling is performed by the provider on every request / event, you no longer need to even think about the question of how many concurrent requests you can handle before running out of memory or seeing too much of a performance hit, at least not within your FaaS hosted components. Downstream databases and non FaaS components will have to be reconsidered in light of a possibly signifcant increase in their load.
Reduced packaging and deployment complexity
While API gateways are not simple yet, the act of packaging and deploying a FaaS function is really pretty simple compared with deploying an entire server. All you’re doing is compiling and zip’ing / jar’ing your code, and then uploading it. No puppet / chef, no start / stop shell scripts, no decisions about whether to deploy one or many containers on a machine. If you’re just getting started you don’t need to even package anything - you may be able to write your code right in the vendor console itself (this, obviously, is not recommended for production code!)
This doesn't take long to describe but in some teams this benefit may be absolutely huge - a fully Serverless solution requires zero system administration.
Platform-as-a-Service (PaaS) solutions have similar deployment benefits but as we saw earlier when comparing PaaS with FaaS the scaling advantages are unique to FaaS.
Time to market / experimentation
‘Easier operational management’ is a benefit which us as engineers understand, but what does that mean to our businesses?
The obvious case is cost: less time on operations = less people needed for operations. But by far the more important case in my mind is ‘time to market’. As our teams and products become increasingly geared around lean and agile processes we want to continually try new things and rapidly update our existing systems. While simple re-deployment allows rapid iteration of stable projects, having a good new-idea-to-initial-deployment capability allows us to try new experiments with low friction and minimal cost.
The new-idea-to-initial-deployment story for FaaS is in some cases excellent, especially for simple functions triggered by a maturely-defined event in the vendor’s ecosystem. For instance say your organization is using AWS Kinesis, a Kafka-like messaging system, for broadcasting various types of real-time events through your infrastructure. With AWS Lambda you can develop and deploy a new production event listener against that Kinesis stream in minutes - you could try several different experiments all in one day!
For web-based APIs the same cannot quite yet be said in the bulk of cases but various open source projects and smaller scale implementations are leading the way. We’ll discuss this further later.
‘Greener’ computing?
We’ve seen an explosion over the last couple of decades in the numbers and sizes of data centers in the world, and the associated energy usage that goes with them along with all the other physical resources required to build so many servers, network switches, etc. Apple, Google and the like talk about hosting some of their data centers near sources of renewable energy to reduce the fossil-fuel burning impact of such sites.
Part of the reason for this massive growth is the number of servers that are idle and yet powered up.
Typical servers in business and enterprise data centers deliver between 5 and 15 percent of their maximum computing output on average over the course of the year.
-- Forbes
That’s extraordinarily inefficient and a huge environmental impact.
On one hand it’s likely that cloud infrastructure has probably helped since companies can ‘buy’ more servers on-demand, rather than provision all possibly necessary servers a long-time in advance. However one could also argue that the ease of provisioning servers may have made the situation worse if a lot of those servers are getting left around without adequate capacity management.
Whether we use a self-hosted, IaaS or PaaS infrastructure solution we’re still making capacity decisions about our applications that will often last months or years. Typically we are cautious, and rightly so, about managing capacity and over-provision, leading to the inefficiencies just described. With a Serverless approach weno longer make such capacity decisions ourselves - we let the Serverless vendor provision just enough compute capacity for our needs in real time. The vendor can then make their own capacity decisions in aggregate across their customers.
This difference should lead to far more efficient use of resources across data centers and therefore to a reduced environmental impact compared with traditional capacity management approaches.
Drawbacks
So, dear reader, I hope you enjoyed your time in the land of rainbows, unicorns and all things shiny, because it’s about to get ugly as we get slapped around the face by the wet fish of reality.
There’s a lot to like about Serverless architectures and I wouldn’t have spent time writing about them if I didn’t think there were a lot of promise in them, but they come with significant trade-offs. Some of these are inherent with the concepts - they can’t be entirely fixed by progress and are always going to need to be considered. Others are down to the current implementations and with time we could expect to see those resolved.
