CNN模型大综述
文章目录
- 一、主要的分类CNN网络:Backbone
- 1.1 LeNet5
- 1.2 Dan Ciresan Net
- 1.3 AlexNet
- 1.3.3 AlexNet的衍生
- 1.4 ZFNet
- 1.5 VGG-16/VGG-19
- 1.6 NIN网络
- 1.7 GoogLeNet - inception
- 1.7.1 [网络结构](https://www.zybuluo.com/rianusr/note/1419006)
- inception v1:
- inception v2:为了解决“Internal Covariate Shift”问题,提出了BN
- inception v3
- inception v4
- Inception-ResNet v1
- Inception-ResNet v2
- 1.7.2 主要技术点
- 1.8 ResNet
- 1.9 DenseNet
- 二、 轻量化网络
- 2.1 SqueezeNet
- 2.2 NobileNet
- 2.3 ShuffleNet
- 2.4 Xception : MobileNet的反向操作
- 三、目标检测模型
- 3.1 基于候选区域(Region Proposal)的深度学习目标检测法
- 3.1.1 [R-CNN Fast-RCNN Faster-RCNN](https://www.zybuluo.com/rianusr/note/1315377)
- 3.1.2 SSP-NET
- 3.1.3 R-FCN
- 3.2 基于回归方法的深度学习目标检测算法
- 3.2.1 Yolo系列
- 3.2.2 SSD
- 3.2.3 RetinaNet
- **focal_loss**
- 3.3 RefineDet
- 3.3.1 网络结构
- 3.3.2 主要技术点
- 3.4 OCR
- 四、语义分割
- 4.1 FCN
- 4.2 Unet
- 4.3 SegNet
- 4.4 PSPNet
- 4.5 DeepLab
- 4.6 MaskRCNN
- 五、目标追踪
- 5.1 相关过滤
- 5.2 深度学习
- 六、行为识别
- 6.1 TSN
转载自:https://www.zybuluo.com/rianusr/note/1514835 非常感谢此博主允许转载
- 物体识别和检测(Object Detection)
- 语义分割(Semantic Segmentation)
- 运动和跟踪(Motion & Tracking)
- 三维重建(3D Reconstruction)
- 视觉问答(Visual Question & Answering)
- 动作识别(Action Recognition)等。
- 顶级会议
- ICCV:International Comference on Computer Vision
- CVPR:International Conference on Computer Vision and Pattern Recogintion
- ECCV:Europeon Conference on Computer Vision
一、主要的分类CNN网络:Backbone
1.1 LeNet5
1994年:LeNet5 卷积-池化-全链接、Avepooling、sigmoid
网络结构
主要技术点
- 卷积、池化、非线性、全链接
- 采用卷积提取空间特征;
- 使用average pooling来进行特征图的下采样,筛选特征;
- 使用tanh或sigmoid激活函数来增加模型的表达;
- 使用全链接层(MLP)作为最后的分类器;

1.2 Dan Ciresan Net
2010年:Dan Ciresan Net - 第一个发布在GPU上训练的神经网络,包含了前向和反向传播
1.3 AlexNet
1.3 2012年:AlexNet ReLU、Dropout、Maxpooling、LRN、分组卷积
网络结构
主要技术点
使用ReLU激活函数;
使用Dropout技术实现模型的正则化,有效避免过拟合;
使用max pooling池化层保留特征图的最大响应;
因为GPU内存的限制,首次采用分组卷积的方法;
LRN:局部响应归一化层
(1):通道间归一化是表示求和的通道数;
- 局部区域范围在相邻通道间,但没有空间上的扩张(即尺寸为local_sizeX1X1);
(2):通道内归一化示表示归一化操作的区间的边长;local_size的默认值为5;
- 局部区域范围在当前通道内,有空间上的扩张(即1XlocalXloacl);

