Python数据结构速成
数据结构
文章目录
- 数据结构
- 基本数据结构类型
- 栈
- 栈的操作
- 栈的代码实现
- 队列
- 队列的操作
- 队列的代码实现
- 队列的应用
- 热土豆游戏
- 双端队列
- 双端队列的操作
- 双端队列的代码实现
- 双端队列的应用
- “ 回文词” 判定
- 无序列表列表(链表)
- 无序列表列表的操作
- 无序列表(链表)的实现
- 节点
- 无序列表(链表)的代码实现
- 有序列表
- 有序列表的操作
- 关于数字大小有序列表的代码实现
- 递归
- 递归三大定律
- 实例
- 字符串的几个常用切片函数
- 动态规划
- 硬币找零问题
- 背包问题
- 单词最小编辑距离问题
- 搜索
- 顺序搜索
- 二分法搜索
- 散列
- 散列函数
- 排序
- 冒泡排序
- 选择排序
- 插入排序
- 希尔排序
- 归并排序
- 快速排序
- 基数排序
- 总结
- 树
- 节点
- 嵌套列表实现树
- 引用节点实现树
- 实例(解析树)
- 树的遍历
- 树结构的应用
- 二叉堆
- 二叉堆实现
- 堆排序
- 八大排序总结
- 二叉搜索树
- AVL树
- 定义
- 解决不平衡
- 代码实现
- 完整代码
- 查看当前导入模块信息
- 图
- 图的实现
- 邻接矩阵实现图
基本数据结构类型
栈,队列,双端队列,和列表,这四种数据集合的项的由添加或删除的方式整合在一起。当添加一个项目时,它就被放在这样一个位置:在之前存在的项与后来要加入的项之间。像这样的数据集合常被称为线性数据
栈
定义 一个栈(有时称“叠加栈”)是一个项的有序集合。添加项和移除项都发生在同一“端”。这一端通常被称为“顶”。另一端的顶部被称为“底”。特征是后进先出
栈的操作
| Stack() | 创建一个新的空栈。它不需要参数,并返回一个空栈。 |
|---|---|
| Push(item | )将新项添加到堆栈的顶部。它需要参数item 并且没有返回值。 |
| pop() | 从栈顶删除项目。它不需要参数,返回item。栈被修改。 |
| peek() | 返回栈顶的项,不删除它。它不需要参数。堆栈不被修改。 |
| isEmpty() | 测试看栈是否为空。它不需要参数,返回一个布尔值。 |
| size() | 返回栈的项目数。它不需要参数,返回一个整数。 |
栈的代码实现
class Stack:
def __init__(self):
self.item=[];
def Push(self,val):
self.item.append(val)
def pop(self):
try:
return self.item.pop()
except:
return None
def peek(self):
try:
return self.item[-1]
except:
return None
def isEmpty(self):
return len(self.item)==0
def size(self):
return len(self.item)
队列
定义 队列(Queue)是一系列有顺序的元素的集合,新元素的加入在队列的一端,这一端叫做“队尾”(rear),已有元素的移除发生在队列的另一端,叫做“队首”(front),特点是先进先出
队列的操作
| Queue() | 创建一个空队列对象,无需参数,返回空的队列; |
|---|---|
| enqueue(item) | 将数据项添加到队尾,无返回值; |
| dequeue() | 从队首移除数据项,无需参数,返回值为队首数据项; |
| isEmpty() | 测试是否为空队列,无需参数,返回值为布尔值; |
| size() | 返回队列中的数据项的个数,无需参数。 |
队列的代码实现
class Queue:
def __init__(self):
self.item = []
def enqueue(self,val):
self.item.insert(0,val)
def dequeue(self):
return self.pop()
def isEmpty(self):
return len(self.item)==0
def size(self):
return len(self.item)
队列的应用
热土豆游戏
在这个游戏中小孩子们围成一个圆圈并以最快的速度接连传递物品,并在游戏的一个特定时刻停止传递,这时手中拿着物品的小孩就离开圆圈,游戏进行至只剩下一个小孩。
问题分析 这个游戏涉及以下几个问题:1.如何模拟圆圈;2.如何模拟时间走动
对于问题1 我们使用队列对圆圈进行模拟,圆圈并不是本质的,而是在时间走动时,可以出现一种循环,我们可以通过不断的进站出站来实现这个过程
from pythonds.basic.queue import Queue #引用pythonds中已经写好的队列类
from random import randint
def hotpotato(namelist):#热土豆游戏
simqueue = Queue()
for name in namelist:
simqueue.enqueue(name)#所有的成员进入队列
m = 1
while simqueue.size()>1:#开始游戏
number = randint(1, simqueue.size());#随机决定停止的位置
for i in range(number):
simqueue.enqueue(simqueue.dequeue())#从队首出,队尾进
print('第%s轮淘汰的是%s'%(m,simqueue.dequeue()))#时间到,队首人员淘汰
m = m+1
else:
print('最后的胜利者是%s'%simqueue.dequeue())
namelist=('军哥','GP','老权','爸爸我','希特勒','蔡徐坤','李云龙','周杰伦')
hotpotato(namelist)
运行得到:
第1轮淘汰的是GP
第2轮淘汰的是周杰伦
第3轮淘汰的是老权
第4轮淘汰的是李云龙
第5轮淘汰的是爸爸我
第6轮淘汰的是蔡徐坤
第7轮淘汰的是希特勒
最后的胜利者是军哥
双端队列
双端队列(deque 或 double-ended queue)与队列类似,也是一系列元素的有序组合。其两端称为队首(front)和队尾(rear)特点是元素可以从两端插入,也可以从两端删,拥有栈和队列各自拥有的所有功能
双端队列的操作
| Deque() | 创建一个空双端队列,无参数,返回值为 Deque 对象。 |
|---|---|
| addFront(item) | 在队首插入一个元素,参数为待插入元素,无返回值。 |
| addRear(item) | 在队尾插入一个元素,参数为待插入元素,无返回值 |
| removeFront() | 在队首移除一个元素,无参数,返回值为该元素。双端队列 |
| removeRear() | 在队尾移除一个元素,无参数,返回值为该元素。双端队列会 |
| isEmpty() | 判断双端队列是否为空,无参数,返回布尔值。 |
| size() | 返回双端队列中数据项的个数,无参数,返回值为整型数值。 |
双端队列的代码实现
class Deque:
def __init__(self):
self.item=[]
def addRear(self,item):
self.item.insert(0,item)
def addFront(self,item):
self.item.append(item)
def removeFront(self):
if self.item:
return self.item.pop()
else:
return print('The deque is empty')
def removeRear(self):
if self.item:
return self.item.pop(0)
else:
return print('The deque is empty')
def isEmpty(self):
return self.item==[]
def size(self):
return len(self.item)
双端队列的应用
“ 回文词” 判定
回文词指的是正读和反读都一样的词,如:radar、toot 和madam。我们想要编写一个算法来检查放入的字符串是否为回文词。
**思路分析:**我们在栈的介绍时,提到过栈可以用来反转顺序,而双端队列,具有‘顺序’,‘逆序’两种性质,所以我们可以通过队列来实现回文词的判断
代码实现
def palchecker(aString):
d=Deque()
for i in aString:#使词进队
d.addRear(i)
while d.size()>1:#进行判断
if d.removeFront()==d.removeRear():
pass
else:
return False
else:
return True
**评:**上述代码虽然可以实现,但是最好时在判断的过程中加入标记,使得代码有更好的维护性
def palchecker(aString):
d=Deque()
for i in aString:#使词进队
d.addRear(i)
stillEqual = True
while d.size()>1:#进行判断
if d.removeFront()==d.removeRear():
pass
else:
stillEqual = False
return stillEqual
无序列表列表(链表)
无序列表结构是一个由各个元素组成的集合,在其中的每个元素拥有一个不同于其它元素的相对位置,无序列表,其实仍有序,只不过是成为了相对序,举例来说,电影院里坐着一排人,你可以说,”喂,快看1排 6号的迪丽热巴!“,但是如果走在街上的话,比较合适的描述是”喂,快看前面黄毛古惑仔,旁边的如花!”
