acm集训队课程设置--第一节课
acm集训队课程设置--第一节课
acm新手入门语法基础
1.输入输出格式
【输入】有多组输入数据,但没有具体的告诉你有多少组,只是让你对应每组输入,应该怎样输出。
【输出】有多组输出,对应着每组输入,每组输出占一行。
【代码】对于上述常见的情况,我们可以用下面的代码来解决
完整代码:
#include
int main()
{
int m,n;
while(scanf("%d%d",&m,&n)!=EOF)
{
m+=n;
printf("%d\n",m);
}
return 0;
} 一般EOF的值为-1,ASCII代码值的范围是0~255,不可能出现-1,因此可以用EOF作为文件结束标志
【输入】先输入一个整数,告诉我们接下来有多少组数据,然后在输入每组数据的具体值。
【输出】有多组输出,对应着每组输入,每组输出占一行。
【代码】这也是一种常见的输入形式,简单的代码,我们可以先用scanf函数输入第一个整数来确定有多少行,然后在用for循环一组一组的输入。
#include
int main()
{
int n,x,y,i;
scanf("%d",&n);
for(i=1;i<=n;i++)
{
scanf("%d%d",&x,&y);
x+=y;
printf("%d\n",x);
}
return 0;
}【输入】有多组输入数据,没有具体的告诉你有多少组,但是题目却告诉你遇见什么结束。
【输出】有多组输出,每对应一组输入都有相应的输出,结束标记不用管!
【代码】这种类型的题目和第一种差不多,但是有一点值得注意,就是要加上结束条件。对于这道题我们可以这样
当然你也可以将条件写在while循环的内部,条件满足时break即可。
【完整代码】
#include
int main() {
int a,b;
while(scanf("%d%d",&a,&b)&&(!(a==0&&b==0))){
printf("%d\n",a+b);
}
return 0;
}再补充下一点点:
提交时可能出现的提示:
#define MAXN 200 //定义宏
int arr[MAXN + 1]; //如果题意规定最多个数为200个,一般都会加上1,防止操作时不小心数组越界了
memset(arr, 0, sizeof(arr)); //初始化数组的个数为0
如何评估时间复杂度和空间复杂度?
时间复杂度:比赛中自己估算复杂度是否会超时会爆栈,首先要记住,时间复杂度为10^7即1千万左右在1s内可以稳当地跑出来, 10^8跑1s很勉强, 有的题目可能卡过去, 有的就卡不过去。
空间复杂度:对于空间复杂度,其实一般就是看用到的数组要开多少。怎么算呢?拿int数组举栗,一个int要4字节即4b,然后1kb能开256个int,然后一般的题目要么给32768kb,要么给65536kb,所以前者可以开790w左右大小的数组,后者可以开1580w左右的数组.
n = 32768*1024 / sizeof(数组类型);就可算得。 sizeof(int) = 4 , 结果:8388608
虽然往上有的时候还能开,但比赛时候最好不要开过大吧,至于为什么?业界良心。
freopen("题.txt", "r", stdin); //读取文件的函数,节约时间的做法,把要输入的数据放在里面,与代码文件同目录下即K即可
freopen("文件名.txt", "w", stdout); //把结果输入到文件的函数,经常用于打表法,比赛时的技巧。
#include
#include
#include
#include
#include
#include
using namespace std;
int main(void){
freopen("文件名.txt", "r", stdin); //放在main方法的开头
int n,m;
scanf("%d%d",&n, &m);
printf("%d %d\n", n, m);
return 0;
} 2.数据类型范围:
unsigned int 0~4294967295
int 2147483648~2147483647
unsigned long 0~4294967295
long 2147483648~2147483647
long long的最大值:9223372036854775807
long long的最小值:-9223372036854775808
unsigned long long的最大值:18446744073709551615
__int64的最大值:9223372036854775807
__int64的最小值:-9223372036854775808
unsigned __int64的最大值:18446744073709551615
类型 比特数 有效数字 数值范围
float 32 6-7 -3.4*10(-38)~3.4*10(38)
double 64 15-16 -1.7*10(-308)~1.7*10(308)
long double 128 18-19 -1.2*10(-4932)~1.2*10(4932)
3.结构体
作用:数据组合成一个整体来使用
几种常见方式
第一种是最基本的结构体定义,其定义了一个结构体A
struct A //第一种
{
int a;
}; 第二种则是在定义了一个结构体B的同时定义了一个结构体B的变量m。
struct B //第二种
{
int b;
}m;第三种结构体定义没有给出该结构体的名称,但是定义了一个该结构体的变量n,也就是说,若是想要在别处定义该结构体的变量是不行的,只有变量n这种在定义结构体的定义变量才行。
struct //第三种
{
int c;
}n;第四种结构体定义在第一种结构定义的基础上加了关键字typedef,此时我们将struct D{int d}看成是一个数据类型,但是因为并没有给出别名,直接用D定义变量是不行的。如D test;,不能直接这样定义变量test。但struct D test;可行。
typedef struct D //第四种
{
int d;
};第五种结构体定义在第四种结构体定义的基础上加上了别名x,此时像在第四种结构体定义中说得那样,此时的结构体E有别名x,故可以用x定义E的结构体变量。用E不能直接定义,需要在前面加struct,如struct E test;。
typedef struct E //第五种
{
int e;
}x;#include
#include
#include
#include
#include
#include
using namespace std;
struct B
{
int a;
int b;
}m;
int main(void){
m.a = 11;
m.b = 12;
m.b = 13;
printf("%d %d\n", m.a, m.b); //11 13
B aa;
aa.a = 12;
aa.b = 13;
printf("%d %d\n", aa.a, aa.b); //12 13
return 0;
} 4.c++常用头文件的简介
#include //集合,元素都是唯一的,而且默认情况下会对元素自动进行升序排列
#include //数学函数
#include //队列
#include //栈
#include // Vector v1; 可以存放任何类型的对象(但必须是同一类对象)。
// vector对象可以在运行时高效地添加元素,并且vector中元素是连续存储的。
#include //用它可以使用c语言的输出
#include //包含随机数函数(srand, rand)等
#include //字符串处理函数strlen,strcmp,strcpy...
