Lucene:查询方式BooleanQuery
1.声明
当前内容主要用于本人学习和复习,当前内容主要使用BooleanQuery方式实现查询
BooleanQuery的查询方式为:
- 创建BooleanQuery.Builder
- 通过and方法实现拼接
- 通过Occur来指定使用
and(MUST)、or(SHOULD)、filter(和and一致)、not(MUST_NOT) - 注意
not语句不能单独使用 - BooleanQuery需要借助
RegexpQuery实现正则查询效果
2.创建工具类LuceneUtils
/**
* @description 转换为Lucene的工具类
* @author hy
* @date 2020-06-08
*/
public class LuceneUtils {
public static List<Document> convertToDocuments(Collection<? extends LuceneAble> list) {
List<Document> documents = new ArrayList<Document>(list.size());
for (LuceneAble t : list) {
Document doc = t.convertToDocument();
documents.add(doc);
}
return documents;
}
public static List<Document> convertToDocuments(Iterable<? extends LuceneAble> entities) {
List<Document> documents = new ArrayList<Document>();
for (LuceneAble luceneAble : entities) {
Document doc = luceneAble.convertToDocument();
documents.add(doc);
}
return documents;
}
public static ArrayList<Document> handlerScoreDocs(ScoreDoc[] scoreDocs, IndexSearcher indexSearcher)
throws IOException {
int[] docIDs = getDocIDs(scoreDocs, indexSearcher);
ArrayList<Document> findDocuments = new ArrayList<Document>(docIDs.length);
for (int i = 0; i < docIDs.length; i++) {
Document document = indexSearcher.doc(docIDs[i]);
findDocuments.add(document);
}
return findDocuments;
}
public static void printDocument(Document doc) {
List<IndexableField> fields = doc.getFields();
for (IndexableField field : fields) {
System.out.println(field.name() + ":" + field.stringValue());
}
}
public static void printDocuments(List<Document> docs) {
for (Document doc : docs) {
printDocument(doc);
System.out.println("=============================");
}
}
public static int[] getDocIDs(ScoreDoc[] scoreDocs, IndexSearcher indexSearcher) {
int[] docIDs = new int[scoreDocs.length];
for (int i = 0; scoreDocs != null && i < scoreDocs.length; i++) {
docIDs[i] = scoreDocs[i].doc;
}
return docIDs;
}
public static void close(Closeable writer) {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static QueryParser createQueryParser(Analyzer analyzer, String findField) throws ParseException {
QueryParser queryParser = new QueryParser(findField, analyzer);
return queryParser;
}
public static Query createEqQuery(Analyzer analyzer, String findField, String findValue) throws ParseException {
QueryParser queryParser = createQueryParser(analyzer, findField);
Query query = queryParser.Query(findValue);
return query;
}
public static Query createEqQuery(String findField, String findValue) throws ParseException {
QueryParser queryParser = createQueryParser(new CJKAnalyzer(), findField);
Query query = queryParser.parse(findValue);
return query;
}
public static Query createRegexQuery(String findField, String findValue, String regex) throws ParseException {
QueryParser queryParser = createQueryParser(new CJKAnalyzer(), findField);
Query query = queryParser.parse(findValue + regex);
return query;
}
public static Query createLikeQuery(String findField, String findValue) throws ParseException {
Query query = createRegexQuery(findField, findValue, "*");
return query;
}
public static Query createBetweenQuery(String findField, String start, String end) throws ParseException {
Query query = createRegexQuery(findField, start, " TO " + end);
return query;
}
// 创建索引写入器
public static IndexWriter createIndexWriter(String indexPath) throws IOException {
Directory dir = FSDirectory.open(Paths.get(indexPath));
IndexWriterConfig conf = new IndexWriterConfig(new CJKAnalyzer());