无序列表列表的操作
| list() | 创建一个新的空列表。它不需要参数,而返回一个空列表。 |
|---|---|
| add(item) | 将新项添加到列表,没有返回值。假设元素不在列表中。 |
| remove(item) | 从列表中删除元素。需要一个参数,并会修改列表。此处假设元素在列表中。 |
| search(item) | 搜索列表中的元素。需要一个参数,并返回一个布尔值。 |
| isEmpty() | 判断列表是否为空。不需要参数,并返回一个布尔值。 |
| size() | 返回列表的元素数。不需要参数,并返回一个整数。 |
| append(item) | 在列表末端添加一个新的元素。它需要一个参数,没有返回值 |
| index(item) | 此处假设该元素原本在列表中, 返回元素在列表中的位置。它需要一个参数,并返回位置索引值。 |
| insert(pos,item) | 在指定的位置添加一个新元素。它需要两个参数,没有返回值 |
| pop() | 从列表末端移除一个元素并返回它。它不需要参数,返回一个元素。 |
| pop(pos) | 从指定的位置移除列表元素并返回它。它需要一个位置参数,并返回值 |
无序列表(链表)的实现
为了实现无序列表,我们将构建一个链表,每个项目的相对位置就可以通过以下简单的链接从一个项目到下一个来确定,链表实现的基本模块是节点
节点
节点必须包含列表元素本身。我们将这称为该节点的“数据区”(data field)。此外,每个节点必须保持到下一个节点的引用
节点代码实现
class Node:
def __init__(self,initdate):
self.data=initdate
self.next=None
def getData(self):
return self.data
def getNext(self):
return self.next
def setData(self,newdata):
self.data=newdata
def setNext(self,newnext):
self.Next=newnext
无序列表(链表)的代码实现
无序列表将由一个节点集合组
只要我们知道第一个节点的位置(包含第一项),在这之后的每个元素都可以通过以下链
接找到下一个节点。为实现这个想法,UnorderedList 类必须保持一个对第一节点的引用
节点就像一个机器人有两个机械臂,左臂小,右臂大,大到和机器人的身体一样大,链表就相当于一系列机器人,这些机器人左手拿着val,右手要么空着,要么抓着另一个机器人

class UnorderedList:
def __init__(self):
self.head = None
def add(self,item):
temp=Node(item)
temp.setNext(self.head)
self.head=temp
def append(self,item):
last=self.head
while last.getNext()!=None:
last=last.getNext()
temp=Node(item)
last.setNext(temp)
def isEmpty(self):
return self.head==None
def size(self):
current=self.head
count = 0
while current!=None:
count =count+1
current=current.getNext()
return count
def search(self,item):
current=self.head
found=False
while current!=None and not found:
if current.getData()==item:
found=True
else:
current=current.getNext()
return found
def search_pos(self,item):
current=self.head
previous=None
found=False
while current!=None and not found:
if current.getData()==item:
found=True
else:
previous=current
current=current.getNext()
return current
def remove(self,item):
current=self.head
previous=None
found=False
while not found:
if current.getData()==item:
found = True
else:
previous=current
current=current.getNext()
if previous==None:#如果找到的节点在第一项
self.head=current.getNext()
else:
previous.setNext(current.getNext())
def index(self,item):
previous=None
current=self.head
while current!=None and current.getData()!=item:
previous=current
current=current.getNext()
print("The last item of %s is %s"%(str(item),str(previous.getData())))
def insert(self,pos,item):
temp_0=self.search_pos(pos)
temp_1=Node(item)
temp_1.setNext(temp_0.getNext())
temp_0.setNext(temp_1)
def pop(self,pos=None):
current=self.head
previous=None
if pos==None:
while current.getNext()!=None:
previous=current
current=current.getNext()
if previous==None:
self.head=None
else:
previous.setNext(None)
return current.getData()
else:
self.remove(pos)
return pos
有序列表
有序列表的结构是一个数据的集合体,在集合体中,每个元素相对其他元素有一个基于元素的
某些基本性质的位置,举例来说,一个班级排队,一开始大家都是随便排,只产生一种相对位置,比如说小花后面是狗蛋,此时队伍就是一个无序列表;如果此时老师要求按身高进行排队,就产生了一种关于属性的位置,此时我们就说队伍是一个有序列
有序列表的操作
| OrderedList() | 创建一个新的空有序列表。它返回一个空有序列表并且不需要传递任何参数。 |
|---|---|
| add(item) | 在保持原有顺序的情况下向列表中添加一个新的元素,新的元素作为参数传递进函数无返回值 |
| remove(item) | 从列表中删除某个元素。欲删除的元素作为参数,并且会修改原列表 |
| search(item) | 在列表中搜索某个元素,被搜索元素作为参数,返回一个布尔值。 |
| isEmpty() | 测试列表是否为空,不需要输入参数并且其返回一个布尔值。 |
| size(): | 返回列表中元素的数量。不需要参数,返回一个整数。 |
| index(item) | 返回元素在列表中的位置。需要被搜索的元素作为参数输入,返回此元素的索引 |
| pop() | 删除并返回列表中的最后一项。不需要参数,返回删除的元素。假设列表中至少有一个 |
| pop(pos) | 删除并返回索引pos 指定项。需要被删除元素的索引值作为参数,并且返回这个元素 |
关于数字大小有序列表的代码实现
在有序列表中除了add,search外,其他所有函数的实现都和无序列表相同
class OrderedList:
def __init__(self):
self.head = None
def add(self,item):
current=self.head
previous=None
stop=False
while current!=None and not stop:
if current.getData()>item:
stop=True
else:
previous=current
current=current.getNext()
temp=Node(item)
if previous==None:
temp.setNext(self.head)
self.head=temp
else:
temp.setNext(current)
previous.setNext(temp)
def search(self,item):
current=self.head
found=False
stop=False
while current!=None and not found and not stop:
if current.getData()==item:
found=True
else:
if current.getData()>item:
stop=True
else:
current=current.getNext()
return found
def print(self):
current=self.head
s=[]
if current==None:
return None
else:
while current!=None:
s.append(current.getData())
current=current.getNext()
return s
实例
w=OrderedList()
w.add(1)
w.add(19)
w.add(20)
w.add(17)
w.print()
运行得到:
[1, 17, 19, 20]
递归
定义 递归是一种解决问题的方法,它把一个问题分解为越来越小的子问题,直到问题的规模小到
可以被很简单直接解决
通常为了达到分解问题的效果,递归过程中要引入一个调用自身的函数
递归三大定律
● 递归算法必须有个基本结束条件
● 递归算法必须改变自己的状态并向基本结束条件演进
● 递归算法必须递归地调用自身
实例
对列表中的元素做加法
def list_sum(num_list):
if len(num_list) == 1:
return num_list[0]#1.结束条件
else:
return num_list[0] + list_sum(num_list[1:])#3.调用自身并2.向基本结束条件演进
print(list_sum([1,3,5,7,9]))
计算一个整数的阶乘
def fact(n:int):
if n>0:#结束条件
return n*fact(n-1) #调用自身,并向基本结束条件演进
else:
return 1
整数转化成任意进制表示的字符串形式
def to_str(n,base=17):
convert_string="0123456789ABCDEFG"
if n<base:#结束条件
return convert_string[n]
else:
return to_str(n//base,base)+convert_string[n%base] #调用自身,并向基本结束条件演进
反转字符串
def reverse(Str):
if len(Str)>1:#结束条件
return Str[-1]+reverse(Str[:-1]) #调用自身,并向基本结束条件演进
else:
return Str[0]
判断回文词
这一题目我们曾在双端队列中做过
def judge_rev(Str):
judge=False
if len(Str)>1:#结束条件
if Str[0]==Str[-1]:
return judge_rev(Str[1:-1])#调用自身,并向基本结束条件演进
else:
return judge
else:
judge=True
return judge
**注意:**在调用函数本身后,最外层的数据一定要对调用结果有引用,否则容易出错
判断句子是否是构成回文词
一些优秀的回文也可以是短语,但是你需要在验证前删除空格和标点符号。例如:madam i’m adam 是个回文
def clearingstr(Str):
Str=Str.lower()#将字母都换为小写
if len(Str)>1:#结束条件
if not Str[0].isalpha() and not Str[0].isdigit():
Str=Str[1:]
return clearingstr(Str) #调用自身,并向基本结束条件演进
else:
return Str[0]+clearingstr(Str[1:])#调用自身,并向基本结束条件演进
else:
if not Str[0].isalpha() and not Str[0].isdigit():
return ''
else:
return Str
字符串的几个常用切片函数
| 函数名 | 语法 | 返回值 |
|---|---|---|
| strip() | str.strip([chars]); | 返回移除字符串头尾指定的字符生成的新字符串。 |
| replace() | str.replace(old, new[, max])#old – 将被替换的子字符串; new – 新字符串,用于替换old子字符串; max – 可选字符串, 替换不超过 max 次 | 替换后的新字符串 |
| split() | str.split(str="", num=string.count(str))#str–分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。num–分割次数。默认为 -1, 即分隔所有。 | 返回分割后的字符串列表 |
河内塔问题(难)
河内塔问题是法国数学家爱德华·卢卡斯于1883年发现的。他受到一个关于印度教寺庙的传说
的启发,故事中这一问题交由年轻僧侣们解决。最开始,僧侣们得到三根杆子,64个金圆盘堆叠在其中一根上, 每个圆盘比其下的小一点。僧侣们的任务是将64个圆盘从一根杆上转移到另一根杆上,但有两项重要的限制,一是他们一次只能移动一个圆盘,一是不能将大圆盘放在小圆盘之上。
我们接下来用代码来实现整个过程

分析: 开始时,所有的盘子都在fromPole上,我们要将所有的盘子移动到toPole上;不妨假设只有三个我们来观察整个过程,记三个盘子分别为1、2、3,柱子分别记为A,B,C
假设我们知道如何1,2 : A → B A\rightarrow B A→B ,那么我们只需要3: A → C A\rightarrow C A→C ,然后利用1,2 : A → B A\rightarrow B A→B 的方法,进行1,2: B → C B\rightarrow C B→C
即可,但是!如果你不知道如何1,2 : A → B , 那 么 你 只 需 要 知 道 如 何 1 : A → C A\rightarrow B ,那么你只需要知道如何1:A \rightarrow C A→B,那么你只需要知道如何1:A→C , 利用同样的方法就可以使得
2: A → B A\rightarrow B A→B ,然后1: C → B C\rightarrow B C→B 即可(ps:这种思想才是递归法的精华所在,我们不是简单的找规律,而是不断的减小问题的规模)
def moveTower(height,fromPole, toPole, withPole):
if height >= 1:
moveTower(height-1,fromPole,withPole,toPole)
moveDisk(fromPole,toPole)
moveTower(height-1,withPole,toPole,fromPole)
def moveDisk(fp,tp):
print("moving disk from",fp,"to",tp)
动态规划
动态规划算法的基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
硬币找零问题
对于任意给出的金额,要求用最少的硬币来找零。
我们已经学过递归算法,下面我们先用递归算法来解决
分析:假设一个顾客投了1美元来购买37美分的物品。你用来找零的硬币的最小数量是多少?答案是六枚硬币:两个25 美分,一个10美分,三个1美分。我们是怎么得到六个硬币这个答案的呢?首先我们要使用面值中最大的硬币(25美分),并且尽可能多的使用它,接着我们再使用下一个可使用的最大面值的硬币,也是尽可能多的使用。这种方法被称为贪心算法,因为我们试图尽可能快的解。( 这里提一个小问题:为什么最新版人民币的币值,只有那几种?)
def recMC(coinlist,money):
coins=0
if money in coinlist:#结束条件
coins=coins+1
return coins
else:
s=[c for c in coinlist if c<=money]
m=max(s)
last=recMC(coinlist,money-m)#调用自身,并向基本结束条件演进
coins=1+last
return coins
但是贪心算法并不是总能给出最优解,如何coinlist=[1,5,10,21,25];money=63;贪心算法会直接选择25作为第一次的找零对象
为此我们需要改进自己的算法
类似是我们在河内塔问题的分析,我们做如下的分析:
假设我们的coinlist=[1,5,10,21,25],money=N,假设我们已经知道了N-1,N-5,N-10,N-21,N-25的最少找零方法,那么我们只需要选择上述N-i(i in coinlist)最少的一个就好,但是如果我们不知道N-1的找零方法,但是我们知道N-1-1,N-1-5,N-1-10,N-1-21,N-1-25的方法的话,同样只要需从中选择最小的一个然后加一就好…
def recMC(coinlist,money):
coins=money
if money in coinlist:#结束条件
coins=coins+1
return coins
else:
last=money
for i in [c for c in coinlist if c<=money]:
last=1+recMC(coinlist,money-i)#调用自身,并向结束条件演进
if last<coins:#进行比较选择最小的方案
coins=last
return coins
上述算法虽然可以实现找零,但是效率太低了,距离来说coinlist=[1,5,10,21,25] ,money=12,上述算法会分析出11,7,2的找零方法,而为了得到7的找零方法,我们又需要得治2,6的找零方法,可是我们不是已经知道2的找零方法了吗??我们曾经在画一个分形树的例子中提到过,递归一旦开始,只能到一口气到结束条件,也就使得我们在分析7的找零方法时,2的找零方法还是要分析一次
减少我们的工作量的关键在于记住一些出现过的结果,这样就能避免重复计算我们已经知道的结果
def recDC(coinValueList,change,knownResults):
minCoins = change
if change in coinValueList:#结束条件
knownResults[change] = 1
return 1
elif knownResults[change] > 0:#结束条件
return knownResults[change]
else:
for i in [c for c in coinValueList if c <= change]:
numCoins = 1 + recDC(coinValueList, change-i, knownResults)#调用自身并向结束条件演进
if numCoins < minCoins:
minCoins = numCoins
knownResults[change] = minCoins#更新记录
return minCoins
print(recDC([1,5,10,25],63,[0]*64))
注: 一定程度上,递归法的思想十分类似于归纳法的想法,比如上述硬币找零的思想就很类似于第二归纳法.