Inherent Drawbacks
Vendor control
With any outsourcing strategy you are giving up control of some of your system to a 3rd-party vendor. Such lack of control may manifest as system downtime, unexpected limits, cost changes, loss of functionality, forced API upgrades, and more. Charity Majors, who I referenced earlier, explains this problem in much more detail in the Tradeoffs section of this article:
[The Vendor service] if it is smart, will put strong constraints on how you are able to use it, so they are more likely to deliver on their reliability goals. When users have flexibility and options it creates chaos and unreliability. If the platform has to choose between your happiness vs thousands of other customers’ happiness, they will choose the many over the one every time — as they should.
-- Charity Majors
Multitenancy Problems
Multitenancy refers to the situation where multiple running instances of software for several different customers (or tenants) are run on the same machine, and possibly within the same hosting application. It's a strategy to achieve the economy of scale benefits we mentioned earlier. Service vendors try their darndest to make it feel as a customer that we are the only people using their system and typically good service vendors do a great job at that. But no-one’s perfect and sometimes multitenant solutions can have problems with security (one customer being able to see another’s data), robustness (an error in one customer’s software causing a failure in a different customer’s software) and performance (a high load customer causing another to slow down.)
These problems are not unique to Serverless systems - they exist in many other service offerings that use multitenancy - but since many Serverless systems are new we may expect to see more problems of this type now than we will once these systems have matured.
Vendor lock-in
Here’s the 3rd problem related to Serverless vendors - lock in. It’s very likely that whatever Serverless features you’re using from a vendor that they’ll be differently implemented by another vendor. If you want to switch vendors you’ll almost certainly need to update your operational tools (deployment, monitoring, etc.), you’ll probably need to change your code (e.g. to satisfy a different FaaS interface), and you may even need to change your design or architecture if there are differences to how competing vendor implementations behave.
Even if you manage to be able to do this for one part of your ecosystem you may be locked in by another architectural component. For instance say you’re using AWS Lambda to respond to events on an AWS Kinesis message bus. The differences between AWS Lambda, Google Cloud Functions and Microsoft Azure Functions may be relatively small, but you’re still not going to be able to directly hook up the latter 2 vendor implementations directly to your AWS Kinesis stream. This means that moving, or porting, your code from one solution to another isn’t going to be possible without also moving other chunks of your infrastructure too.
And finally even if you figure out a way to reimplement your system with a different vendor’s capabilities you’re still going to have a migration process dependent on what your vendor offers you. For example if you’re switching from 1 BaaS database to another do the export and import features of the original and target vendors do what you want? And even if they do, at what amount of cost and effort?
One possible mitigation to some of this could be an emerging general abstraction of multiple Serverless vendors, and we’ll discuss that further later.
Security concerns
This really deserves an article in and of itself but embracing a Serverless approach opens you up to a large number of security questions. Two of these are as follows, but there are many others that you should consider.
- Each Serverless vendor that you use increases the number of different security implementations embraced by your ecosystem. This increases your surface area for malicious intent and the likelihood for a successful attack.
- If using a BaaS Database directly from your mobile platforms you are losing the protective barrier a server-side application provides in a traditional application. While this is not a dealbreaker it does require significant care in designing and developing your application.
Repetition of logic across client platforms
With a ‘full BaaS’ architecture no custom logic is written on the server-side - it’s all in the client. This may be fine for your first client platform but as soon as you need your next platform you’re going to need to repeat the implementation of a subset of that logic that you wouldn’t have done in a more traditional architecture. For instance if using a BaaS database in this kind of system all your client apps (perhaps Web, native iOS and native Android) are now going to need to be able to communicate with your vendor database, and will need to understand how to map from your database schema to application logic.
Furthermore if you want to migrate to a new database at any point you’re going to need to replicate that coding / coordination change across all your different clients too.
Loss of Server optimizations
Again with a ‘full BaaS’ architecture there is no opportunity to optimize your server-design for client performance. The ‘Backend For Frontend’ pattern exists to abstract certain underlying aspects of your whole system within the server, partly so that the client can perform operations more quickly and use less battery power in the case of mobile applications. Such a pattern is not available for 'full BaaS'.
I’ve made it clear that both this and previous drawback exist for ‘full BaaS’ architectures where all custom logic is in the client and the only backend services are vendor supplied. A mitigation of both of these is actually to embrace FaaS or some other kind of lightweight server-side pattern to move certain logic to the server.