1.3.3 AlexNet的衍生
Overfeat:AlexNet的衍生 - 提出了learning bounding box的概念
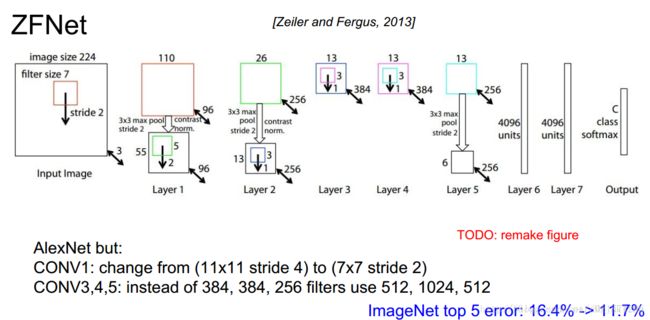
1.4 ZFNet
2013年:ZFNet 特征可视化、反池化、反卷积、反激活
网络结构
主要技术点
(1)特征可视化:
反卷积、反池化、反激活函数
- 结论一:CNN网络前面的层学习的是物理轮廓、边缘、颜色、纹理等特征,后面的层学习的是和类别相关的抽象特征
- 结论二:CNN学习到的特征具有平移和缩放不变性,但是,没有旋转不变性
(2)特征提取的通用性:
- CNN网络的特征提取具有通用性,这是后面微调(fine-tune)的理论支持
(3)对于遮挡的敏感性:
(4)特征的层次分析:更深层的网络有助于分类性能的提升;
- 层数越深,特征不变性越强,类别的判别能力越强;
(5)对AlexNet的改进:在卷积网络的第一层,更小的卷积核、步长效果更好
- 通过特征可视化可以知道,Krizhevsky的CNN结构学习到的第一层特征只对于高频和低频信息有了收敛,但是对于中层信息却还没有收敛;同时,第二层特征出现了混叠失真,这个主要是因为第一个卷积层的层的步长设置为4引起的,为了解决这个问题,作者不仅将第一层的卷积核的大小设置为7*7,同时,也将步长设置为2
特征可视化方法:
反池化:记录池化过程的最大值的位置,反池化时将该位置还原,其余位置填0;
- 池化过程不可逆,反池化只是一种近似
反卷积:使用学习到的核(参数一致)转置后作为反卷积的核,对调整后的特征进行反卷积;
反激活:同样采用ReLU激活函数,确保输出前后均为整数,激活与反激活过程没啥区别;
1.5 VGG-16/VGG-19
2014年:VGG-16/VGG-19 探索网络深度、3*3卷积核、3*3的卷积序列组合,模拟大卷积核的感受野
网络结构
主要技术点
- 第一个在各个层使用3*3卷积核(更小的卷积)进行卷积;
- 通过3*3的卷积序列组合,模拟大卷积核的感受野;

1.6 NIN网络
2014年:NIN网络
网络结构
主要技术点
各个卷积之后使用空间MLP进行特征组合;
- MLP 的能力能通过将卷积特征组合进更复杂的组(group)来极大地增加单个卷积特征的有效性
将之前网络中最后的MLP层使用 全局平均池化层(Global Average Pooling) 代替;