事实上,我们目前所采用的方法还不是动态规划,我们只是使用了一种叫做**“函数值缓存”**,或者一般称为“缓存”的方法改善了程序的性能。
动态规划的解决方法是从为1分钱找零的最优解开始,逐步递加上去,直到我们需要的找零钱数
这就保证了在算法的每一步过程中,我们已经知道了兑换任何更小数值的零钱时所需的硬币数量的最小值
def dpMakeChange(coinValueList,change,minCoins,coinsUsed):
for cents in range(change+1):
coinCount = cents
newCoin = 1
for j in [c for c in coinValueList if c <= cents]:#计算从1到change逐一增加的找零钱数
if minCoins[cents-j] + 1 < coinCount:
coinCount = minCoins[cents-j]+1
newCoin = j#记录使用的钱币
minCoins[cents] = coinCount
coinsUsed[cents] = newCoin
return minCoins[change]
def printCoins(coinsUsed,change):
coin = change
while coin > 0:
thisCoin = coinsUsed[coin]
print(thisCoin)
coin = coin - thisCoin
def main():
amnt = 63
clist = [1,5,10,21,25]
coinsUsed = [0]*(amnt+1)
coinCount = [0]*(amnt+1)
print("Making change for",amnt,"requires")
print(dpMakeChange(clist,amnt,coinCount,coinsUsed),"coins")
print("They are:")
printCoins(coinsUsed,amnt)
print("The used list is as follows:")
print(coinsUsed)
main()
**评:**提一个简单的问题:为什么这里我们没有使用递归?如果使用的递归从1到change 逐一的寻找最优解,我们将每次都把小于cents的最佳解,重新求解一遍,而这正是动态规划的优势所在。
背包问题
假设你是一个计算机科学家或是一个艺术小偷,闯入了一个艺术画廊。你身上只有一个背
包可以用来偷出宝物,这个背包只能装W英镑的艺术品,但你知道每一件艺术品的价值和它的重
量。运用动态规划写一个函数,来帮助你获得最多价值的宝物。你可以利用下面的例子来编写程
序:假设你的背包可以容纳的总重量为20,你有如下5件宝物:
| item | weight | value |
|---|---|---|
| 1 | 2 | 3 |
| 2 | 3 | 4 |
| 3 | 4 | 8 |
| 4 | 5 | 8 |
| 5 | 9 | 10 |
贪心算法:每次只拿最有价值的宝物,一直到背包放不下为止
def Artsteal(artlist,bag):
s=[c for c in artlist if c[1]<=bag]
value=0
if s !=[]:
w=(0,0,0)
for i in s:
if w[2]<=i[2]:
w=i
value=w[2]
print(w)
value=value+Artsteal(artlist,bag-w[1])
return value
else:
return value
artlist=[(1,2,3),(2,3,4),(3,4,8),(4,5,8),(5,9,10)]
print(Artsteal(artlist,20))
运行得到:
(5, 9, 10)
(5, 9, 10)
(1, 2, 3)
23
动态规划:从背包容纳重量为1开始求最优解,一直找到bag重
def Artsteal(artlist,maxres,steallist,bag):
for w in range(bag+1):
s=[c for c in artlist if c[1]<=w]
value=0
use=0
if s !=[]:
for j in s:
if maxres[w-j[1]]+j[2]>value:
value=maxres[w-j[1]]+j[2]
use=j
maxres[w]=value
steallist[w]=use
return maxres[bag]
def stealed(steallist,bag):
s=bag
while s>1:
stealed=steallist[s]
print(stealed)
s=s-stealed[1]
def main():
bag=20
artlist=[(1,2,3),(2,3,4),(3,4,8),(4,5,8),(5,9,10)]
maxres=[0]*(bag+1)
steallist=[(0,0,0)]*(bag+1)
print(Artsteal(artlist,maxres,steallist,bag))
stealed(steallist,bag)
main()
运行得到:
40
(3, 4, 8)
(3, 4, 8)
(3, 4, 8)
(3, 4, 8)
(3, 4, 8)
单词最小编辑距离问题
给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
插入一个字符
删除一个字符
替换一个字符
def minDistance( word1, word2):
n = len(word1)
m = len(word2)
# if one of the strings is empty
if n * m == 0:
return n + m
# array to store the convertion history
d = [ [0] * (m + 1) for _ in range(n + 1)]
# init boundaries
for i in range(n + 1):
d[i][0] = i
for j in range(m + 1):
d[0][j] = j
# DP compute
for i in range(1, n + 1):
for j in range(1, m + 1):
left = d[i - 1][j] + 1
down = d[i][j - 1] + 1
left_down = d[i - 1][j - 1]
if word1[i - 1] != word2[j - 1]:
left_down += 1
d[i][j] = min(left, down, left_down)
return d[n][m]
**评:**这次动态规划,我们从1维到1维,改为了2维的规划,通过观察注意到当我们获得 D[i-1][j],D[i][j-1] 和 D[i-1][j-1] 的值之后就可以计算出 D[i][j]。
如果两个子串的最后一个字母相同,word1[i] = word2[i] 的情况下:
D [ i ] [ j ] = 1 + m i n ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] − 1 ) D [ i ] [ j ] = 1 + min ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] − 1 ) D [ i ] [ j ] = 1 + m i n ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] − 1 ) D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]−1)\\ D[i][j] = 1 + \min(D[i - 1][j], D[i][j - 1], D[i - 1][j - 1] - 1)\\ D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]−1) D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]−1)D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]−1)D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]−1)
否则,word1[i] != word2[j] 我们将考虑替换最后一个字符使得他们相同:
D [ i ] [ j ] = 1 + m i n ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] ) D [ i ] [ j ] = 1 + min ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] ) D [ i ] [ j ] = 1 + m i n ( D [ i − 1 ] [ j ] , D [ i ] [ j − 1 ] , D [ i − 1 ] [ j − 1 ] ) D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1])\\ D[i][j] = 1 + \min(D[i - 1][j], D[i][j - 1], D[i - 1][j - 1])\\ D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1]) D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1])D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1])D[i][j]=1+min(D[i−1][j],D[i][j−1],D[i−1][j−1])
否则,word1[i] != word2[j] 我们将考虑替换最后一个字符使得他们相同:
总结:动态规划和递归不同,递归是先解决n的情况,再解决n-1的情况,而动态规划刚好相反,先解决n-1的情况,再解决n的情况。
搜索
搜索的算法过程就是在一些项集合中找到一个特定的项。搜索过程通常会根据特定项是否存在来给出回答True或者False。
顺序搜索
在Python列表,这些相对位置所对应的是单个项的索引值。由于这些索引值是有一定次序的,可以依次访问它们。,
def sequentialSearch(alist, item):
pos = 0#位置从0开始
found = False#记录是否找到
while pos < len(alist) and not found:
if alist[pos] == item:
found = True
else:
pos = pos + 1
return found
testlist = [1, 2, 32, 8, 17, 19, 42, 13, 0]
print(sequentialSearch(testlist, 3))
print(sequentialSearch(testlist, 13))
我们寻找的目标项可能在任意位置,对列表的每一个位置,我们找到它的概率是相等的,从而顺序搜索的复杂度是O(n) .
二分法搜索
假设在一组有序的元素中进行搜索,二分搜索将从中间项开始检测
def binarySearch(alist,item):
pos=0;
found=False
last=len(alist)-1#元素的位置从0开始计算
while pos<=last and not found:
mid=(pos+last)//2#找到中间位置
if alist[mid]==item:#比较中间位置与item
found=True
return found
else:
if item<alist[mid]:
last=mid-1
else:
pos=mid-1
return found
在二分法搜索中我们最多分割 n 2 i \frac{n}{2^i} 2in 次,其中 i : 2 i ≤ n < 2 i + 1 i:2^i\le n<2^{i+1} i:2i≤n<2i+1 ,也就是说我们差不多最多对比i次,解出来后 i = log ( n ) i=\log(n) i=log(n) ,从而二分搜索的复杂度是O(log(n)) .
在顺序搜索和二分搜索中我们用来搜索的对象都是具有相对位置的集合,也就是有序列表,但是面对毫无顺序的“散列”,我们又该如何搜索呢?或者说我们又应该如何使其变得有序呢?