No in-server state for Serverless FaaS
After a couple of BaaS-specific drawbacks let’s talk about FaaS for a moment. I said earlier:
FaaS functions have significant restrictions when it comes to local .. state. .. You should assume that for any given invocation of a function none of the in-process or host state that you create will be available to any subsequent invocation.
I also said that the alternative to this was to follow factor number 6 of the ‘Twelve Factor App’ which is to embrace this very constraint:
Twelve-factor processes are stateless and share-nothing. Any data that needs to persist must be stored in a stateful backing service, typically a database.
-- The Twelve-Factor App
Heroku recommends this way of thinking but you can bend the rules when running on their PaaS. With FaaS there’s no bending the rules.
So where does your state go with FaaS if you can’t keep it in memory? The quote above refers to using a database and in many cases a fast NoSQL Database, out-of-process cache (e.g. Redis) or an external file store (e.g. S3) will be some of your options. But these are all a lot slower than in-memory or on-machine persistence. You’ll need to consider whether your application is a good fit for this.
Another concern in this regard is in-memory caches. Many apps that are reading from a large data set stored externally will keep an in-memory cache of part of that data set. You may be reading from ‘reference data’ tables in a database and use something like Ehcache. Alternatively you may be reading from an http service that specifies cache headers, in which case your in-memory http client can provide a local cache. With a FaaS implementation you can have this code in your app but your cache is rarely, if ever, going to be of much benefit. As soon as your cache is ‘warmed up’ on the first usage it is likely to be thrown away as the FaaS instance is torn down.
A mitigation to this is to no longer assume in-process cache, and to use a low-latency external cache like Redis or Memcached, but this (a) requires extra work and (b) may be prohibitively slow depending on your use case.
Implementation Drawbacks
The previously described drawbacks are likely always going to exist with Serverless. We’ll see improvements in mitigating solutions, but they’re always going to be there.
The remaining drawbacks, however, are down purely to the current state of the art. With inclination and investment on the part of vendors and/or a heroic community these can all be wiped out. But for right now there are some doozies...
Configuration
AWS Lambda functions offer no configuration. None. Not even an environment variable. How do you have the same deployment artifact run with different characteristics according to the specific nature of the environment? You can’t. You have to redefine the deployment artifact, perhaps with a different embedded config file. This is an ugly hack. The Serverless framework can abstract this hack for you, but it’s still a hack.
I have reason to believe that Amazon are fixing this (and probably pretty soon) and I don’t know whether other vendors have the same problem, but I mention it right at the top as an example of why a lot of this stuff is on the bleeding edge right now.
DoS yourself
Here’s another fun example of why Caveat Emptor is a key phrase whenever you’re dealing with FaaS at the moment. AWS Lambda, for now, limits you to how many concurrent executions you can be running of all your lambdas. Say that this limit is 1000, that means that at any one time you are allowed to be executing 1000 functions. If something causes you to need to go above that you may start getting exceptions, queueing, and/or general slow down.
The problem here is that this limit is across your whole AWS account. Some organizations use the same AWS account for both production and testing. That means if someone, somewhere, in your organization does a new type of load test and starts trying to execute 1000 concurrent Lambda functions you’ll accidentally DoS your production applications. Oops.
Even if you use different AWS accounts for production and development one overloaded production lambda (e.g. processing a batch upload from a customer) could cause your separate real-time lambda-backed production API to become unresponsive.
Other types of AWS resources can be separated by context of environment and application area through various security and firewalling concepts. Lambda needs the same thing, and I’ve no doubt it will before too long. But for now, again, be careful.
Execution Duration
Earlier on in the article I mentioned that AWS Lambda functions are aborted if they run for longer than 5 minutes. That's a limitation which I would expect could be removed later, but it will interesting to see how AWS approach that.
Startup Latency
Another concern I mentioned before was how long it may take a FaaS function to respond, which is especially a concern of occasionally used JVM-implemented functions on AWS. If you have such a Lambda function it may take in the order of 10s of seconds to startup.
I expect AWS will implement various mitigations to improve this over time, but for now it may be a deal-breaker for using JVM Lambdas under certain use cases.
OK, that’s enough picking on AWS Lambda specifically. I’m sure the other vendors also have some pretty ugly skeletons barely in their closets.
