学习笔记——归并排序
算法介绍
- 归并
即将两个有序的数组归并成一个更大的有序数组。 - 归并排序
要将一个数组排序,可以先(递归)将它分成两半分别排序,然后将结果归并起来。 - 简单归并排序
创建一个适当大小的数组,然后将两个输入数组中的元素一个一个放入这个数组中。
这种算法很容易实现,但是当数组比较大时,需要进行多次归并,每次归并都需要创建一个新的数组来储存结果,消耗的空间会非常大。 - 原地归并
仅靠在数组中移动元素,不使用额外的空间进行归并排序。
原地归并的代码实现
//原地归并
func merge(a []int, lo, mid, hi int) {
i, j := lo, mid+1
for k := lo; k <= hi; k++ {
aux[k] = a[k]
}
for k := lo; k <= hi; k++ {
if i > mid {
a[k] = aux[j]
j++
} else if j > hi {
a[k] = aux[i]
i++
} else if aux[j] < aux[i] {
a[k] = aux[j]
j++
} else {
a[k] = aux[i]
i++
}
}
}
先将所有元素都复制到aux中,然后再归并回a中。
在归并时(第二个for循环进行了4个条件判断:左半边用尽(取右半边的元素、右半边用尽(取左半边的元素)、右半边的当前元素小于左半边的当前元素(取右半边的元素)以及右半边的当前元素大于等于左半边的当前元素(取左半边的元素)。
自顶向下的归并排序
var aux []int
func Sort(a []int) {
aux = make([]int, len(a))
sort(a, 0, len(a)-1)
}
func sort(a []int, lo, hi int) {
if hi <= lo {
return
}
mid := lo + (hi-lo)/2
sort(a, lo, mid) //左半边排序
sort(a, mid+1, hi) //右半边排序
merge(a, lo, mid, hi) //归并结果
}
下图为归并的具体过程:
算法分析
- 对于长度为N的任意数组,自顶向下归并排序需要 1 / 2 N l g N 1/2NlgN 1/2NlgN至 N l g N NlgN NlgN次比较。
- 对于长度为N的任意数组,自顶向下归并排序最多访问数组 6 N l g N 6NlgN 6NlgN次。
做个实验
接下来我想将go的协程特性运用在自顶向下的归并排序中测试一下性能是否会有提升。
编写测试脚本
package main
import (
"math/rand"
"time"
"./merge"
"github.com/BB-fat/gostopwatch"
)
func main() {
a := []int{}
seed := rand.NewSource(time.Now().Unix())
r := rand.New(seed)
for i := 0; i < 100000000; i++ {
a = append(a, r.Intn(100000000))
}
gs := gostopwatch.StopWatch{}
gs.NewTimer("计时器")
merge.Sort(a)
gs.NewPoint("计时器", "连接完成")
gs.PrintOneTimer("计时器")
}
利用我之前写的一个go秒表来给程序运行计时。
测试的数据量是一亿。
首先使用正常的自顶向下归并排序将这个随机生成的数组排序,结果耗时15.6秒。
改进sort函数
func sort(a []int, lo, hi int) {
if hi <= lo {
return
}
mid := lo + (hi-lo)/2
wg := sync.WaitGroup{}
wg.Add(2)
go func() {
sort(a, lo, mid) //左半边排序
wg.Done()
}()
go func() {
sort(a, mid+1, hi) //右半边排序
wg.Done()
}()
wg.Wait()
merge(a, lo, mid, hi) //归并结果
}
左半边右半边分别通过一个协程启动,并通过WaitGroup阻塞每一层的sort函数。
接下来运行测试脚本进行测试,结果耗时3分多!