散列
散列表也叫哈希表是一种数据的集合,其中的每个数据都通过某种特定的方式进行存储以方面日后的查找(也就是说对于本来无序的数据,通过某种映射使其变得有序)。散列表的每一个位置叫做槽 ,槽能够存放一个数据项,并以从0开始递增的整数命名。例如,第一个槽记为0,下一个记为1,再下一个记为2,并以此类推。
某个数据项与在散列表中存储它的槽之间的映射叫做 散列函数。
散列函数
如果一个散列函数可以将每一个数据项都映射到不同的槽中,那么这样的散列函数叫做 完美散列函数。
我们的目标是创建一个能够将冲突的数量降到最小,计算方便,并且最终将数据项分配到散列表中的散列函数
常用的方法有:
| 散列函数 | 详细说明 |
|---|---|
| 直接定址法 | 直接定址法是以关键字K本身或关键字加上某个数值常量C作为散列地址的方法。对应的散列函数h(K)为: h(K)=K+C 若C为O,则散列地址就是关键字本身。这种方法计算最简单,并且没有冲突发生,若有冲突发生,则表明是关键字错误。它适应于关键字的分布基本连续的情况,若关键字分布不连续,空号较多,将造成存储空间的浪费。 |
| 除留余数法 | 除留余数法是用关键字K除以散列表长度m所得余数作为散列地址的方法。对应的散列函数h(K)为:h(K)=k%m |
| 数字分析法 | 数字分析法是取关键字中某些取值较分散的数字位作为散列地址的方法。它适合于所有关键字已知,并对关键字中每一位的取值分布情况作出了分析。例如,有一组关键字为(92317602,92326875,92739628,92343634,92706816,92774638,92381262, 92394220),通过分析可知,每个关键字从左到右的第1,2,3位和第6位取值较集中,不宜作散列地址。剩余的第4,5,7和8位取值较分散,可根据实际需要取其中的若干位作为散列地址。若取最后两位作为散列地址,则散列地址的集合为(2,75,28,34,16,38,62,20)。 |
| 平方取中法 | 平方取中法是取关键字平方的中间几位作为散列地址的方法,具体取多少位视实际要求而定。一个数平方后的中间几位和数的每一位都有关。从而可知,由平方取中法得到的散列地址同关键字的每一位都有关,使得散列地址具有较好的分散性。平方取中法适应于关键字中的每一位取值都不够分散或者较分散的位数小于散列地址所需要的位数的情况。 |
| 折叠法 | 折叠法是首先将关键字分割成位数相同的几段(最后一段的位数若不足应补0),段的位数取决于散列地址的位数,由实际需要而定,然后将它们的叠加和(舍去最高位进位)作为散列地址的方法。例如一个关键字K=68242324,散列地址为3位,则将此关键字从左到右每三位一段进行划分,得到的三段为682,423和240,叠加和为682+423+240=345,此值就是存储关键字为68242324元素的散列地址。折叠法适应于关键字的位数较多,而所需的散列地址的位数又较少,同时关键字中每一位的取值又较集中的情况。 |
散列函数在运作时,常常并不是完美的,也就是会出现冲突的情况,对于冲突的情况,这里不在做详解,有兴趣的小伙伴可以自行搜索。
排序
冒泡排序
冒泡排序要对一个列表多次重复遍历项,并且交换顺序排错的项。每对列表实行一次遍历,就有一个最大项排在了正确的位置。(毫无疑问,通过每次的两两对比,每一次遍历都将会把最大值找到正确位置)
**由于每一次遍历都会使下一个最大项归位,所需要遍历的总次数就是n-1 **
def bubbleSort(alist):
for passnum in range(len(alist)-1,0,-1):
for i in range(passnum):
if alist[i]>alist[i+1]:
alist[i],alist[i+1] = alist[i+1],alist[i]
alist = [54,26,93,17,77,31,44,55,20]
bubbleSort(alist)
print(alist)
评:一般的编程语言,在交换两项的顺序时,都需要第三项来做临时的存储器,但是Python可以进行同时赋值。
容易得知,冒泡排序的复杂度是 O ( n 2 ) O(n^2) O(n2)
选择排序
选择排序提高了冒泡排序的性能,它每遍历一次列表只交换一次数据,即进行一次遍历时找到最大的项
def Selectsort(alist):
l=len(alist)
for i in range(l):#遍历次数
pos=l-i-1
maxpos=0
for j in range(pos+1):#找出最大项
if alist[maxpos]<=alist[j]:
maxpos=j
alist[pos],alist[maxpos]=alist[maxpos],alist[pos]#把最大项放到最后
return print(alist)
显然,选择排序和冒泡排序有相同的复杂度是 O ( n 2 ) O(n^2) O(n2)
插入排序
保持一个位置靠前的已排好的子表,然后每一个新的数据项被“插入”到前边的子表里,排好的子表增加一项
其实就是利用双边队列的一个想法,假定第一个数已经排好位置,那么对于下一个数,只要确定它在排好的位置的数的左边还是右边就可以了
def InsertionSort(alist):
l=len(alist)
for i in range(1,l):
insvalue=alist[i];#记录比较的值
pos=i#记录被计较位置
while pos>0 and insvalue<alist[pos-1]:
alist[pos],alist[pos-1]=alist[pos-1],alist[pos]
pos=pos-1
插入排序和冒泡排序非常的类似,都是左右两两比较后交换位置,但是和冒泡排序每次遍历数据的个数刚好相反,举例来说,插入排序最初只比较一次,而冒牌排序最后遍历时只比较一次,两者互为镜像
显然,插入排序的复杂度也是 O ( n 2 ) O(n^2) O(n2)
希尔排序
希尔排序有时又叫做“缩小间隔排序”,它以插入排序为基础,将原来要排序的列表划分为一些子列表,再对每一个子列表执行插入排序,从而实现对插入排序性能的改进。具体举例来说:我们有一个含九个元素的列表。如果我们以3为间隔来划分,就会分为三个子列表,每一个可以执行插入排序。
def gapinsertionsort(alist,star=0,gap=1):#对列表进行排序且不改变其他元素的位置
for i in range(star+gap,len(alist),gap):
insvalue=alist[i];
pos=i
while pos>star and insvalue<alist[pos-1]:
alist[pos],alist[pos-gap]=alist[pos-gap],alist[pos]
pos=pos-gap
def shellsort(alist):
gap=len(alist)//3
for star in range(gap):#对子列表进行插入排序
gapinsertionsort(alist,star,gap)
gapinsertionsort(alist)#最后进行总的处理
return alist
评:冒泡排序和插入排序都是最基础的排序方法,希尔排序的想法更像是先粗加工,最后精加工
归并排序
上面的几种排序方法,都暗含一种假设我们有n个数字,已经排好了n-1个,那么我们自然可以正确的找到第n个数的位置。特别是排序是每次遍历都需要重新进行小规模或者全体的比较,我们很自然的想法用递归去处理。
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:#结束条件
mid = len(alist)//2
lefthalf = alist[:mid]
righthalf = alist[mid:]
mergeSort(lefthalf)#调用自身并向结束条件演进
mergeSort(righthalf)#调用自身并向结束条件演进
i=0
j=0
k=0
while i < len(lefthalf) and j < len(righthalf):#每次只记录最小的数
if lefthalf[i] < righthalf[j]:
alist[k]=lefthalf[i]
i=i+1
else:
alist[k]=righthalf[j]
j=j+1
k=k+1
while i < len(lefthalf):#防止左右子列所含的个数不相等的情况
alist[k]=lefthalf[i]
i=i+1
k=k+1
while j < len(righthalf):
alist[k]=righthalf[j]
j=j+1
k=k+1
print("Merging ",alist)
alist = [9,8,7,6,5,4,3,2,1]
mergeSort(alist)
print(alist)
运行得到:
plitting [9, 8, 7, 6, 5, 4, 3, 2, 1]
Splitting [9, 8, 7, 6]
Splitting [9, 8]
Splitting [9]
Merging [9]
Splitting [8]
Merging [8]
Merging [8, 9]
Splitting [7, 6]
Splitting [7]
Merging [7]
Splitting [6]
Merging [6]
Merging [6, 7]
Merging [6, 7, 8, 9]
Splitting [5, 4, 3, 2, 1]
Splitting [5, 4]
Splitting [5]
Merging [5]
Splitting [4]
Merging [4]
Merging [4, 5]
Splitting [3, 2, 1]
Splitting [3]
Merging [3]
Splitting [2, 1]
Splitting [2]
Merging [2]
Splitting [1]
Merging [1]
Merging [1, 2]
Merging [1, 2, 3]
Merging [1, 2, 3, 4, 5]
Merging [1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
我们能通过logn的数量级的计算将长度为n的列表拆分。而第二个过程是合并,每个列表中的元素最终将被处理并被放置在排序好的列表中,所以合并操作对一个长度为n的列表需要n的数量级的操作。从而最终操作的复杂度为nlogn。归并排序是一种O(nlogn) 的算法。
快速排序
快速排序用了和归并排序一样分而治之的方法来获得同样的优势,但同时不需要使用额外的存储空间(也就是说快速排序中我们不需要子列)。
快速排序首先选择一个中值。虽然有很多不同的方法来选择这个数值,我们将会简单地选择列表里的第一项。中值的作用在于协助拆分这个列表。中值在最后排序好的列表里的实际位置,我们通常称之为分割点的,是用来把列表变成两个部分来随后分别调用快速排序函数的。
我们来举例说明:alist=[5,9,4,7],我们通过两个指标i,j 来标注比5(分割点)小的数字和比5大的数字,
1.让i从9开始,j从3开始,i发现9比5大,于是i向j报告说我这边发现了你的人,i等待j的反应,
2.j骂了句开始拼了老命工作j先找到7,7比5大,j放置7,进一步考察4,于是向i反应,说这边有i的人,
3.于是双方互换人质(XD,此时alist=[5,4,9,7]),
4.然后i又开始工作,考察9,向j反应md,又是你们的人,
5.j开始工作看了看4,表示没有其他人可以考察,
6.俩个指标停止工作,5和4交换位置,alist=[4,5,9,7],然后对5(分割点)两边的数字们,重复上述操作
def partition(alist,first,last):#对分割点外的数进行比较,并根据大小移动到分割点两边
pivotvalue = alist[first]
leftmark = first+1#左指标
rightmark = last#右指标
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:#左指标先考察
leftmark = leftmark + 1
while alist[rightmark] >= pivotvalue and rightmark >= leftmark:#左指标停止工作后右指标开始工作
rightmark = rightmark -1
if rightmark < leftmark:#考察结束
done = True
else:#交换数字
temp = alist[leftmark]
alist[leftmark] = alist[rightmark]
alist[rightmark] = temp
print(alist)
temp = alist[first]#分割点移动到正确位置
alist[first] = alist[rightmark]
alist[rightmark] = temp
return rightmark
运行
s=[5,9,4,7]
partition(s,0,3)
print(s)
得到:
[5, 4, 9, 7]
[4, 5, 9, 7]
对分割点两边重复操作:
def quickSort(alist):
def quickSortHelper(alist,first,last):
if first<last:#对分割点左右进行递归,结束条件
splitpoint = partition(alist,first,last)
quickSortHelper(alist,first,splitpoint-1)#调用自身,向结束条件演进
quickSortHelper(alist,splitpoint+1,last)#调用自身,向结束条件演进
完整代码:
def quickSort(alist):
def quickSortHelper(alist,first,last):
if first<last:
splitpoint = partition(alist,first,last)
quickSortHelper(alist,first,splitpoint-1)
quickSortHelper(alist,splitpoint+1,last)
quickSortHelper(alist,0,len(alist)-1)
def partition(alist,first,last):
pivotvalue = alist[first]
leftmark = first+1
rightmark = last
done = False