Testing
Unit testing Serverless Apps is fairly simple for reasons I’ve talked about earlier - any code that you write is ‘just code’ and there aren’t for the most part a whole bunch of custom libraries you have to use or interfaces that you have to implement.
Integration testing Serverless Apps on the other hand is hard. In the BaaS world you’re deliberately relying on externally provided systems rather than (for instance) your own database. So should your integration tests use the external systems too? If yes how amenable are those systems to testing scenarios? Can you easily tear-up / tear-down state? Can your vendor give you a different billing strategy for load testing?
If you want to stub those external systems for integration testing does the vendor provide a local stub simulation? If so how good is the fidelity of the stub? If the vendor doesn’t supply a stub how will you implement one yourself?
The same kinds of problems exist in FaaS-land. At present most of the vendors do not provide a local implementation that you can use so you’re forced to use the regular production implementation. But this means deploying remotely and testing using remote systems for all your integration / acceptance tests. Even worse the kinds of problems I just described (no configuration, cross-account execution limits) are going to have an impact on how you do testing.
Part of the reason that this is a big deal is that our units of integration with Serverless FaaS (i.e. each function) are a lot smaller than with other architectures and therefore we rely on integration testing a lot more than we may do with other architectural styles.
Tim Wagner (general manager of AWS Lambda) made a brief reference at the recent Serverless Conference that they were tackling testing, but it sounded like it was going to rely heavily on testing in the cloud. This is probably just a brave new world, but I’ll miss being able to fully test my system from my laptop, offline.
Deployment / packaging / versioning
This is a FaaS specific problem. Right now we’re missing good patterns of bundling up a set of functions into an application. This is a problem for a few reasons:
- You may need to deploy a FaaS artifact separately for every function in your entire logical application. If (say) your application is implemented on the JVM and you have 20 FaaS functions that means deploying your JAR 20 times.
- It also means you can’t atomically deploy a group of functions. You may need to turn off whatever event source is triggering the functions, deploy the whole group, and then turn the event source back on. This is a problem for zero-downtime applications.
- And finally it means there’s no concept of versioned applications so atomic rollback isn’t an option.
Again there are open source workarounds to help with some of this, however it can only be properly resolved with vendor support. AWS announced a new initiative named ‘Flourish’ to address some of these concerns at the recent Serverless Conference, but have released no significant details as of yet.
Discovery
Similarly to the configuration and packaging points there are no well-defined patterns for discovery across FaaS functions. While some of this is by no means FaaS specific the problem is exacerbated by the granular nature of FaaS functions and the lack of application / versioning definition.
Monitoring / Debugging
At present you are stuck on the monitoring and debugging side with whatever the vendor gives you. This may be fine in some cases but for AWS Lambda at least it is very basic. What we really need in this area are open APIs and the ability for third party services to help out.
API Gateway definition, and over-ambitious API Gateways
A recent ThoughtWorks Technology Radar discussed over-ambitious API Gateways. While the link refers to API Gateways in general it can definitely apply to FaaS API Gateways specifically, as I mentioned earlier. The problem is that API Gateways offer the opportunity to perform much application specific-logic within their own configuration / definition domain. This logic is typically hard to test, version control, and even often times define. Far better is for such logic to remain in program code like the rest of the application.
With Amazon’s API Gateway at present you are forced into using many Gateway-specific concepts and configuration areas even for the most simple of applications. This is partly why open source projects like the Serverless framework and Claudia.js exist, to abstract the developer from implementation-specific concepts and allow them to use regular code.
While it is likely that there will always be the opportunity to over-complicate your API gateway, in time we should expect to see tooling to avoid you having to do so and recommended patterns to steer you away from such pitfalls.
Deferring of operations
I mentioned earlier that Serverless is not ‘No Ops’ - there’s still plenty to do from a monitoring, architectural scaling, security, networking, etc. point of view. But the fact that some people (ahem, possibly me, mea culpa) have described Serverless as ‘No Ops’ comes from the fact that it is so easy to ignore operations when you’re getting started - “Look ma - no operating system!” The danger here is getting lulled into a false sense of security. Maybe you have your app up and running but it unexpectedly appears on Hacker News, and suddenly you have 10 times the amount of traffic to deal with and oops - you’re accidentally DoS’ed and have no idea how to deal with it.