#include // 声明了一些用来在标准输入输出设备上进行输入输出操作的对象,例如(常见的cin、cout)
#include // 包含sort排序,
using namespace std; //告诉编译器使用 std 命名空间
const int MaxN = 0x3f3f3f3f; //无穷大
const int MinN = 0xc0c0c0c0; //无穷小 #include
迭代器模拟了C++中的指针,可以有++运算,
用*(解引用算符,deference)或 -> 算符来访问容器中的元素
4.1.关于set
关于set有下面几个问题:
(1)为何map和set的插入删除效率比用其他序列容器高?
大部分人说,很简单,因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。结构图可能如下:
A
/ \
B C
/ \ / \
D E F G
因此插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点也OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
(2)当数据元素增多时,set的插入和搜索速度变化如何?
如果你知道log2的关系你应该就彻底了解这个答案。在set中查找是使用二分查找,也就是说,如果有16个元素,最多需要比较4次就能找到结果,有32个元素,最多比较5次。那么有10000个呢?最多比较的次数为log10000,最多为14次,如果是20000个元素呢?最多不过15次。看见了吧,当数据量增大一倍的时候,搜索次数只不过多了1次,多了1/14的搜索时间而已。你明白这个道理后,就可以安心往里面放入元素了。
#include
#include
#include
#include
#include
#include
#include
#include 4.2关于 cmath
cmath是c++语言中的库函数,其中的c表示函数是来自c标准库的函数,math为数学常用库函数。
以下是cmath的标头中定义的函数:
int abs(int i);//返回整型参数i的绝对值
double fabs(double x);//返回双精度参数x的绝对值
long labs(long n);//返回长整型参数n的绝对值
double exp(double x);//返回指数函数e^x的值
double log(double x);//返回logex的值
double log10(double x) 返回log10x的值
double pow(double x,double y) 返回x^y的值
double pow10(int p) 返回10^p的值
double sqrt(double x) 返回+√x的值
double acos(double x) 返回x的反余弦arccos(x)值,x为弧度
double asin(double x) 返回x的反正弦arcsin(x)值,x为弧度
double atan(double x) 返回x的反正切arctan(x)值,x为弧度
double cos(double x) 返回x的余弦cos(x)值,x为弧度
double sin(double x) 返回x的正弦sin(x)值,x为弧度
double tan(double x) 返回x的正切tan(x)值,x为弧度
double hypot(double x,double y) 返回直角三角形斜边的长度(z),
x和y为直角边的长度,z^2=x^2+y^2
double ceil(double x) 返回不小于x的最小整数
double floor(double x) 返回不大于x的最大整数
int rand() 产生一个随机数并返回这个数
double atof(char *nptr) 将字符串nptr转换成浮点数并返回这个浮点数
long atol(char *nptr) 将字符串nptr转换成长整数并返回这个整数
double atof(char *nptr) 将字符串nptr转换成双精度数,并返回这个数,错误返回0int atoi(char *nptr) 将字符串nptr转换成整型数, 并返回这个数,错误返回0
long atol(char *nptr) 将字符串nptr转换成长整型数,并返回这个数,错误返回0
4.3.1 普通队列4.3 关于Queue
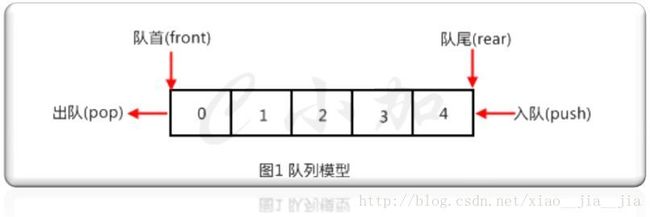
#include
#include
#include
#include
#include
#include
#include
#include PriorityQueue介绍(自动排序)
下面是一个典型的优先队列的结构图:
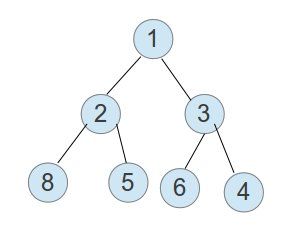
它的每个父节点都比两个子节点要小,但是整个数组又不是完全顺序的。
priority_queue
Type为数据类型, Container为保存数据的容器,Functional为元素比较方式。
如果不写后两个参数,那么容器默认用的是vector,比较方式默认用operator<,也就是优先队列是大顶堆,队头元素最大。
#include
#include
#include
#include
#include
#include
#include
#include 优先输出小数据
如果要用到小顶堆,则一般要把模板的三个参数都带进去。
STL里面定义了一个仿函数 greater<>,对于基本类型可以用这个仿函数声明小顶堆
#include
#include
#include
#include
#include
#include
#include
#include #include
#include
#include
#include