while not done:
while leftmark <= rightmark and alist[leftmark] <= pivotvalue:
leftmark = leftmark + 1
while alist[rightmark] >= pivotvalue and rightmark >= leftmark:
rightmark = rightmark -1
if rightmark < leftmark:
done = True
else:
temp = alist[leftmark]
alist[leftmark] = alist[rightmark]
alist[rightmark] = temp
temp = alist[first]
alist[first] = alist[rightmark]
alist[rightmark] = temp
return rightmark
注意一个长度为n的列表,如果每次分裂都发生在列表的中央,那么将会重复logn次分裂。为了找到分割点,n个项目中的每一个都需要和中值进行对比,那么,综合起来是O(nlogn),但是若是分割点非常的小,或者非常的大,快速排序的性能就会衰退到 O ( n 2 ) O(n^2) O(n2) ,所以一般我们会随机的抽取几个数字还后选择最好的,作为分割点。
基数排序
十进制的基数排序是一个使用了“箱的集合”(包括一个主箱和 10 个数箱)的机械分选技术。每个箱像队列(Queue)一样,根据数据项的到达顺序排好并保持它们的值。
算法开始时,将每一个待排序数值放入主箱中。然后对每一个数值进行逐位的分析。每个从主箱最前端取出的数值,将根据其相应位上的数字放在对应的数字箱中。比如,考虑个位数字,534 被放置在数字箱 4,667 被放置在数字箱 7。一旦所有的数值都被放置在相应的数字箱中,所有数值都按照从箱 0 到箱 9 的顺序,依次被取出,重新排入主箱中。该过程继续考虑十位数字,百位数字,等等。当最后一位被处理完后,主箱中就包含了排好序的数值。
def basenumberSort(alist):
mainbox=alist.copy()#建立主箱
boxs=[[]]*10#建立数字箱
check=False#标注排序是否完成
base=1#每次检查的位数
while not check:
for i in mainbox:
pos=(i//base)%10
boxs[pos]=boxs[pos]+[i]#从主箱进入数箱
print('base=%d'%base)
print("Now boxs is",boxs)
if boxs[1:]==[[]]*(9):
check=True
else:
mainbox=[]#主箱重置
for j in boxs:#从数箱进入主箱
mainbox=mainbox+j
base=base*10
boxs=[[]]*10#数箱重置
print("Now mainbox is",mainbox)
return mainbox
显然基数排序的次数与排序数组中最大值的位数(记为d)有关系,也和我们有几个数箱有关系(也就是基数数,记为r),对n个数进行排序,每次对r个数箱进行赋值,再对主箱进行n次赋值,一共进行d次,所以容易知道,基数的复杂度是 O ( d ⋅ ( n + r ) ) O(d\cdot(n+r)) O(d⋅(n+r))
总结
到目前为止,我们已经介绍了八大排序中的七个,分别是冒泡排序、选择排序、插入排序、希尔排序、归并排序、快速排序和基数排序;
这7个排序中最基础的是冒泡排序和插入排序,以及基础排序;
冒泡排序每次遍历,对相邻的两个数进行考察,每次遍历确定一个‘最大值’;
插入排序每次遍历,将一个数据与‘有序子表’进行比较,插入到有序子表的正确位置中;
基数排序每次遍历,对所有数据的某一位进行考查,直接放入对应的数箱中,再从数箱中逐个进行主箱;
而选择排序、希尔排序、归并排序、快速排序都是‘二代排序’,也就是基础排序的改进排序。
选择排序是冒泡排序的优化,优化了交换数据的次数,每次直接将最大值放到正确位置;
希尔排序是插入排序的优化,采用分而治之的想法,将数据分为几个小的子表,先对子表进行插入排序,再汇总后进行总体的插入排序;
最后归并排序和快速排序可以说是一种高级排序,他们都在排序的过程中引入了递归的思想;
归并排序是将数据不断的分割,最后对分割的小子表进行排序,然后将子表进行合并(合并的过程也涉及到对比)
快速排序相对归并排序又有所进步,它并不需要子表来辅助排序,而是直接选择‘中立方’和考察方,查考数据,看看数据是左派还是右派,然后对各自hi的派别再重复考察,有点二分法的味道
这里先不对这七个排序的时间复杂度和稳定性进行分析,待我们学习过堆排序后再做进一步的分析
树
一棵树是由n(n>0)个元素组成的有限集合,其中:
(1)每个元素称为结点(node)
(2)有一个特定的结点,称为根结点或根(root)
节点
节点(Node)是树的基本构成部分。
边(Edge):也是另一个树的基本构成部分。边连接两个节点,并表示它们之间存在联系。
除了根节点(顶部节点)外,每个节点都有父节点,也许有子节点也许没有,一般我们将父节点和子节点用直线链接起来来表示一棵树

子树:节点的子树是指该节点的子节点的所有边和后代节点所构成的集合。
层数:一个节点的层数是指从根节点到该节点的路径中的边的数目。
高度:树的高度等于所有节点的层数的最大值。例如上面的树层数就是2
嵌套列表实现树
tree=['老爷爷',['大爸',['姐姐'],[]],['臭老爹',[],['花花']]]
print('根节点:',tree[0])
print('左子树:',tree[1])
运行得到
根节点: 老爷爷
左子树: ['大爸', ['姐姐'], []]
嵌套列表法的一个非常好的特性是子树的结构与树相同;这个结构本身是递归的!子树具有一个根值和两个表示叶节点的空列表。嵌套列表法的另一个优点是它容易扩展到多叉树。(因为每个节点的位置都已经用数字表明)
class BinaryTree:
def __init__(self,root):
self.item=[root,[],[]]
def addLeft(self,newBranch):#对根节点增加左子树
t=self.item.pop(1)
if len(t)>1:
self.item.insert(1,[newBranch,t,[]])
else:
self.item.insert(1,[newBranch,[],[]])
def addRight(self,newBranch):#对根节点增加右子树
t=self.item.pop(2)
if len(t)>1:
self.item.insert(2,[newBranch,t,[]])
else:
self.item.insert(2,[newBranch,[],[]])
def getroot(self):#输出根节点
return self.item[0]
def setroot(self,val):#重新设立根节点
self.item[0]=val
def getleftChild(self):#查看左子树
return self.item[1]
def getrightChild(self):#查看右子树
return self.item[2]
def printtree(self):
return self.item
运行
tree=BinaryTree(0)
tree.addLeft(2)
tree.addLeft(3)
tree.addRight(4)
tree.printtree()
得到:
[0, [3, [2, [], []], []], [4, [], []]]
每次插入新的节点只能对当前的root的左右进行插入,如果想要对根节点的某个子节点添加左右子树,只需要利用类中get**Child对子节点进行追踪即可.
引用节点实现树
class node:#建立节点类
def __init__(self,root):
self.key=root#根节点
self.left=None#左子节点
self.right=None#右子节点
class BinaryTree(node):#建立树类,继承节点类属性
def insertRight(self,newNode):#增加右子树
if self.right==None:
self.right=newNode
else:
newNode.right=self.right
self.right=newNode
def insertLeft(self,newNode):#增加左子树
if self.left==None:
self.left=newNode
else:
newNode.left=self.left
self.left=newNode
def getroot(self):
return self.key
def getleftChild(self):#得到左子树
return self.left
def getrightChild(self):#得到右子树
return self.right
运行
s=BinaryTree(1)
s.addLeft(node(2))
s.addLeft(node(3))
s.addRight(node(4))
print(s.getleftChild())
print(s.getrightChild())
得到:
<__main__.node object at 0x7f35763e24a8>
<__main__.node object at 0x7f35763e2588>
实例(解析树)
将(7+3)*(5-2)这样一个数学表达式表示成一个解析树
我们希望将一个数学表达式以树的结构进行存储,例如10*3,我们将其存储为下图形式

整个过程涉及到的字符有左括号,右括号,操作符和操作数。
每当读到一个左括号时,就代表着有一个新的表达式,我们就需要创建一个与之相对应的新的树。相反,每当读到一个右括号时,就代表这一个表达式的结束。整个过程需要我们改变root节点来保持对子节点的追踪,最后需要我们把root还原成根节点。
最后,每个操作符都应该有一个左子节点和一个右子节点。通过上面的分析我们定义以下四条规则:
1.读到 ( 时,建立一个新的节点,作为当前节点的左子树
2.读到数字时,将该数字添加到当前节点,将当前节点改为该节点的父节点
3.读到运算符时,建立新的节点,为当前节点添加右子树,将当前节点改为右子树
4.读到 ) 时,root节点改为当前节点的父节点
分析:规则4要求我们对根节点和一个节点的父节点进行记录,且后记录的父节点,先提升,是一个先进后出的顺序,从而我们利用栈的结构来实现
from pythonds.basic.stack import Stack#引用栈
from pythonds.trees.binaryTree import BinaryTree#引用二叉树
def ParseTree(formule):
f=formule.split()#对公式进行切割
pStack=Stack()
eTree=BinaryTree('')
pStack.push(eTree)#对根节点进行记录
currentTree=eTree
for i in f:
if i =='(':
currentTree.insertLeft('')#增加左节点
pStack.push(currentTree)#对父节点进行记录
currentTree=currentTree.getLeftChild()#改变当前节点
elif i not in ['+','-','/','*',')']:
currentTree.setRootVal(int(i))#对当前节点赋值
parent=pStack.pop()
currentTree=parent#当前节点改为父节点
elif i in ['+', '-', '*', '/']:
currentTree.setRootVal(i)
currentTree.insertRight('')
pStack.push(currentTree)#对父节点进行记录
currentTree = currentTree.getRightChild()
elif i == ')':
currentTree = pStack.pop()#由当前节点向根节点回退
else:
raise ValueError#如果输入的字符有误,停止操作
return eTree
运行
s = ParseTree("( ( 10 + 5 ) * 3 )")
s.getRootVal()
得到:
'*'
树的遍历
在上面一节引用节点来实现树的结构时,我们输出的左右子树还只是存储左右子树的地址,如果想要输出具体的树结构,就需要对树的每个节点进行遍历。
1.二叉树的遍历,分为先序、中序和后序,分别代表根左右、左根右和左右根;
2.二叉树的层次遍历,指按层去进行从左到右的读取
所有的遍历都是采用递归的想法(我们用上面的得到的解析树来进行验证)
def xianxu(tree):
if tree:
print(tree.getRootVal())
xianxu(tree.getLeftChild())
xianxu(tree.getRightChild())
def zhongxu(tree):
if tree!=None:
zhongxu(tree.getLeftChild())
print(tree.getRootVal())
zhongxu(tree.getRightChild())
def houxu(tree):
if tree:
zhongxu(tree.getLeftChild())
zhongxu(tree.getRightChild())
print(tree.getRootVal())
def chenxu(tree):
print(tree.getRootVal())
def printchen(tree):
if tree!=None:
left=tree.getLeftChild()
right=tree.getRightChild()
if left:
print(left.getRootVal())
if right:
print(right.getRootVal())
printchen(left)
printchen(right)
printchen(tree)
print('先序为:')
xianxu(s)
print('中序为:')
zhongxu(s)
print('后序为:')
houxu(s)
print('层序为:')
chenxu(s)
运行得到:
先序为:
*