The fix here, like part of the API Gateway point above, is education. Teams using Serverless systems need to be considering operational activities early and it is on vendors and the community to provide the teaching to help them understand what this means.
The Future of Serverless
We’re coming to the end of this journey into the world of Serverless architectures. To close out I’m going to discuss a few areas where I think the Serverless world may develop in the coming months and years.
Mitigating the Drawbacks
Serverless, as I’ve mentioned several times already, is new. And as such the previous section on Drawbacks was extensive and I didn’t even cover everything I could have. The most important developments of Serverless are going to be to mitigate the inherent drawbacks and remove, or at least improve, the implementation drawbacks.
Tooling
The biggest problem in my mind with Serverless FaaS right now is tooling. Deployment / application bundling, configuration, monitoring / logging, and debugging all need serious work.
Amazon’s announced but as-yet unspecified Flourish project could help with some of these. Another positive part of the announcement was that it would be open source, allowing the opportunity for portability of applications across vendors. I expect that we’ll see something like this evolve over the next year or two in the open source world, even if it isn’t Flourish.
Monitoring, logging and debugging are all part of the vendor implementation and we’ll see improvements across both BaaS and FaaS here. Logging on AWS Lambda at least is painful right now in comparison with traditional apps using ELK and the like. We are seeing the early days of a few 3rd party commercial and open source efforts in this area (e.g. IOPipe and lltrace-aws-sdk) but we’re a long way away from something of the scope of New Relic. My hope is that apart from AWS providing a better logging solution for FaaS that they also make it very easy to plug into 3rd party logging services in much the same way that Heroku and others do.
API Gateway tooling also needs massive improvements, and again some of that may come from Flourish or advances in the Serverless Framework, and the like.
State Management
The lack of in-server state for FaaS is fine for a good number of applications but is going to be a deal breaker for many others. For example many microservice applications will use some amount of in-process cached state to improve latency. Similarly connection pools (either to databases or via persistent http connection to other services) are another form of state.
One workaround for high throughput applications will likely be for vendors to keep function instances alive for longer, and let regular in-process caching approaches do their job. This won’t work 100% of the time since the cache won’t be warm for every request, but this is the same concern that already exists for traditionally deployed apps using auto-scaling.
A better solution could be very low-latency access to out-of-process data, like being able to query a Redis database with very low network overhead. This doesn’t seem too much of a stretch given the fact that Amazon already offer a hosted Redis solution in their Elasticache product, and that they already allow relative co-location of EC2 (server) instances using Placement Groups.
More likely though what I think we’re going to see are different kinds of application architecture embraced to take account of the no-in-process-state constraint. For instance for low latency applications you may see a regular server handling an initial request, gathering all the context necessary to process that request from it’s local and external state, then handing a fully-contextualized request off to a farm of FaaS functions that themselves don’t need to look up data externally.
Platform Improvements
Certain drawbacks to Serverless FaaS right now are down to the way the platforms are implemented. Execution Duration, Startup Latency, non-separation of execution limits are 3 obvious ones. These will likely be either fixed by new solutions, or given workarounds with possible extra costs. For instance I could imagine that Startup Latency could be mitigated by allowing a customer to request 2 instances of a FaaS function are always available at low latency, with the customer paying for this availability.
We’ll of course see platform improvements beyond just fixing current deficiencies, and these will be exciting to see.
Education
Many vendor-specific inherent drawbacks with Serverless are going to be mitigated through education. Everyone using such platforms needs to think actively about what it means to have so much of their ecosystems hosted by one or many application vendors. Questions that need to be considered are ones like ‘do we want to consider parallel solutions from different vendors in case one becomes unavailable? How do applications gracefully degrade in the case of a partial outage?’
Another area for education is technical operations. Many teams these days have fewer ‘Sys Admins’ than they used to, and Serverless is going to accelerate this change. But Sys Admins do more than just configure Unix boxes and chef scripts - they’re also often the people on the front line of support, networking, security and the like.
A true DevOps culture becomes even more important in a Serverless world since those other non Sys Admin activities still need to get done, and often times it’s developers who’ll be responsible for them. These activities may not come naturally to many developers and technical leads, so education and close collaboration with operations folk will be of utmost importance.