1.7 GoogLeNet - inception
2014年:GoogLeNet - inception
- inception网络是针对高层feature-map的操作,底层仍然保持传统的卷积来提取特征。
- 基于赫布原则和多尺度处理,提升了模型的宽度和深度;
- 利用padding=same的方式,通过不同尺度的卷积核,感受野不同,获取不同尺度obj的特征;
- Inception为什么有效?
- Inception的作用就是替代了人工确定卷积层中过滤器的类型或者是否创建卷积层和池化层,让网络自己学习它具体需要什么参数。
1.7.1 网络结构
inception v1:
- 第一代inception网络:通过1*1卷积核的降维操作,有效的降低了计算量;
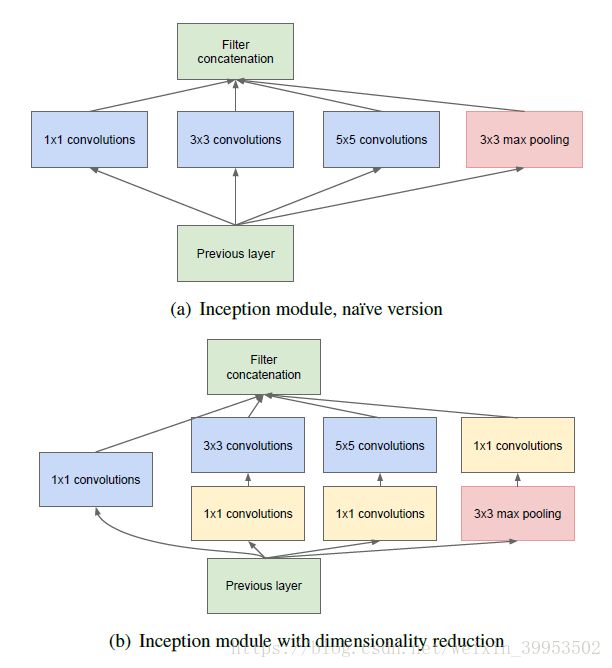
inception v2:为了解决“Internal Covariate Shift”问题,提出了BN
- 这个问题是由于在训练过程中,网络参数变化所引起的。具体来说,对于一个神经网络,第n层的输入就是第n-1层的输出,在训练过程中,每训练一轮参数就会发生变化,对于一个网络相同的输入,但n-1层的输出却不一样,这就导致第n层的输入也不一样,这个问题就叫做“Internal Covariate Shift”
- 在网络结构方面,通过2个3*3的卷积操作,代替一个5*5的卷积,获得相同的感受野
- BN的主要作用:
- 加速网络收敛;
- 防止梯度消失
inception v3
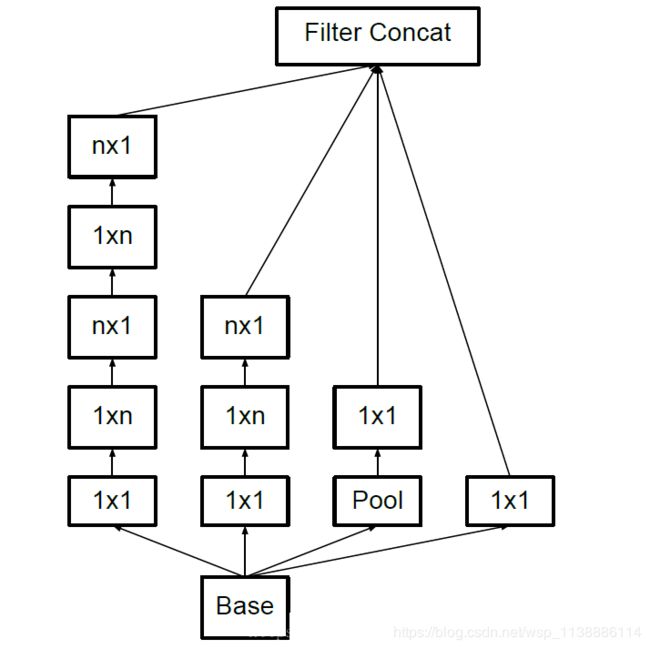
inception v4
Inception-ResNet v1
Inception-ResNet v2
1.7.2 主要技术点
bottleneck:通过1*1卷积进行通道降维后再进行卷积操作,之后再次通过1*1卷积进行升维操作;使用辅助分类器:利用中间特征层进行预测,并将loss按照一定比例(0.3)贡献到总loss
- 把梯度有效的传递回去,不会有梯度消失问题,加快了训练
- 中间层的特征也有意义,空间位置特征比较丰富,有利于提成模型的判别力;
除了在加深模型的方向上,提出了在模型宽度上的探索;
注意:当过滤器的数目超过1000个的时候,会出现问题,网络会“坏死”
- 即在average pooling层前都变成0。即使降低学习率,增加BN层都没有用。这时候就在激活前缩小残差可以保持稳定。为了增加稳定性,作者通过 0.1 到 0.3 的比例缩放残差激活值,即下图

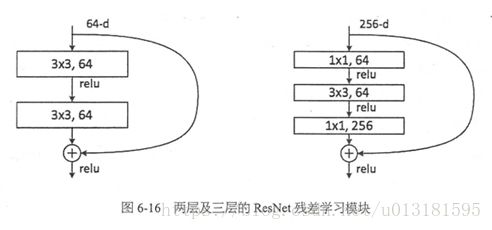
1.8 ResNet
2015年:ResNet
网络结构
- 主要技术点
- shorcut or skip connections
- 一定程度上解决了深层网络训练时的梯度消失和梯度爆炸的问题;
- 保护信息的完整性;
- 整个网络只需要学习输入、输出差别的那一部分,简化学习目标和难度