+
10
5
3
中序为:
10
+
5
*
3
后序为:
10
+
5
3
*
层序为:
*
+
3
10
5
树结构的应用
二叉堆
队列一种重要的变体叫做“优先队列”(Priority Queue)。优先队列的出队(Dequeue)操作和队列一样,都是从队首出
队。但在优先队列内部,数据项的次序是由它们的“优先级”来确定的:有最高优先级的数据项排在队首,而优先级最低的数据项则排在队尾。
自然的会想到,以队列加排序的方式来实现优先队列,一个数据插入的复杂度是O(n),列表排序(指快速排序)的复杂度是O(nlog(n)),而二叉堆则可以以更低的复杂度实现
二叉堆其逻辑结构用图形表示很像二叉树,但我们却可以仅仅用一个列表来实现它。二叉堆通常有两种:最小成员 key 排在队首的称为“最小堆(min heap)”,反之,最大 key排在队首的是“最大堆(max heap)”。在这一节里我们会使用最小堆。
二叉堆实现
为了使得二叉堆的复杂度维持在O(nlog(n)),在我们的堆实现中,我们采用“完全二叉树”的结构来近似实现“平衡”。完全二叉树,指每个内部节点都有两个子节点,最多可有一个节点例外。
完全二叉树的引入,直接使得我们在实现二叉堆时可以不采用嵌套或者节点引用的方法,而是直接使用列表,

例如上图中,为了找到9的父节点,我们只需要对9所在的位置除以2,看看它的商即可,但是这需要我们从list[1],开始记录堆的数据。
根据上面的说明,我们定义二叉堆如下
class BinHeap:
def __init__(self):
self.heapList = [0]#二叉堆的结构主体,注意我们并不使用list[0]的位置,而是从list[1]开始
self.currentSize = 0#二叉堆的大小
(这里说些题外话,由于完全二叉树的特殊结构,我们如果知道数据的大小n,是否立即就可以推出建立起来完全二叉树的高度呢?记树的高度为h,则h满足 2 h − 1 ≤ n < 2 h 2^{h-1}\le n<2^{h} 2h−1≤n<2h)
很容易想到,当有新的数据进入堆时,一个直接的办法是让该数据插入到队尾,也就是添加为叶节点,然后再和其对应的父节点进行比较和交换位置。
def percUp(self,i):#和父节点进行比较和交换
while i // 2 > 0:#复杂度是O(log(n))
if self.heapList[i] < self.heapList[i // 2]:
tmp = self.heapList[i // 2]
self.heapList[i // 2] = self.heapList[i]
self.heapList[i] = tmp
i = i // 2
def insert(self,k):#插入数据
self.heapList.append(k)
self.currentSize = self.currentSize + 1#记录数据个数
self.percUp(self.currentSize)
现在我们已经定义了增加数据的方法,也通过percup函数,使得根节点是最小的数字;
但是真正的难点在于一旦我们移走根节点后,整个二叉堆的就需要重排,你当然可以将移走根节点后的列表重新逐个进入二叉堆,这样的复杂度是是O((n-1)log(n-1));
我们有更好的办法,先将一个叶节点(这里我们取列表中的最后一个) 放到根节点的位置,然后对根节点进行“下沉”操作:让其与子节点进行比较并与较小的子节点交换位置
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):#选出较小的节点
if i * 2 + 1 > self.currentSize:#确定子节点的个数
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
综上,我们设置输出并移走堆顶如下:
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]#叶节点上升至堆顶
self.currentSize = self.currentSize - 1#记录堆大小变化
self.heapList.pop()#删除原堆顶
self.percDown(1)#堆顶下沉
return retval
至此我们已经定义了一个二叉堆所有的常用功能
完整代码如下
class BinHeap:
def __init__(self):
self.heapList = [0]
self.currentSize = 0
def percUp(self,i):
while i // 2 > 0:
if self.heapList[i] < self.heapList[i // 2]:
tmp = self.heapList[i // 2]
self.heapList[i // 2] = self.heapList[i]
self.heapList[i] = tmp
i = i // 2
def insert(self,k):
self.heapList.append(k)
self.currentSize = self.currentSize + 1
self.percUp(self.currentSize)
def percDown(self,i):
while (i * 2) <= self.currentSize:
mc = self.minChild(i)
if self.heapList[i] > self.heapList[mc]:
tmp = self.heapList[i]
self.heapList[i] = self.heapList[mc]
self.heapList[mc] = tmp
i = mc
def minChild(self,i):
if i * 2 + 1 > self.currentSize:
return i * 2
else:
if self.heapList[i*2] < self.heapList[i*2+1]:
return i * 2
else:
return i * 2 + 1
def delMin(self):
retval = self.heapList[1]
self.heapList[1] = self.heapList[self.currentSize]
self.currentSize = self.currentSize - 1
self.heapList.pop()
self.percDown(1)
return retval
def buildHeap(self,alist):#将一个列表转为二叉堆
i = len(alist) // 2
self.currentSize = len(alist)
self.heapList = [0] + alist[:]
while (i > 0):
self.percDown(i)
i = i - 1
bh = BinHeap()
bh.buildHeap([9,5,6,2,3])
print(bh.delMin())
print(bh.delMin())
print(bh.delMin())
print(bh.delMin())
print(bh.delMin())
最后buildHeap的部分,我们也可以改为:
def buildHeap(self,alist):#将一个列表转为二叉堆
i = len(alist) // 2
self.currentSize
for j in alist:
self.insert(j)
在目前为止看起来,如果我们每次只要求堆顶是最小值,似乎并不需要每次都对父节点和子节点进行比较,那么这种父节点总是小于(或大于)子节点的优势到底在哪呢?
堆排序
堆排序的基本思想是:将待排序序列构造成一个最小堆,此时,整个序列的最小值就是堆顶的根节点。去掉根节点,然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次最小值。
如此反复执行,便能得到一个有序序列了
def HeapSort(alist):
hp=BinHeap()
hp.buildHeap(alist)
l=len(alist)
for i in range(l):
alist[i]=hp.delMin()
return alist
八大排序总结
至此我们已经学习了所有的八大排序,下面我们对这八个常见的排序的复杂度,稳定性进行总结

总结完八大排序后我们继续关于树结构的学习
二叉搜索树
定义:如果左子树中键值 Key 都小于父节点,而右子树中键值 Key 都大于父节点,我们将这种树称为 BST 搜索树
很容易就注意到二叉搜索树,有二部分组成:树结构和排序 (左为尊,但是一个二货确认为右为大)
注意:二叉搜索树一般并不是简单的储存值,而是有权重的任何数据,例如:(姓名,体重);(姓名:身高)等等,从而我们需要重新写树节点,要有主体和权重两部分
我们利用以下的方法来创建一个‘有序’的二叉树:
- 从树的根开始搜索,比较新的键值,如果新的键值是小于当前节点。搜索左子树,如果新的键值是大于当前节点,搜索右子树。
- 当无左(或右)子树的搜索,我们发现的位置就是应该在子树中安装新节点的位置。
- 向树添加一个节点,在上一步发现插入对象的位置创建一个新的TreeNode
为了实现以上操作,我们需要
1.确认根节点是否为空;
2.与根节点进行比较;
3.确认左右子树是否为空;
4.对左右节点进行追踪;
我们按照上述的步骤利用递归编写增加节点的方法
先来定义树节点
class TreeNode:
def __init__(self,key,val,left=None,right=None,parent=None):
self.key = key#权重
self.payload = val#主体
self.leftChild = left
self.rightChild = right
self.parent = parent#跟踪节点
def hasLeftChild(self):#查看左子树是否为空
return self.leftChild
def hasRightChild(self):#查看右子树是否为空
return self.rightChild
村民的你一定由节点,有序—联想到了链表,同样的我们也只需要对根节点进行记录,然后每次添加或者查找是都从根节点进行递归操作,我们定义二叉搜索树的主体如下:
class BinarySearchTree:
def __init__(self):
self.root = None
self.size = 0
下面来实现增加节点:
class BinarySearchTree:
def __init__(self):
self.root = None
self.size = 0
def length(self):
return self.size
def __len__(self):
return self.size
def put(self,key,val):#如果主体为空,定义根节点
if self.root:
self._put(key,val,self.root)
else:
self.root = TreeNode(key,val)
self.size = self.size + 1
def _put(self,key,val,currentNode):
if key < currentNode.key:#和根节点进行比较
if currentNode.hasLeftChild():
self._put(key,val,currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key,val,parent=currentNode)
else:
if currentNode.hasRightChild():
self._put(key,val,currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key,val,parent=currentNode)
def __setitem__(self,k,v):#python的魔法方法
self.put(k,v)
上面使用了一种我们从来没有见过的魔法方法:__setitem__和__len__
为了后面进行查找时,可以像字典一样的方便我们(也许python的字典就是一个二叉查找树)
在Python中,如果我们想实现创建类似于字典的类,可以通过重写魔法方法__getitem__、setitem、delitem、__len__方法去模拟。
getitem(self,key):返回键对应的值。
setitem(self,key,value):设置给定键的值
delitem(self,key):删除给定键对应的元素。
len():返回元素的数量
实际操作:
BST=BinarySearchTree()
BST[199]='小刘'
BST.root.payload
得到:'小刘'
下面我们利用__getitem__来定义查找
def get(self,key):#从根节点开始查找
if self.root:
res = self._get(key,self.root)
if res:
return res.payload
else:
return None
else:
return None
def _get(self,key,currentNode):#定义递归的查找函数
if not currentNode:
return None
elif currentNode.key == key:
return currentNode
elif key < currentNode.key:
return self._get(key,currentNode.leftChild)
else:
return self._get(key,currentNode.rightChild)
def __getitem__(self,key):
return self.get(key)
更新二叉搜索树类定义后,我们运行BST[199]
得到'小刘'
这样我们就可以取出已知的权重的主体,但是我们还无法判断一个值是否在我们二叉树中
我们引入__contain__映射,使得我们可以使用类似list中的in操作
def __contains__(self,key):
if self._get(key,self.root):
return True
else:
return False
运行print(199 in BST) print(250 in BST),得到
True False
这就NB了!!