Increased transparency / clearer expectations from Vendors
And finally on the subject of mitigation Vendors are going to have to be even more clear in the expectations we can have of their platforms as we continue to rely on them for more of our hosting capabilities. While migrating platforms is hard, it’s not impossible, and untrustworthy vendors will see their customers taking their business elsewhere.
The emergence of patterns
Apart from the rawness of the underlying platforms our understanding of how and when to use Serverless architectures is still very much in its infancy. Right now teams are throwing all kinds of ideas at a Serverless platform and seeing what sticks. Thank goodness for pioneers!
But at some point soon we’re going to start seeing patterns of recommended practice emerge.
Some of these patterns will be in application architecture. For instance how big can FaaS functions get before they get unwieldy? Assuming we can atomically deploy a group of FaaS functions what are good ways of creating such groupings - do they map closely to how we’d currently clump logic into microservices or does the difference in architecture push us in a different direction?
Extending this further what are good ways of creating hybrid architectures between FaaS and traditional ‘always on’ persistent server components? What are good ways of introducing BaaS into an existing ecosystem? And, for the reverse, what are the warning signs that a fully- or mostly-BaaS system needs to start embracing or using more custom server-side code?
We’ll also see more usage-patterns emerge. One of the standard examples for FaaS is media conversion: “whenever a large media file is stored to an S3 bucket then automatically run processes to create smaller versions in another bucket.” But we need more usage-patterns to be catalogued in order to see if our particular use cases might be a good fit for a Serverless approach.
Beyond application architecture we’ll start seeing recommended operational patterns once tooling improves. How do we logically aggregate logging for a hybrid architecture of FaaS, BaaS and traditional servers? What are good ideas for discovery? How do we do canary releases for API-gateway fronted FaaS web applications? How do we most effectively debug FaaS functions?
Beyond ‘FaaSification’
Most usages of FaaS that I’ve seen so far are mostly about taking existing code / design ideas and ‘FaaSifying’ them - converting them to a set of stateless functions. This is powerful, but I also expect that we’ll start to see more abstractions and possibly languages using FaaS as an underlying implementation that give developers the benefits of FaaS without actually thinking about their application as a set of discrete functions.
As an example I don’t know whether Google use a FaaS implementation for theirDataflow product, but I could imagine someone creating a product or open source project that did something similar, and used FaaS as an implementation. A comparison here is something like Apache Spark . Spark is a tool for large-scale data processing offering very high level abstractions which can use Amazon EMR / Hadoop as its underlying platform.
Testing
As I discussed in the ‘Drawbacks’ section there is a lot of work to do in the area of integration and acceptance testing for Serverless systems. We’ll see vendors come out with their suggestions, which will likely be cloud based, and then I suspect we’ll see alternatives from old crusties like me who want to be able to test everything from their development machine. I suspect we’ll end up seeing decent solutions for both on- and offline testing, but it could take a few years.
Portable implementations
At present all popular Serverless implementations assume deployment to a 3rd-party Vendor system in the cloud. That’s one of the benefits to Serverless - less technology for us to maintain. But there’s a problem here if a company wants to take such technology and run it on their own systems and offer it as an internal service.
Similarly all the implementations have their own specific flavor of integration points - deployment, configuration, function interface, etc. This leads to the vendor lock-in drawbacks I mentioned earlier.
I expect that we’ll see various portable implementations created to mitigate these concerns. I’m going to discuss the 2nd one first.
Abstractions over Vendor implementations
We’re already starting to see something like this in open source projects like the Serverless Framework and the Lambada Framework. The idea here is that it would be nice to be able to code and operate our Serverless apps with a development-stage neutrality of where and how they are deployed. It would be great to be able to easily switch, even right now, between AWS API Gateway + Lambda, and Auth0 webtask, depending on the operational capabilities of each of the platforms.
I don’t expect such an abstraction to be complete until we see much more of a commoditization of products, but the good thing is that this idea can be implemented incrementally. We may start with something like a cross-vendor deployment tool - which may even be AWS’s Flourish project that I mentioned earlier - and build in more features from there.
