java常用类库——io包
文章目录
- io包
- 文件系统
- File & FileFilter & FilenameFilter
- io流
- 介绍
- 字符流和字节流的主要区别
- 字节流读写方法
- 字符流读写方法
- io异常
- IOException异常
- FileNotFoundException异常
- InterruptedIOException异常
io包
通过数据流,序列化和文件系统提供系统输入和输出。 除非另有说明,否则在此包中的任何类或接口中将null参数传递给构造函数或方法将导致抛出NullPointerException 。
文件系统
File & FileFilter & FilenameFilter
File类提供了很多对文件和目录操作的方法
小知识:
相对路径:./表示当前路径…/表示上一级路径,相对路径就需要有参照
绝对路径:绝对路径名是完整的路径名,不需要任何其他信息就可以定位自身表示的文件
常用的属性:separator
我们在拼接文件路径的时候总会需要拼接路径分隔符,在Windows下的路径分隔符和Linux下的路径分隔符是不一样的,当直接使用绝对路径时,跨平台会暴出“No such file or diretory”的异常。
例如:Windows系统下创建文件 File file = new File(“E:\java\test.txt”) 或者 File file = new File(“E://java//test.txt”)
Linux系统下创建文件 File file = new File("/java/test.txt")
如果将Windows环境下开发的代码部署到Linux系统中就会读取不到文件,那么就需要设置分隔符根据不同系统改变斜杠的方向,所以跨平台开发可以使用如下方式创建文件
File file = new File(“E:” + File.separator + “java” + File.separator + “test.txt”)
其实也可以使用“/”,在Windows和Linux系统都可以识别,而且如果是将文件路径存库的话,使用File.separator,那么存储在数据库中文件分隔符就是当前系统的格式,比如Windows系统,那么存在数据库的文件分隔符就是“\”,若将系统部署到Linux系统中从数据库中读取了该文件路径,那么就会导致在Linux系统中找不到文件的问题。
常用的构造函数:File(String pathname)
我们通常指定一个抽象路径的字符串来创建File实例
常用的方法:
创建文件:createNewFile() 返回boolean类型表示是否创建成功
创建目录:mkdir() 和 mkdirs()
区别:mkdirs()可以如果父目录不存在也可以创建
删除文件或目录: delete() 注意只能删除空目录
判断文件或目录是否存在:exists()
获取文件各种路径的方法:
getAbsoluteFile() 获取抽象路径的绝对形式 返回File类型
getAbsolutePath() 获取抽象路径的绝对路径字符串 返回String类型
getParent() 获取抽象路径的父路径的字符串 返回String类型
getPath() 获取抽象路径的字符串 返回String类型
。。。。。。
获取文件或目录名称:getName()
判断是否是文件:isFile()
获取文件长度:length()
获取文件集合:
listFiles() 获取指定路径下的所有文件 返回File[ ]
listFiles(FileFilter filter) 和 listFiles(FilenameFilter filter) 可以过滤文件
区别:FileFilter和FilenameFilter接口中方法accept参数不同,FilenameFilter的方法accept(File dir , String name)其中dir就是指定文件或目录,name就是指定文件或目录的名称,比如:可以判断文件是否是txt结尾的等场景,而FileFilter的方法accept(File pathname)其中pathname就是指定抽象路径名,所以接口FileFilter是抽象路径名的过滤器,接口FilenameFilter是文件名的过滤器
io流
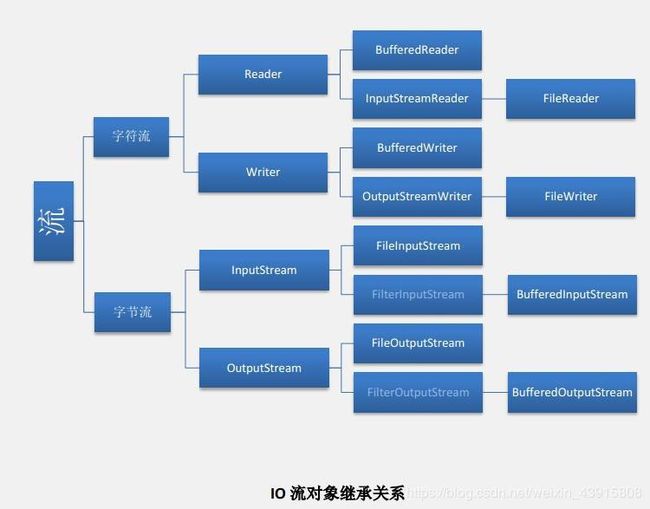
上图就是我们常用的数据流,根据字符流和字节流分类的,其实流还有其他分类标准,比如:输入输出流
介绍
四大抽象超类:
InputStream & OutputStream 和 Reader & Write分别是字节输入流&字节输出流和字符输入流&字符输出流的抽象基类,
文件流:
常用的读取文件使用到文件流 FileInputStream & FileOutputStream 和 FileReader & FileWrite
缓存流:
BufferedInputStream & BufferedOutputStream 和 BufferedReader & BufferedWrite缓存流读写效率较高,自带缓存区
转换流:
InputStreamReader 和 OutputStreamWrite可以将字符流和字节流进行转换,并且可以设置编码格式,其中InputStreamReader是从字节流到字符流的桥:它读取字节,并使用指定的charset将其解码为字符 。 它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集。
OutputStreamWriter是字符的桥梁流以字节流:向其写入的字符编码成使用指定的字节charset 。 它使用的字符集可以由名称指定,也可以被明确指定,或者可以接受平台的默认字符集。