IndexWriter indexWriter = new IndexWriter(dir, conf);
return indexWriter;
}
// 获取结果
public static ArrayList<Document> findDocumentsByQuery(String indexPath, Query query, int num)
throws IOException, ParseException {
try (Directory dir = FSDirectory.open(Paths.get(indexPath));
DirectoryReader directoryReader = DirectoryReader.open(dir);) {
IndexSearcher indexSearcher = new IndexSearcher(directoryReader);
// 开始查找name中具有张的文档
TopDocs topDocs = indexSearcher.search(query, num);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
// TotalHits totalHits = topDocs.totalHits;
ArrayList<Document> findDocuments = handlerScoreDocs(scoreDocs, indexSearcher);
return findDocuments;
}
}
// 添加单个文档数据
public static long addDocument(String indexPath, LuceneAble doc) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
return indexWriter.addDocument(doc.convertToDocument());
}
}
// 添加多个文档数据
public static long addDocuments(String indexPath, Collection<? extends LuceneAble> documents) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
return indexWriter.addDocuments(convertToDocuments(documents));
}
}
// 使用Term匹配方式删除数据
public static long deleteDocumentByTerms(String indexPath, Term... terms) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
return indexWriter.deleteDocuments(terms);
}
}
// 使用Query方式删除数据
public static long deleteDocumentByQueries(String indexPath, Query... queries) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
return indexWriter.deleteDocuments(queries);
}
}
// 删除所有的数据
public static long deleteAll(String indexPath) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
return indexWriter.deleteAll();
}
}
// 更新使用Term匹配的数据,更新单条数据
public static long updateDocument(String indexPath, Term term, LuceneAble entity) throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
long result = indexWriter.updateDocument(term, entity.convertToDocument());
indexWriter.flush();
return result;
}
}
// 实现批量更新的操作
public static long updateDocuments(String indexPath, Term term, Iterable<? extends LuceneAble> entities)
throws IOException {
try (IndexWriter indexWriter = createIndexWriter(indexPath)) {
List<Document> documents = convertToDocuments(entities);
return indexWriter.updateDocuments(term, documents);
}
}
// 一个查询器
public static QueryBuilder getQueryBuilder() {
return new QueryBuilder();
}
public static class QueryBuilder {
Builder builder;
public QueryBuilder() {
builder = new BooleanQuery.Builder();
}
private QueryBuilder queryChain(Builder builder, Query query, Occur occur) {
builder.add(query, occur);
return this;
}
public QueryBuilder and(Query query) {
queryChain(builder, query, Occur.MUST);
return this;
}
public QueryBuilder filter(Query query) {
queryChain(builder, query, Occur.FILTER);
return this;
}
public QueryBuilder or(Query query) {
queryChain(builder, query, Occur.SHOULD);
return this;
}
public QueryBuilder not(Query query) {
queryChain(builder, query, Occur.MUST_NOT);
return this;
}
public Query build() {
return builder.build();
}
}
}
本人将其封装到工具类中的QueryBuilder中以简化使用方式
3.准备测试数据
static class Score implements LuceneAble {
private String name;
private Double score;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Double getScore() {
return score;
}
public void setScore(Double score) {
this.score = score;
}
@Override
public Document convertToDocument() {
Document doc = new Document();
doc.add(new StringField("score", this.getScore() + "", Store.YES));
doc.add(new StringField("name", this.getName(), Store.YES));