并且在运行的时候cpu和内存使用均出现了异常。
结果分析
go语言的协程特性使程序员可以很方便的使用它编写并发程序,这一点要清楚:是并发不是并行。并行是指同时有多个程序在运行,而并发是指多个函数在同一时间段运行,但是在同一时刻cpu只在执行一条语句。使用并发来解决问题所在的层次是在算法之上的,举个例子:一个程序有两个协程,其中一个要通过网络传输数据,另一个需要和硬盘交换数据,那么如果协程一在请求网络通信之后等待网络的返回,此时通过go的协程调度,程序可以先执行和硬盘交互的协程,等网络响应之后再继续执行协程一。
在这个问题中,因为归并排序中存在递归,所以程序在运行起来之后将创建几千万个协程,每一个协程都要分配相应的内存资源,而且程序在切换协程的时候也需要消耗一些性能,所以这么做不但没有优化算法,反而将电脑搞成平底锅,实在是愚蠢。
对小规模子数组使用插入排序
归并排序适用于长度较大的数组,对于长度较小的数组简单的排序方法会比归并排序更快,接下来我就设定在数组长度小于15的时候使用插入排序。
package merge
func Sort_insert(a []int) {
aux = make([]int, len(a))
sort(a, 0, len(a)-1)
}
func sort_insert(a []int, lo, hi int) {
if hi-lo <= 16 {
for i := lo; i < hi; i++ {
for j := i; j >= lo && a[j] < a[j-1]; j-- {
tmp := a[j]
a[j] = a[j-1]
a[j-1] = tmp
}
}
}
mid := lo + (hi-lo)/2
sort_insert(a, lo, mid) //左半边排序
sort_insert(a, mid+1, hi) //右半边排序
merge(a, lo, mid, hi) //归并结果
}
编写一个测试脚本来验证这个猜想,测试数据大小是10亿。
func main() {
a := []int{}
seed := rand.NewSource(time.Now().Unix())
r := rand.New(seed)
for i := 0; i < 1000000000; i++ {
a = append(a, r.Intn(1000000000))
}
b := make([]int, len(a))
copy(b, a)
// fmt.Println(a)
gs := gostopwatch.StopWatch{}
gs.NewTimer("普通归并排序")
merge.Sort(a)
// fmt.Println(a)
gs.NewPoint("普通归并排序", "完成")
gs.NewTimer("优化归并排序")
merge.Sort_insert(b)
gs.NewPoint("优化归并排序", "完成")
gs.PrintAllTimers()
}
由于数据量较大,程序跑起来比较吓人。
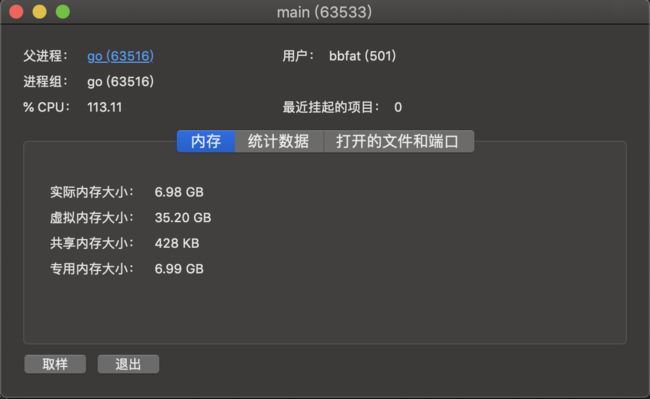

测试结果:
普通归并排序
完成 4m31.531979145s
优化归并排序
完成 4m14.386619368s
速度提升了10%左右
自底向上的归并排序
实现归并排序的另一种方法是先归并那些微型数组,然后再成对归并得到的子数组,如此这般,直到我们将整个数组归并在一起。这种实现方法比标准递归方法所需要的代码量更少。首先我们进行的是两两归并(把每个元素想象成一个大小为1的数组),然后是四四归并(将两个大小为2的数组归并成一个有4个元素的数组),然后是八八的归并,一直下去。
代码实现
merge函数同自顶向下归并排序。
func SortBU(a []int) {
aux = make([]int, len(a))
n := len(a)
for sz := 1; sz < n; sz += sz {
for lo := 0; lo < n-sz; lo += sz + sz {
merge(a, lo, lo+sz-1, int(math.Min(float64(lo+sz+sz-1), float64(n-1))))
}
}
}
算法分析
自底向上归并排序图解:
- 对于长度为N的任意数组,自底向上的归并排序需要1/2NlgN至NlgN次比较,最多访问数组6NgN次。
- 当数组长度为2的幂时,自顶向下和自底向上的归并排序所用的比较次数和数组访问次数相同。
- 自底向上的归并排序比较适合用链表组织的数据,因为该方法只需要重新组织链表的链接就能将链表原地排序(不需要创建新的节点)。
- 没有任何基于比较的算法能够保证使用少于lg(N)~NlgN次比较将长度为N的数组排序。
本节代码