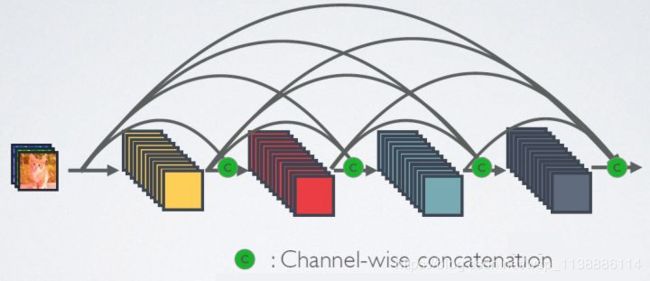
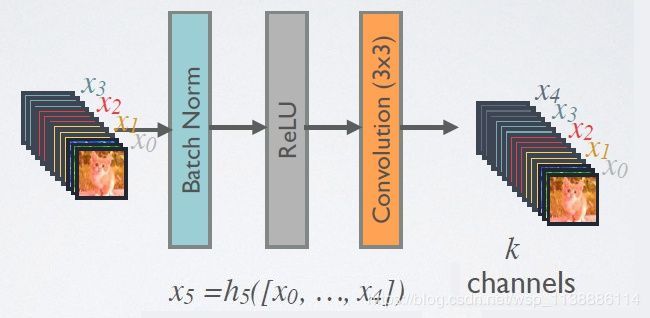
1.9 DenseNet
2017年:DenseNet
网络结构
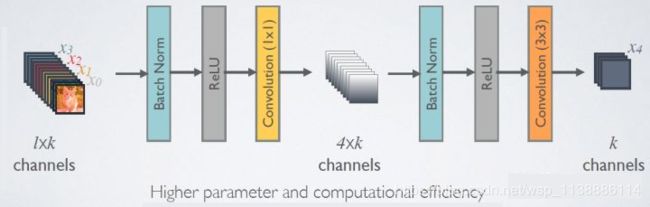
- bottleneck优化:
- 主要技术点
- 由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。
- 由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”;
- 参数更小且计算更高效,这有点违反直觉,由于DenseNet是通过concat特征来实现短路连接,
- 实现了特征重用,并且采用较小的growth rate,每个层所独有的特征图是比较小的;
- 由于特征复用,最后的分类器使用了低级特征。

二、 轻量化网络
- 轻量化模型:SqueezeNet,MobileNet,ShuffleNet以及Xception
2.1 SqueezeNet
- fire_model :
- 总结:
1、提出了一种新的结构,来对原先的网络进行修改。
2、使用FCN替代FC,减小参数数量。
3、使用deep-compression方法来进一步缩小模型。
- 裁剪:设置阈值,对小于阈值的参数直接写0,然后用非零参数再次训练。
- 量化:对参数做聚类,然后每个类别的参数的梯度值相加,作用在聚类中心上。
- 编码:Huffman编码进一步压缩存储。

2.2 NobileNet
- depthwise-separable-convolution :
- me个channel单独配置一个卷积核,对所有卷积后的特征图经过1*1的卷积获得想要的channel_num

2.3 ShuffleNet
group convolutions:
详解:
- 1、假设有输入的feature-map是5*5*9的图。我们按照channel将其分为3组。
- 2、同样我们有12个卷积核,同样将其分为3组,每组负责对某一组channel进行卷积。
- 3、另外,如果一直这样分开,容易产生边缘效应。所以,对于每个channel内部,在卷积完了后,我们在分成若干个sub-group。
- 4、然后下一层的group就由上一层每个group中各取一个subgroup组成得到。

2.4 Xception : MobileNet的反向操作
总结:
- 1、Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了
depthwiseseparableconvolution,在基本不增加网络复杂度的前提下提高了模型的效果。- 2、有些人会好奇为什么引入depthwise separable convolution没有大大降低网络的复杂度,因为depthwise separable convolution在mobileNet中主要就是为了降低网络的复杂度而设计的。
- 3、原因是Inception的作者加宽了网络,使得参数数量和Inception v3差不多,然后在这前提下比较性能。因此Xception目的不在于模型压缩,而是提高性能。