return doc;
}
public Score() {
super();
// TODO Auto-generated constructor stub
}
public Score(String name, Double score) {
super();
this.name = name;
this.score = score;
}
}
public static List<? extends LuceneAble> getDatas() {
List<Score> scores = new ArrayList<NumberTypeTest.Score>();
scores.add(new Score("张三", 1000d));
scores.add(new Score("张三", 900d));
scores.add(new Score("李四", 666d));
scores.add(new Score("王五", 777d));
scores.add(new Score("赵六", 888d));
return scores;
}
public static void initData(String indexPath) throws IOException {
List<? extends LuceneAble> datas = getDatas();
LuceneUtils.addDocuments(indexPath, datas);
}
// filter查询
public static void queryFilter(String indexPath, Term... terms) throws IOException, ParseException {
QueryBuilder builder = LuceneUtils.getQueryBuilder();
for (Term term : terms) {
builder.filter(new TermQuery(term));
}
Query query = builder.build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
// 混合查询
public static void queryMix(String indexPath, Term t1, Term t2) throws IOException, ParseException {
Query query = LuceneUtils.getQueryBuilder().and(new TermQuery(t1)).or(new TermQuery(t2)).build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
// not查询
public static void queryNot(String indexPath, Term t1,Term t2) throws IOException, ParseException {
Query query = LuceneUtils.getQueryBuilder().and(new TermQuery(t1)).not(new TermQuery(t2)).build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
// or查询
public static void queryOr(String indexPath, Term... terms) throws IOException, ParseException {
QueryBuilder builder = LuceneUtils.getQueryBuilder();
for (Term term : terms) {
builder.or(new TermQuery(term));
}
Query query = builder.build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
// and查询
public static void queryAnd(String indexPath, Term... terms) throws IOException, ParseException {
QueryBuilder builder = LuceneUtils.getQueryBuilder();
for (Term term : terms) {
builder.and(new TermQuery(term));
}
Query query = builder.build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
//正则查询
public static void queryRegex(String indexPath, Term term) throws IOException, ParseException {
Query query = LuceneUtils.getQueryBuilder().and(new RegexpQuery(term)).build();
ArrayList<Document> list = LuceneUtils.findDocumentsByQuery(indexPath, query, 50);
LuceneUtils.printDocuments(list);
}
此时调用initData初始化当前的索引库

4.开始测试查询
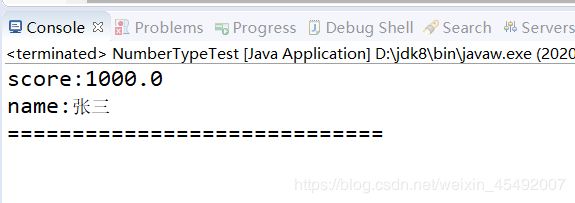
1.and查询
public static void main(String[] args) throws IOException, ParseException {
String indexPath = "D:\\eclipse-workspace\\Lucene-Start\\scoresIndexs";
queryAnd(indexPath, new Term("name", "张三"),new Term("score", "1000.0"));
}
2.or查询
queryOr(indexPath, new Term("name", "张三"), new Term("name", "李四"));
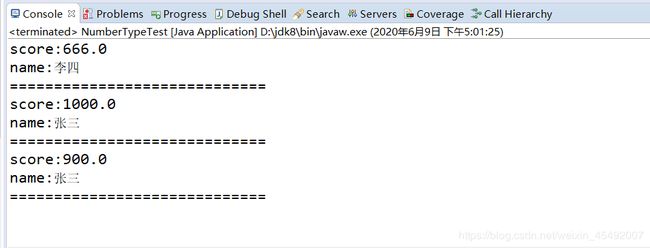
3.混合查询
queryMix(indexPath, new Term("score", "666.0"), new Term("name", "张三"));
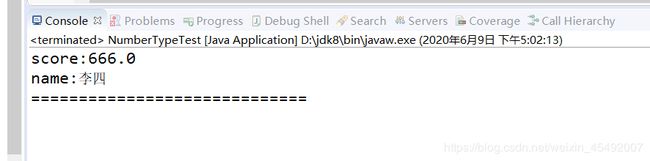
4.not查询
queryNot(indexPath, new Term("name", "张三"), new Term("score", "1000.0"));
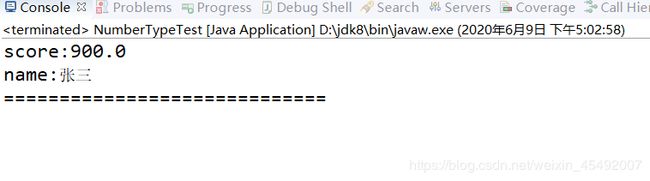
5.filter查询(结果和and查询完全一致)
queryFilter(indexPath, new Term("name", "张三"),new Term("score", "1000.0"));
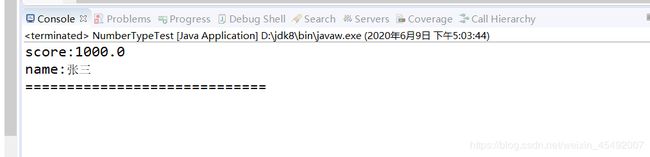
6.正则查询
- 查询所有数据
queryRegex(indexPath, new Term("name", ".*"));

2. 使用正则匹配查询
queryRegex(indexPath, new Term("name", "张.*"));
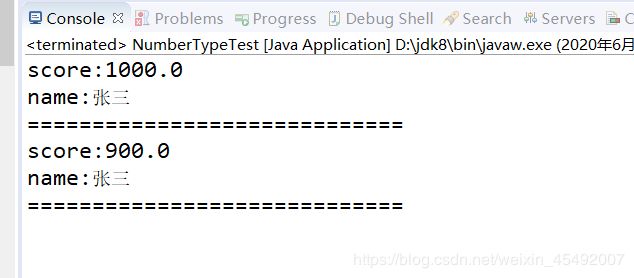
5.总结
1.使用当前的BooleanQuery可以很快实现链式查询,但是也具有一个缺点,使用正则查询需要切换使用RegexpQuery
2.不能单独使用not查询(not查询必须和其他查询一起使用),否则无效
以上纯属个人见解,如有问题请联本人!