#include
#include
#include
#include 4.4 关于栈
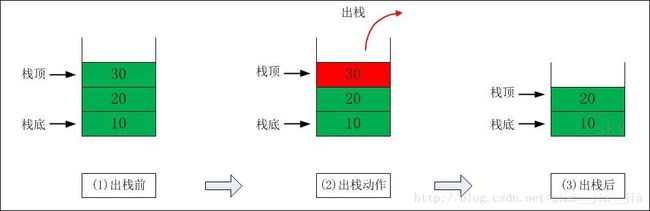
主要的方法有如下:
empty() 堆栈为空则返回真
pop() 移除栈顶元素(不会返回栈顶元素的值)
push() 在栈顶增加元素
top() 返回栈顶元素
#include
#include
#include
#include
#include
#include
#include
#include 4.5关于vector
作用:它能够像容器一样存放各种类型的对象,简单地说,vector是一个能够存放任意类型的动态数组,能够增加和压缩数据。
vector
vec.begin()//指向迭代器中第一个元素。
vec.end()//指向迭代器中末端元素的下一个,指向一个不存在元素。
vec.push_back(elem) //在尾部加入一个数据。
vec.pop_back() //删除最后一个数据。
vec.capacity() //vector可用空间的大小。
vec.size()//返回容器中数据个数。
vec.empty() //判断容器是否为空。
vec.front() //传回第一个数据。
vec.back() //传回最后一个数据,不检查这个数据是否存在。
vec.at(index) //传回索引idx所指的数据,如果idx越界,抛出out_of_range。
vec.clear() //移除容器中所有数据。
vec.erase(iterator) //删除pos位置的数据,传回下一个数据的位置。
vec.erase(begin,end) //删除[beg,end)区间的数据,传回下一个数据的位置。注意:begin和end为iterator
vec.insert(position,elem) //在pos位置插入一个elem拷贝,传回新数据位置。
vec.insert(position,n,elem) //在pos位置插入n个elem数据,无返回值。
vec.insert(position,begin,end) //在pos位置插入在[beg,end)区间的数据,无返回值。
Vector作为函数的参数或者返回值时,需要注意它的写法:
double Distance(vector
简单的使用方法如下:
vector
test.push_back(1);
test.push_back(2); //把1和2压入vector,这样test[0]就是1,test[1]就是2
自己见到的实例:
vector
points[0].size(); //指第一行的列数
使用下标访问元素,cout<
vector
for(it=vec.begin(); it!=vec.end(); it++)
cout<<*it<
vector的元素不仅仅可以是int,double,string,还可以是结构体,但是要注意:结构体要定义为全局的,否则会出错。
#include
#include
#include
#include
using namespace std;
typedef struct rect
{
int id;
int length;
int width;
bool operator< (const rect &a) const
{
if(id!=a.id)
return id vec;
Rect rect;
rect.id=1;
rect.length=2;
rect.width=3;
vec.push_back(rect);
rect.id=2;
rect.length=3;
rect.width=5;
vec.push_back(rect);
rect.id=1;
rect.length=3;
rect.width=3;
vec.push_back(rect);
vector::iterator it=vec.begin();
sort(vec.begin(), vec.end()); //排序
for(; it < vec.end(); it++) {
cout<<(*it).id<<' '<<(*it).length<<' '<<(*it).width< 4.6 关于algorithm的sort
sort(a,a+N,cmp),第三个参数是一个函数 ;
sort函数的三个参数
第一个;开始值的地址
第二个;结束值的地址
第三个;排序的函数,若没有则默认为升序排列;记住函数return中大于为降序,小于为升序。
#include
#include
#include
#include
#include
#include
#include
#include #include
#include
#include
#include
#include
#include
#include
#include algorithm的其他常用函数
//algorithm中的swap函数
char x = 'X', y = 'Y';
int a = 1, b = 2;
swap(x, y);
swap(a, b);
printf("x = %c, y = %c\n", x, y);
printf("a = %d, y = %d\n", a, b);
char str[] = "abcdefgh";
//algorithm中的反转函数
reverse(str+2,str+7); //前闭后开
cout << str << endl; #include
#include
using namespace std;
int main() {
string s = "0123456789";
int n;
cin >> n;
int cnt = 1;
do {
//数据处理
}while(next_permutation(s.begin(), s.end())); //实现全排
return 0;
}