字符流和字节流的主要区别
1.字节流读取的时候,读到一个字节就返回一个字节;字符流使用了字节流读到一个或多个字节(中文GBK编码对应的字节数是2个,在UTF-8码表中是3个字节)时。先去查指定的编码表,将查到的字符返回。
2.字节流可以处理所有类型数据,如:图片,MP3,AVI视频文件,而字符流只能处理字符数据。只要是处理纯文本数据,就要优先考虑使用字符流,除此之外都用字节流。
3.字节流在操作文件时,即使不关闭资源(close方法),文件也能输出,但是如果字符流不使用close方法的话,则不会输出任何内容,说明字符流用的是缓冲区,并且可以使用flush方法强制进行刷新缓冲区,这时才能在不close的情况下输出内容。flush方法只有Writer类或其子类拥有。
字节流读写方法
读:
read() 从输入流中读取数据一个字节,返回0到255之间的数值,如果没有字节可读,那就返回值为-1。如下:
public static void main(String[] args) {
File file = new File("C:" + File.separator + "test" + File.separator + "text.txt");
try (FileInputStream fis = new FileInputStream(file)){
int read ;
while ((read = fis.read()) != -1){
System.out.print((char)read);
}
} catch (Exception e) {
e.printStackTrace();
}
}
read(byte[] b) 从输入流中读取数据存储到b中,可以给b设置长度,一般1024的倍数,读取数据每次达到b的长度就输出一次,如下:
public static void main(String[] args) {
File file = new File("C:" + File.separator + "test" + File.separator + "text.txt");
try (FileInputStream fis = new FileInputStream(file)){
byte[] b = new byte[1024];
int read ;
while ((read = fis.read(b)) != -1){
String s = new String(b, 0, read);
System.out.print(s);
}
} catch (Exception e) {
e.printStackTrace();
}
}
read(byte[ ] b, int off, int len) 本方法与上面第二个方法类似,一般不使用此方法,参数off表示存储数据时b的起始位置,参数len表示存储的长度。一般off设置为0,len设置为数组b的长度。
注意:如果长度len大于数组存储数据的长度就会报下标越界异常
public static void main(String[] args) {
File file = new File("C:" + File.separator + "test" + File.separator + "text.txt");
try (FileInputStream fis = new FileInputStream(file)){
byte[] b = new byte[1024];
int read ;
while ((read = fis.read(b,1,1023)) != -1){
String s = new String(b, 0, read);
System.out.print(s);
}
} catch (Exception e) {
e.printStackTrace();
}
}
写:
write(byte[ ] b) 将b.length字节从指定的字节数组写入此输出流
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text2.txt");
try (FileInputStream fis = new FileInputStream(file1);
FileOutputStream fos = new FileOutputStream(file2)){
byte[] b = new byte[1024];
while ((fis.read(b,0,1024)) != -1){
//输出流将读到的数据写入到text2文件中
fos.write(b);
}
} catch (Exception e) {
e.printStackTrace();
}
}
write(byte[ ] b, int off, int len)从指定的字节数组写入len字节,从偏移off开始输出到此输出流。 write(b, off, len)的一般合同是数组b中的一些字节按顺序写入输出流; 元素b[off]是写入的第一个字节, b[off+len-1]是此操作写入的最后一个字节。一般off设置为0,len设置为1024的倍数。写入数据速度更快。
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text2.txt");
try (FileInputStream fis = new FileInputStream(file1);
FileOutputStream fos = new FileOutputStream(file2)){
byte[] b = new byte[1024];
while ((fis.read(b,0,1024)) != -1){
fos.write(b,0,1024);
}
} catch (Exception e) {
e.printStackTrace();
}
}
字符流读写方法
其实字符流的读写方法与字节流的读写方法类似
读:
read()读一个字符;
read(char[ ] char)将字符读入数组
read(char[ ] char, int off, int len)将字符读入数组的一部分
写:
write(char[ ] char )写入一个字符数组
write(char[ ] char, int off, int len) 写入字符数组的一部分
write(String str)写一个字符串
write(String str, int off, int len)写一个字符串的一部分
特别注意:使用字符流写入数据的时候必须使用flush刷新流,因为字符流本质是带有缓冲区的字节流,会将数据写入到缓冲区,通过刷新才能将数据写入到目标位置,或者通过关闭流强制将数据写入到目标位置。
//示例一
//注意示例使用字符流读取数据,没有flush,也没有关闭流,所以text3.txt是空的
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text3.txt");
try{
FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2);
char[] chars = new char[1024];
while ((fr.read(chars)) != -1){
fw.write(chars);
}
}catch (Exception e){
e.printStackTrace();
}
}
//示例二
//本示例通过flush将数据刷新输出,但是没有关闭流
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text3.txt");
try{
FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2);
char[] chars = new char[1024];
while ((fr.read(chars)) != -1){
fw.write(chars);
fw.flush();
}
}catch (Exception e){
e.printStackTrace();
}
}
//示例三
//本方法运用了java1.8可以自动关闭流,同事通过flush方法友好的将数据输出到目标位置
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text3.txt");
try(FileReader fr = new FileReader(file1);
FileWriter fw = new FileWriter(file2)){
char[] chars = new char[1024];
while ((fr.read(chars)) != -1){
fw.write(chars);
fw.flush();
}
}catch (Exception e){
e.printStackTrace();
}
}
缓存流添加了读写高效的方法:
缓存流的BufferedReader相比其他输入流添加了一个新的读取方法:readLine() 可以对文本按行进行读取,一行被视为由换行符(’\ n’),回车符(’\ r’)中的任何一个或随后的换行符终止。
缓存流的BufferedWriter相比其他输出流添加了一个新的行分隔符方法:newLine()因为BufferedReader可以按照行进行读取,但是不会读取换行符,那么如果需要输出是按照原文内容进行换行,就需要通过newLine()方法将每一行数据后加一个换行符,而且本换行符会根据系统属性添加不同的换行符标识。例如:
public static void main(String[] args) {
File file1 = new File("C:" + File.separator + "test" + File.separator + "text1.txt");
File file2 = new File("C:" + File.separator + "test" + File.separator + "text3.txt");
try (BufferedReader br = new BufferedReader(new FileReader(file1));
BufferedWriter bw = new BufferedWriter(new FileWriter(file2))
) {
String rs;
while ((rs = br.readLine()) != null){
bw.write(rs);
bw.flush();
bw.newLine();
}
} catch (Exception e) {
e.printStackTrace();
}
}
io异常
io异常是我们在程序中常见的一种异常,在io包下对这些异常进行了介绍,下面学习几种比较常见的异常。
IOException异常
IOException的父类就是Exception,直接子类有很多,其实我们在工作中一般会直接对IOException进行操作,可能抛出,或者捕获。
FileNotFoundException异常
文件找不到异常,一般当指定的文件路径下没有找到要读取的文件就会报此异常
InterruptedIOException异常
表示I / O操作已中断。 抛出一个InterruptedIOException表示输入或输出传输已被终止,因为执行它的线程被中断。