现在我们就剩下删除操作了
删除操作是所有操作里最困难的操作,我们二叉树节点的有序性是在利用put做到的,一旦删除一个有子树的节点,二叉树将不再有序
我们分三种情况进行讨论:
1.删除节点没有子树
2.删除节点有一个子树
3.删除节点有两个子树
我们直接来看第三种情况,第1和第2种情况蕴含在第三种情况里
我们针对第三种情况做如下操作:
我称其为找继承人法:从被删除节点的右子树的最小节点,或者从左子树的找最大的节点来替代,由于二叉搜索树的特殊结构你一定发现,这是可行的
下面我们结合例子来说明找继承人法:删除节点5,我们从11节点的选出最小的节点7进行替代,当然如果你想先对左子树进行操作,我们将使用2进行替代
当然在处理的过程中我们需要全程记录继承节点的父节点

代码实现:
在这里我们直接取右子树的最小节点或者说右子树的最左节点
1.首先我们来更新get函数,使得我们在get的过程中记录get节点的父节点,因为我们删除一个key时,需要找到对应的节点以及他的父节点(根节点除外)
def _get(self,key,currentNode):#定义递归的查找函数
if currentNode==None:
return None
elif currentNode.key == key:
return currentNode
elif key < currentNode.key:
temp = currentNode
currentNode = currentNode.leftChild
if currentNode:
currentNode.parent=temp
return self._get(key,currentNode)
else:
temp = currentNode
currentNode = currentNode.rightChild
if currentNode:
currentNode.parent=temp
return self._get(key,currentNode)
进一步我们对TreeNode类增加寻找继承节点的函数以及判断是否为叶子节点的函数,该函数使得第一种情况,即被删除节点没有子树的情况
class TreeNode:
def __init__(self,key,val,left=None,right=None,parent=None):
self.key = key#权重
self.payload = val#主体
self.leftChild = left
self.rightChild = right
self.parent = parent#跟踪节点
def hasLeftChild(self):#查看左子树是否为空
return self.leftChild
def hasRightChild(self):#查看右子树是否为空
return self.rightChild
def isLeaf(self):#d判断是否为叶节点
if not self.hasLeftChild() and not self.hasRightChild():
return True
else:
return False
def findMin(self):#寻找最小节点
current = self
while current.hasLeftChild():
current = temp
current= current.leftChild,current
current.parent = temp
return current
def finMax(self):#寻找最大节点
current = self
while current.hasRightChild():
temp = current
current = current.rightChild
current.parent = temp
return current
def findSuccessor(self):#寻找继承节点
succ = self
if self.hasRightChild():
succ = self.rightChild.findMin()
else:
succ = self.leftChild.finMax()
return succ
有了以上的铺垫工作后
我们现在来完成继承法:
def remove(self,key):
if not self._get(key,self.root):
return 'do not exit This point'
else:
current=self._get(key,self.root);
if current.isLeaf():
if current==current.parent.leftChild:
current.parent.leftChild=None
else:
current.parent.rightChild=None
else:
succ = current.findSuccessor()
if succ.isLeaf():
if succ.parent.hasLeftChild():
succ.parent.leftChild = None
else:
succ.parent.rightChild = None
current.key,current.payload = succ.key,succ.payload
else:
if succ.hasLeftChild():
succ.parent.rightChild=succ.leftChild
else:
succ.parent.leftChild = succ.rightChild
current.key,current.payload = succ.key,succ.payload
完成代码:
class TreeNode:
def __init__(self,key,val,left=None,right=None,parent=None):
self.key = key#权重
self.payload = val#主体
self.leftChild = left
self.rightChild = right
self.parent = parent#跟踪节点
def hasLeftChild(self):#查看左子树是否为空
return self.leftChild
def hasRightChild(self):#查看右子树是否为空
return self.rightChild
def isLeaf(self):#d判断是否为叶节点
if not self.hasLeftChild() and not self.hasRightChild():
return True
else:
return False
def findMin(self):#寻找最小节点
current = self
while current.hasLeftChild():
current = temp
current= current.leftChild,current
current.parent = temp
return current
def finMax(self):#寻找最大节点
current = self
while current.hasRightChild():
temp = current
current = current.rightChild
current.parent = temp
return current
def findSuccessor(self):
succ = self
if self.hasRightChild():
succ = self.rightChild.findMin()
else:
succ = self.leftChild.finMax()
return succ
#################################################################################################################################################################################
class BinarySearchTree:
def __init__(self):
self.root = None
self.size = 0
def length(self):
return self.size
def __len__(self):
return self.size
def put(self,key,val):
if self.root:
self._put(key,val,self.root)
else:
self.root = TreeNode(key,val)
self.size = self.size + 1
def _put(self,key,val,currentNode):
if key < currentNode.key:
if currentNode.hasLeftChild():
self._put(key,val,currentNode.leftChild)
else:
currentNode.leftChild = TreeNode(key,val,parent=currentNode)
else:
if currentNode.hasRightChild():
self._put(key,val,currentNode.rightChild)
else:
currentNode.rightChild = TreeNode(key,val,parent=currentNode)
def __setitem__(self,k,v):
self.put(k,v)
def get(self,key):#从根节点开始查找
if self.root!=None:
res = self._get(key,self.root)
if res:
return res.payload
else:
return None
else:
return None
def _get(self,key,currentNode):#定义递归的查找函数
if currentNode==None:
return None
elif currentNode.key == key:
return currentNode
elif key < currentNode.key:
temp = currentNode
currentNode = currentNode.leftChild
if currentNode:
currentNode.parent=temp
return self._get(key,currentNode)
else:
temp = currentNode
currentNode = currentNode.rightChild
if currentNode:
currentNode.parent=temp
return self._get(key,currentNode)
def __getitem__(self,key):
return self.get(key)
def remove(self,key):
if not self._get(key,self.root):
return 'do not exit This point'
else:
current=self._get(key,self.root);
if current.isLeaf():
if current==current.parent.leftChild:
current.parent.leftChild=None
else:
current.parent.rightChild=None
else:
succ = current.findSuccessor()
if succ.isLeaf():
if succ.parent.hasLeftChild():
succ.parent.leftChild = None
else:
succ.parent.rightChild = None
current.key,current.payload = succ.key,succ.payload
else:
if succ.hasLeftChild():
succ.parent.rightChild=succ.leftChild
else:
succ.parent.leftChild = succ.rightChild
current.key,current.payload = succ.key,succ.payload
下面进行试验:
BST=BinarySearchTree()
BST[199]='小刘'
BST[230]='GP'
BST[220]='老权'
BST[240]='老何'
BST[260]='小马哥'
#########################################################################################
print(BST.get(260))
BST.remove(260)
if BST.get(260)==None:
print('This point has delected')
########################################################################################
#小马哥是一个叶节点,下面我们来删除GP节点,GP有两个子节点‘老权’和‘老何’,删除‘GP’后‘老何’将会成为继承者
print(BST.get(230))
print(BST.root.rightChild.payload)
BST.remove(230)
if BST.get(230)==None:
print('This point has delected')
print(BST.root.rightChild.payload)
运行得到:
小马哥
This point has delected
GP
GP
This point has delected
老何
AVL树
定义
高度平衡属性:对于树中的每一个节点p,节点p的子树的高度最多相差1
AVL树是具有高度平衡属性的二叉查找树(若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值)
解决不平衡
但是并不是所有的二叉查找树都可以满足条件,例如下面的情形:
1.LL(根节点左不平衡,根左子树也不平衡)

2.LR(根节点左子树不平衡,根左子树右不平衡)

3.RR(根节点右子树不平衡,右子树右不平衡)
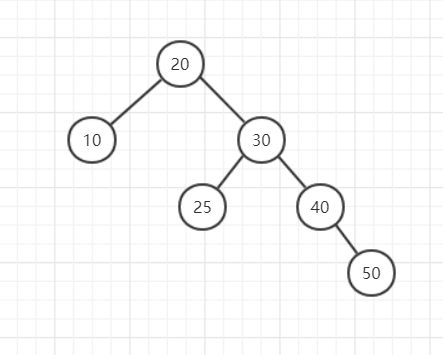
4.RL(根节点右子树不平衡,右子树左不平衡)

显然这就是所有的情况,当然你可以进一步详细的描述二叉树不平衡的状态,例如定义LLL等等
但是有了以上的描述(两次),我们足矣解决AVL树的平衡问题
我们先来定义树类:
class node:#建立节点类
def __init__(self,root):
self.key=root#根节点
self.left=None#左子节点
self.right=None#右子节点
class BinaryTree(node):#建立树类,继承节点类属性
def insertRight(self,newNode):#增加右子树
if self.right==None:
self.right=newNode
else:
newNode.right=self.right
self.right=newNode
def insertLeft(self,newNode):#增加左子树
if self.left==None:
self.left=newNode
else:
newNode.left=self.left
self.left=newNode
def getroot(self):#得到根节点
return self.key
def getleftChild(self):#得到左子树
return self.left
def getrightChild(self):#得到右子树
return self.right
对于上面的四种不平衡的情况,我们希望将LR和RL的类型通过简单的处理后化为LL和RR,然后再解决LL,RR是LL的镜像也就对应解决了
也就是说,我们要解决的问题主要有两个:
1.如何将LR转为LL(RL的情况完全类似),