三、目标检测模型

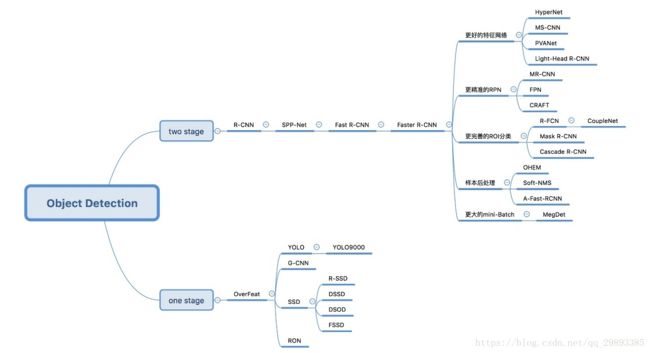
- 深度学习目标检测网络汇总对比
- CNN-目标检测、定位、分割
3.1 基于候选区域(Region Proposal)的深度学习目标检测法
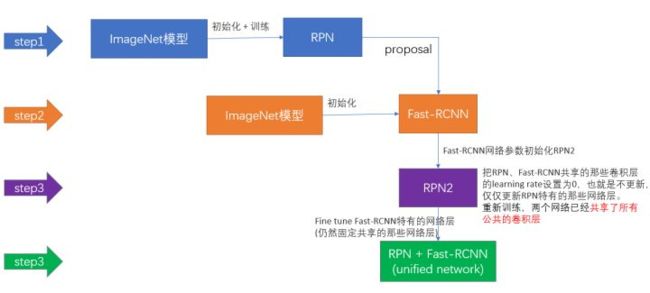
3.1.1 R-CNN Fast-RCNN Faster-RCNN
主要技术点:
- Selective Search RPN;
- 图像块缩放 ROI Pooling;
- SVM分类器 SoftMax分类;
- 全连接层加速:对权值矩阵进行SVD分解;
- 轮流训练:

3.1.2 SSP-NET
3.1.3 R-FCN
3.2 基于回归方法的深度学习目标检测算法
3.2.1 Yolo系列
Yolo系列
3.2.2 SSD
- 从YOLO到SSD再到YOLO9000(二):SSD
3.2.3 RetinaNet
RetinaNet
focal_loss
3.3 RefineDet
- 对于目标检测,two-stage方法(例如Faster R-CNN)可以获得最高精度,而one-stage方法(例如SSD)具有高效率的优点。继承两者的优点且克服其缺点,本文提出了一种新的单次目标探测器,名为RefineDet,它比two-stage方法更精准,同时保持了one-stage方法的效率。
3.3.1 网络结构
3.3.2 主要技术点
3.4 OCR
-
目前OCR的应用场景主要分为以下三个方面:
1、自然场景下多形态文本检测与识别
2、手写体文本检测与识别
3、文档的文本检测与识别(版面分析等) -
OCR目前的技术综述以及文献
- 文本检测
-
1、CTPN(基于Faster RCNN):目前比较成熟的文本检测框架,精确度较好。但是检测时间较长,有很大的优化空间。
【文献】Detecting Text in Natural Image with Connectionist Text Proposal Network -
2、TextBoxes、TextBoxes++(基于SSD):调整Anchor长宽比,适用于文字细长的特点,但针对小文本会有漏检。
【文献】TextBoxes: A Fast Text Detector with a Single Deep Neural Network
TextBoxes++: A Single-Shot Oriented Scene Text Detector -
3、SegLink(CTPN+SSD):通常用于自然场景下,检测多角度文本。
【文献】Detecting Oriented Text in Natural Images by Linking Segments -
4、DMPNet:采用非矩形四边形选定Anchor进行检测,通过Monte-Carlo方法计算标注区域于矩形候选框和旋转候选框的重合度后重新计算顶点坐标,得到非矩形四边形的顶点坐标。适用于自然场景下文本检测。
【文献】Deep Matching Prior Network: Toward Tighter Multi-oriented Text Detection -
5、YOLO:文本检测时间短,精确度较好。但针对小目标效果一般,容易造成大范围漏检。
【文献】YOLOv3: An Incremental Improvement -
6、EAST:采取FCN思路,做特征提取和特征融合,局部感知NMS阶段完成检测。网络的简洁使得检测准确率和速度都有进一步提升。(针对自然场景下使用较多)
【文献】EAST: An Efficient and Accurate Scene Text Detector -
7、Pixel-Anchor:针对Anchor数量多引起文本出现的丢失问题、Pixel感受野不足引起长文本丢失情况,结合两者各自的优点,对于长行的中文检测场景有较好的适应性。网络结构可以分为两部分,其中pixel-based的方法为对EAST的改进,anchor-based的方法为对SSD的改进。前者主要为了检测中等的文本,后者主要为了检测长行和较小的文本。
【文献】Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks -
8、IncepText:针对大尺度、长宽比及方向变化问题,借鉴GoogLeNet中的inception模块来解决这些问题。在inception结构中通过不同尺寸的卷积核设计达到检测不同大小和宽高比的文字,同时引入deformable卷积层操作和deformable PSROI pooling层提升任意方向文字的检测效果。
【文献】IncepText: A New Inception-Text Module with Deformable PSROI Pooling for Multi-Oriented Scene Text Detection - 文本识别
-
1、CNN+RNN+CTC(如CRNN):使用目前最为广泛的一种文本识别框架。需要自己构建字词库(包含常用字、各类字符等)。
【文献】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition -
2、CNN(如Densenet)+CTC:资料不多,效果一般,泛化能力较差。没有加入了RNN的效果好。
【文献】暂未找到,可参考GitHub -
3、Tesserocr(Tesseract):使用比较广泛的一种开源识别框架,支持多语言多平台。Tesseract在识别清晰的标准中文字体效果还行,稍微复杂的情况就很糟糕(多字体等),而且花费的时间也很多。
GitHub -
4、RARE:主要用于识别变形的文本图像效果好,用于自然场景下文本识别。
【文献】Robust Scene Text Recognition with Automatic Rectification -
5、FOTS(EAST+CRNN):端到端OCR模型,检测和识别任务共享卷积特征层,既节省了计算时间,也比两阶段训练方式学习到更多图像特征。引入了旋转感兴趣区域(RoIRotate), 可以从卷积特征图中产生出定向的文本区域,从而支持倾斜文本的识别。
【文献】FOTS: Fast Oriented Text Spotting with a Unified Network - 最新比赛进展
-
OCR的比赛,最著名的当属ICDAR了,即文档分析与识别国际会议(International Conference on Document Analysis and Recognition,ICDAR)。目前是每两年举办一次,2019年举办了一次比赛(ICDAR 2019),共分为以下六个赛道:
-
(1)Scene Text Visual Question Answering(ST-VQA,场景文本识别并回答问题)
(2)Multi-lingual scene text detection and recognition(MLT,多语言场景文本检测和识别)
(3)Large-scale Street View Text with Partial Labeling(LSVT,部分标签的大型街景文本识别)
(4)Arbitrary-Shaped Text(ArT,任意形状文本识别)
(5)Scanned Receipts OCR and Information Extraction(SROIE,扫描收据OCR和信息提取)
(6)Reading Chinese Text on Signboard(ReCTS,在商家招牌上识别中文)
四、语义分割
语义分割
4.1 FCN
4.2 Unet
- 深入理解深度学习分割网络Unet
- U-Net:生物医学的图像分割笔记
- 全卷积神经网络图像分割(U-net)-keras实现
- Unet++:研习U-Net
- 全卷积网络(FCN)与图像分割
4.3 SegNet
4.4 PSPNet
4.5 DeepLab
4.6 MaskRCNN
模型结构:Backbone:ResNet101
主要技术点:
ROIAlign:不做任何量化,以双线性内插方法获取像素点的值
- 在FasterRCNN中ROIPooling经历了两次量化过程
- 在GT框映射到feature-map上时;
- 在执行ROIpooling的时候;
Mask Branch(Head Architecture) - FCN结构;
FPN
Multi-task Loss function:
- Mask Branch针对FasterRCNN中识别为指定类的区域进行像素级别的预测;
- 对每个像素点采用sigmoid而分类,避免了类之间的竞争
图像分割综述【深度学习方法】
SegNet(Pooling的时候记录index)
空洞卷积-dilated conv
dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息
潜在问题:
- The Gridding Effect: kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对 pixel-level dense prediction 的任务来说是致命的。
- Long-ranged information might be not relevant:我们从 dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。如何同时处理不同大小的物体的关系,则是设计好 dilated convolution 网络的关键。
优化策略:
通向标准化设计:Hybrid Dilated Convolution (HDC)
第一个特性是,叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷积,依然会出现 gridding effect。
第二个特性是,我们将 dilation rate 设计成 锯齿状结构,例如 [1, 2, 5, 1, 2, 5] 循环结构。
第三个特性是,我们需要满足一下这个式子:
- 其中 是 层的 dilation rate 而 是指在 层的最大dilation rate,那么假设总共有n层的话,默认 。假设我们应用于 kernel 为 的话,我们的目标则是 ,这样我们至少可以用 dilation rate 1 即 standard convolution 的方式来覆盖掉所有洞。
PSPNet:
deeplab
- hole kernel
- softmax + CRF
refineNet
- RefineNet的一个特点是使用了较多的residual connection。这样的好处不仅在于在RefineNet内部形成了short-range的连接,对训练有益。此外还与ResNet形成了long-range的连接,让梯度能够有效传送到整个网络中。作者认为这一点对于网络是很有好处的。
分割网络总结:
