SWPU CTF题解
本博客为西南石油大学(南充校区)CTF团队赛的题解
所有题目网址:http://47.106.87.69:9000/game
今天我是流泪狗狗头
解压后发现压缩包中是一个带有密码的图片,winhex分析二进制,发现文件数据区的全局加密为00 00,但压缩源文件目录区的全局方位标记为09 00,可知为伪加密,更改为00 00即可在解压出图片,再用notepad打开即可发现藏在文件末尾的flag
你知道啥是机器人吗?
打开./robots.html即可发现flag
我说这是签到题你信吗
放大后即可发现flag
星座之谜
甲子纪年法,60一甲子,把年份对应成数字为
5 7 28 6 20 21 21 19,然后根据+甲子,再加上60即为
65 67 88 86 80 81 81 79
都在A-Z的范围,翻译提交不正确,可猜测还有字符加密,通过栅栏解密,再分别凯撒解密,即可得到最后flag
出题人正在学前端
wireshark或者brupsuite抓包即可,也可以禁止网页js达到进制页面跳转的效果。
简单信息检索
枚举不同组合即可
有趣的GIF
跑一下发现文件下面还有一个GIF文件,分离出来,然后再分帧找到最后一句话即可得到flag
嘤嘤嘤
js代码aaencode加密
控制台跑一下即可
Eazy_android
修改apk为rar文件,解压得到classes.dex文件,然后丢jadx-gui分析源码即可得到flag
简单MD5
写个脚本跑一下即可,脚本如下


import hashlib # 明文为: djas?djashkj?as?ad # 密文为 : 765781f???2485b8b727ce3c???d0e90 str1 = 'djas' str2 = 'djashkj' str3 = 'as' str4 = 'ad' #遍历所有字符 res = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z'] def getMd5(plaintext): md5Object = hashlib.md5() md5Object.update(str(plaintext).encode("UTF-8")) return md5Object.hexdigest() for i in res: for j in res: for k in res: plaintext = str1 + i + str2 + j + str3 + k + str4 # 拼接明文字符串 print (plaintext + " ",end = " ") md5 = getMd5(plaintext) print (md5) # 判断是否成功 if md5.startswith('765781f') and md5.endswith('d0e90'): print ('Flag is : spctf{' + md5 + '}') exit(0)
图片很好看
看着像二维码,对比一下发现颜色反了,Stegsolve打开相反色扫描即可得到Flag
这是一道RE
基础python反汇编,通过https://tool.lu/pyc/得到源码,然后编写解密脚本即可得到Flag
import base64 def decode(message): message = base64.b64decode(message) s = '' for i in message: x = int(i) - 16 x = x ^ 32 s += chr(x) return s correct = 'Y2BTZFZrWY9kWFleW49ZJ48hY49VUWppbQ==' print(decode(correct))
出题人学完前端了
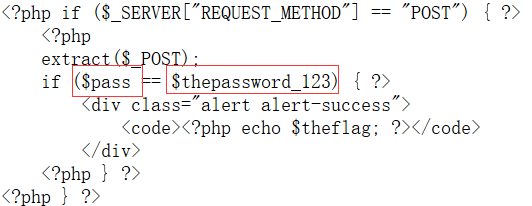
既让pass变量和thepassword_123变量相等即可,所以通过POST传参使得两变量相等即可得到flag
Are u ok?
Ook编码解密即可得到Flag
QWER
abcd对应qwer即可得到Flag
Crack Me
ReversingKr原题,自行百度
F5一把梭
ReversingKr原题,自行百度
高级信息检索
右下角水印找到原微博即可在评论区找到Flag
又是一个签到题
分析二进制发现有ZIP文件结尾,但是文件开头PK改成了PL,改为PK即可找到隐藏压缩包中的FLAG文件
又是一个Zip
编写脚本异或两文件即可得到Flag,脚本如下
import binascii import struct def str2hex(str): hexs = [] for s in str: tmp = (hex(ord(s)).replace('0x','')) if len(tmp) == 2: hexs.append(tmp) else: hexs.append('0'+tmp) return hexs arr = ['0','1','2','3','4','5','6','7','8','9','a','b','c','d','e','f'] arr2 = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] def tran(r): for i in range(len(arr)): if r == arr[i]: return arr2[i] f = open('A','rb') f2 = open('B','rb') hexs = [] hexs2 = [] while True: t = f.readline() t2 = f2.readline() if not t or not t2: break hexs.extend(str2hex(t)) hexs2.extend(str2hex(t2)) f.close() f2.close() ff = open('out.txt','wb') for i in range(min(len(hexs),len(hexs2))): a = tran(hexs[i][0])*16+tran(hexs[i][1]) b = tran(hexs2[i][0])*16+tran(hexs2[i][1]) B = struct.pack('B',a^b) ff.write(B) ff.close()
平面坐标系
群文件有WP,不再写