2.如何将LL(RR完全类似)变为平衡树
一个直接的想法是把LR的左子树的左右节点交换,这样就变为了LL,但是这样就破坏了每个树的排序结构,该树不再是一个二叉查找树
我们采用一种“提拔和降一级”的方式(很多地方叫做旋转)
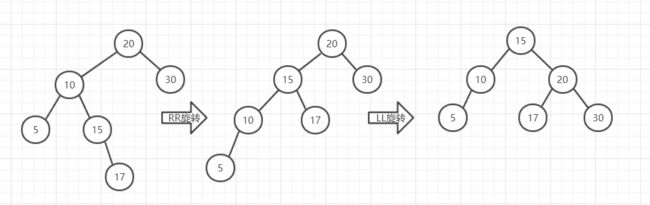
“提拔”较长的子节点,降一级父节点,就上图来说提拔15节点,降级10节点,同时依据二叉查找树的要求,10节点变为15节点的左节点,这样的LR就转为了LL
利用同样的思路,对LL进行操作,就上面中间的图的说,提拔较长的15节点,降一级父节点20,并根据排序规则安排好17就完成了全过程
代码实现
但是在上述操作前我们需要判断LR类型和LL类型,这需要我们对树的高度有所了解
def gethigh(tree):#判断一个树的高度
high=0
if not tree:
return 0
elif tree and tree.left==None and tree.right==None:
high = high +1
return high
elif tree and tree.left == None:
high = 1+ gethigh(tree.right)
return high
elif tree and tree.right == None:
high = 1 + gethigh(tree.left)
return high
else:
return 1+max(gethigh(tree.left),gethigh(tree.right))
利用树的高度我们就可以判断一个树是否平衡:
def judgeBalance(tree):
if abs(gethigh(tree.left)-gethigh(tree.right)<=1):#查看左右子树的高度差
print('This tree is good baby Tree')
return True
else:
print('bad Tree')
return False
进一步查看类型(这里只判断是LL还是LR,也就是默认只有两种情况)
def judgeClass(tree):#判断一颗树的类型是LL还是LR
if judgeBalance(tree):
pass
else:
if gethigh(tree.left)>gethigh(tree.right) and gethigh(tree.left.left)>gethigh(tree.left.right):
return 'LLTree'
else:
return 'LRTree'
运行一个例子:
T=Tree(20)
T.left=Tree(10)
T.right=Tree(30)
T.left.left=Tree(5)
T.left.right=Tree(15)
T.left.right.right=Tree(17)
运行judgeClass(T),得到
bad Tree
'LRTree'
下面对LR类型的树进行平衡化,也就是提拔和降一级:
为了简化代码我们将judgeBalance函数中的print删掉
def BalanceTree(tree):
if judgeClass(tree)=='LRTree':
T_left=tree.left#记录左子树
#进行降一级
T_left_right=T_left.right
T_left.right=None
if T_left_right.left==None:
T_left_right.left=T_left
else:
T_left.right=T_left_right.left
T_left_right.left=T_left
#进行提拔
tree.left = T_left_right
if judgeClass(tree)=='LLTree':
#进行降一级
T_left=tree.left
tree.left=None
if T_left.right==None:
T_left.right =tree
else:
tree.left=T_left.right
T_left.right =tree
#提拔
tree=T_left
对上面的例子进行处理,运行judgeBalance(T)后查看是否平衡judgeBalance(T)
得到:True
完整代码
class node:#建立节点类
def __init__(self,root):
self.key=root#根节点
self.left=None#左子节点
self.right=None#右子节点
class Tree(node):#建立树类,继承节点类属性
def insertRight(self,newNode):#增加右子树
if self.right==None:
self.right=newNode
else:
newNode.right=self.right
self.right=newNode
def insertLeft(self,newNode):#增加左子树
if self.left==None:
self.left=newNode
else:
newNode.left=self.left
self.left=newNode
def getroot(self):#得到根节点
return self.key
def getleftChild(self):#得到左子树
return self.left
def getrightChild(self):#得到右子树
return self.right
def gethigh(tree):
high=0
if not tree:
return 0
elif tree and tree.left==None and tree.right==None:
high = high +1
return high
elif tree and tree.left == None:
high = 1+ gethigh(tree.right)
return high
elif tree and tree.right == None:
high = 1 + gethigh(tree.left)
return high
else:
return 1+max(gethigh(tree.left),gethigh(tree.right))
def judgeBalance(tree):
if abs(gethigh(tree.left)-gethigh(tree.right)<=1):
return True
else:
return False
def judgeClass(tree):
if judgeBalance(tree):
pass
else:
if gethigh(tree.left)>gethigh(tree.right) and gethigh(tree.left.left)>gethigh(tree.left.right):
return 'LLTree'
else:
return 'LRTree'
T=Tree(20)
T.left=Tree(10)
T.right=Tree(30)
T.left.left=Tree(5)
T.left.right=Tree(15)
T.left.right.right=Tree(17)
def BalanceTree(tree):
if judgeClass(tree)=='LRTree':
T_left=tree.left#记录左子树
#进行降一级
T_left_right=T_left.right
T_left.right=None
if T_left_right.left==None:
T_left_right.left=T_left
else:
T_left.right=T_left_right.left
T_left_right.left=T_left
#进行提拔
tree.left = T_left_right
if judgeClass(tree)=='LLTree':
#进行降一级
T_left=tree.left
tree.left=None
if T_left.right==None:
T_left.right =tree
else:
tree.left=T_left.right
T_left.right =tree
#提拔
tree=T_left
查看当前导入模块信息
在我们上面的学习中常常引入pythonds模块来,引用里面的栈,二叉树,利用dir()查看当前导入模块的信息,可以快速了解当前模块的结构
help("modules")#查看当前Python已经安装的模块列表
运行
dir(pythonds)
得到:
['AVLTree',
'BinHeap',
'BinarySearchTree',
'BinaryTree',
'Deque',
'Graph',
'PriorityQueue',
'Queue',
'Stack',
'Vertex',
'__ALL__',
'__builtins__',
'__cached__',
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__path__',
'__spec__',
'basic',
'graphs',
'trees']
我们可以看到pythonds下有二叉堆(BinHeap),etc
我们进一步查看二叉堆dir(BinHeap)
['__class__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__le__',
'__lt__',
'__module__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__',
'__weakref__',
'buildHeap',
'delMin',
'insert',
'minChild',
'percDown',
'percUp']
进一步查看insert函数:dir(BinHeap.insert())
------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-29-552eccecb349> in <module>
----> 1 dir(BinHeap.insert())
TypeError: insert() missing 2 required positional arguments: 'self' and 'k'
我们看到提示:表示insert函数需要self和k
图
图是比我们上一章学习的树更普遍的结构,事实上你可以认为树是一种特殊的图
顶点 Vertex
顶点(也称“节点 node”)是图的基础部分。它具有名称标识“key”。顶点也可以有附加的信息项“playload”。
边 Edge
边(也称“弧 arc”)是图的另一个基础组成部分。如果一条边连接两个顶点,则表示两者具有联系。边可以是单向的,也可以是双向的。如果一个图中的边都是单向的,我们就说这个图是“有向图directed graph/digraph”。上图所显示的先修依赖图很明显是一个有向图,因为你必须先修某些课程才能学习其他课程。
权重 Weight
从一个顶点到另一个顶点的“代价”,可以给边赋权。例如,一个连接两个城市的道路图中,两个城市之间的距离就可以作为边的权重。
图的定义:图可以用 G=(V,E)来表述。对于图 G,V 是顶点的集合,E 是边的集合。每个边是一个元组(v, w),w, v∈V
路径 Path
图中的路径,是由边依次连接起来的顶点序列
[外链图片转存失败(img-5KROdAqZ-1565252249057)(https://runestone.academy/runestone/books/published/pythonds/_images/digraph.png)]
圈 Cycle
有向图里的圈是首尾顶点相同的路径
| Graph() | 创建一个空的图 |
|---|---|
| addVertex(vert) | 将一个顶点Vertex 对象加入图中 |
| addEdge(fromVert, toVert) | 添加一条有路径的有向边 |
| addVertex(vert) | 将一个顶点 Vertex 对象加入图中 |
| addEdge(fromVert, toVert, weight) | 添加一条带权的有向边 |
| getVertices() | 返回图中所有顶点列表 |
| in | 返回顶点是否存在图中 |
图的实现
图最容易的实现方法之一就是采用二维矩阵

然而,我们也注意到大部分的矩阵分量是空的,这种情况我们称矩阵是“稀疏”的
邻接矩阵实现图
class Graph:
def __init__(self,vertex=[],AdjMtrix=[],Weight=[]):#有节点列表,边邻接矩阵和权重邻接矩阵组成
self.vertex=vertex
self.AdjMtrix=AdjMtrix
self.Weight=Weight
def addVertex(self,vert):#的结构重点
if vert in self.vertex:#如果已经存在不用任何操作
print('Included this vertex')
else:
self.vertex.append(vert)#增加节点到节点列表
for i in self.AdjMtrix:
i.append(0)#原有的矩阵每行增加一列
self.AdjMtrix.append([0]*len(self.vertex))#在矩阵里增加一行
for j in self.Weight:
j.append(0)#在原有矩阵增加一列
self.Weight.append([0]*len(self.vertex))#在矩阵里增加一行
def addEdge(self,fromVert,toVert,weight=0):
if fromVert in self.vertex and toVert in self.vertex:#若两个节点都在图中
fromV_local=self.vertex.index(fromVert)#查到节点对应的位置
toV_local=self.vertex.index(toVert)#查到节点对应的位置
self.AdjMtrix[fromV_local][toV_local] = 1#在矩阵中进行标注
self.Weight[fromV_local][toV_local] = weight
elif fromVert in self.vertex:#若只有一个节点在
self.addVertex(toVert)
self.addEdge(fromVert,toVert,weight)
elif toVert in self.vertex:
self.addVertex(fromVert)
self.addEdge(fromVert,toVert,weight)
else:#若两个节点都不在
self.addVertex(fromVert)
self.addVertex(toVert)
self.addEdge(fromVert,toVert,weight)
def getVertices(self):
print('All Vertices is ',self.vertex)
print('All egdes in down matrix')
for i in self.AdjMtrix:
print(i)
def __contains__(self,vertex):#使得in可以使用
return vertex in self.vertex
案例:
G=Graph()
G.addEdge(0,1,5)
G.addEdge(0,5,2)
G.addEdge(0,5,2)
G.addEdge(1,2,4)
G.addEdge(2,3,9)
G.addEdge(3,4,7)
G.addEdge(3,5,3)
G.addEdge(4,0,1)
G.addEdge(5,2,1)
G.addEdge(5,4,8)
G.getVertices()
print(5 in G)
得到:
All Vertices is [0, 1, 5, 2, 3, 4]
All egdes in down matrix
[0, 1, 1, 0, 0, 0]
[0, 0, 0, 1, 0, 0]
[0, 0, 0, 1, 0, 1]
[0, 0, 0, 0, 1, 0]
[0, 0, 1, 0, 0, 1]
[1, 0, 0, 0, 0, 0]
True