One tricky part to this will be modeling abstracted FaaS coding interfaces without some idea of standardization, but I’d expect that progress could be made on non proprietary FaaS triggers first. For instance I expect we’ll see an abstraction of web-request and scheduled (‘cron’) Lambdas before we start seeing things like abstraction of AWS S3 or Kinesis Lambdas.
Deployable implementations
It may sound odd to suggest that we use Serverless techniques without using 3rd-party providers, but consider these thoughts:
- Maybe we’re a large technical organization and we want to start offering aFirebase-like database experience to all of our mobile application development teams, but we want to use our existing database architecture as the back end.
- We’d like to use FaaS style architecture for some of our projects, but for compliance / legal / etc. reasons we need to run our applications ‘on premise’.
In either of these cases there are still many benefits of using a Serverless approach without those that come from vendor-hosting. There’s a precedent here - consider Platform-as-a-Service (PaaS). The initial popular PaaS’s were all cloud based (e.g. Heroku), but fairly quickly people saw the benefits of running a PaaS environment on their own systems - a so-called ‘Private PaaS’ (e.g. Cloud Foundry).
I can imagine, like private PaaS implementations, seeing both open source and commercial implementations of both BaaS and FaaS concepts becoming popular.Galactic Fog is an example of an early-days open source project in this area, which includes its own FaaS implementation. Similarly to my point above about vendor abstractions we may see an incremental approach. For example the Kong project is an open source API Gateway implementation. At the time of writing it doesn’t currently integrate with AWS Lambda (although this is being worked on), but if it did this would be an interesting hybrid approach.
Community
I fully expect to see a huge growth of the Serverless community. Right now there’s been one conference and there are a handful of meetups around the world. I expect that we’ll start seeing something more like the massive communities that exist around Docker and Spring - many conferences, many communities, and more online fora than you can possibly keep track of.
Conclusion
Serverless, despite the confusing name, is a style of architecture where we rely to a smaller extent than usual on running our own server side systems as part of our applications. We do this through two techniques - Backend as a Service (BaaS), where we tightly integrate third party remote application services directly into the front-end of our apps, and Functions as a Service (FaaS), which moves server side code from long running components to ephemeral function instances.
Serverless is very unlikely to be the correct approach for every problem, so be wary of anyone who says it will replace all of our existing architectures. And be even more careful if you take the plunge into Serverless systems now, especially in the FaaS realm. While there are riches (of scaling and saved deployment effort) to be plundered, there also be dragons (of debugging, monitoring) lurking right around the next corner.
Those benefits shouldn't be quickly dismissed however since there are significant positive aspects to Serverless Architecture, including reduced operational and development costs, easier operational management, and reduced environmental impact. The most important benefit to me though is the reduced feedback loop of creating new application components - I’m a huge fan of ‘lean’ approaches, largely because I think there is a lot of value in getting technology in front of an end user as soon as possible to get early feedback, and the reduced time-to-market that comes with Serverless fits right in with this philosophy.
Serverless systems are still in their infancy. There will be many advances in the field over the coming years and it will be fascinating to see how they fit into our architectural toolkit.
Origin of ‘Serverless’
The term ‘Serverless’ is confusing since with such applications there are both server hardware and server processes running somewhere, but the difference to normal approaches is that the organization building and supporting a ‘Serverless’ application is not looking after the hardware or the processes - they are outsourcing this to a vendor.
First usages of the term seem to have appeared around 2012, including this article by Ken Fromm. Badri Janakiraman says that he also heard usage of the term around this time in regard tocontinuous integration and source control systems being hosted as a service, rather than on a company’s own servers. However this usage was about development infrastructure rather than incorporation into products.
We start to see the term used more frequently in 2015, after AWS Lambda’s launch in 2014 and even more so after Amazon’s API Gateway launched in July 2015. Here’s an example whereAnt Stanley writes about Serverless following the API Gateway announcement. In October 2015 there was a talk at Amazon’s re:Invent conference titled “The Serverless Company using AWS Lambda”, referring to PlayOn! Sports. Towards the end of 2015 the ‘Javascript Amazon Web Services (JAWS)’ open source project renamed themselves to the Serverless Framework, continuing the trend.
Fast forward to today (mid 2016) and one sees examples such as the recent Serverless Conference, plus the various Serverless vendors are embracing the term from product descriptions to job descriptions. Serverless as a term, for better or for worse, is here to stay.